搜索引擎之如何实时更新索引
1.引子
公司的底层检索引擎已经用了10年,很稳定也没有很大的重构需求,直到最近PM报了很多数据更新不及时的问题,
加上最近我也有个想法实现一个轻量级的检索引擎,于是用了不到2个月算是完成第1版(github地址:https://github.com/dodng/comse)
一是尝试解决现有公司的检索系统中更新时效性的问题,二是把自己对检索服务的理解动手实践一下。
2.搜索引擎的索引
在我讲述索引更新策略前,容我在和大家一起回顾一下搜索引擎的索引,如下:
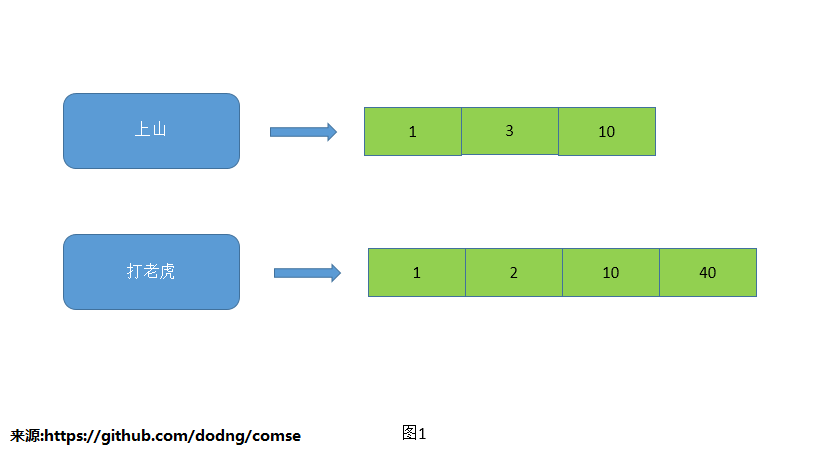
图1中蓝色的是term,绿色的列表就是倒排索引(不知道的话可以去google搜索),里面的数字代表的是docID
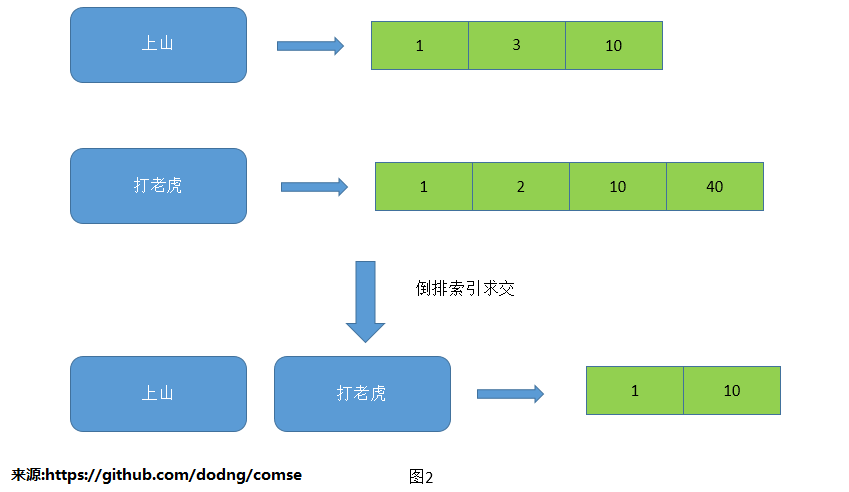
索引的组织结构一般是线性表(docID按照増序排列),方便快速查找(时间复杂度lg(n)),并与别的term索引进行求交(详见图2)
3.常见的更新索引策略
现在切入主题,常见的更新索引策略有2个,如下:
1.全量更新后双buffer交换
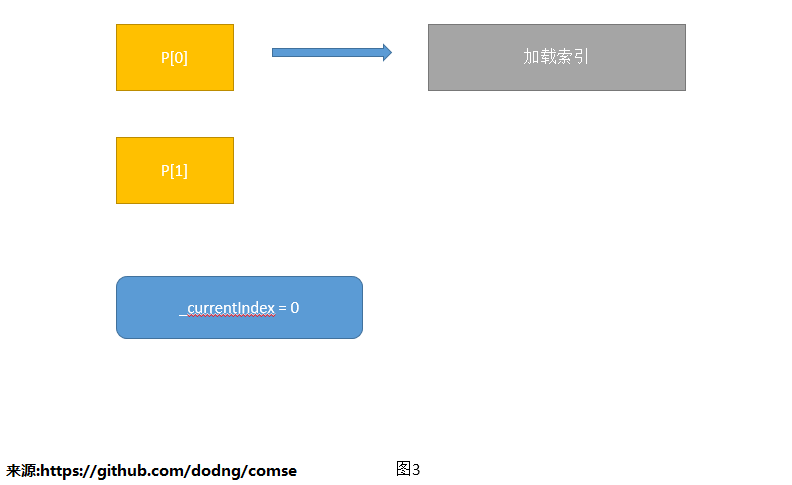
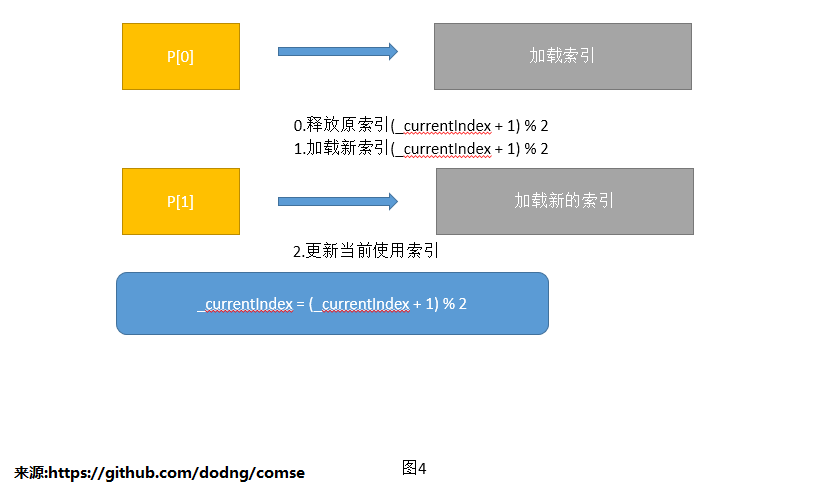
优点:查询快,只是读取操作,无锁操作。代码实现简单
缺点:内存至少需要索引内存的2倍。索引更新的时效性差。
扩展:我们公司现有的索引就是这个样子,只不过有2套索引。可以简单理解为有1套数据量非常大的索引,基本1天更新一次,
另外1套数据量小的索引,半小时更新一次。这2套索引各自更新,最后检索的结果是这2个索引返回数据的并集,然后再排序输出。
2.小索引更新后合并到大索引

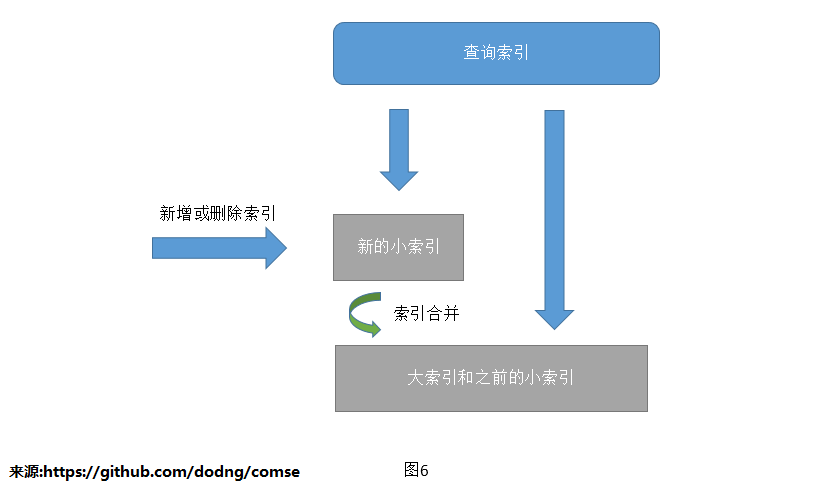
优点:索引更新的时效性较快
缺点:开发量和代码实现难度增加,查询小索引时会有锁操作
扩展:粗略的看了几个常用的开源检索引擎和一些相关的专利,基本都是这种方式。
4."原地"实时更新索引
comse用到的实时更新策略:
1.新增索引
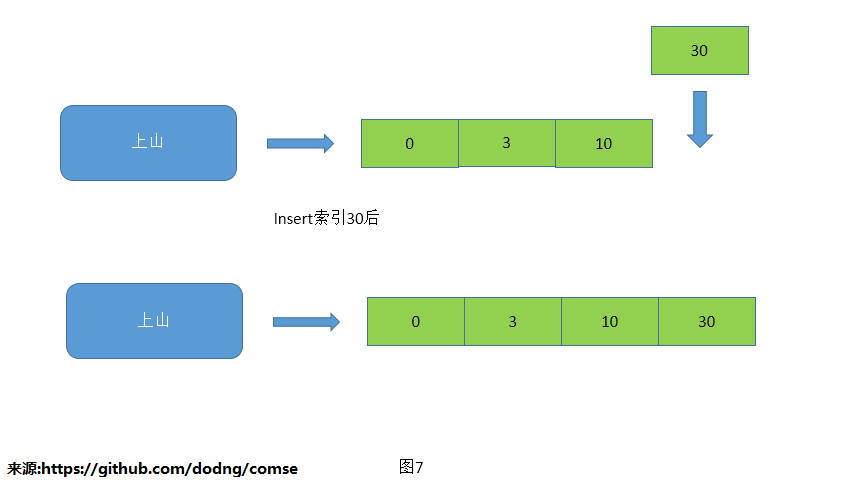
现在的策略比较简单粗暴,保证索引的docID号是递增的,新增索引只是在索引后面追加一个docID就好。
2.删除索引
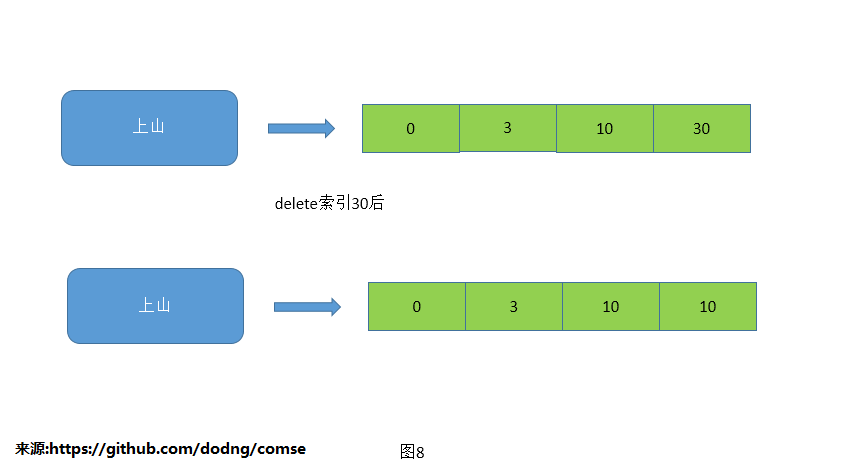
删除索引采取的是伪删除,即用前面一个docID覆盖要删除的docID,一是保证了docID是増序排列,二是快速的删除了docID。
不过有个细节要注意的是每个索引第1个元素要添加一个空元素“0”,保证第1个有用的元素删除时不会出现异常。
3.压缩索引
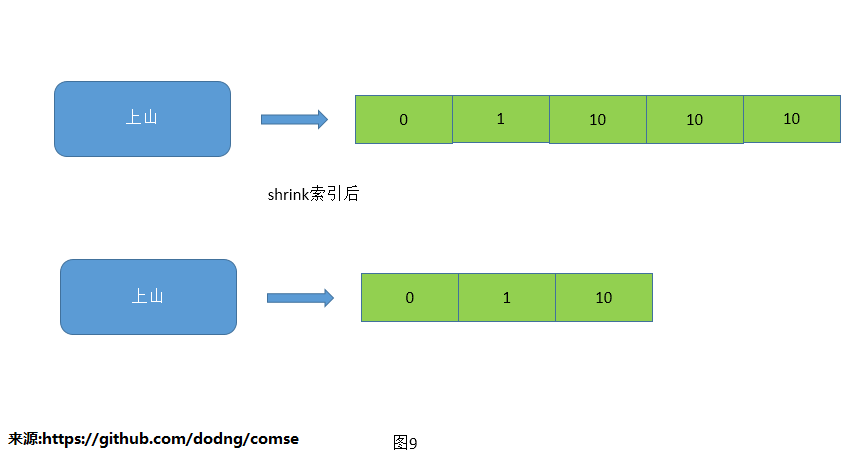
由于删除元素采用的是伪删除,会导致索引中堆积大量的重复docID,使用shrink就是压缩索引,使索引数量最小化,从而达到节省空间
和加快查找速度的目的。
最后欢迎大家去使用或点赞https://github.com/dodng/comse,有什么问题或好玩的东西,大家可以一起讨论下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号