第二次结对作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzzcxy/2018SE1 |
|---|---|
| 作业目标 | 爬取云班课堂经验值,完成经验值排序 |
| 作业源代码 | https://gitee.com/floating-life/Collaboration2nd |
| 蔡华翔 | 211806301 |
| 林清松 | 211806392 |
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzzcxy/2018SE1/homework/11250 |
#1、我和我的伙伴
蔡华翔:平时喜欢出门逛逛,看看电影,喝杯奶茶,喜欢游泳。
林清松:平时喜欢打游戏,就这样。
这是我们第二次合作一定会更加有默契,办事效率也会提高。
#2、结对感受
对于本次作业,这次的题目是利用cookies模拟登陆,获取非本页面HTML的元素并对其进行爬取。很多东西都不太会使用,通过两个人的结对研究,从原本对爬虫一无所知,通过两天对爬虫教程的了解,也就学了个皮毛,也是询问了对爬虫认知比较多的同学才得以有个大致的了解,观摩已完成同学的代码和思路,逐渐对爬虫有了一个较为立体的认识。一步步从不会到入门,也促进了伙伴之间的合作能力,经过分工合作和分工复查,最后发现作业也并没有想象的那么困难,这次作业锻炼提升了我们伙伴间的结对能力和自学能力。
结对讨论图片


#3、结对过程
(1)项目需求以及分析:
这次的项目需求分析和具体实现思路。
①通过获取cookie模拟登陆,进入活动页面获取html信息。
②通过获取的html信息统计每个学生的课堂完成部分的总经验值。
③分别对每个url爬取存入html。
④最后统计分数,和最高分,最低分,平均分,存入txt文件中。
(2)详细代码解析:
①将活动页相关的url和cookie放在properties中,去获取相应的活动页的登录

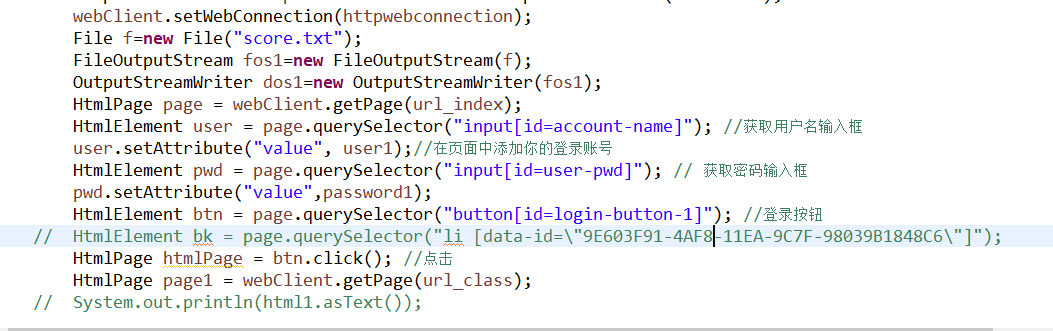
②寻找相对应集合能进行排序的函数,对所获得的数据进行排序,最后用文本文件的格式进行输出。

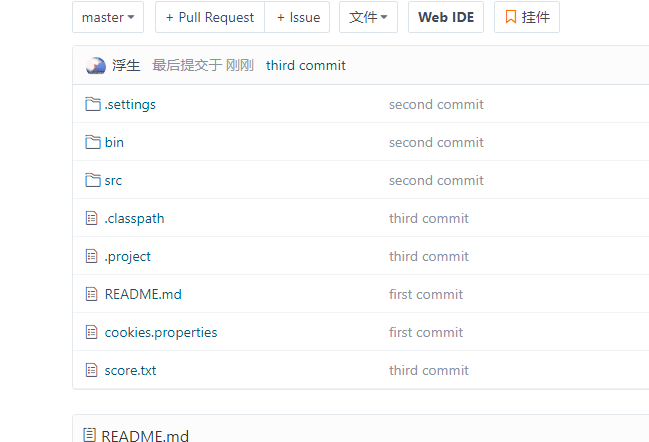
(3)最终结果和commit信息:
成绩统计表:

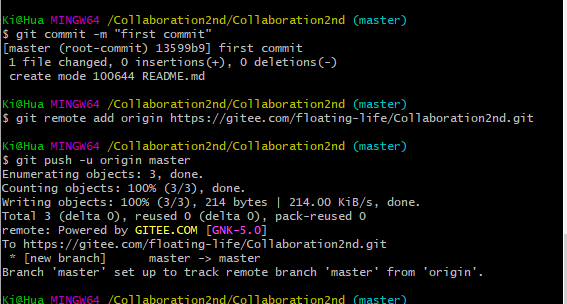
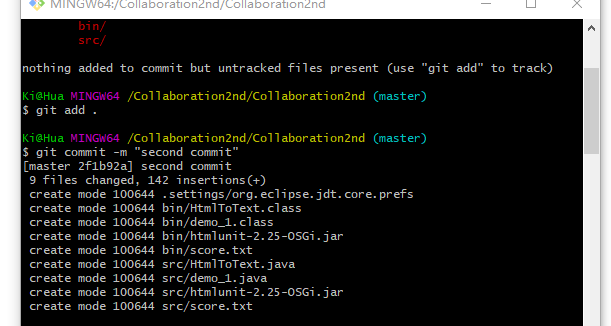
commit信息:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号