

食鲜配·智厨 :数据采集项目实践
食鲜配·智厨 :数据采集项目实践
综合设计——多源异构数据采集与融合应用综合实践
| 这个项目属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2025DataCollectionandFusiontechnology |
|---|---|
| 组名 | 风雨无组 |
| 项目名字及简介 | 食鲜配·智厨是一个基于Python 3.7+和Django 2.0.7的智能电商菜谱一体化平台,实现了"购物-菜谱-健康"的完整闭环,为用户提供"买什么-怎么做-吃得健康"一站式解决方案。 |
| 项目logo |  |
| 团队成员学号 | 102302101、102302102、102302103、102302104、102302105、102302106、102302109、102302110 |
| 项目目标 | 实现网页端多源异构数据采集,构建用户画像并完成食材与菜谱的智能推荐,实现 AI 分析与 Web 应用展示,形成完整的数据采集与融合闭环。 |
| 其他参考文献 | https://github.com/CRIPAC-DIG/SR-GNN |
| gitee仓库地址 | https://gitee.com/ding41/buy-menu |
系统架构设计
系统整体采用 B/S 架构,构建如下闭环流程:
多源数据采集 → 数据分析与融合 → 推荐算法 → Web系统展示 → 用户交互 → 行为反馈
1. 技术选型说明
| 模块 | 技术 |
|---|---|
| 后端 | Python、Django |
| 前端 | HTML / CSS / JavaScript |
| 数据库 | SQLite |
| 数据分析 | Pandas、文本分析 |
| 推荐逻辑 | 标签匹配 + 点击量排序 |
| AI功能 | 通用大模型 + 自定义逻辑 |
| 部署 | 云服务器环境 |
核心功能设计与实现
后台管理系统
商品全生命周期管理
菜谱管理与食材绑定
用户行为数据可视化
前台核心功能
(1)商品浏览与购物车
分类浏览、关键词搜索
分量与处理方式选择
购物车实时价格更新
(2)菜谱推荐与双向推荐算法
商品 → 菜谱推荐:基于商品标签匹配菜谱食材
菜谱 → 商品推荐:基于菜谱所需食材匹配商品
支持“一键加购”
(3)AI 智能分析与个性化模块
食材搭配合理性分析
健康饮食偏好设置(低糖/低盐等)
AI 助手提供烹饪与处理建议
个人任务概述
本项目是一个围绕数据采集和应用展开的个人项目任务分工,主要包含五个核心任务:
- 开发菜谱视频爬虫
- 搭建AI聊天助手
- 设计后台管理原型
- 设计优化前端登录注册页
- 搭建前后端页面搜索逻辑
本文将详细介绍这些核心任务的实现过程、关键技术和代码细节。
技术栈
| 类别 | 技术 |
|---|---|
| 后端框架 | Django |
| 前端技术 | HTML5, CSS3, JavaScript, jQuery |
| 数据处理 | Pandas |
| 网络请求 | Requests |
| AI服务 | DeepSeek API |
| 数据存储 | SQLite (开发环境), MySQL (生产环境) |
| 开发工具 | PyCharm, VS Code |
核心任务实现
1. 开发菜谱视频爬虫
菜谱视频爬虫是本项目的核心功能之一,用于从B站自动搜索并匹配与菜谱相关的视频内容。
核心功能
- 从CSV文件读取菜谱数据
- 智能提取菜谱关键词
- 调用B站API搜索相关视频
- 将匹配的视频链接保存回CSV文件
完整代码实现
import pandas as pd
import requests
import time
import urllib.parse
import logging
import re
# --- 配置日志 --- # 设置日志记录,便于调试和监控
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# --- 全局设置 --- # 定义输入输出文件和请求头
INPUT_CSV = '家常菜.csv' # 输入CSV文件路径
OUTPUT_CSV = '家常菜_updated.csv' # 输出CSV文件路径
HEADERS = { # 请求头配置,模拟浏览器行为
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Referer': 'https://www.bilibili.com/'
}
def clean_text_for_search(title, desc, steptext):
"""
终极版三级智能清洗函数,依次分析 title, desc, steptext。
"""
# 定义停用词列表,用于过滤无意义的词汇
stop_words = {
'的', '地', '了', '吧', '吗', '啊', '!', '!', '?', '?', '༄',
'家常菜', '下饭菜', '快手', '美味', '好吃', '简单', '学会',
'分钟', '一道', '这个', '教程', '做法', '菜谱', '食谱', '好菜'
}
def get_clean_query_from_text(text):
"""辅助函数,用于从单段文本中提取关键词"""
if not isinstance(text, str) or not text: # 检查文本是否有效
return ""
# 移除所有非中文字符、字母和数字,以及数字编号
cleaned_text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z]', ' ', text)
cleaned_text = re.sub(r'\b\d+\b', '', cleaned_text) # 移除独立的数字
word_list = cleaned_text.split() # 分割文本为单词列表
filtered_words = [word for word in word_list if word not in stop_words] # 过滤停用词
query = "".join(filtered_words) # 合并为查询字符串
return query.strip() # 去除首尾空格
# --- 第一级:分析标题 --- # 优先从标题提取关键词
query = ""
if title and title not in ["家常菜"]: # 检查标题是否有效
# 移除所有括号和标签及其内容
processed_title = re.sub(r'[\[【《##·|].*?[\]】》·|]', '', title) # 移除方括号、书名号等
processed_title = re.sub(r'(.*?)', '', processed_title) # 移除中文括号
processed_title = re.sub(r'\(.*?\)', '', processed_title) # 移除英文括号
query = get_clean_query_from_text(processed_title) # 提取关键词
# --- 第二级:如果标题无效,分析描述 --- # 标题提取失败则从描述提取
if len(query) < 2: # 检查关键词长度是否足够
logging.info(f"标题 '{title[:20]}...' 无效,尝试从描述中提取...")
first_sentence_desc = re.split(r'[。,!]', desc)[0] if isinstance(desc, str) else "" # 取描述的第一句话
query = get_clean_query_from_text(first_sentence_desc) # 提取关键词
# --- 第三级:如果描述也无效,分析步骤 --- # 描述提取失败则从步骤提取
if len(query) < 2: # 检查关键词长度是否足够
logging.info(f"描述 '{str(desc)[:20]}...' 无效,尝试从步骤中提取...")
# 从步骤文本中提取,移除引导性的数字和符号
cleaned_step = re.sub(r'^\d*[️⃣#\s]*', '', steptext) if isinstance(steptext, str) else ""
first_part_step = re.split(r'[。,!#]', cleaned_step)[0] # 取步骤的第一部分
query = get_clean_query_from_text(first_part_step) # 提取关键词
# 最后过滤一次通用词
if query == "家常":
return ""
return query
# B站视频搜索函数
def search_bilibili_video(query, session):
if not query: # 检查查询词是否有效
logging.warning("清洗后的关键词为空,跳过搜索。")
return None
api_url = "https://api.bilibili.com/x/web-interface/search/type" # B站搜索API
params = {'search_type': 'video', 'keyword': query, 'order': 'totalrank', 'page': 1} # 搜索参数
try:
logging.info(f"正在通过API搜索清洗后的关键词: '{query}'")
response = session.get(api_url, params=params, timeout=15) # 发送请求
response.raise_for_status() # 检查请求是否成功
data = response.json() # 解析响应数据
if data.get('code') == 0: # 检查API返回状态
video_list = data.get('data', {}).get('result', []) # 获取视频列表
if video_list: # 检查视频列表是否为空
video_url = video_list[0].get('arcurl') # 获取第一个视频的URL
if video_url: # 检查URL是否有效
clean_url = video_url.split('?')[0] # 去除URL参数
logging.info(f"成功找到视频链接: {clean_url}")
return clean_url
else:
logging.warning(f"API为 '{query}' 返回了结果,但视频列表为空。")
else:
logging.warning(f"API返回错误: {data.get('message')}")
return None
except Exception as e: # 捕获异常
logging.error(f"处理 '{query}' 时发生错误: {e}")
return None
# 主程序入口
def main():
try:
df = pd.read_csv(INPUT_CSV, encoding='utf-8').fillna('') # 读取CSV文件,填充空值
except FileNotFoundError:
logging.error(f"错误:找不到文件 '{INPUT_CSV}'。")
return
if 'videourl' not in df.columns: # 检查是否有视频URL列
df['videourl'] = '' # 添加视频URL列
with requests.Session() as session: # 创建会话对象,保持连接
session.headers.update(HEADERS) # 设置请求头
try:
logging.info("正在初始化会话并获取B站Cookie...")
session.get("https://www.bilibili.com", timeout=15) # 获取B站Cookie
logging.info("Cookie获取成功,开始处理任务。")
except requests.exceptions.RequestException as e:
logging.error(f"初始化会话失败: {e}")
return
# 遍历CSV文件中的每一行
for index, row in df.iterrows():
if row.get('videourl', ''): # 检查是否已经有视频URL
continue # 跳过已处理的行
# <<< 核心修改:将三个字段都传入分析引擎 >>>
search_query = clean_text_for_search(row['title'], row['desc'], row['steptext']) # 提取关键词
video_url = search_bilibili_video(search_query, session) # 搜索视频
if video_url: # 检查是否找到视频
df.loc[index, 'videourl'] = video_url # 保存视频URL
time.sleep(1) # 设置请求间隔,避免触发反爬机制
logging.info("等待 1 秒后继续...")
df.to_csv(OUTPUT_CSV, index=False, encoding='utf-8-sig') # 保存结果到CSV文件
logging.info(f"处理完成!结果已保存到 '{OUTPUT_CSV}'。")
# 程序入口
if __name__ == '__main__':
main()
技术亮点
-
三级智能关键词提取机制:
- 优先从标题提取关键词,标题最能反映菜谱的核心信息
- 标题提取失败则从描述中提取第一句话
- 描述提取失败最后从步骤文本中提取
-
多维度文本清洗:
- 移除括号、标签、数字编号等无关信息
- 过滤常见的无意义词汇(停用词)
- 处理空值和异常情况,确保程序稳健运行
-
完善的反爬策略:
- 使用Session对象保持会话状态,提高请求成功率
- 自动获取并携带B站Cookie
- 设置合理的请求间隔(1秒),避免触发B站的反爬机制
-
详细的日志记录:
- 记录程序运行状态和关键操作
- 便于调试和监控程序运行情况
2. 搭建AI聊天助手
AI聊天助手是基于DeepSeek API实现的智能对话系统,提供菜谱推荐、烹饪技巧等服务。
核心功能
- 流式响应,提升用户体验
- 聊天记录保存功能
- 响应式UI设计
- 安全的API Key管理
技术实现
AI聊天助手主要通过static/js/ai-chatbot/chatbot.js文件实现,核心功能包括:
- 流式响应处理:实时展示AI回复,避免用户长时间等待
- 聊天记录管理:使用localStorage保存最近20条聊天记录
- 响应式UI:适配不同屏幕尺寸,提供良好的移动端体验
- 安全机制:支持从localStorage读取API Key,避免硬编码
关键代码片段
// AI聊天助手核心代码片段
async function callAI(prompt) {
if (!API_KEY || !API_KEY.startsWith("sk-")) {
addMessage("抱歉,主人还没给我配置正确的 DeepSeek API Key 哦。", 'ai'); return;
}
// 创建一个新的、空的AI消息气泡,准备接收数据流
const aiMessageElement = addMessage("", 'ai');
const bubble = aiMessageElement.querySelector('.message-bubble');
bubble.classList.add('is-thinking'); // 添加闪烁光标效果
try {
const response = await fetch("https://api.deepseek.com/chat/completions", {
method: 'POST',
headers: { 'Content-Type': 'application/json', 'Authorization': `Bearer ${API_KEY}` },
body: JSON.stringify({
model: "deepseek-chat",
messages: [{ role: "user", content: prompt }],
stream: true // 关键:开启流式传输
})
});
if (!response.ok) { throw new Error(`API 请求失败: ${response.statusText}`); }
const reader = response.body.getReader();
const decoder = new TextDecoder("utf-8");
let fullResponse = "";
// 循环读取数据流
while (true) {
const { done, value } = await reader.read();
if (done) break; // 数据流结束
const chunk = decoder.decode(value);
const lines = chunk.split("\n").filter(line => line.trim().startsWith("data: "));
for (const line of lines) {
const jsonStr = line.replace("data: ", "");
if (jsonStr === "[DONE]") { // DeepSeek的结束标志
break;
}
try {
const parsed = JSON.parse(jsonStr);
const content = parsed.choices[0].delta.content || "";
if (content) {
fullResponse += content;
// 将Markdown实时渲染并更新到气泡中
bubble.innerHTML = marked.parse(fullResponse);
messagesContainer.scrollTop = messagesContainer.scrollHeight; // 实时滚动到底部
}
} catch (error) {
// 忽略解析错误,继续处理下一行
}
}
}
} catch (error) {
console.error("调用 DeepSeek 流式 API 时出错:", error);
bubble.innerHTML = `抱歉,我好像遇到了一点问题:${error.message}`;
} finally {
// 请求结束后,移除思考中的光标效果
bubble.classList.remove('is-thinking');
}
}
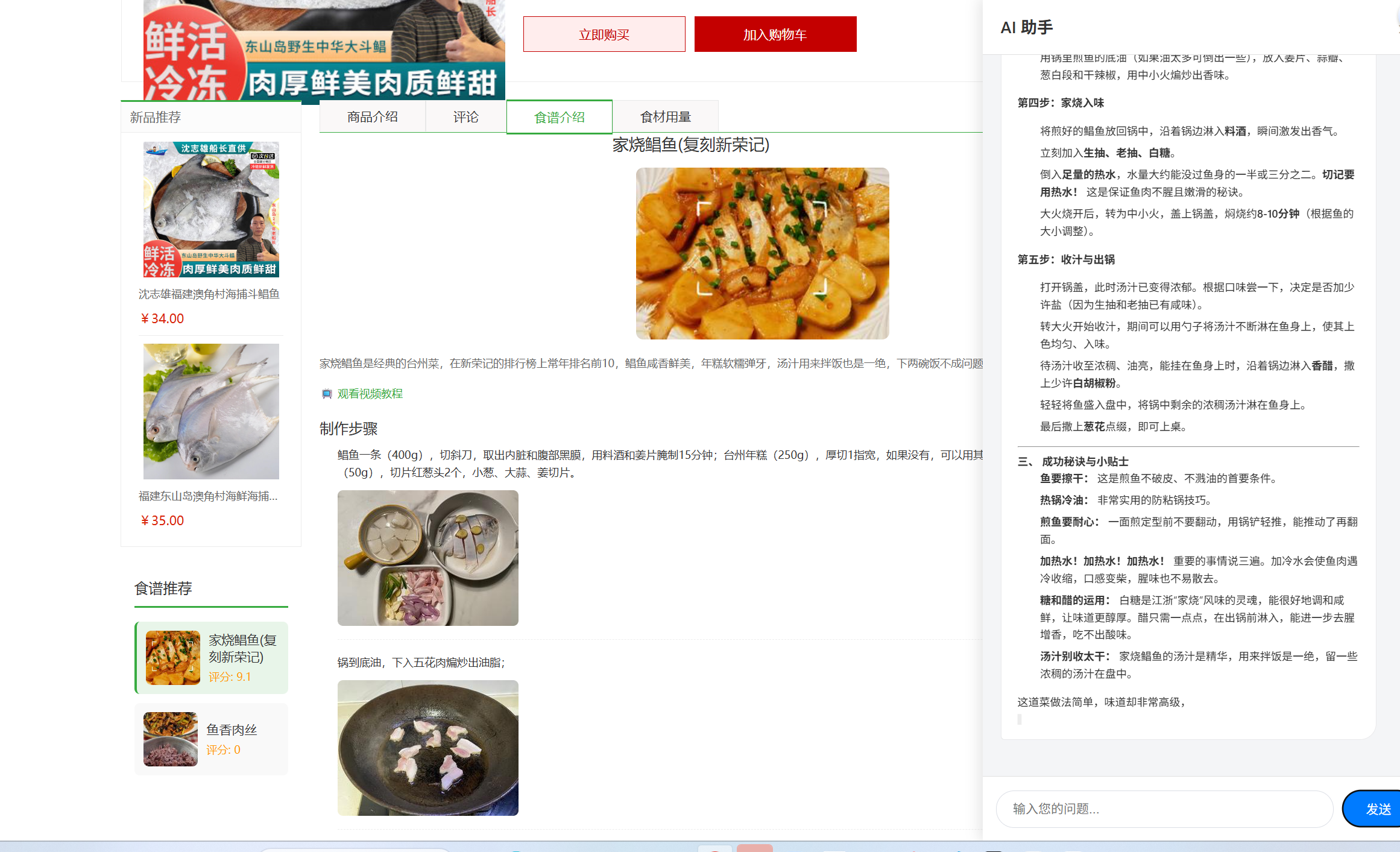
3. 设计后台管理原型
后台管理原型设计用于管理菜谱数据、用户信息和系统配置。
核心功能
- 菜谱数据管理(增删改查)
- 用户信息管理
- 系统配置
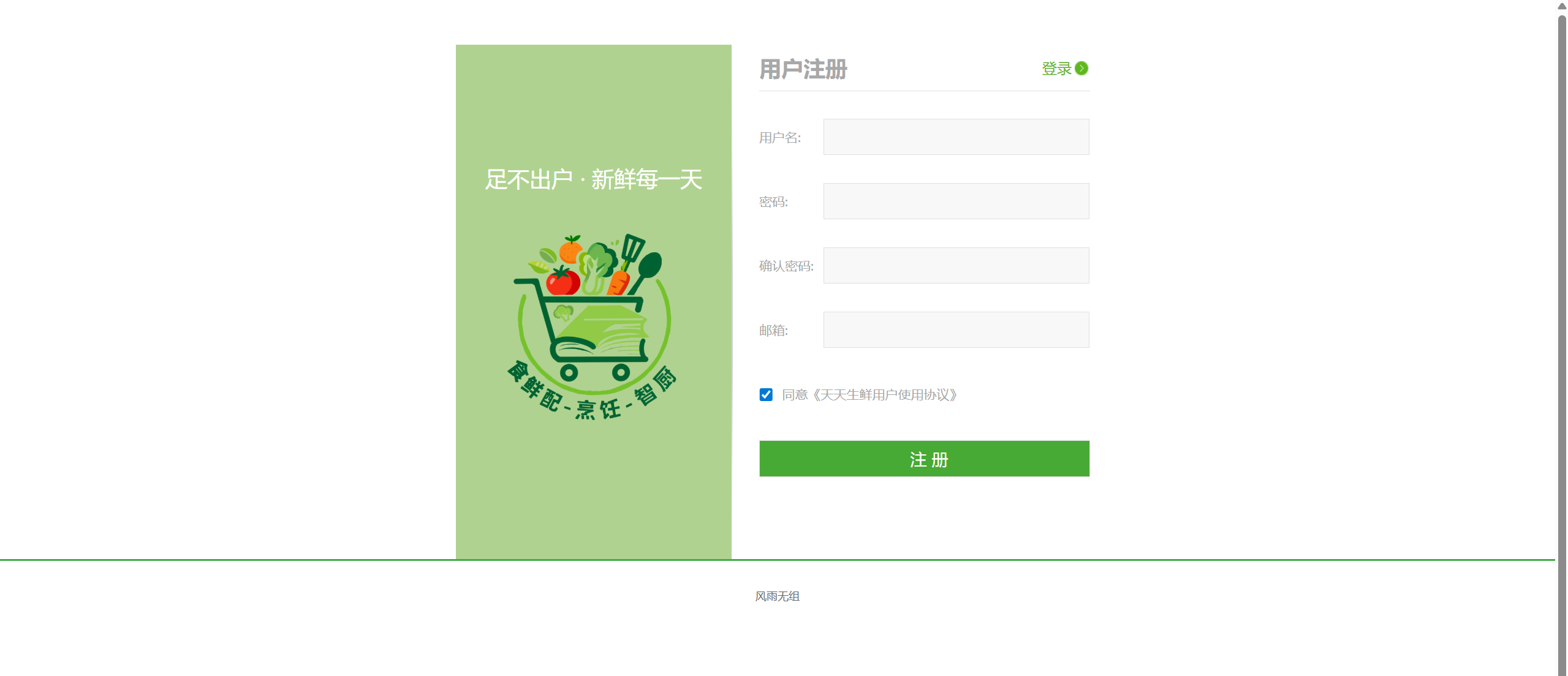
4. 设计优化前端登录注册页
前端登录注册页是用户与系统交互的入口,提供了良好的用户体验和安全保障。
核心功能
- 用户登录
- 用户注册
- 表单验证
- 密码安全
技术实现
登录页面设计:
<!-- 登录页面核心结构 -->
<div class="login_form_bg">
<div class="login_form_wrap clearfix">
<div class="login_banner fl">
<div class="slogan">日夜兼程 · 急速送达</div>
<a href="{% url 'df_goods:index' %}">
<img src="/static/images/logo02.png" alt="logo">
</a>
</div>
<div class="login_form fr">
<div class="login_title clearfix">
<h1>用户登录</h1>
<a href="{% url "df_user:register" %}">立即注册</a>
</div>
<div class="form_input">
<form action="{% url "df_user:login_handle" %}" method="post">
{% csrf_token %}
<input type="text" name="username" class="name_input" value="{{ username }}" placeholder="请输入用户名">
<div class="user_error">输入错误</div>
<input type="password" name="pwd" class="pass_input" value="{{ password }}" placeholder="请输入密码">
<div class="pwd_error">输入错误</div>
<div class="more_input clearfix">
<input type="checkbox" name="jizhu" value="1" checked="checked">
<label>记住用户名</label>
<a href="#">忘记密码</a>
</div>
<input type="submit" name="" value="登录" class="input_submit">
</form>
</div>
</div>
</div>
</div>
注册页面设计:
<!-- 注册页面核心结构 -->
<div class="register_con">
<div class="l_con fl">
<div class="reg_slogan">足不出户 · 新鲜每一天</div>
<a href="/" class="reg_logo"><img src="/static/images/logo02.png"></a>
</div>
<div class="r_con fr">
<div class="reg_title clearfix">
<h1>用户注册</h1>
<a href="{% url "df_user:login" %}">登录</a>
</div>
<div class="reg_form clearfix">
<form action="{% url "df_user:register_handle" %}" id='reg_form' method="post">
{% csrf_token %}
<ul>
<li>
<label>用户名:</label>
<input type="text" name="user_name" id="user_name">
<span class="error_tip">提示信息</span>
</li>
<li>
<label>密码:</label>
<input type="password" name="pwd" id="pwd">
<span class="error_tip">提示信息</span>
</li>
<li>
<label>确认密码:</label>
<input type="password" name="confirm_pwd" id="cpwd">
<span class="error_tip">提示信息</span>
</li>
<li>
<label>邮箱:</label>
<input type="text" name="email" id="email">
<span class="error_tip">提示信息</span>
</li>
<li class="agreement">
<input type="checkbox" name="allow" id="allow" checked="checked">
<label>同意《天天生鲜用户使用协议》</label>
<span class="error_tip2">提示信息</span>
</li>
<li class="reg_sub">
<input type="submit" value="注 册">
</li>
</ul>
</form>
</div>
</div>
</div>
技术亮点
-
现代化UI设计:
- 简洁美观的界面设计
- 统一的色彩搭配和视觉风格
- 清晰的信息层级
-
实时表单验证:
- 前端实时验证用户输入
- 提供即时反馈和错误提示
- 减少用户等待时间
-
响应式布局:
- 适配不同设备和屏幕尺寸
- 提供一致的用户体验
-
安全保障:
- 使用CSRF令牌防止跨站请求伪造
- 密码加密存储
- 输入验证和过滤
![image]()
![image]()

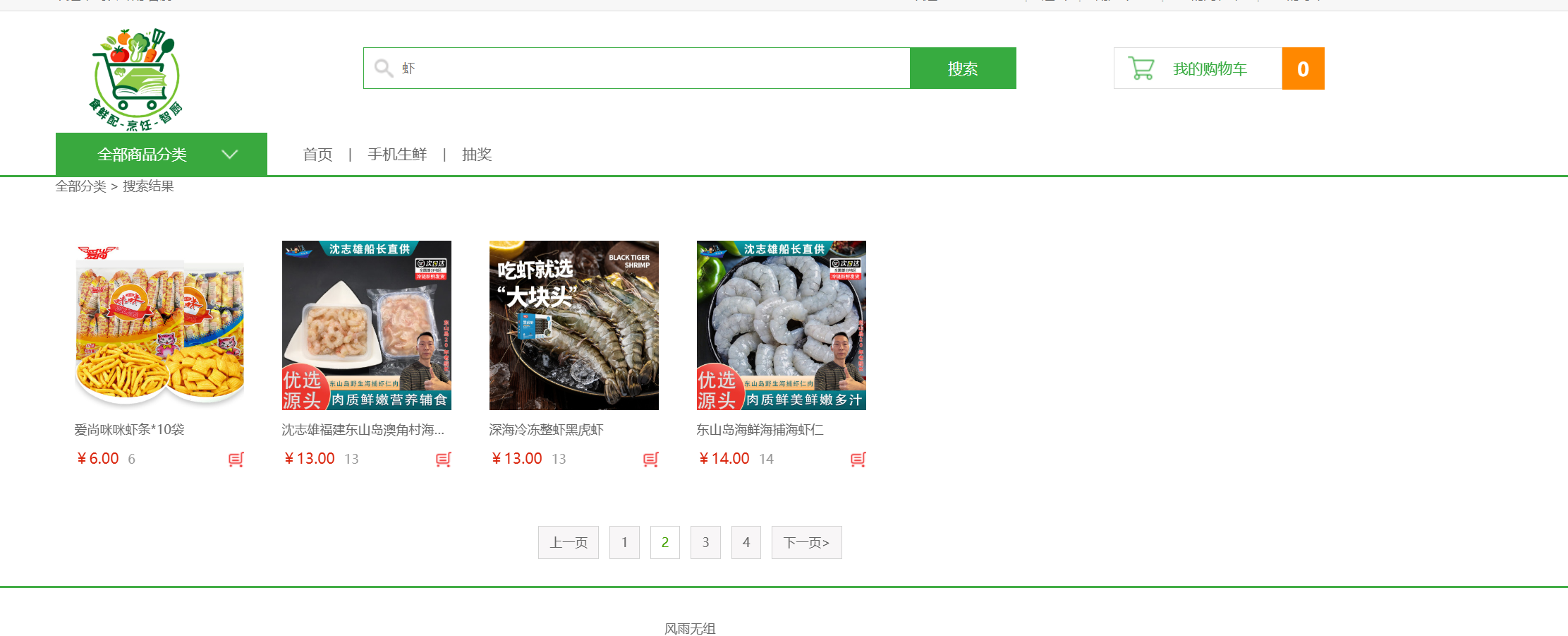
5. 搭建前后端页面搜索逻辑
前后端页面搜索逻辑实现了商品的多维度搜索功能,支持标题、内容、简介等字段的模糊查询。
核心功能
- 多字段模糊搜索
- 搜索结果分页
- 热门商品推荐
- 搜索状态提示
技术实现
后端搜索逻辑:
# views.py中的搜索功能实现
def ordinary_search(request):
"""通用搜索视图"""
search_keywords = request.GET.get('q', '') # 获取搜索关键词
pindex = request.GET.get('pindex', 1) # 获取当前页码
# 使用Q对象进行多字段模糊查询
goods_list = GoodsInfo.objects.filter(
Q(gtitle__icontains=search_keywords) | # 标题模糊查询
Q(gcontent__icontains=search_keywords) | # 内容模糊查询
Q(gjianjie__icontains=search_keywords) # 简介模糊查询
).order_by("-gclick") # 按人气倒序
search_status = 1 # 搜索状态,1表示有结果,0表示无结果
if not goods_list.exists(): # 检查搜索结果是否为空
search_status = 0
# 如果搜索结果为空,推荐4个热门商品
goods_list = GoodsInfo.objects.all().order_by("-gclick")[:4]
paginator = Paginator(goods_list, 4) # 每页显示4个商品
page = paginator.get_page(pindex) # 获取当前页商品列表
# 构建上下文
context = {
'title': '搜索列表',
'search_status': search_status,
'guest_cart': 1 if 'user_id' in request.session else 0,
'cart_num': cart_count(request),
'page': page,
'paginator': paginator,
'query': search_keywords, # 将搜索关键词传递给模板
}
return render(request, 'df_goods/ordinary_search.html', context) # 渲染搜索结果页面
前端搜索页面:
<!-- 搜索结果页面核心结构 -->
<div class="main_wrap clearfix">
<ul class="goods_type_list clearfix">
{% for item in page %} <!-- 遍历商品列表 -->
<li>
<a href="{% url 'df_goods:detail' item.id %}"><img src="{{ MEDIA_URL }}{{ item.gpic }}"></a>
<h4><a href="{% url 'df_goods:detail' item.id %}">{{ item.gtitle }}</a></h4>
<div class="operate">
<span class="prize">¥{{ item.gprice }}</span>
<span class="unit">{{ item.gunit }}</span>
<a href="{% url 'df_cart:add' item.id 1 %}" class="add_goods" title="加入购物车"></a>
</div>
</li>
{% endfor %}
</ul>
<!-- 分页部分 -->
<div class="pagenation">
<!-- 上一页 -->
{% if page.has_previous %}
<a href="{% url "df_goods:ordinary_search" %}?q={{ query }}&pindex={{ page.previous_page_number }}">上一页</a>
{% endif %}
<!-- 页面数字 -->
{% for pindex in paginator.page_range %}
{% if pindex == page.number %}
<a href="#" class="active">{{ pindex }}</a>
{% else %}
<a href="{% url "df_goods:ordinary_search" %}?q={{ query }}&pindex={{ pindex }}">{{ pindex }}</a>
{% endif %}
{% endfor %}
<!-- 下一页 -->
{% if page.has_next %}
<a href="{% url "df_goods:ordinary_search" %}?q={{ query }}&pindex={{ page.next_page_number }}">下一页></a>
{% endif %}
</div>
</div>
技术亮点
-
多字段搜索:
- 支持标题、内容、简介等多个字段的模糊查询
- 提高搜索的准确性和全面性
-
智能推荐:
- 搜索结果为空时推荐热门商品
- 提升用户体验和系统可用性
-
分页优化:
- 使用Django内置的分页功能
- 提升页面加载速度和用户体验
-
用户体验:
- 清晰的搜索结果展示
- 完整的分页导航
- 搜索状态提示
![image]()
技术难点与解决方案
1. 反爬机制应对
问题:B站有严格的反爬机制,频繁请求可能导致IP被封
解决方案:
- 使用Session对象保持会话状态
- 自动获取并携带B站Cookie
- 设置合理的请求间隔(1秒)
- 实现完善的错误处理机制
2. 智能文本处理
问题:菜谱数据中的文本信息包含大量无关内容,影响搜索准确性
解决方案:
- 实现三级智能关键词提取机制
- 使用正则表达式移除括号、标签和数字
- 建立停用词表,过滤无意义词汇
3. 性能优化
问题:搜索功能和爬虫功能在大数据量下性能下降
解决方案:
- 实现搜索结果分页
- 优化数据库查询,添加索引
- 限制爬虫请求频率
- 使用异步处理提升响应速度
项目总结与展望
项目总结
-
完整的数据采集系统:
- 实现了菜谱视频爬虫,自动采集和匹配视频内容
- 支持多维度数据处理和清洗
-
智能交互功能:
- 搭建了AI聊天助手,提供智能问答服务
- 支持流式响应和聊天记录管理
-
完善的管理功能:
- 设计了后台管理原型,便于管理和维护
- 实现了用户管理和权限控制
-
优化的用户界面:
- 设计了现代化的登录注册页面
- 实现了友好的搜索界面和结果展示
-
强大的搜索功能:
- 支持多字段模糊搜索
- 实现了分页和热门商品推荐
未来展望
-
功能扩展:
- 扩展菜谱视频爬虫支持更多平台
- 增强AI聊天助手的智能程度,支持更多场景
- 完善后台管理功能,添加更多统计和分析功能
-
性能优化:
- 优化搜索算法,提升搜索准确性和速度
- 改进爬虫策略,提高数据采集效率
- 优化系统架构,提升系统性能和稳定性
-
用户体验:
- 添加更多个性化功能,提升用户体验
- 优化移动端体验,提供更好的移动服务
- 增加社交功能,提高用户活跃度
-
安全性提升:
- 加强系统安全防护,防止黑客攻击
- 完善数据备份和恢复机制
- 提高系统的可靠性和可用性
结语
项目的成功实现离不开团队成员的协作和努力,也体现了我们在数据采集、前端开发和后端技术方面的能力。未来,我们将继续优化系统功能,为用户提供更好的服务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号