
作业4
数据采集与融合技术作业4
作业①:
要求:熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。 使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
(1)实验步骤:
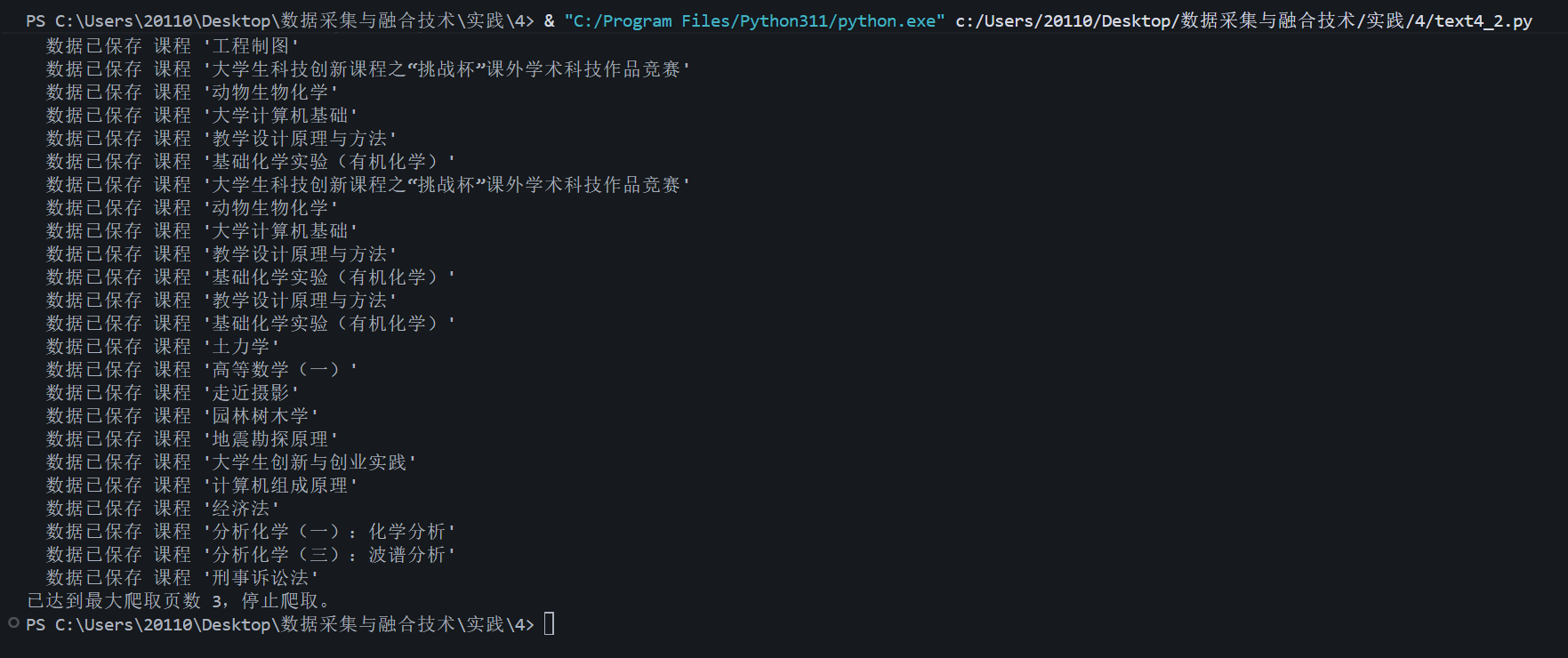
1.采集沪深京A股数据,这是默认的 Tab
复制xpath://*[@id="mainc"]/div/div/div[4]/table,定位到表格
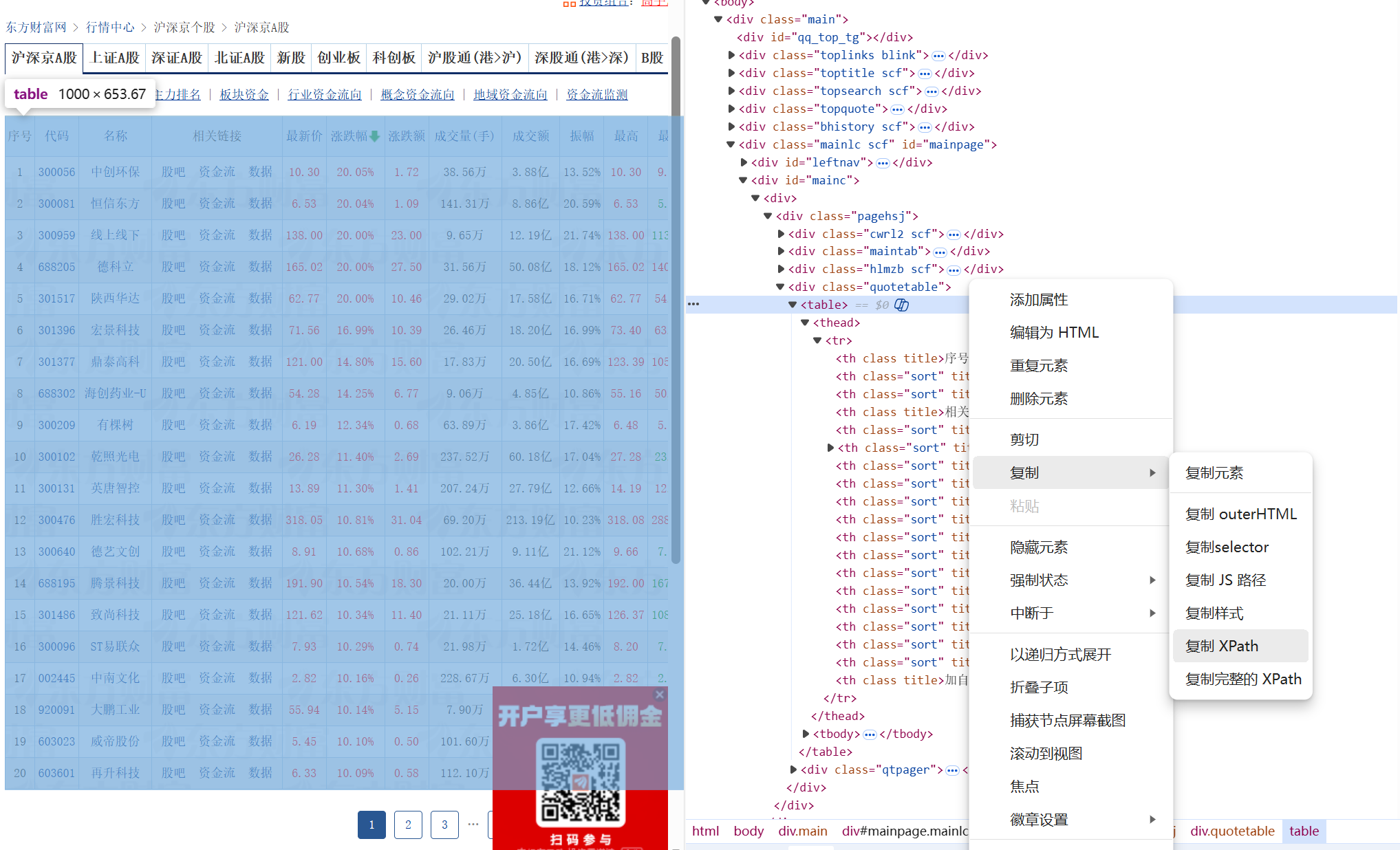
# 使用精确的 XPath 定位到数据表格的主体部分,并提取所有数据行
main_table_xpath = '//*[@id="mainc"]/div/div/div[4]/table' # 主数据表格的 XPath
trs = tree.xpath(f'{main_table_xpath}/tbody/tr') # 从表格 tbody 中获取所有行
data_list = [] # 用于存储从表格中提取出的每行股票数据
表格中要过滤掉表头行跟无效文本
for i, tr in enumerate(trs): # 遍历每一行数据
tds = [td.strip() for td in tr.xpath('.//text()') if td.strip()]
# not any(...): 检查行内是否包含表头关键字,排除表头行
if len(tds) > 5 and not any(col in ''.join(tds) for col in ['代码', '名称', '相关', '沪股通', '深股通', '港股通']):
# 过滤掉一些无关的文本,如“股吧”、“资金流”等
filtered_tds = [item for item in tds if item not in ['股吧', '资金流', '数据']]
if len(filtered_tds) < 13: # 如果提取的数据少于13列(序号+12个字段)
filtered_tds.extend([None] * (13 - len(filtered_tds)))
data_list.append(filtered_tds) # 将处理后的数据行添加到列表中
if i < 3:
print(f" 第{i+1}行数据: {filtered_tds[:13]}...")
对应信息插入数据库
for data in data_list: # 遍历每条股票数据进行插入
try:
if len(data) >= 13:
cursor.execute(
f"""INSERT INTO `{table_name}`
(stocksymbol, stockname, LatestPrice, Pricelimit, Riseandfall,
volume, turnover, amplitude, max_price, min_price, today_open, yesterday_close)
VALUES(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)""",
(data[1], data[2], data[3], data[4], data[5], # 股票代码、名称、最新价、涨跌幅、涨跌额
data[6], data[7], data[8], data[9], data[10], data[11], data[12]) # 成交量、成交额、振幅、最高、最低、今开、昨收
)
success_count += 1
except pymysql.MySQLError as e:
print(f"插入数据时出错: {e}")
print(f"问题: {data}")
except IndexError:
print(f"数据行格式不正确或长度不足,跳过: {data}")
conn.commit()
print(f"{table_name} 数据保存完成,共 {success_count} 条记录")
return True
2.采集上证A股数据
使用浏览器复制 XPath 来定位深证A股的 Tab 按钮
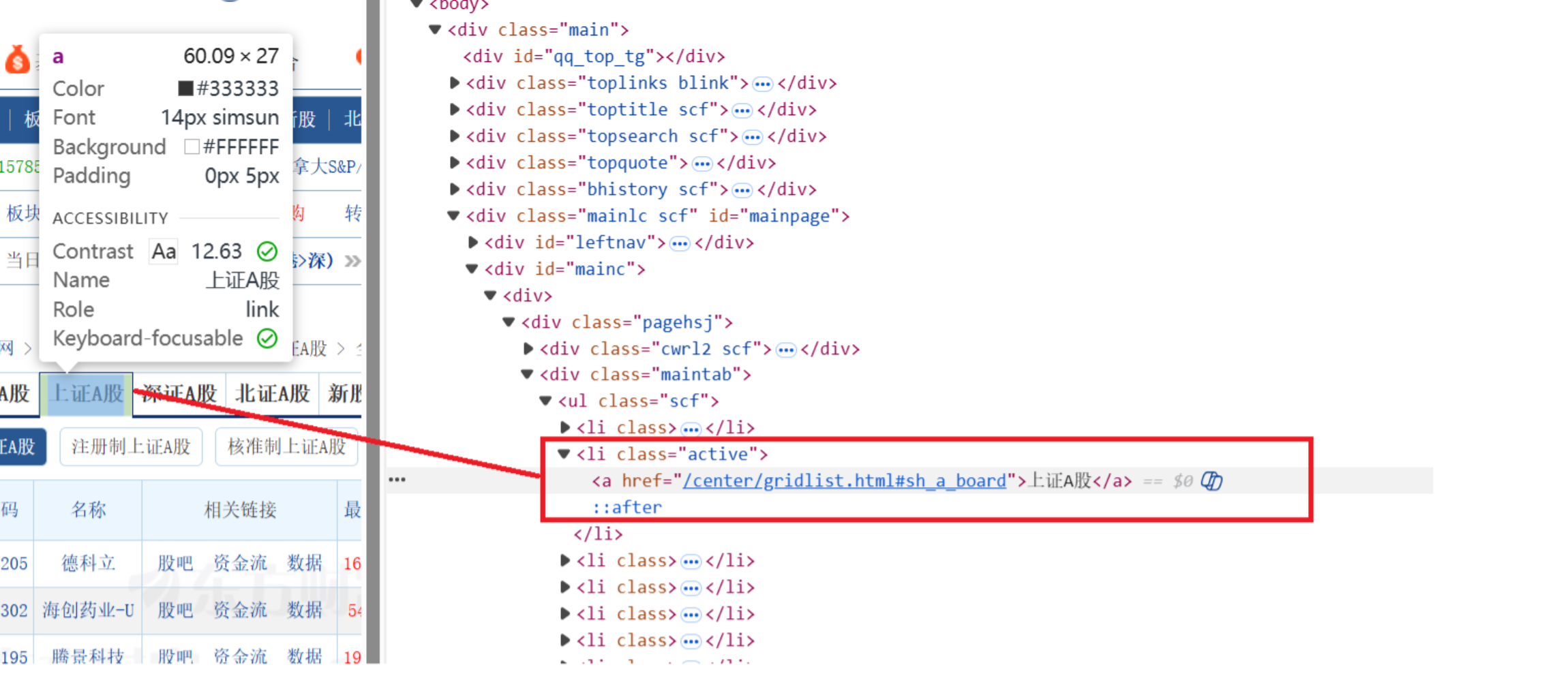
scrape_stock_data(driver, con, cursor, "shangzhengagu", '//*[@id="mainc"]/div/div/div[2]/ul/li[2]/a')
其余步骤一致
3.采集深证A股数据
使用浏览器复制 XPath 来定位深证A股的 Tab 按钮
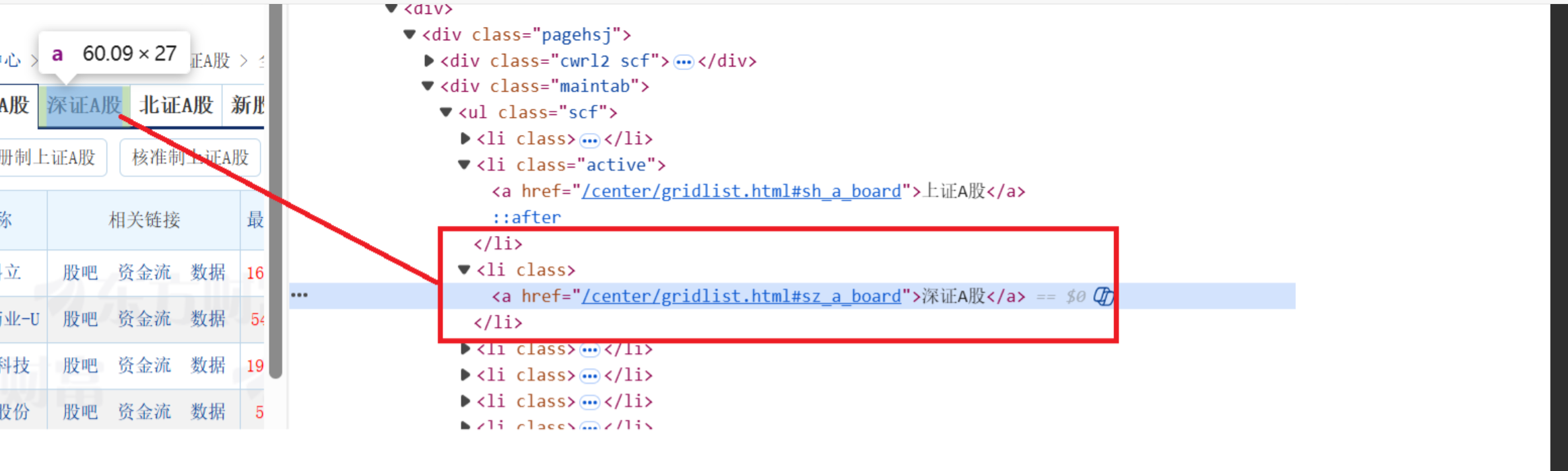
scrape_stock_data(driver, con, cursor, "shenzhengagu", '//*[@id="mainc"]/div/div/div[2]/ul/li[3]/a')
输出信息:
终端输出信息
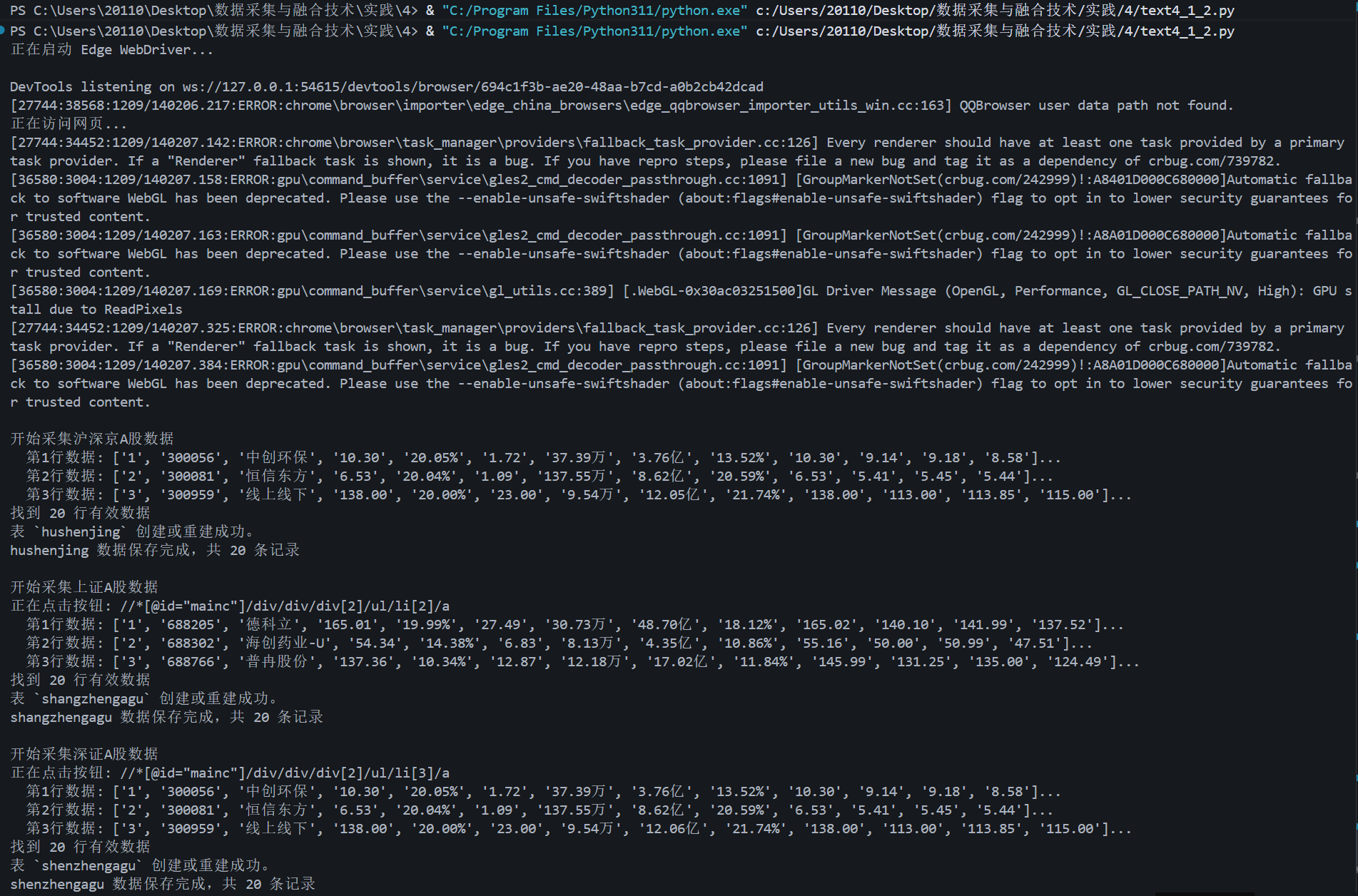
MySQL数据库
hushenjing
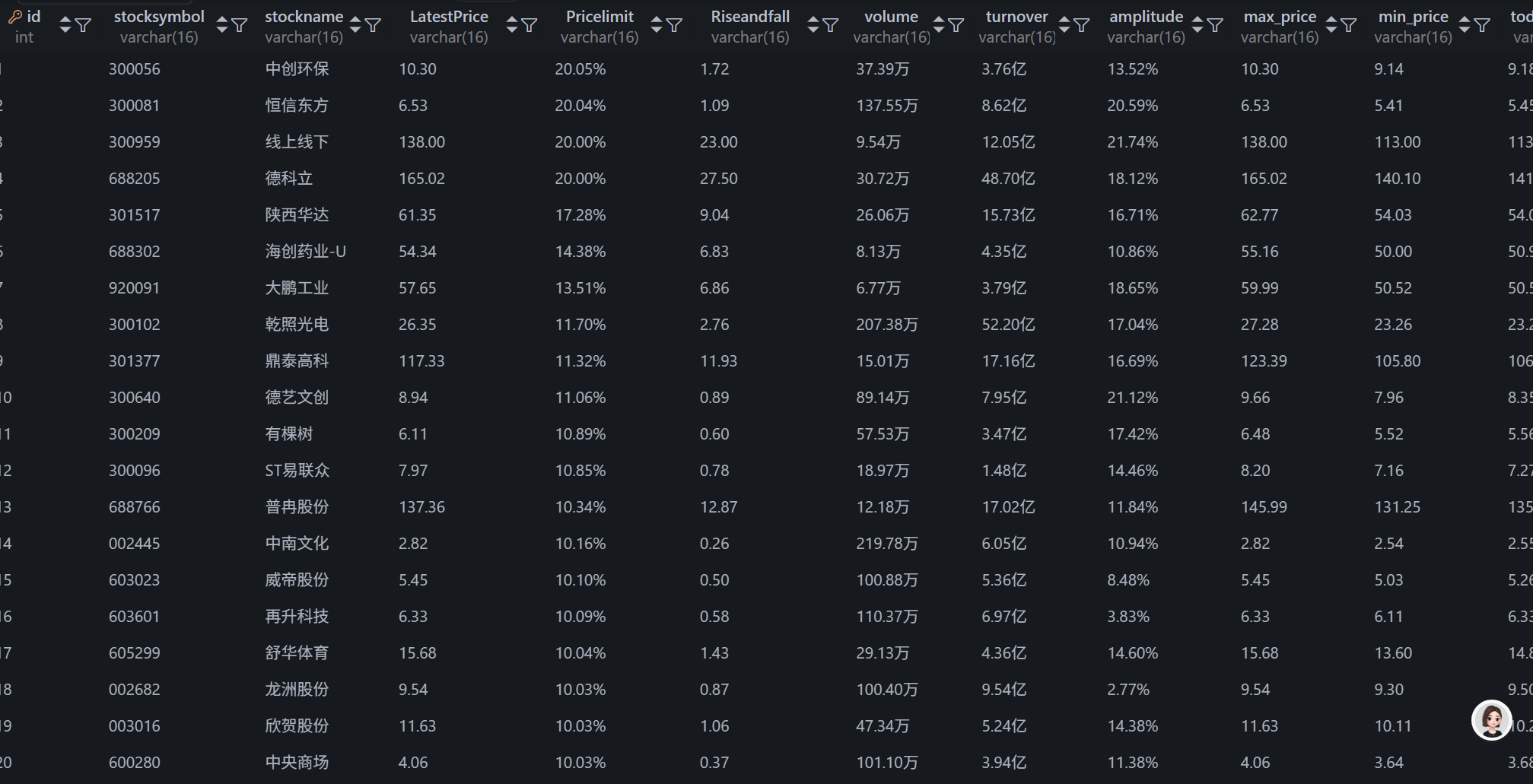
shangzhengagu
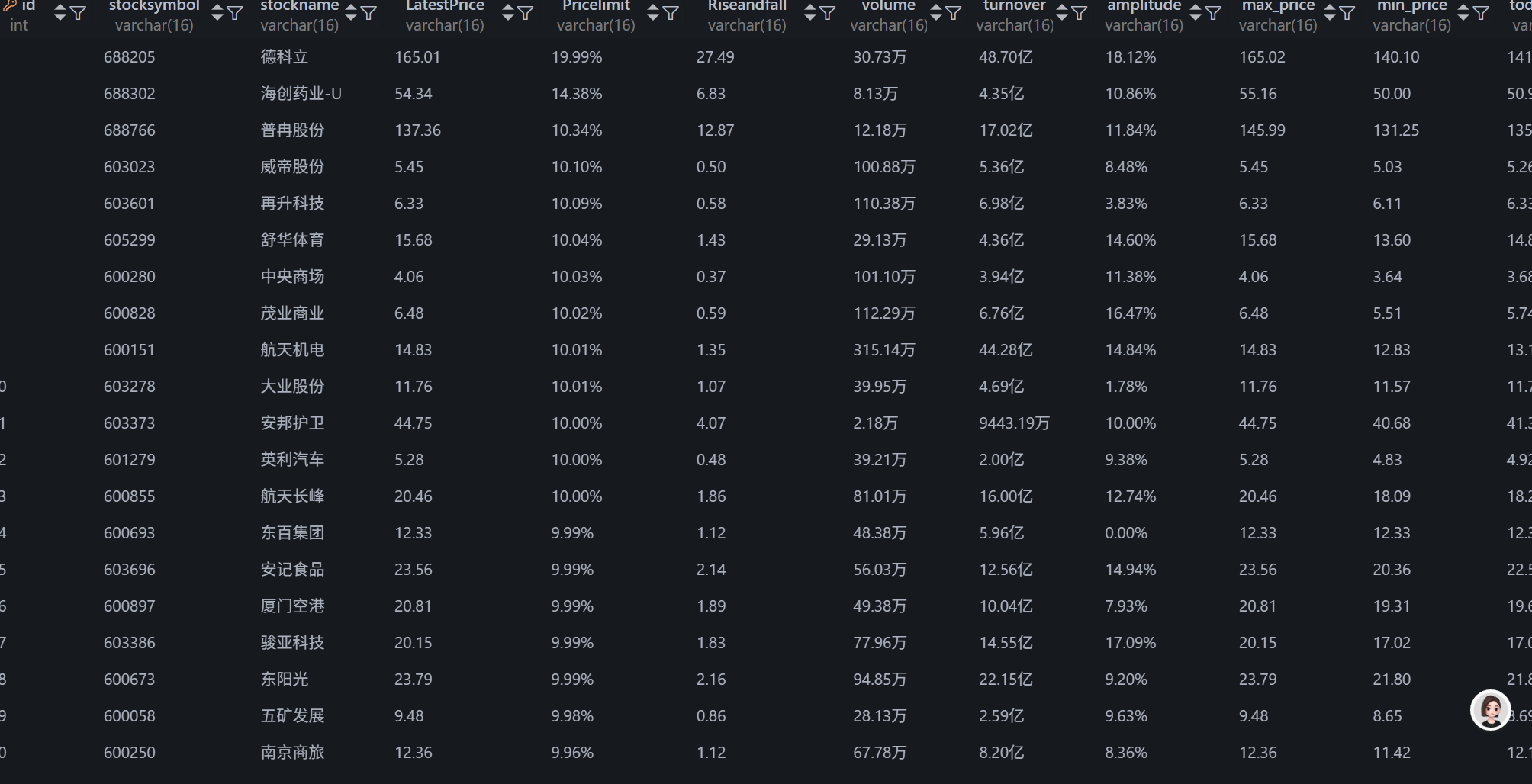
shenzhengagu
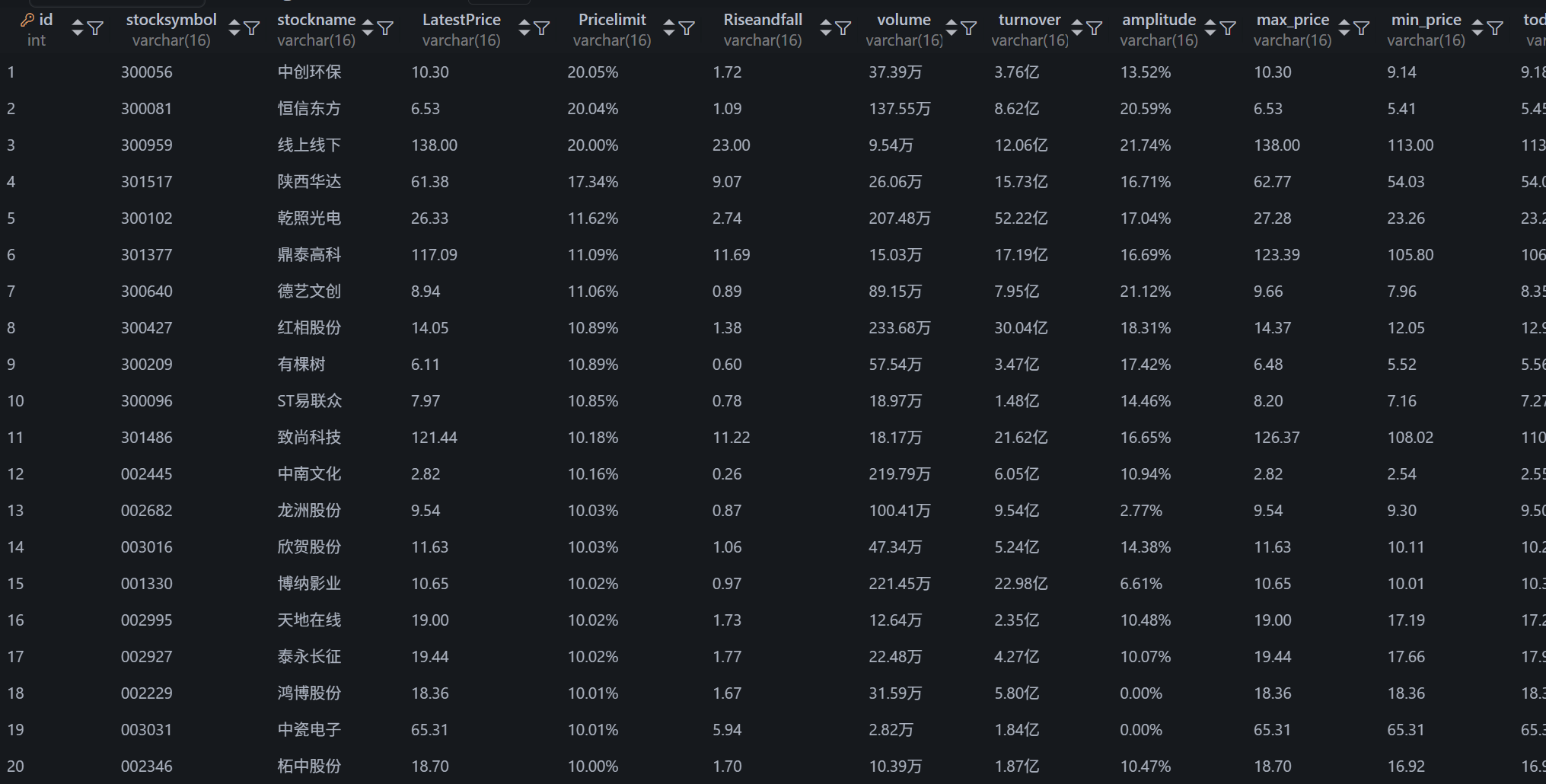
(2)心得体会:
重点在于通过 XPath 精确定位元素,并对网络延迟进行处理,确保页面数据的完整性。通过 cursor.execute 方法将数据存储到 MySQL 数据库中,加深了我对数据库操作的理解。
代码仓库:
https://gitee.com/oozyt/datacollecting/blob/master/作业4/stock.py
作业2
o 要求:熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
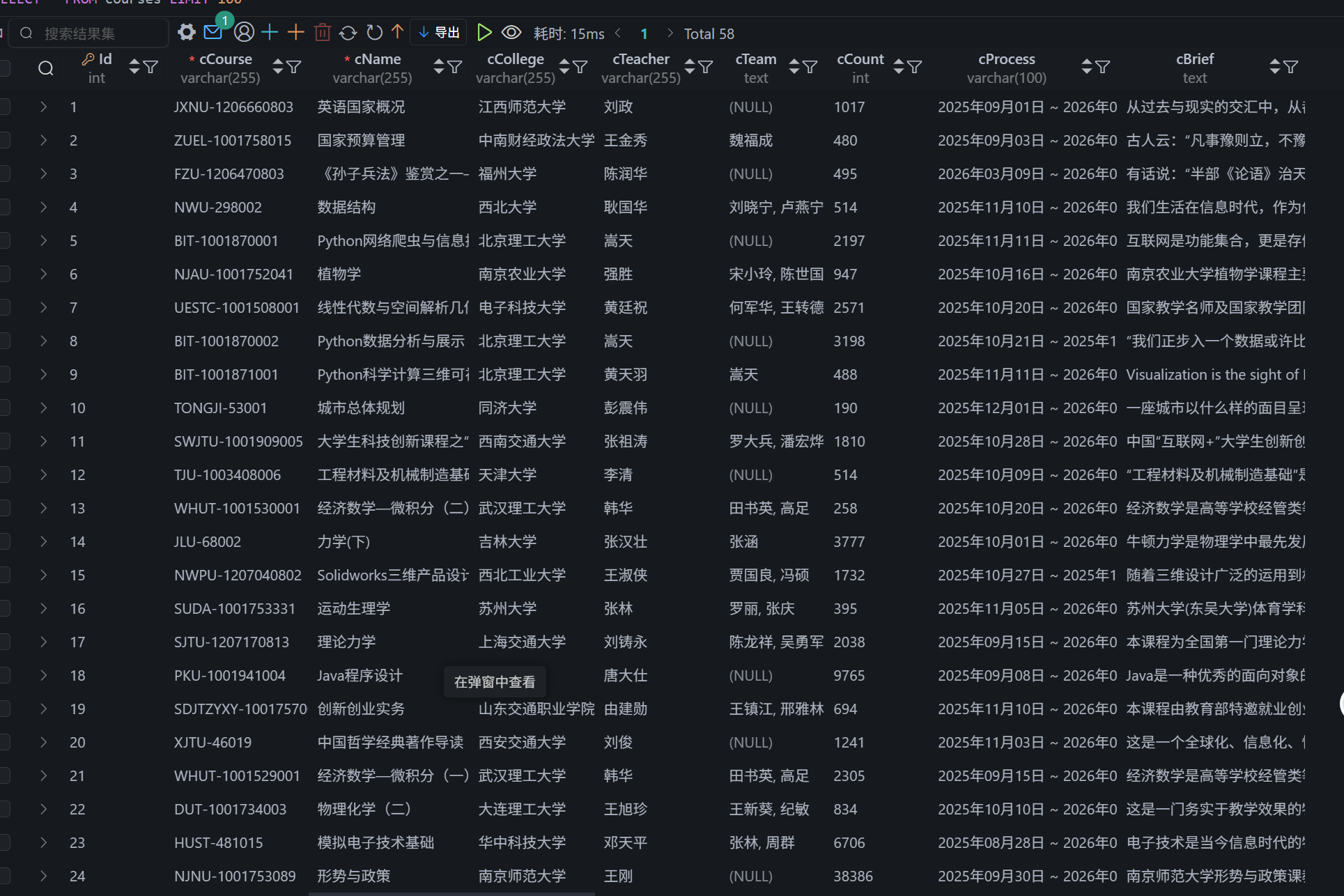
等待 HTML 元素等内容。 使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
o 候选网站:中国 mooc 网:https://www.icourse163.org
(1)实验步骤
1.登录操作
点击登录按钮
# 点击登录/注册按钮
wait.until(EC.element_to_be_clickable((By.XPATH, "//div[text()='登录/注册']"))).click()
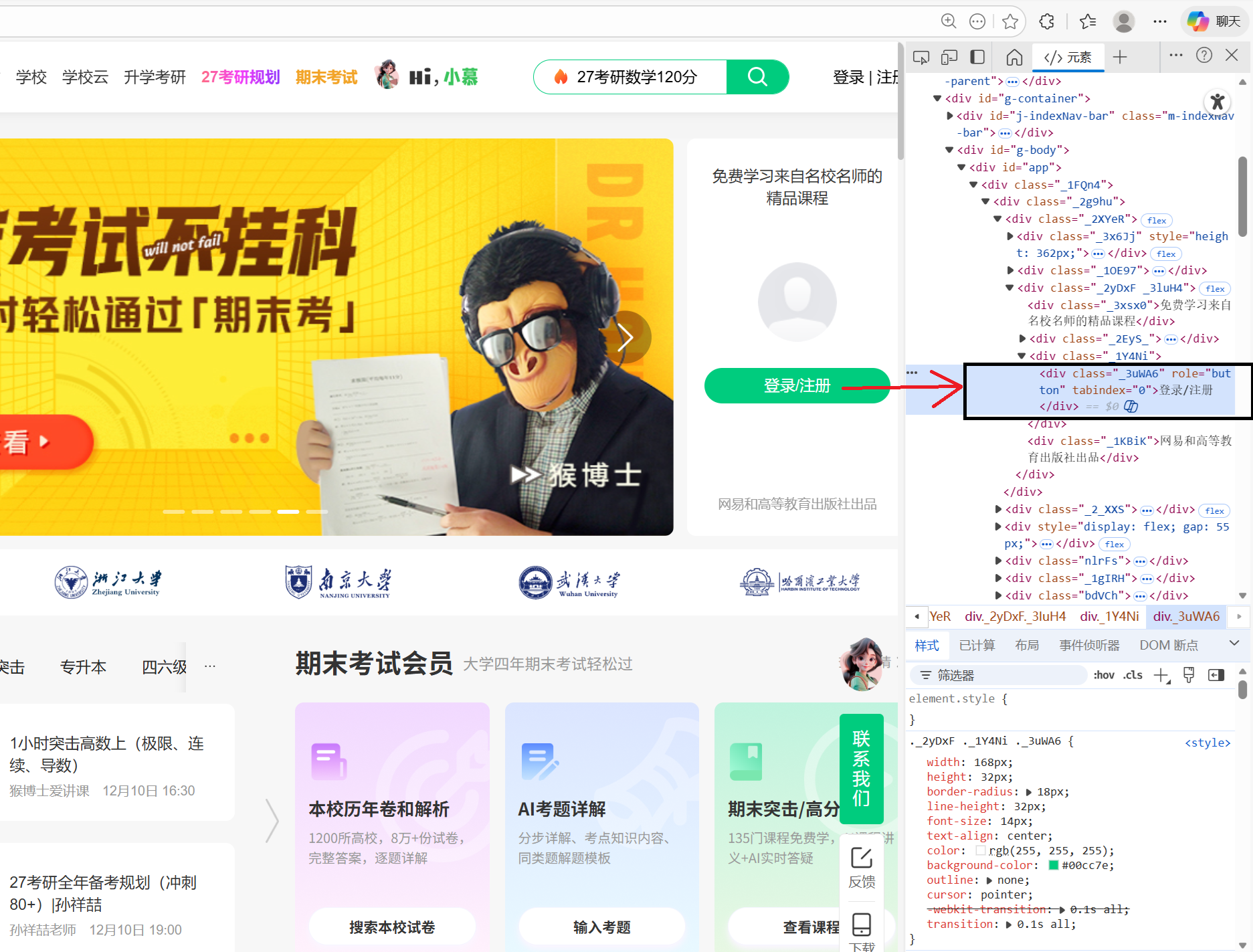
切换到登录iframe
切换到登录页面中的 iframe。登录表单位于 iframe 内,因此在输入凭据之前需要切换上下文。frame_to_be_available_and_switch_to_it 检查该 iframe 是否可用,并自动切换到这个 iframe。
# 切换到登录iframe
wait.until(EC.frame_to_be_available_and_switch_to_it((By.XPATH, "//iframe[contains(@id, 'x-URS-iframe')]")))
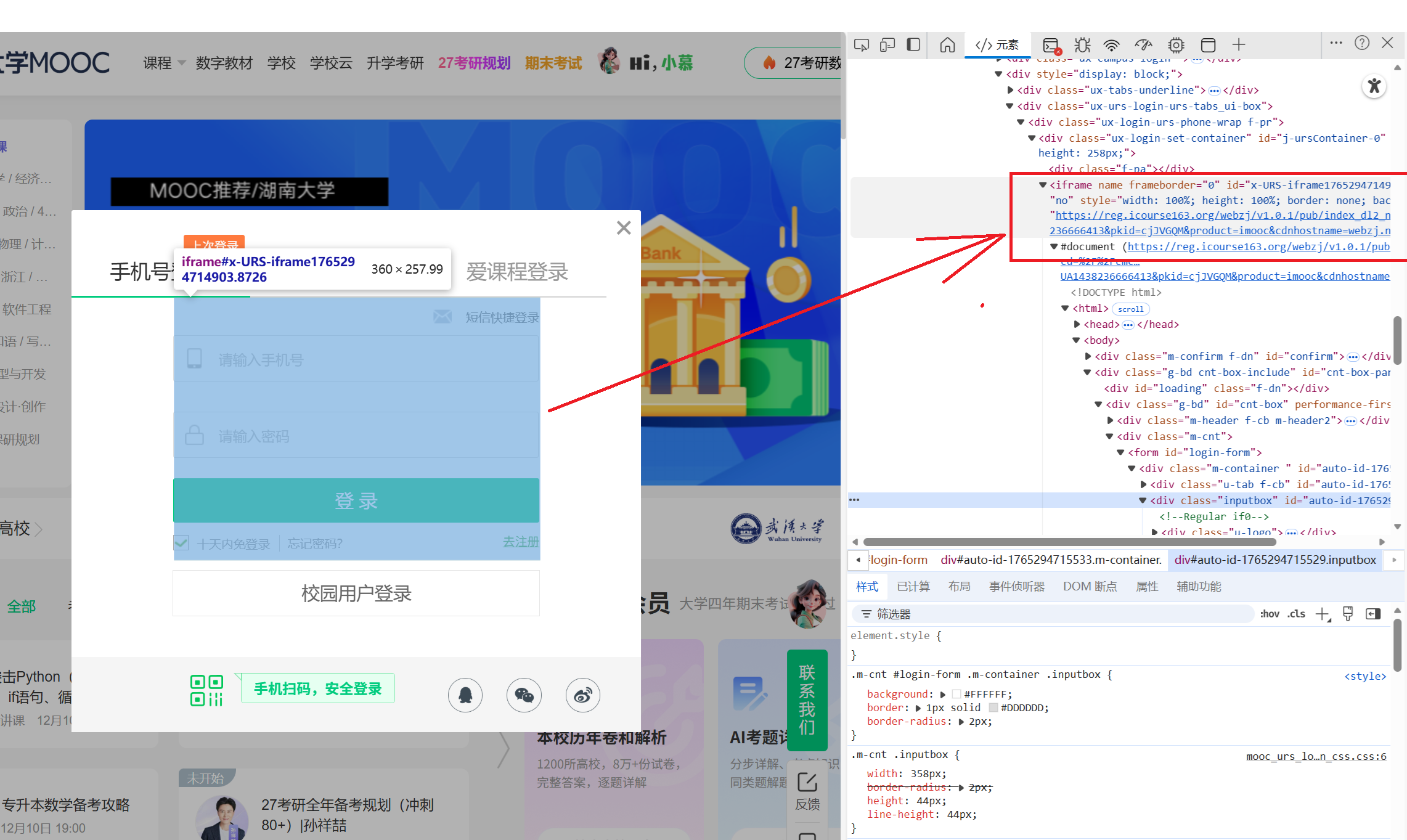
输入用户名和密码并点击登录按钮
# 输入用户名和密码
username_input = wait.until(EC.presence_of_element_located((By.XPATH, "//input[@placeholder='请输入手机号' or @placeholder='请输入邮箱帐号']")))
password_input = driver.find_element(By.XPATH, "//input[@placeholder='请输入密码']")
username_input.send_keys(MOOC_USERNAME); password_input.send_keys(MOOC_PASSWORD)
# 点击登录按钮
driver.find_element(By.XPATH, "//a[@id='submitBtn']").click()
检查登录状态
利用登录后出现的个人中心定位
wait.until(EC.presence_of_element_located((By.XPATH, "//a[text()='个人中心']"))); print("登录成功!"); return True
2.搜索操作
定位搜索框
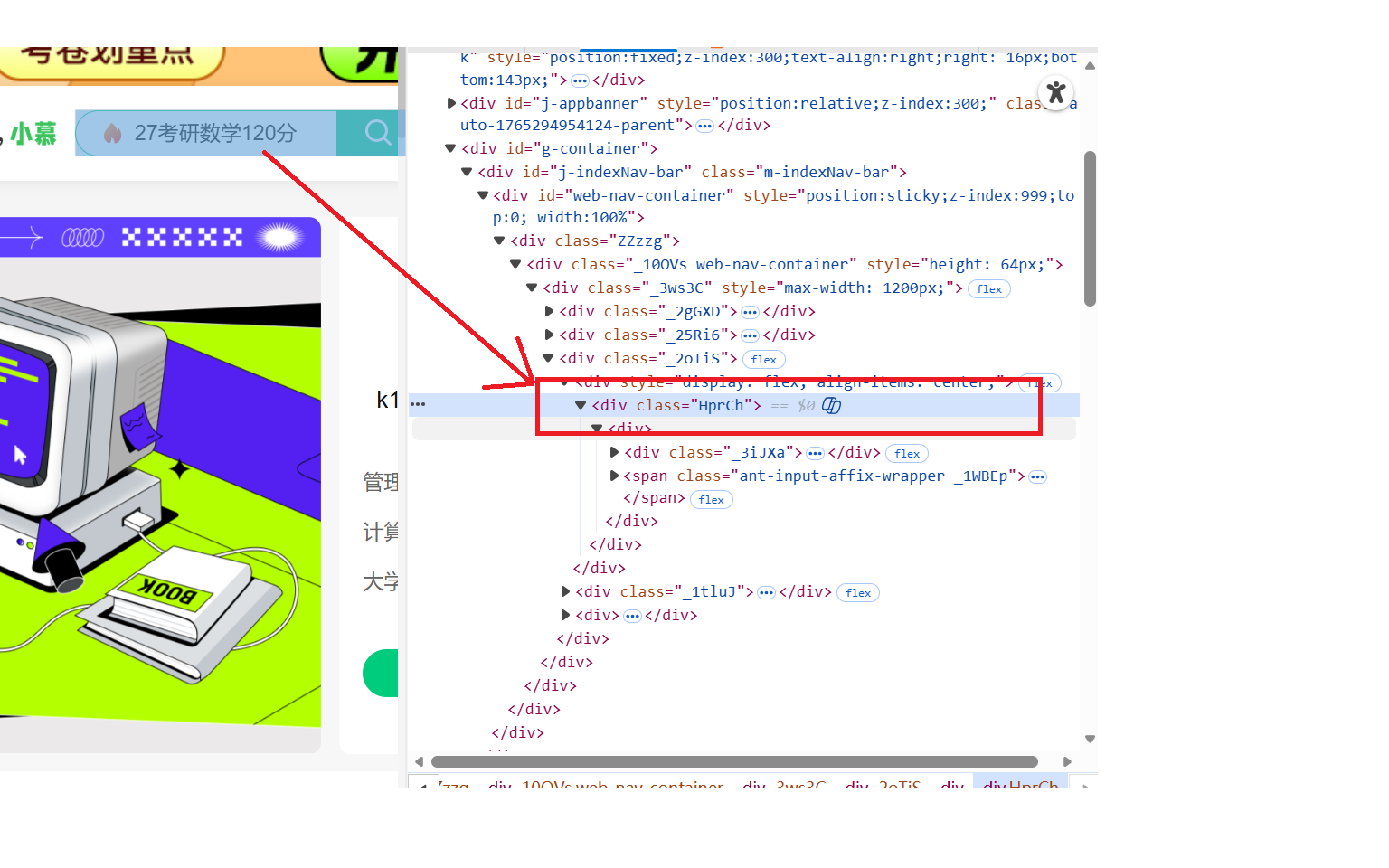
点击元素定位到搜索框检查元素并提供xpath定位
search_box = wait.until(EC.presence_of_element_located((By.XPATH, "//div[contains(@class, 'HprCh')]//input"))) # 定位搜索框
search_box.send_keys(SEARCH_KEYWORD); # 输入关键词
search_icon = wait.until(EC.element_to_be_clickable((By.XPATH, "//div[contains(@class, 'HprCh')]//span[contains(@class, 'E3Zsq')]")));
search_icon.click(); # 点击搜索按钮
点击筛选框
由于直接搜索容易出现考研等宣传报名类课程,且很多要爬取信息字段没有,所有我在搜索之后进一步点击筛选框优化爬虫效率
filter_checkbox = wait.until(EC.element_to_be_clickable((By.XPATH, "//label[contains(., '国家精品课')]")));
driver.execute_script("arguments[0].click();", filter_checkbox); # 点击“国家精品课”筛选
点击课程卡片
开始我是使用js点击课程卡片,发现容易发生误触,跳转到了讲师界面。查看网页元素之后,直接定位到课程标题,不容易发生误触
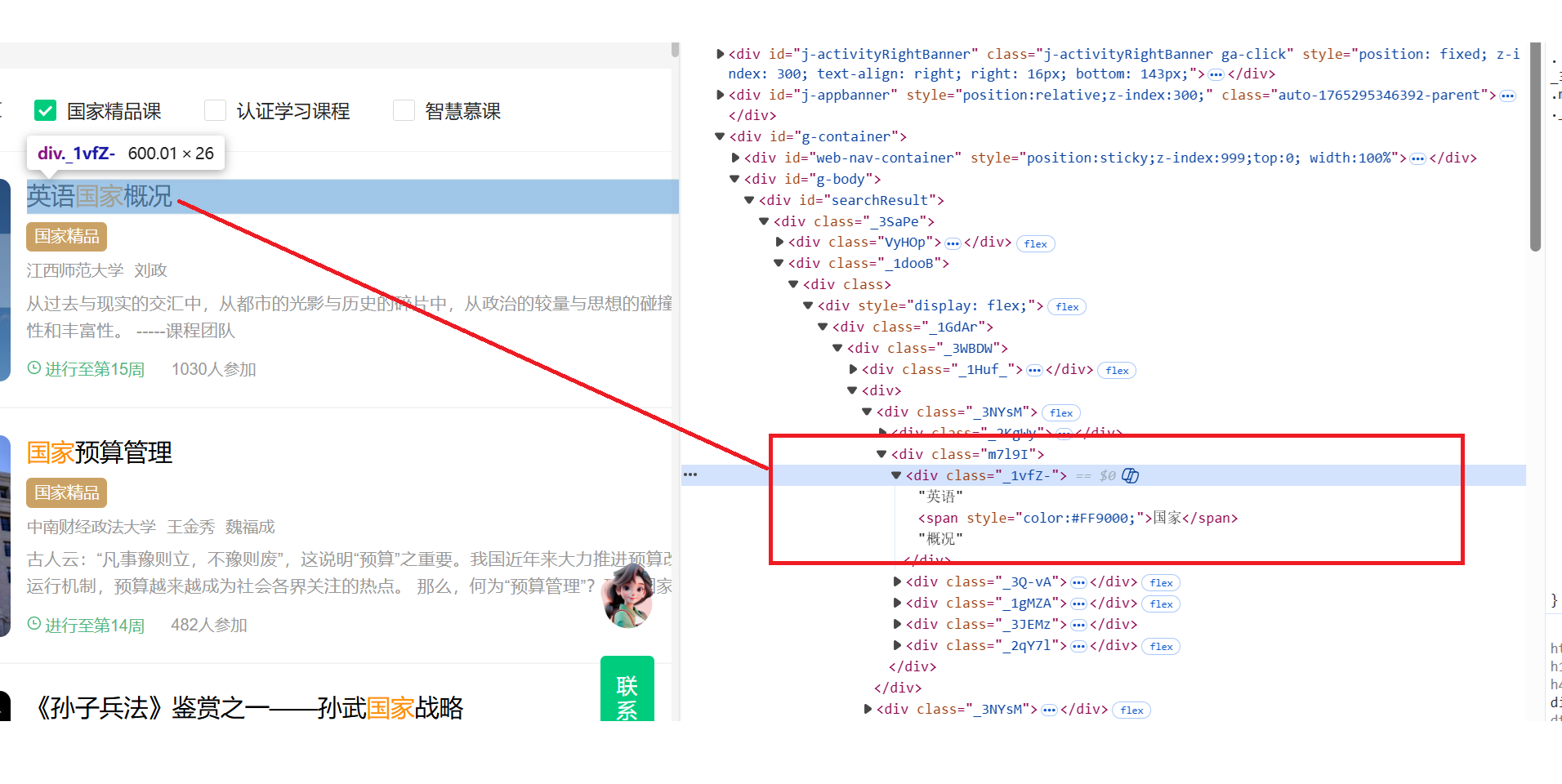
for i in range(len(all_cards_on_page)): # 遍历每张卡片
original_window = driver.current_window_handle # 记录当前窗口句柄
try:
all_cards = driver.find_elements(By.XPATH, "//div[contains(@class, '_3NYsM')]") # 重新获取卡片,避免StaleElementReferenceException
if i >= len(all_cards): continue
card_to_click = all_cards[i]
driver.execute_script("arguments[0].scrollIntoView({block: 'center'});", card_to_click); # 滚动到卡片
time.sleep(0.5);
# 精确点击课程标题div,避免误触
try:
course_title_div = card_to_click.find_element(By.XPATH, ".//div[contains(@class, '_1vfZ-')]") # 定位课程标题
driver.execute_script("arguments[0].click();", course_title_div) # 使用JS点击
except NoSuchElementException:
print(f" 第{page_num}页第{i+1}门课程未找到课程标题div,尝试点击整个卡片。")
card_to_click.click() # 未找到标题则点击整个卡片
3.爬取操作
进入课程详情页,定位到每一个需要爬取的信息,复制xpath,例如:
课程名字cName字段
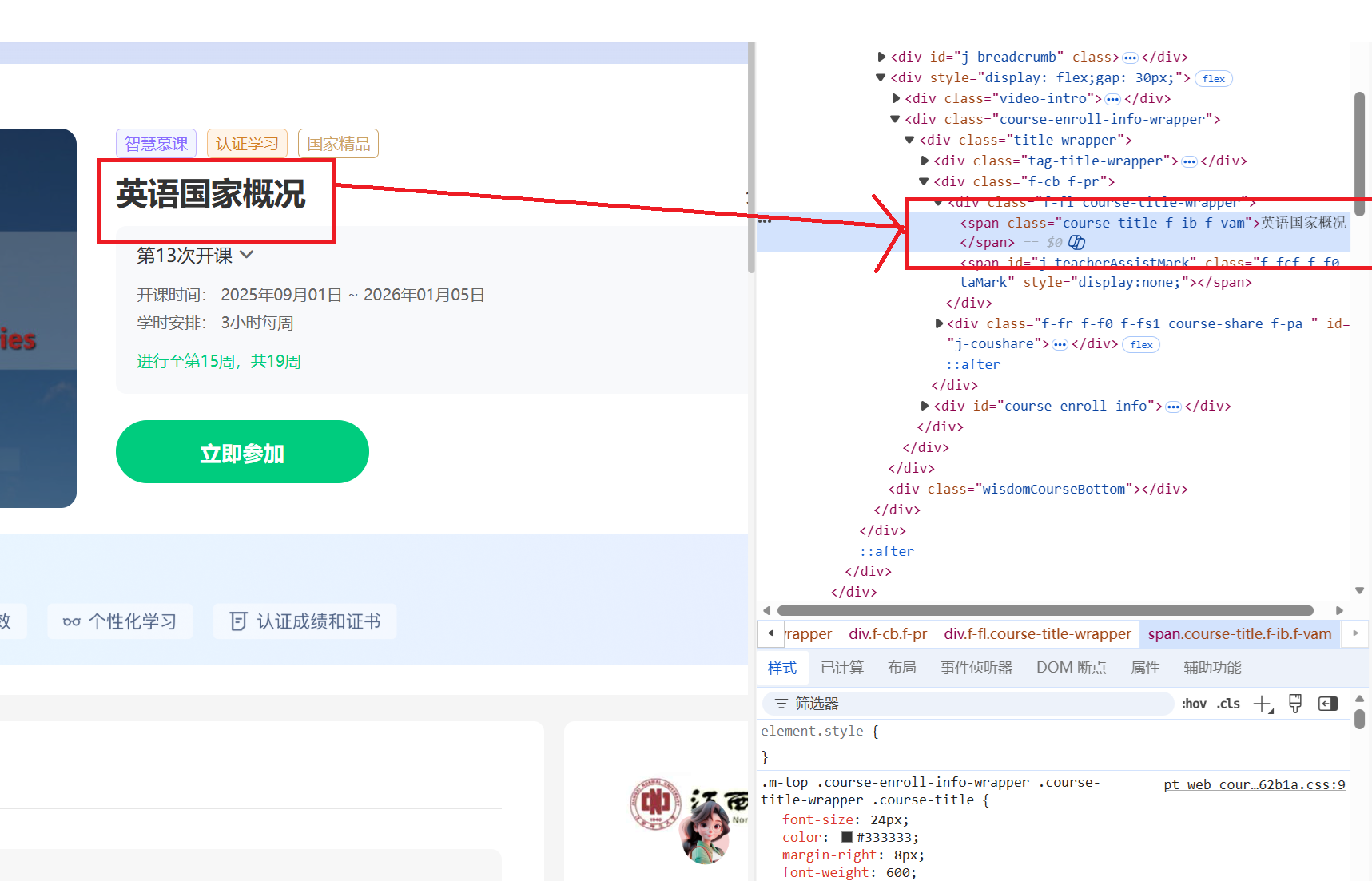
课程进度cProcess字段
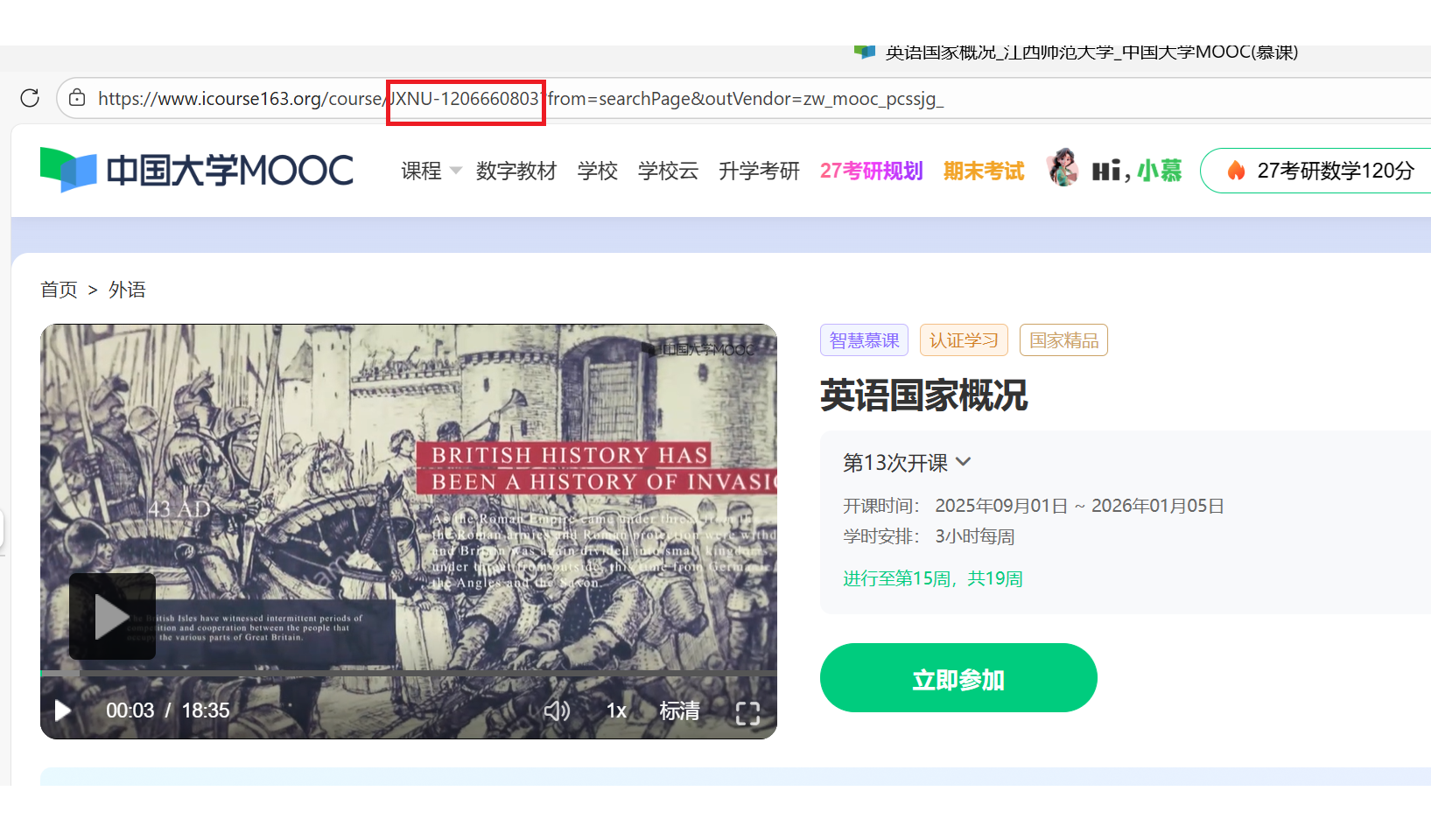
特别注意的是课程号不出现在课程详情页面上,而是出现在链接的url中
完整的数据抓取函数
def scrape_course_details(driver, wait):
time.sleep(4)
data = {}
# 从URL提取课程ID
try: data['course_id'] = re.search(r'course/([A-Z0-9a-z_-]+)', driver.current_url).group(1)
except: data['course_id'] = "N/A"
# 获取课程名称
locators_name = [{'by': By.XPATH, 'value': "//span[contains(@class, 'course-title')]"}, {'by': By.XPATH, 'value': "//div[@class='title']/span"} ]
data['course_name'] = get_text_with_fallbacks(driver, locators_name)
if not data['course_name']: return None
# 获取学校名称
try: data['school_name'] = driver.find_element(By.XPATH, "//a[contains(@class, 'm-teachers_school-img')]").get_attribute('data-label').split('-')[-1]
except: data['school_name'] = get_text_with_fallbacks(driver, [{'by': By.XPATH, 'value': "//div[contains(@class, 'course-teacher-i')]//div[@class='name']"}])
# 获取参加人数
locators_participants = [{'by': By.XPATH, 'value': "//span[@class='count']"}, {'by': By.XPATH, 'value': "//span[contains(text(), '人参加')]"}, {'by': By.XPATH, 'value': "//span[contains(text(), '人报名')]"} ]
participants_text = get_text_with_fallbacks(driver, locators_participants)
if participants_text:
try: data['participant_count'] = int(re.search(r'(\d+)', participants_text.replace(',', '')).group(1))
except: data['participant_count'] = 0
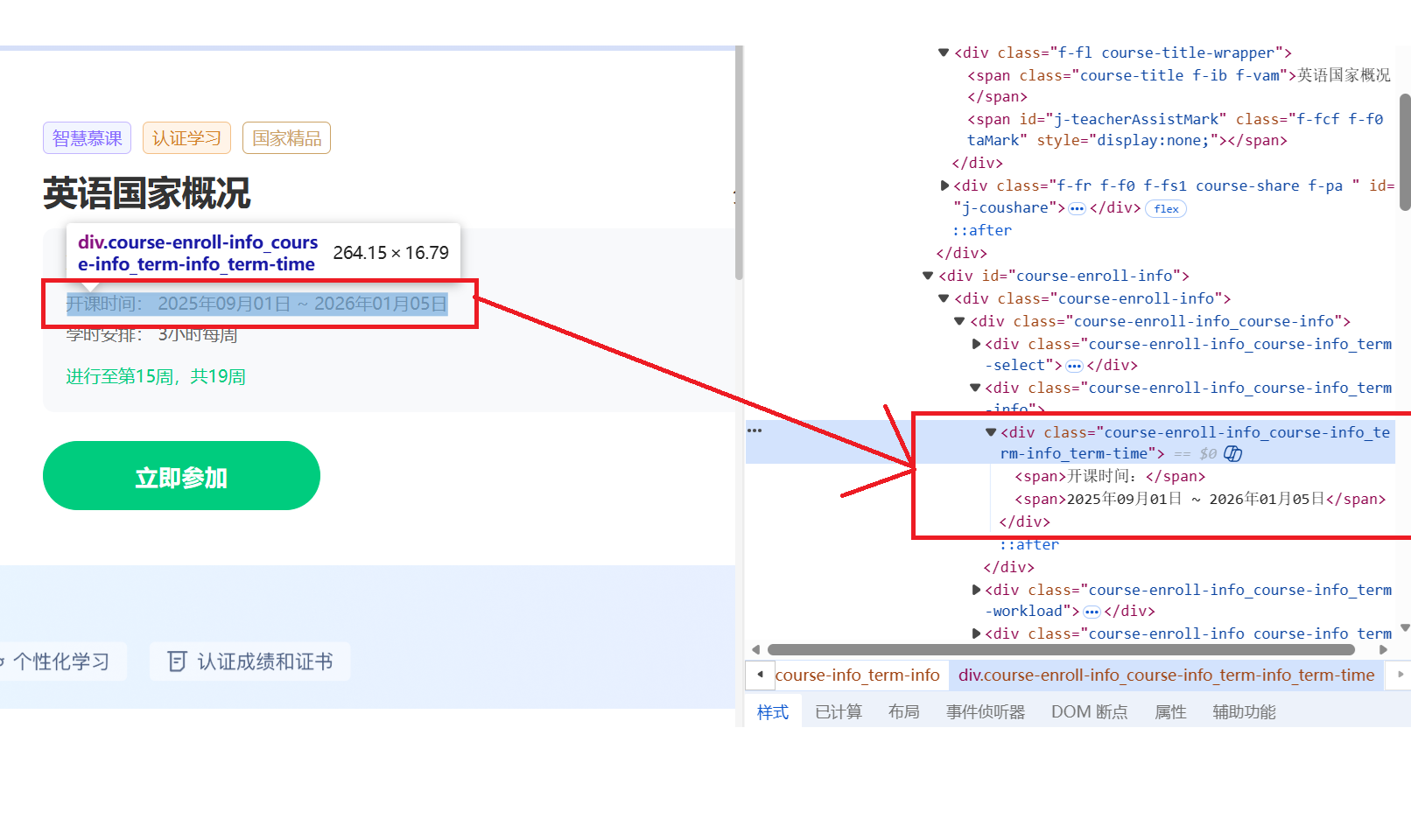
# 获取课程进度/开课时间
locators_process = [
{'by': By.XPATH, 'value': "//div[@class='course-enroll-info_course-info_term-info']//span[contains(text(), '开课时间')]/following-sibling::span"},
{'by': By.XPATH, 'value': "//div[contains(@class, 'ux-dropdown_hd')]"},
{'by': By.XPATH, 'value': "//div[contains(@class, 'state-tag')]"}
]
data['course_status'] = get_text_with_fallbacks(driver, locators_process)
# 获取课程简介
locators_intro = [{'by': By.ID, 'value': "j-rectxt2"}, {'by': By.ID, 'value': "j-rect-intro"} ]
data['course_intro'] = get_text_with_fallbacks(driver, locators_intro)
# 获取教师信息 (主讲教师和团队成员)
try:
teacher_cards = driver.find_elements(By.XPATH, "//div[contains(@class, 'u-tchcard')]")
teacher_names = [card.find_element(By.TAG_NAME, 'h3').text for card in teacher_cards if card.find_element(By.TAG_NAME, 'h3').text]
data['main_teacher'] = teacher_names[0] if teacher_names else None
data['team_members'] = ', '.join(teacher_names[1:]) if len(teacher_names) > 1 else None
except: data['main_teacher'], data['team_members'] = None, None
if not data.get('main_teacher'):
data['main_teacher'] = get_text_with_fallbacks(driver, [{'by': By.XPATH, 'value': "//div[contains(@class, 'course-teacher-i')]//div[@class='name']"}])
return data
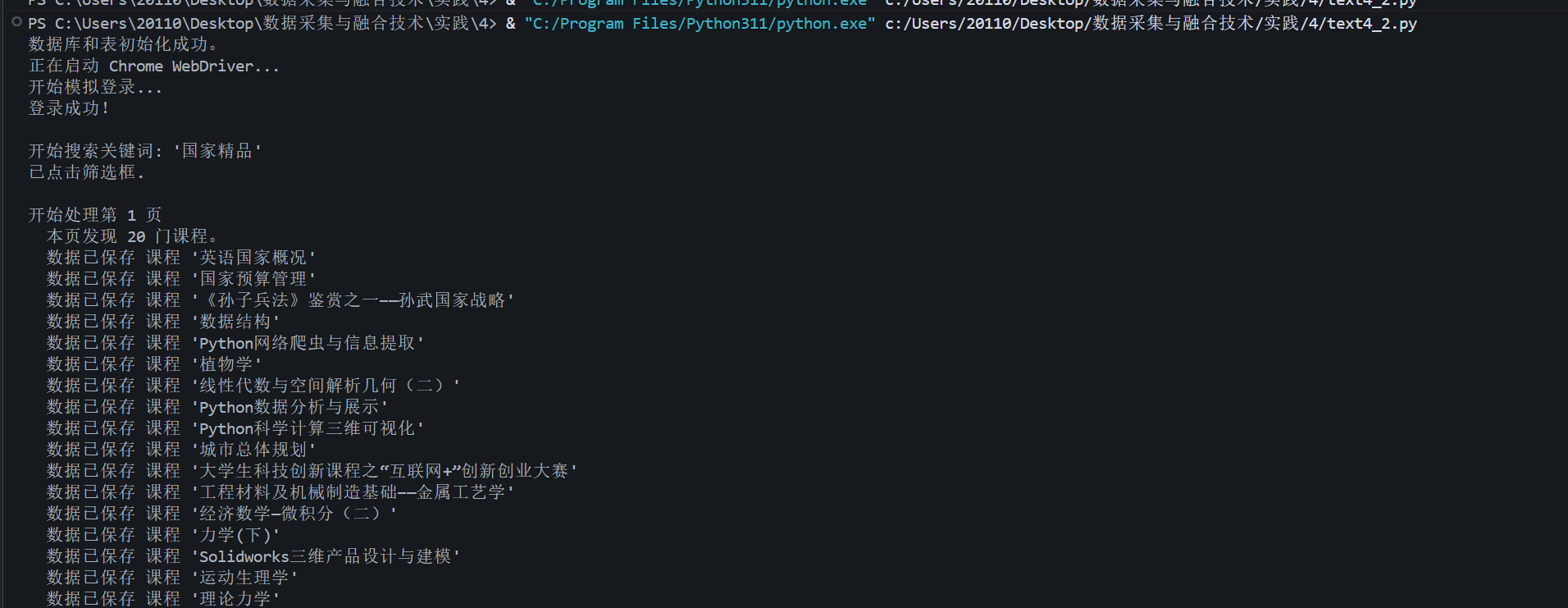
输出信息:
终端输出信息
MYSQL数据库
(2)心得体会:
模拟登录流程感受到真实用户交互中的复杂性。这里需要考虑可能出现的弹窗,以及不同的 iframe。在 try-except 结构中有效地处理了可能的异常情况,确保了脚本的稳定性。使用xpath定位各爬取字段,加深了我对其的熟练程度与理解运用。
代码仓库:
https://gitee.com/oozyt/datacollecting/blob/master/作业4/mooc.py
作业③:
要求: 掌握大数据相关服务,熟悉 Xshell 的使用 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档
环境搭建:任务一:开通 MapReduce 服务
实时分析开发实战:
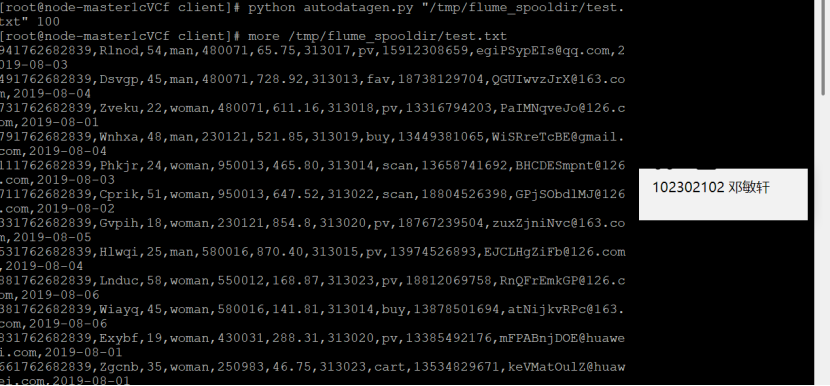
任务一:Python 脚本生成测试数据
执行Python命令,测试生成100条数据

任务二:配置 Kafka
在kafka中创建topic
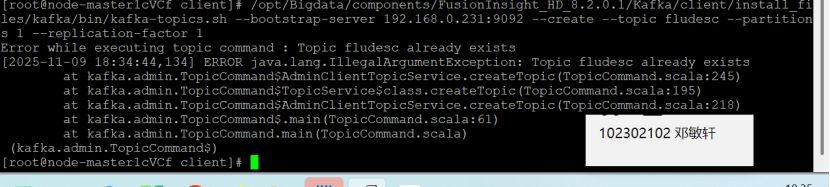
查看topic信息

任务三: 安装 Flume 客户端
下载flume客户端
提示:客户端生成成功,保存在服务器(192.168.0.155)如下路径:/tmp/FusionInsight-Client/FusionInsight_Cluster_1_Flume_Client.tar
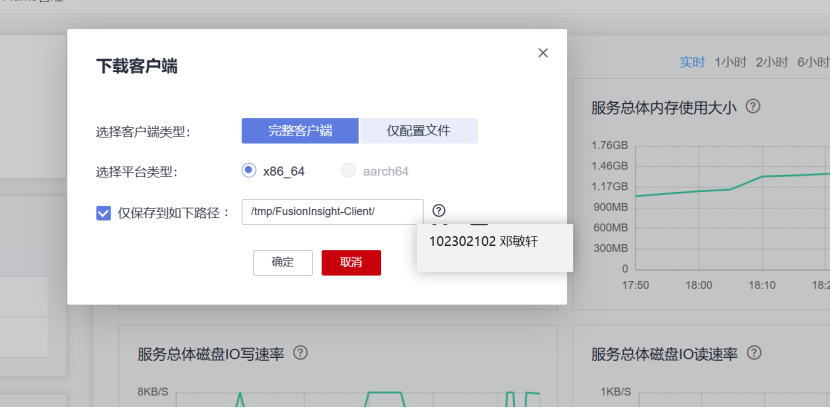
校验下载的客户端文件包


安装Flume运行环境

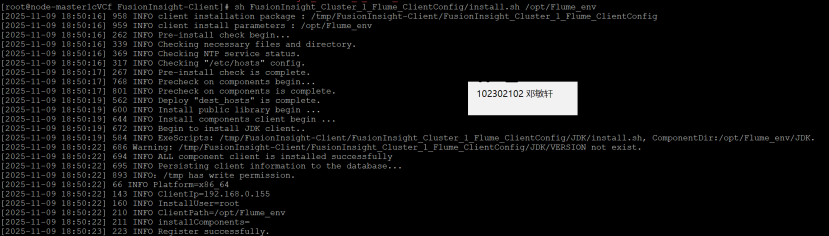
执行安装脚本

服务重启成功

任务四:配置 Flume 采集数据
修改配置文件并创建消费者消费kafka中的数据

新开一个PuTTY会话窗口,进入Python脚本所在目录,执行python脚本,再生成一份数据。
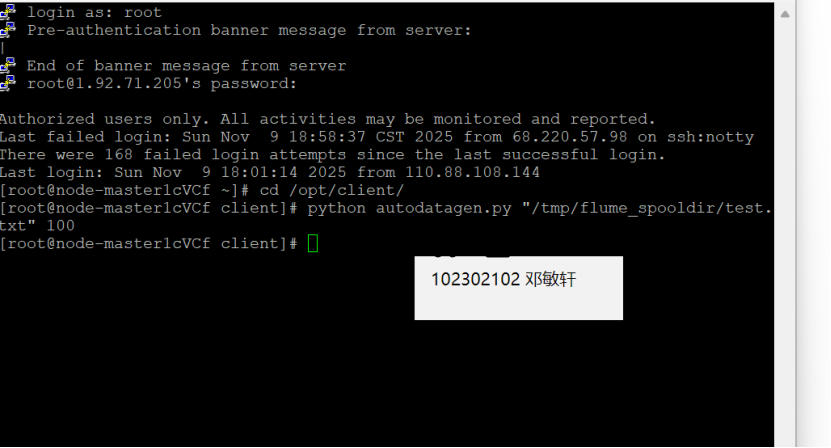
原窗口已经消费出了数据:

心得体会:
在这个实验中,通过使用大数据工具(如 Flume 和 Kafka)进行数据流的处理,让我对大数据的架构有了初步的认识。环境的搭建与配置让我意识到,数据采集和分析流程的复杂性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号