
智能客服不是问答机器人,微调更不是“多训点数据”
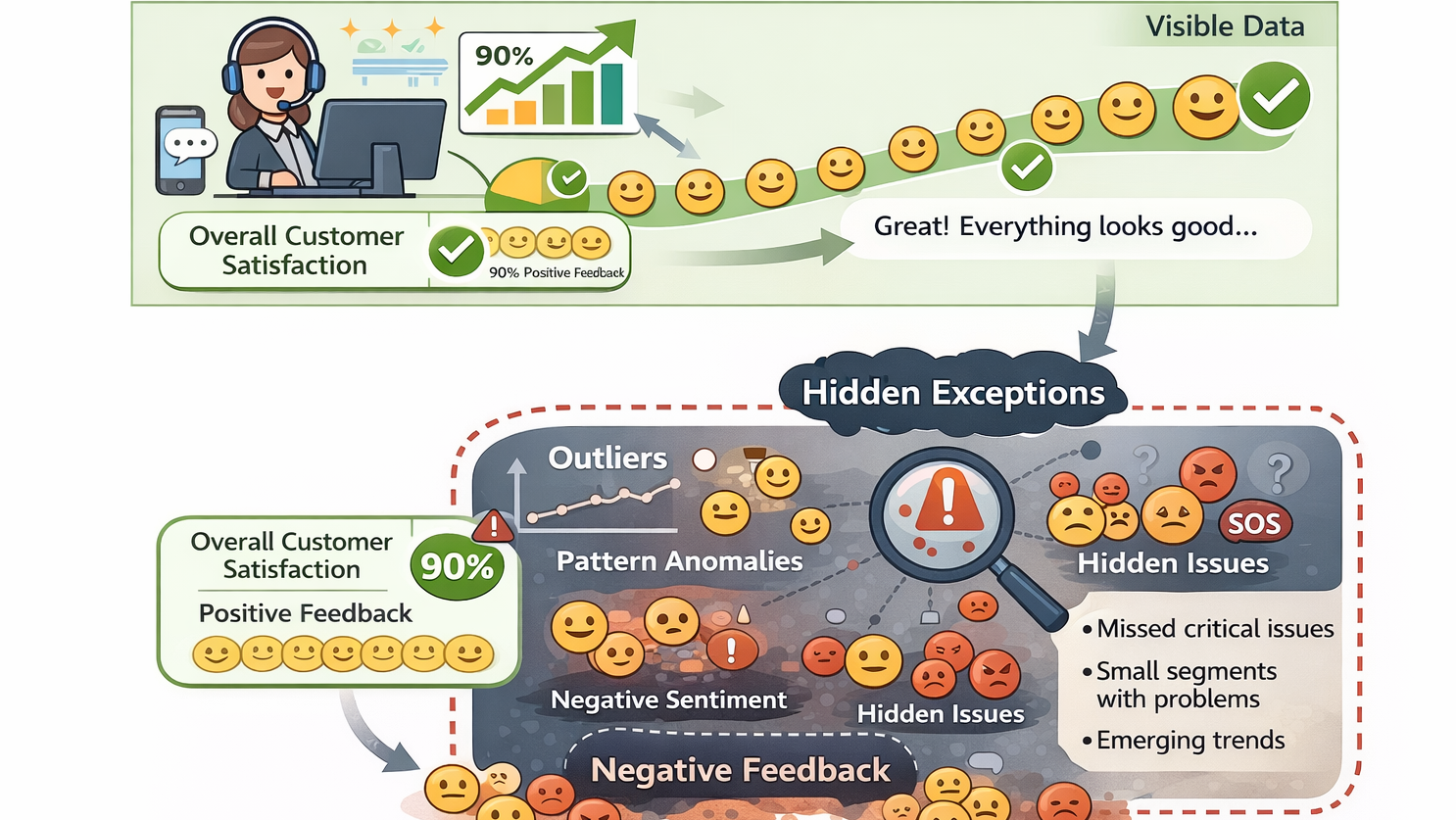 智能客服失败常因误将“问答机器人”当“服务处理器”。其核心不在答对,而在判断:是否该答、答到哪、何时转人工、如何安抚。微调非万能,仅适用于稳定风格、固化明确规则、强化安全拒答三类场景;知识更新、动态状态、争议判断等问题,应交由RAG或规则系统处理。
智能客服失败常因误将“问答机器人”当“服务处理器”。其核心不在答对,而在判断:是否该答、答到哪、何时转人工、如何安抚。微调非万能,仅适用于稳定风格、固化明确规则、强化安全拒答三类场景;知识更新、动态状态、争议判断等问题,应交由RAG或规则系统处理。
大多数“智能客服失败”,不是模型不行,而是期望错了
如果你做过或接触过智能客服项目,大概率会经历一个相似的心理过程:
一开始觉得:
“现在大模型这么强,客服这种问答场景,不是正好对口吗?”
然后你会很快发现现实是:
- 问题很杂
- 规则很多
- 灰度极多
- 一句话答错,后果可能很严重
最后,团队往往会把希望寄托在一件事上:
“那我们给模型微调一下吧。”
而真正的问题是——
你往往是在还没想清楚“客服到底在干什么”的情况下,就开始微调了。
一个必须先说清楚的事实:智能客服 ≠ 问答机器人
这是所有判断的起点。
问答机器人解决的是:
“我问一个问题,你给我一个答案。”
而智能客服解决的,其实是:
- 是否该回答
- 回答到什么程度
- 是否要引导用户
- 是否需要转人工
- 是否要安抚情绪
- 是否要遵守规则优先级
换句话说,客服的核心不是“答对”,而是“处理得当”。
这也是为什么,很多“看起来很聪明”的模型,一放进客服系统就开始出问题。
为什么客服场景天然容易“被微调冲坏”
客服是一个高约束、低容错、强边界的场景。
这意味着三件事:
- 输出不能随意发挥
- 行为不能前后不一致
- 边界问题比正确答案更重要
而微调,尤其是不加区分地微调,本质上是在做一件事:
把历史行为固化进模型。
如果你不非常清楚“哪些行为是好行为”,
那微调只会把历史系统的混乱,永久写进模型参数里。
智能客服里,最容易被拿去微调、但风险最高的数据
这是一个必须说清楚的话题。
在客服项目里,最容易被认为“很宝贵”的数据,往往是:
- 历史真实对话
- 人工客服的回复记录
- 运营总结的标准话术
但这些数据里,隐藏着非常多的雷:
- 人工客服有大量“临场判断”和“例外处理”
- 同一问题,不同客服给过不同尺度的回答
- 有些回复只是为了“先安抚用户”,并不是真正的规则解答
如果你把这些数据直接拿去做 SFT 或 PPO 微调,
模型学到的往往不是“规范行为”,而是人类的随意性。
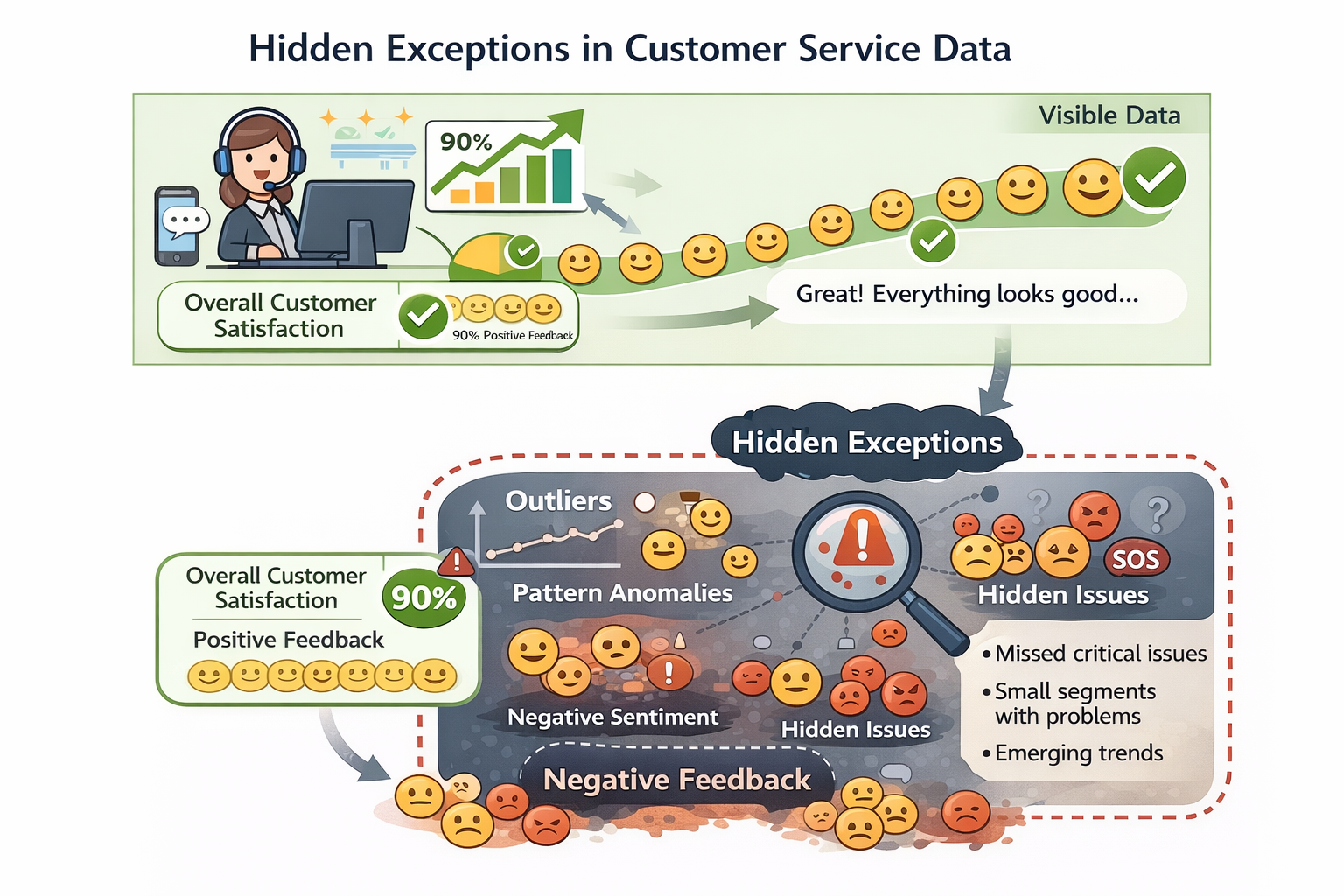
客服数据中的“隐性例外”示意图
微调在客服系统中,真正“适合做”的三类事情
说清楚风险之后,我们再来讲微调的正向价值。
在客服场景里,微调并不是没用,
但它只能用在非常有限、非常明确的目标上。
第一类:稳定输出风格,而不是扩展知识
客服大模型最常见的问题之一是:
同一问题,不同时间回答风格不一致。
比如:
- 有时很官方
- 有时很随意
- 有时解释很多
- 有时一句话打发
这种不一致,会极大降低用户信任感。
在这种情况下,微调的目标不是“教模型新知识”,
而是:
在模型已经会回答的前提下,
固定它的表达方式和语气边界。
这类微调,风险相对可控,收益也比较明确。
第二类:高频、规则明确、几乎没有灰度的问题
比如:
- 发票怎么开
- 退款流程是什么
- 工单状态怎么查
这类问题的特点是:
- 答案相对固定
- 规则来源明确
- 例外情况少
如果你已经通过 RAG 或规则验证了答案的正确性,
再用微调去减少模型胡乱发挥的概率,是合理的。
但这里的关键词是:
减少发挥,而不是增加发挥。
第三类:安全拒答与转人工的“行为倾向”
在客服系统里,有一类问题不是“答什么”,而是:
- 要不要答
- 要不要转人工
- 要不要先安抚
这些行为,很难通过规则完全覆盖,
但人类在对比多个回复时,往往很容易选出“更合适的”。
这正是 PPO / DPO 类微调在客服场景里最有价值的地方。
你不是在教模型规则,
而是在教它:
什么情况下该收手。
智能客服里,哪些问题“不该”通过微调解决
这一部分,比“该做什么”更重要。
不该微调的第一类:知识经常变的问题
比如:
- 活动规则
- 临时政策
- 地域差异条款
这类问题,如果用微调,一定会遇到:
- 更新慢
- 回滚难
- 历史版本混乱
RAG 或规则系统,几乎总是更好的选择。
不该微调的第二类:高度依赖上下文和状态的问题
比如:
- 用户当前工单状态
- 历史投诉记录
- 账户风险等级
这些信息,本来就不应该被“学进模型”,
而应该在推理时动态注入。
微调在这里,不但帮不上忙,还会制造安全隐患。
不该微调的第三类:本身就存在争议的业务判断
如果你的业务方自己都说不清楚:
- 这个问题到底该不该答
- 该答到什么程度
那你就不可能通过微调,把问题解决掉。
微调只会把“当前的不确定状态”固化。
一个真实的工程现象:客服模型越微调,越“像老客服”
这句话听起来像好事,但在工程里往往不是。
“老客服”的特点包括:
- 很多隐性规则
- 很多历史包袱
- 很多“看人下菜”的判断
这些特质,一旦被写进模型,就很难再统一收回。
所以在客服场景里,
微调不是让模型“像人”,而是让模型“像规范”。
一个客服微调项目,最容易忽略的评估维度
很多团队评估客服模型,只看:
- 命中率
- 满意度
但在微调之后,你更应该关注的是:
- 是否更容易越界
- 是否更难拒绝
- 是否更少转人工
- 是否在边界问题上变得自信
这些指标,一旦恶化,后果往往比“答不出来”更严重。
客服微调的一个健康技术组合(而不是单点押注)
在真实系统里,一个更健康的架构往往是:
- 规则系统:兜底红线
- RAG:提供事实和流程
- 微调模型:稳定行为风格
- 人工客服:处理灰度与例外
微调,永远不是主角,而是收敛器。
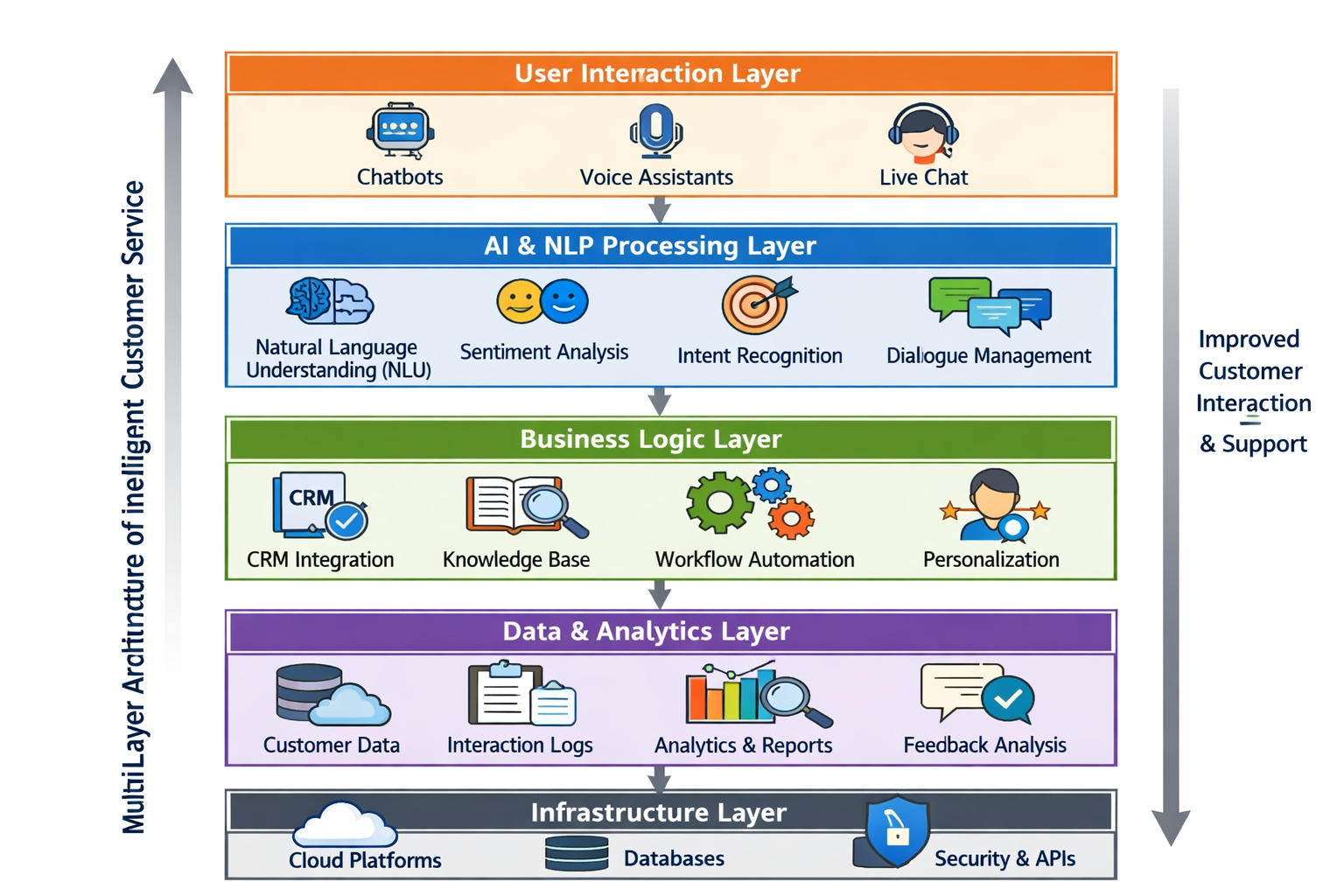
智能客服多层架构示意图
一个简单示意:客服 PPO 微调在干什么(非教学)
responses = policy.generate(prompt, n=3)
# 人工或规则选出“更合适的行为”
preferred = choose_best(responses)
# PPO 学的不是“答案”
# 而是:在客服场景下,哪种处理方式更稳妥
reward = compare(preferred, responses)
你会发现,这里根本没有“正确答案”的概念。
在客服场景下做微调,最难的往往不是训练,而是评估行为变化是否真的变“稳”了。用LLaMA-Factory online先对固定客服评估集跑小规模微调、对比不同 checkpoint 在拒答、转人工、安抚语气上的差异,比直接全量上线要安全得多,也更容易和业务方对齐预期。
总结:智能客服的微调,本质是一次“风险管理决策”
如果要给这篇文章一个真正的结论,那应该是这句话:
在智能客服里,你调的不是模型能力,
而是系统愿意承担的风险边界。
当你把微调当成“能力增强”,
它往往会反噬你;
当你把微调当成“行为收敛工具”,
它才会发挥真正的价值。
真正成熟的客服系统,从来不是“模型多强”,
而是在复杂、模糊、充满情绪的场景里,依然能稳住。
你选一个,我继续按这套标准写。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号