
PPO 微调的本质:它不是在教模型“更聪明”
 PPO微调本质是“行为选择”而非“知识学习”:它不教模型新能力,而是通过奖励信号与KL约束,在已有能力空间中重校输出概率分布,对齐人类偏好。核心只更新Policy,Reward引导方向,KL保障安全,专治风格、安全、边界问题。
PPO微调本质是“行为选择”而非“知识学习”:它不教模型新能力,而是通过奖励信号与KL约束,在已有能力空间中重校输出概率分布,对齐人类偏好。核心只更新Policy,Reward引导方向,KL保障安全,专治风格、安全、边界问题。
PPO 难,不是因为算法复杂,而是因为它在干一件反直觉的事
如果你第一次接触 PPO 微调,大概率会有一种强烈的挫败感。
你可能已经:
- 看过 PPO 的算法图
- 看过 reward / value / policy 的关系
- 甚至跑过一次训练
但只要你认真问自己一个问题:
“PPO 到底在改模型的哪一部分?”
你很可能说不清楚。
你只知道:
- reward 在涨
- loss 在变
- 输出风格在变化
但这些变化为什么会发生,
发生在模型的哪一层逻辑上,
你并没有一个“工程上能落地的解释”。
而这,正是 PPO 最容易被误解的地方。
一个必须先说清楚的前提:PPO 微调不是“能力学习”,而是“行为选择”
这是理解 PPO 的第一道门槛。
在 SFT(监督微调)里,模型学的是:
“在这个输入下,正确答案长这样。”
但 PPO 学的不是“正确答案”,
而是:
“在这个输入下,我更应该选择哪种回答方式。”
这是一个策略选择问题,而不是知识学习问题。
PPO 从来不关心模型“会不会”,
它关心的是:
模型在多个可能回答中,选哪个更好。
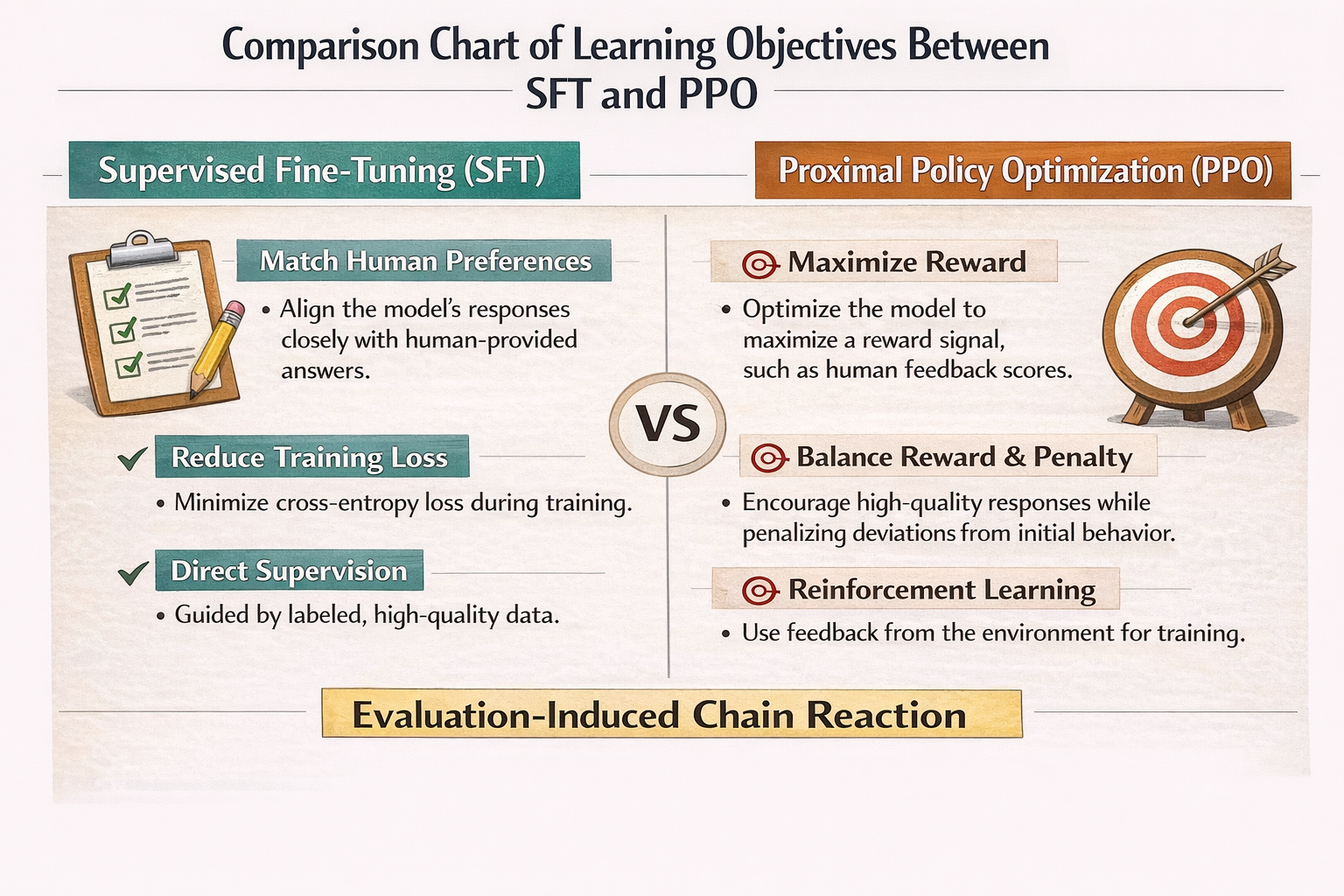
SFT vs PPO 学习目标对比图
为什么 PPO 一定要引入“奖励”,而不是直接算 loss
这是很多人第一次看 PPO 时最困惑的地方。
你会问:
既然已经有 loss,为什么还要 reward?
原因非常简单,但非常关键:
loss 只能衡量“像不像训练数据”,
reward 才能衡量“你想不想要这种行为”。
在 PPO 里,你想优化的往往是一些不可直接写成标签的东西:
- 回答是否谨慎
- 是否拒绝不该回答的问题
- 是否遵循偏好顺序
- 是否避免某类风险
这些东西,很难通过“正确答案”来定义,
但可以通过“好 / 不好”来判断。
于是,reward 出现了。
PPO 里的核心角色,其实只有一个:Policy(策略)
在 PPO 的论文图里,你会看到很多模块:
- Policy
- Reference
- Reward
- Value
但如果从工程视角看,
真正被更新的,只有 Policy。
Policy 本质上是什么?
就是你正在微调的那个模型。
其它模块,全部都是为了一件事服务的:
限制、引导、校正 Policy 的更新方向。
PPO 的核心问题:模型“想变”,但不能乱变
这是 PPO 名字里“Proximal”的真正含义。
PPO 要解决的问题,不是:
“怎么让模型变得更符合 reward”
而是:
“怎么让模型在不偏离原模型太远的情况下,
慢慢朝 reward 指向的方向移动”
为什么要这样?
因为在大模型里,一次“走太远”的更新,几乎一定会带来灾难性副作用。
KL 约束:PPO 里真正的“安全带”
很多人第一次看到 PPO,会觉得 KL 是个“技术细节”。
但在大模型微调里,
KL 约束是 PPO 能用的前提条件。
KL 在这里干的事情只有一件:
惩罚模型“和原来太不一样”。
你可以把它理解成:
- reward 在踩油门
- KL 在踩刹车
没有 reward,模型不知道往哪走;
没有 KL,模型会直接冲出赛道。
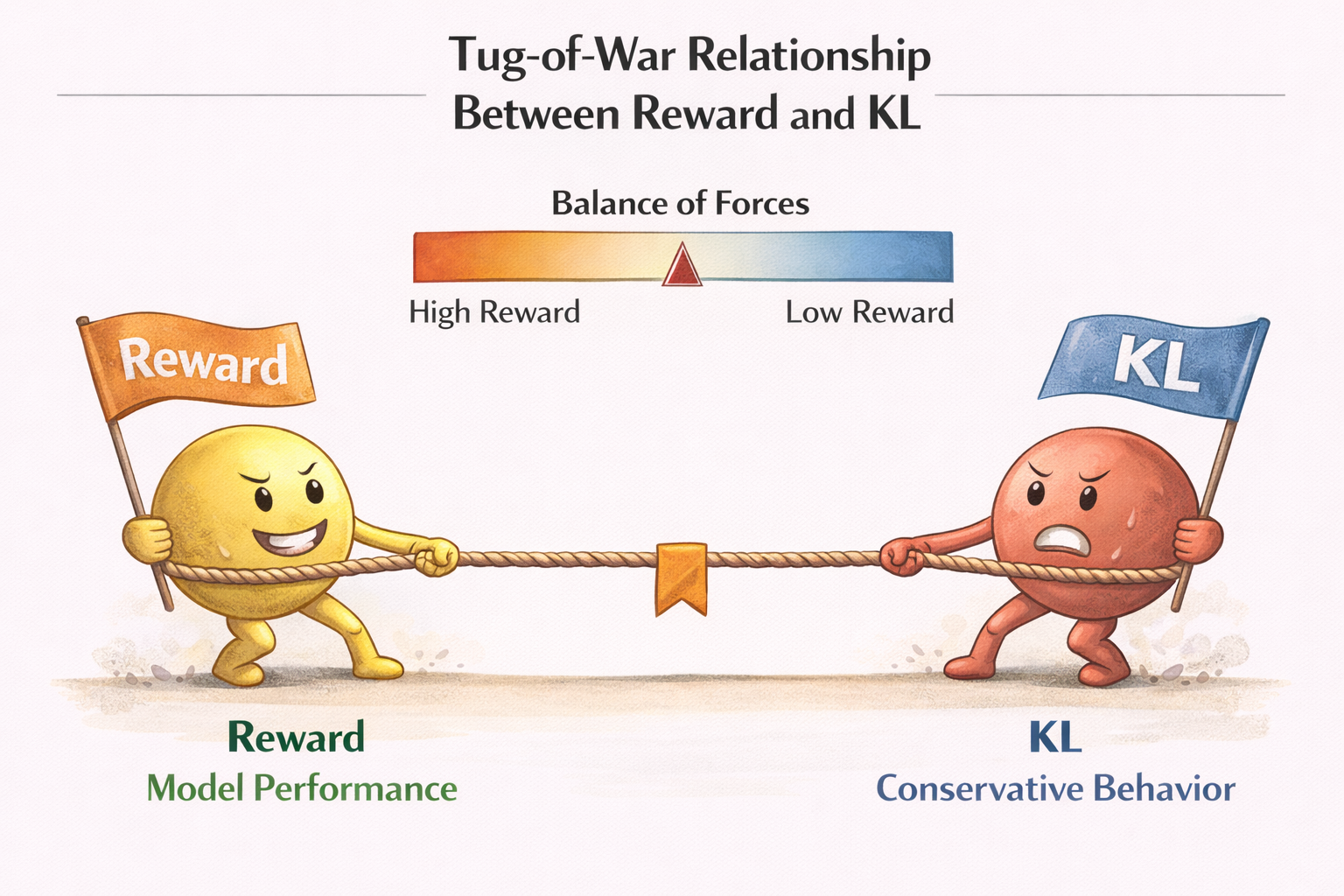
reward 与 KL 的拉扯关系示意图
为什么 PPO 会“改风格”,却不一定“变聪明”
这是很多人 PPO 调完后最困惑的点。
你会发现:
- 模型回答更谨慎了
- 更会拒绝问题
- 更符合偏好
- 但并没有学到新知识
这是因为 PPO 的更新信号根本不是知识型的。
PPO 优化的是:
在已有能力空间中,
哪些输出更值得被选择。
它不会扩展模型的知识边界,
只会重排“行为概率”。
PPO 训练流程,用“工程语言”重新走一遍
下面我们不用论文语言,而用工程视角,重新走一遍 PPO。
第一步:Policy 生成多个候选输出
responses = policy_model.generate(prompt, n=4)
这一步非常关键:
PPO 需要选择空间,而不是单一答案。
第二步:Reward Model 给每个输出打分
rewards = reward_model.score(prompt, responses)
注意:
reward 是相对信号,不是绝对真理。
第三步:计算 Policy 更新方向(带 KL 约束)
loss = -reward + kl_coef * kl(policy, reference)
你可以把 PPO loss 理解成一句话:
“我想要高 reward,但不想和原模型差太远。”
第四步:更新 Policy(而不是 Reward)
loss.backward()
optimizer.step()
整个 PPO 过程中,
唯一被训练的,始终是 Policy。
为什么 PPO 一定需要 Reference Model
很多人会问:
“既然我已经有 policy,为什么还要 reference?”
答案是:
因为你需要一个‘不会动的锚点’。
Reference model 通常是:
- SFT 后的模型
- 或 PPO 初始模型
它的作用只有一个:
告诉你:你现在离“原来的自己”有多远。
没有 reference,KL 就失去了意义。
PPO 在大模型微调中,真正改变的是“概率分布形状”
这是一个非常关键、但极少被讲清楚的点。
PPO 不会:
- 新增 token
- 改变词表
- 加新知识
它只是在做一件事:
重新拉伸或压缩输出分布。
某些回答方式概率被放大,
某些被压低。
于是你看到的“行为变化”,
本质上是概率变化的结果。
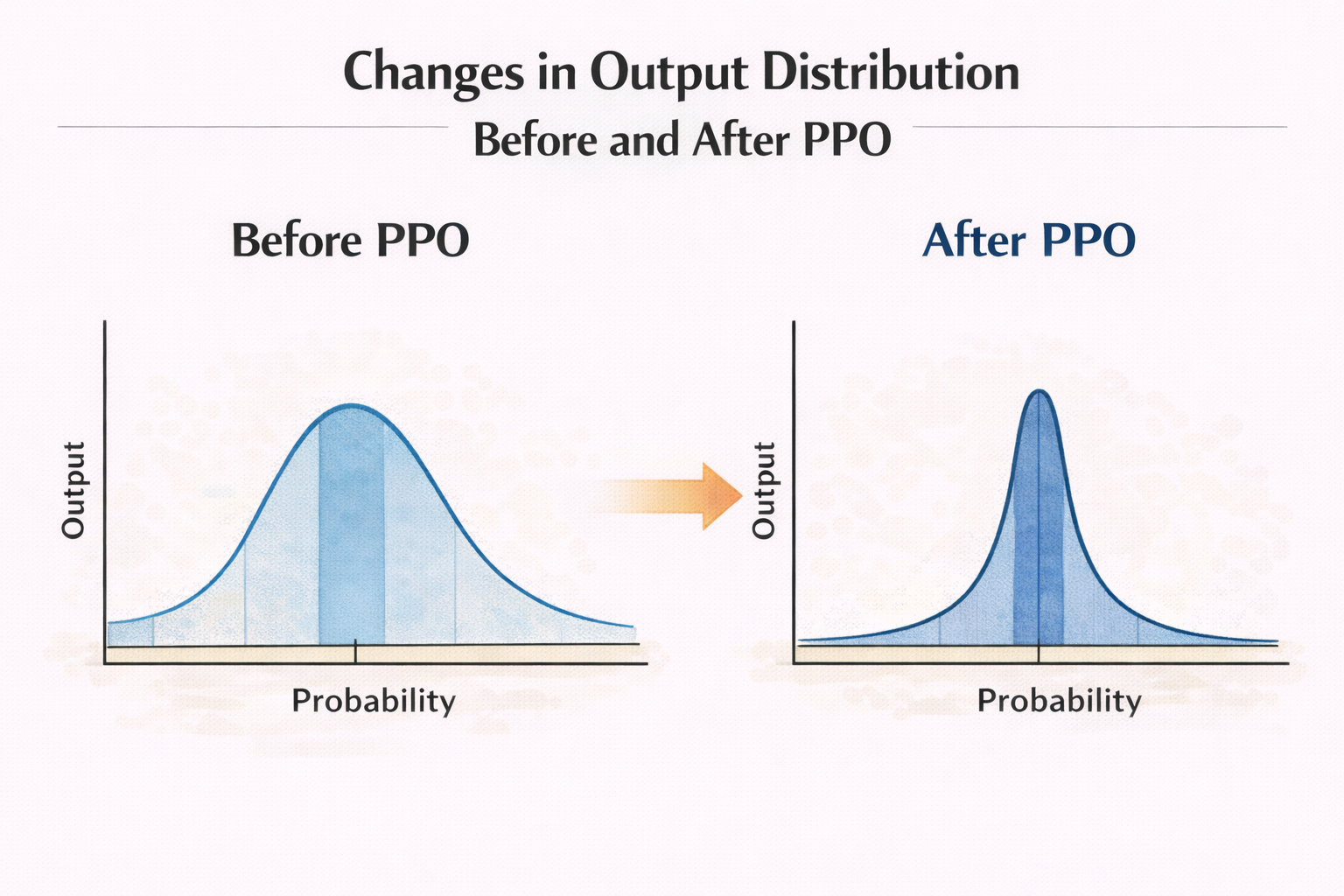
PPO 前后输出分布变化示意图
为什么 PPO 对“边界行为”影响最大
你会发现一个现象:
PPO 调完后,
模型在“模糊、边界、灰色问题”上的变化最大。
原因很简单:
- 确定性强的问题,分布本来就集中
- 边界问题,分布本来就发散
PPO 的 reward,恰恰最容易在这些地方起作用。
PPO 为什么“风险高”,但又“不可替代”
PPO 风险高,是因为:
- reward 本身可能有偏
- 模型可能走捷径
- 行为变化难以预测
但它又不可替代,是因为:
你无法用 SFT 教会模型“偏好”。
偏好,本质上是比较、权衡、取舍。
而 PPO,正是为这类问题而生的。
一个非常重要的结论:PPO 是“行为对齐工具”,不是“性能优化工具”
如果你把 PPO 用来:
- 提升准确率
- 学新知识
- 纠正事实错误
那你几乎一定会失望。
但如果你用它来:
- 调整风格
- 强化安全边界
- 对齐人类偏好
那 PPO 会非常强大。
另外一个很实际的点是:PPO 的“对齐效果”好不好,很多时候要靠对照评估集反复测试、对比不同 checkpoint 的输出风格。这个过程如果全靠本地脚本手动切版本,很容易把精力耗在搬运和对比上。用 LLaMA-Factory online 做快速版本对照和小规模迭代验证,会比你一开始就重工程投入更容易把方向跑正。
总结:理解 PPO,关键不在算法,而在“你到底想改什么”
写到这里,其实可以把整篇文章浓缩成一句话:
PPO 不是在教模型新东西,
而是在告诉模型:你已经会的东西里,哪种更值得选。
一旦你用“行为选择”而不是“参数优化”来理解 PPO,
你会发现:
- reward 的意义清晰了
- KL 的必要性清晰了
- 风险从哪里来,也清晰了
而这,正是后面所有 PPO 实战、调参、评估、踩坑的基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号