
RAG 不是万能解,这些场景你一开始就不该用
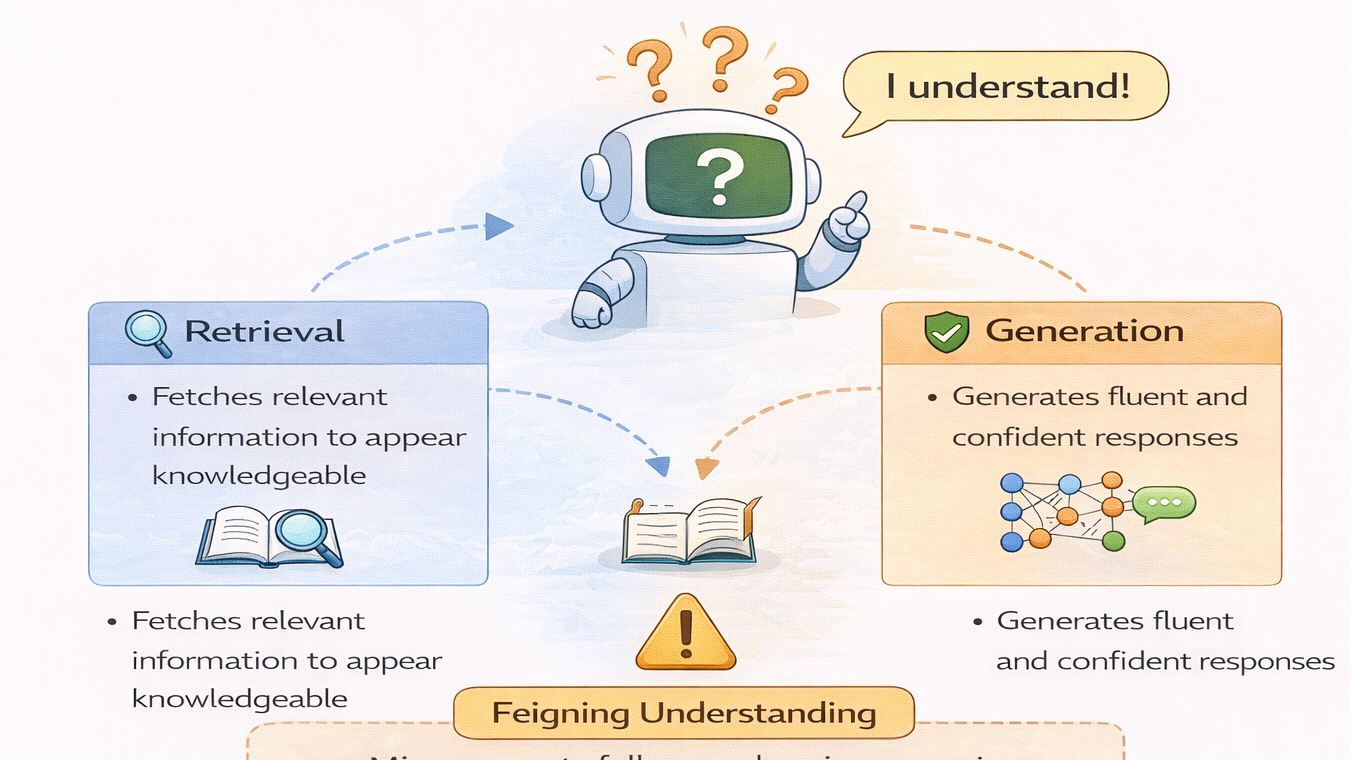 RAG并非万能,默认滥用反致系统复杂、效果难测。它仅解决“信息获取”,不提升模型能力。最适合四类场景:动态知识更新、需答案溯源、长尾问题密集、需求尚不明确。慎用于强推理、隐性经验、高实时性及高确定性要求场景。核心判断:问题是“找不到信息”,还是“不会处理信息”?
RAG并非万能,默认滥用反致系统复杂、效果难测。它仅解决“信息获取”,不提升模型能力。最适合四类场景:动态知识更新、需答案溯源、长尾问题密集、需求尚不明确。慎用于强推理、隐性经验、高实时性及高确定性要求场景。核心判断:问题是“找不到信息”,还是“不会处理信息”?
RAG 最常见的失败,并不是“没效果”,而是“用错地方”
如果你观察过一段时间大模型落地项目,会发现一个非常有意思的现象。
很多团队做 RAG,并不是因为认真分析过需求,
而是因为:
“大家都在用 RAG。”
于是 RAG 成了一种默认选项:
- 有知识问题 → RAG
- 模型不懂 → RAG
- 业务效果不好 → 再加一层 RAG
结果就是:
系统越来越复杂,
效果却始终说不清楚“好在哪里”。
后来你会发现一个非常扎心的事实:
RAG 不是没用,而是被用在了大量不适合它的地方。
一个必须先讲清楚的前提:RAG 解决的是“信息获取”,不是“能力提升”
这是理解“RAG 适合什么、不适合什么”的第一把钥匙。
RAG 的核心能力只有一件事:
在模型生成之前,把相关信息取出来,交给模型阅读。
它并不会:
- 提升模型的推理能力
- 改变模型的价值判断
- 让模型学会新技能
RAG 能做的,只是把模型“看不到的信息”,变成“看得到的信息”。
一旦你把 RAG 当成“能力增强工具”,很多决策从一开始就错了。
RAG 非常适合的第一类场景:稳定但经常变化的知识
这是 RAG 最经典、也最成功的应用场景。
比如:
- 产品文档
- 内部流程说明
- 政策条款
- 技术规范
这些知识有几个共同特点: - 内容本身是确定的
- 更新频率不低
- 不适合写死在模型里
如果你用微调来解决这类问题,你会立刻遇到几个现实问题: - 每次更新都要重新训练
- 历史版本难以回溯
- 风险极高(模型记住旧规则)
而 RAG 天然适合这种场景:
你只需要更新文档或索引,模型本身无需变化。
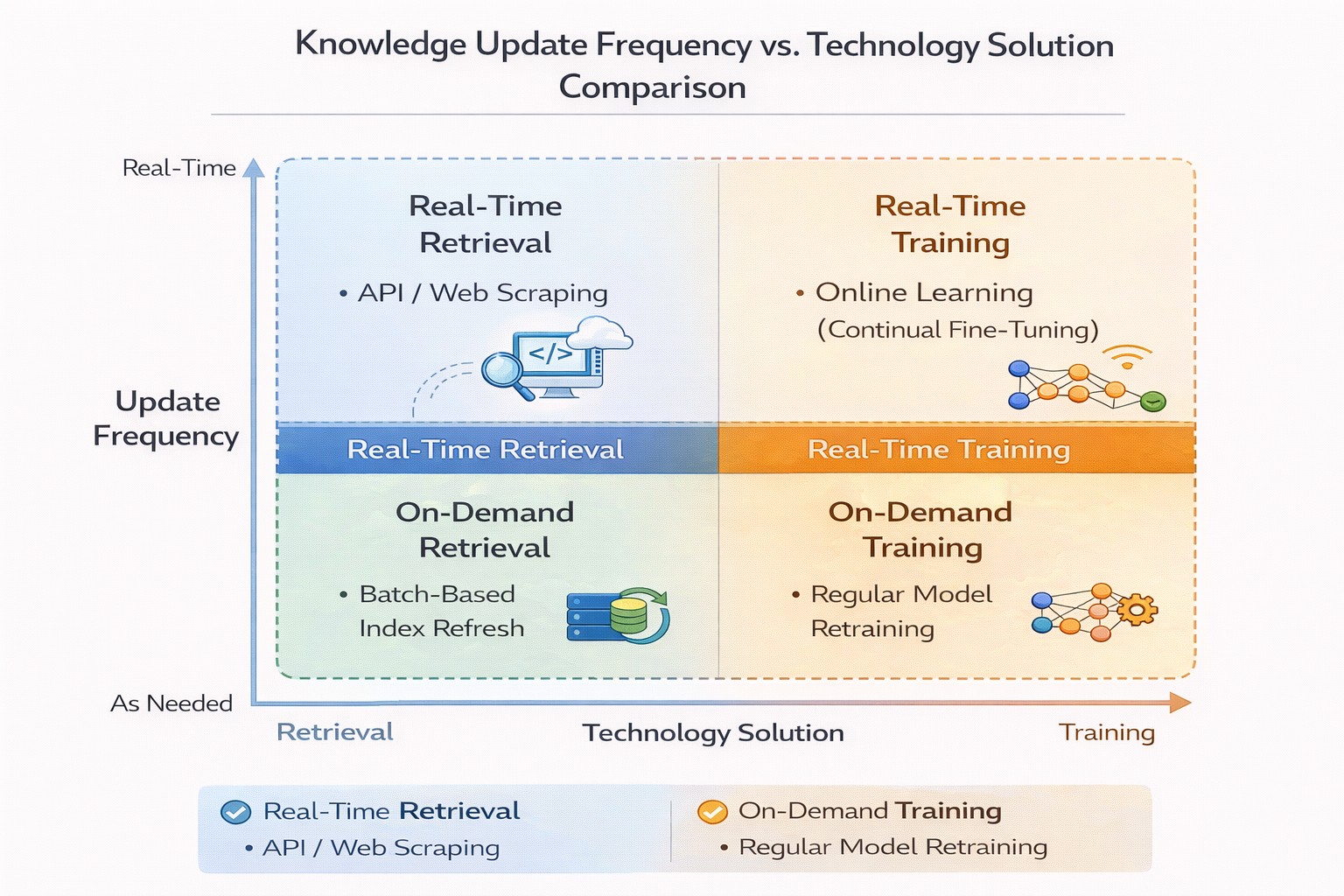
知识更新频率 vs 技术方案选择对比图
RAG 非常适合的第二类场景:可解释性要求高的系统
在很多业务里,“为什么这么答”和“答对了”同样重要。
比如:
- 企业内部系统
- 法律 / 合规辅助
- 运维 / 排障工具
在这些场景中,你往往需要: - 告诉用户信息来源
- 追溯引用依据
- 在出问题时能快速定位责任
RAG 的一个巨大优势在于:
答案是“有出处的”。
哪怕模型回答得不完美,你也可以清楚地知道:
它是基于哪些材料生成的。
这是纯生成模型或深度微调很难做到的。
RAG 非常适合的第三类场景:长尾问题密集的知识型应用
如果你的系统面对的是:
- 问题分布极其分散
- 单个问题出现频率不高
- 但整体知识面很广
那 RAG 几乎是必选方案。
典型例子包括: - 内部知识助手
- 技术支持系统
- 运维知识库
在这些场景中,用微调去“覆盖所有问题”几乎不可能。
而 RAG 可以通过检索,把长尾问题“变成已知问题”。
RAG 适合的第四类场景:你还不确定需求会怎么变
这是一个经常被忽略,但非常现实的点。
在很多项目早期,你其实并不清楚:
- 用户会问什么
- 哪些问题最重要
- 哪些信息最常被用到
在这种不确定阶段,RAG 的低承诺成本非常重要。
你可以: - 快速增删文档
- 调整切分和索引
- 改检索策略
而不用动模型本身。
从工程管理角度看,RAG 非常适合作为探索期方案。
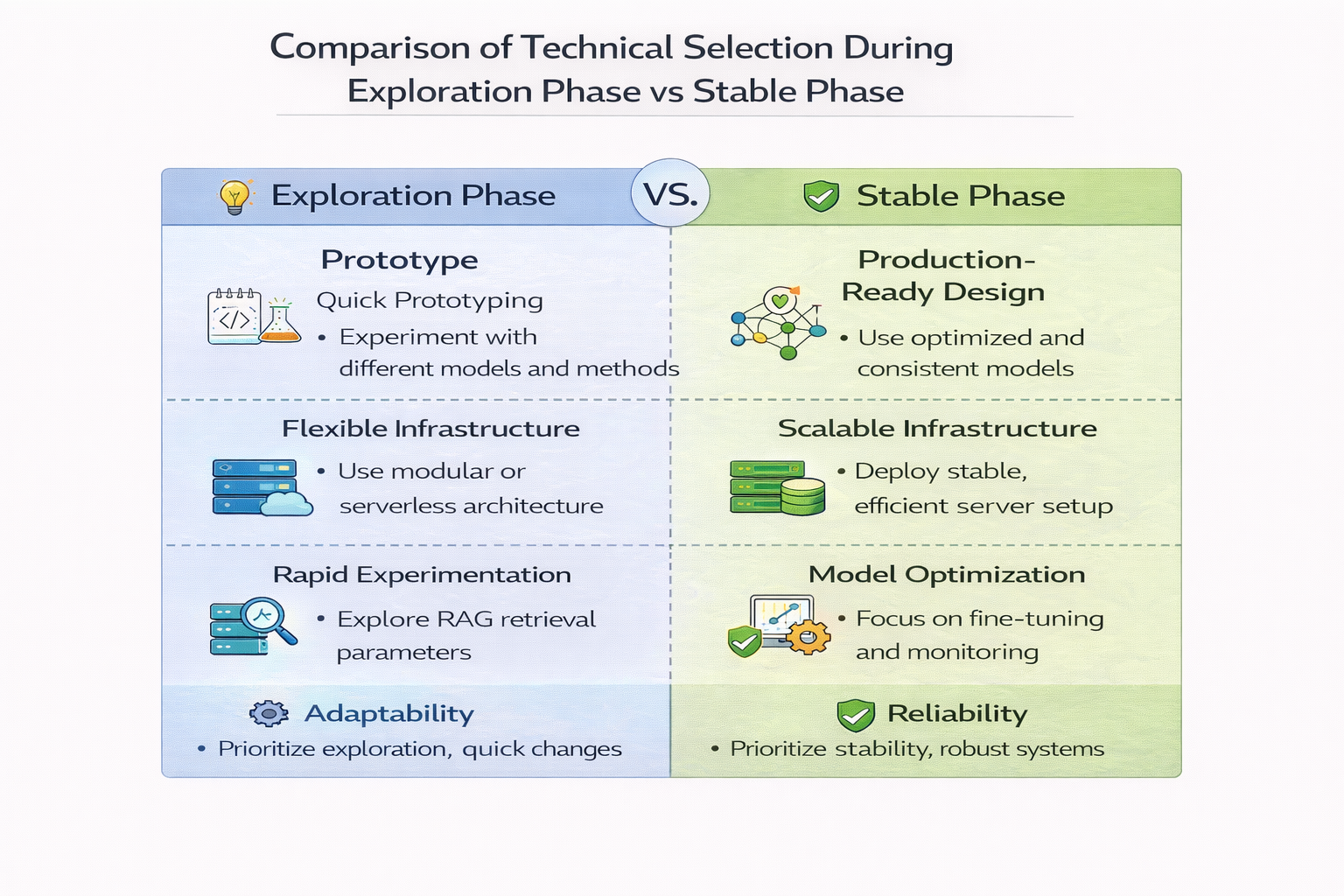
探索期 vs 稳定期的技术选型对比
RAG 明显不适合的第一类场景:强逻辑推理任务
这是一个非常常见、但经常被误判的地方。
如果你的问题本质是:
- 多步推理
- 条件组合
- 状态演化
那么 RAG 能提供的帮助非常有限。
RAG 可以把相关信息取出来,
但它无法替模型完成复杂推理。
比如: - 复杂规则判断
- 多条件决策
- 动态策略计算
在这些场景中,你更需要的是: - 明确的规则系统
- 专用算法
- 或直接人工介入
而不是一层又一层 RAG。
RAG 不适合的第二类场景:答案高度依赖“隐含经验”
有些问题,人类能答得很好,但很难写成文档。
比如:
- 经验判断
- 语境理解
- 潜规则
如果答案高度依赖“人怎么想”,而不是“文档怎么写”,
那 RAG 很可能会让模型输出看起来很像答案,但实际上很危险的内容。
因为 RAG 给模型的是“文本”,而不是“经验”。
RAG 不适合的第三类场景:对实时性要求极高的系统
RAG 的每一步,都会引入额外延迟:
- embedding
- 检索
- rerank
- 上下文拼接
如果你的系统对响应时间极其敏感,
比如毫秒级交易、实时控制系统,
RAG 往往不是合适的选择。
即使你能把延迟压下来,
复杂度和稳定性成本也非常高。
RAG 不适合的第四类场景:你需要“非常确定的输出”
这是很多人容易忽略的一点。
RAG 本质上是“概率系统 + 检索系统”的组合。
哪怕检索结果相同,
模型的生成结果也可能有差异。
如果你的业务要求的是:
- 输出高度一致
- 可预测
- 可形式化验证
那 RAG 往往不是最安全的方案。
在这类场景中,
规则系统或结构化查询,往往更可靠。
一个非常实用的判断方法:RAG 前三问
在决定是否使用 RAG 之前,我通常会先问三个问题。
第一:
问题的核心,是“不知道信息”,还是“不会处理信息”?
如果是前者,RAG 很合适;
如果是后者,RAG 基本帮不上忙。
第二:
答案是否可以清晰地写成文档?
如果答案本身写不清楚,RAG 只会放大混乱。
第三:
出错的代价有多大?
如果出错成本很高,而你又无法完全控制上下文质量,
那 RAG 风险很高。
一个简单的代码示例:展示 RAG 的“能力边界”
下面这段代码不是为了教你怎么写 RAG,
而是用来说明:RAG 只能基于检索内容发挥。
context = """
退款规则:
- 支付宝:1-3 个工作日到账
- 银行卡:3-7 个工作日到账
"""
question = "如果用户在节假日退款,什么时候到账?"
prompt = f"""
请根据以下信息回答问题:
{context}
问题:{question}
"""
# 模型只能在给定 context 内推断
在这个例子里,
模型不可能“知道”节假日如何处理,
因为 context 里根本没有这条信息。
你再大的模型,结果也不会更“正确”。
为什么很多 RAG 项目,看起来“什么都能答一点”
这是一个非常危险的信号。
当你发现一个 RAG 系统:
- 什么问题都敢答
- 回答都很流畅
- 但你又不太敢完全相信
那往往意味着:
RAG 被用在了不适合它的地方。
模型开始用语言能力,去弥补信息缺失,
而不是用检索结果支撑回答。
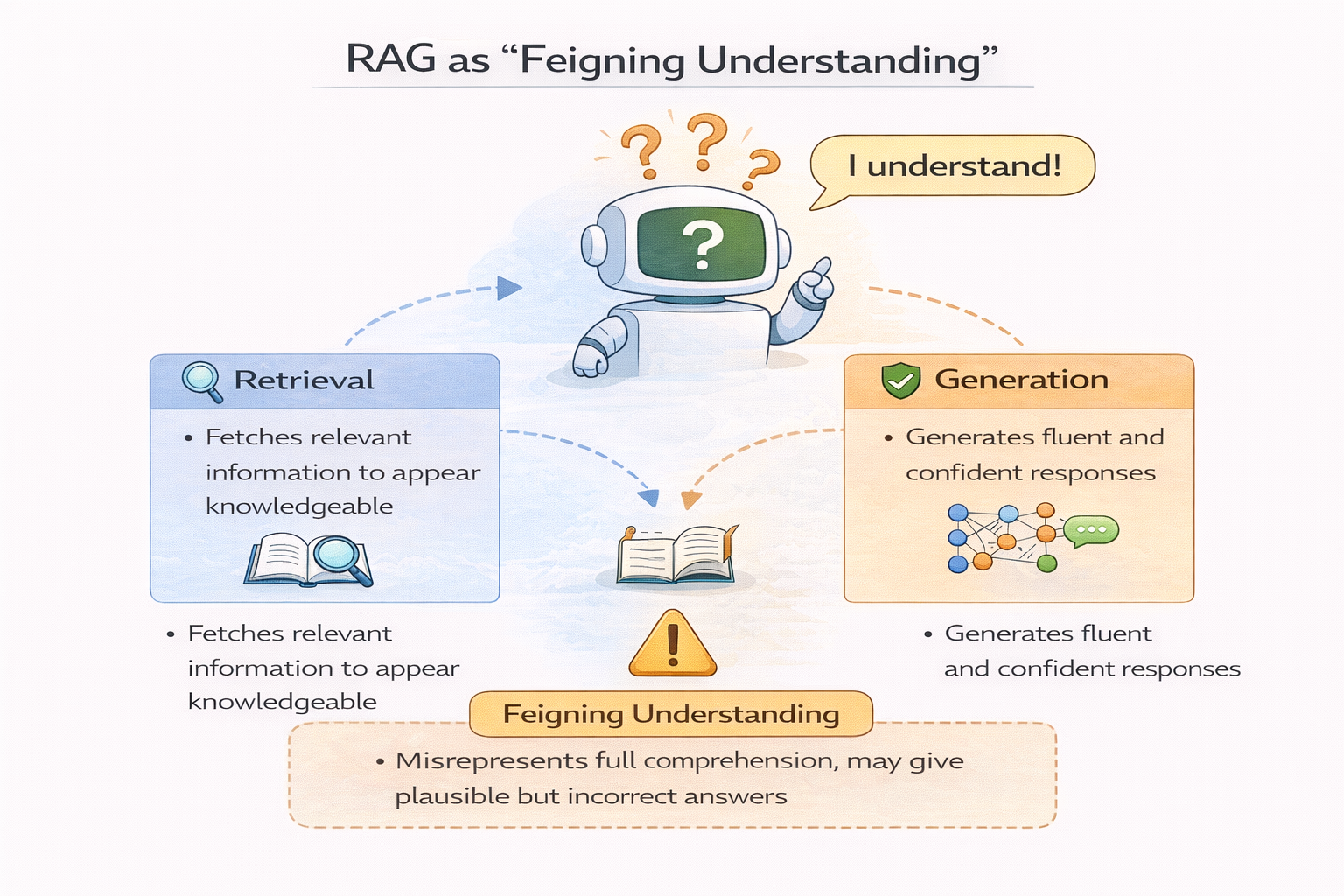
RAG 退化为“装懂”的示意图
一个现实建议:RAG 不是默认选项,而是“被选择的方案”
成熟的系统设计里,RAG 不应该是默认开启的。
它更像是:
在你确认“问题本质是信息获取”之后,
才被引入的一种解决方案。
否则,你会不知不觉地,把大量不适合的问题,
塞进一个不适合它的系统里。
工程实践中的一个常见组合思路
在真实项目中,一个更健康的架构往往是:
- 规则系统:处理确定性强的问题
- RAG:处理知识检索型问题
- 模型生成:处理表达和总结
而不是“所有问题都先过 RAG”。
在探索阶段,RAG 更适合“先小规模试”
RAG 的工程成本,往往被低估。
- 切分策略
- 检索质量
- 评估方式
- 维护成本
这些都不是一次性工作。
在探索 RAG 是否适合当前业务时,先用 LLaMA-Factory online 这类工具快速验证不同 RAG 方案、观察真实效果,再决定是否大规模投入,会比一开始就自建复杂系统更安全。
总结:RAG 适合解决“找得到就能答”的问题
如果要用一句话总结 RAG 的适用边界,那就是:
RAG 适合解决“只要把信息找对,模型就能答好”的问题。
一旦问题超出了这个边界,
RAG 不但帮不上忙,
还可能让系统看起来“更聪明、但更危险”。
真正成熟的使用方式,
不是问“能不能用 RAG”,
而是问:
“这个问题,本质上是不是一个检索问题?”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号