
数据集不是“越多越好”:微调里最容易被误解的一件事
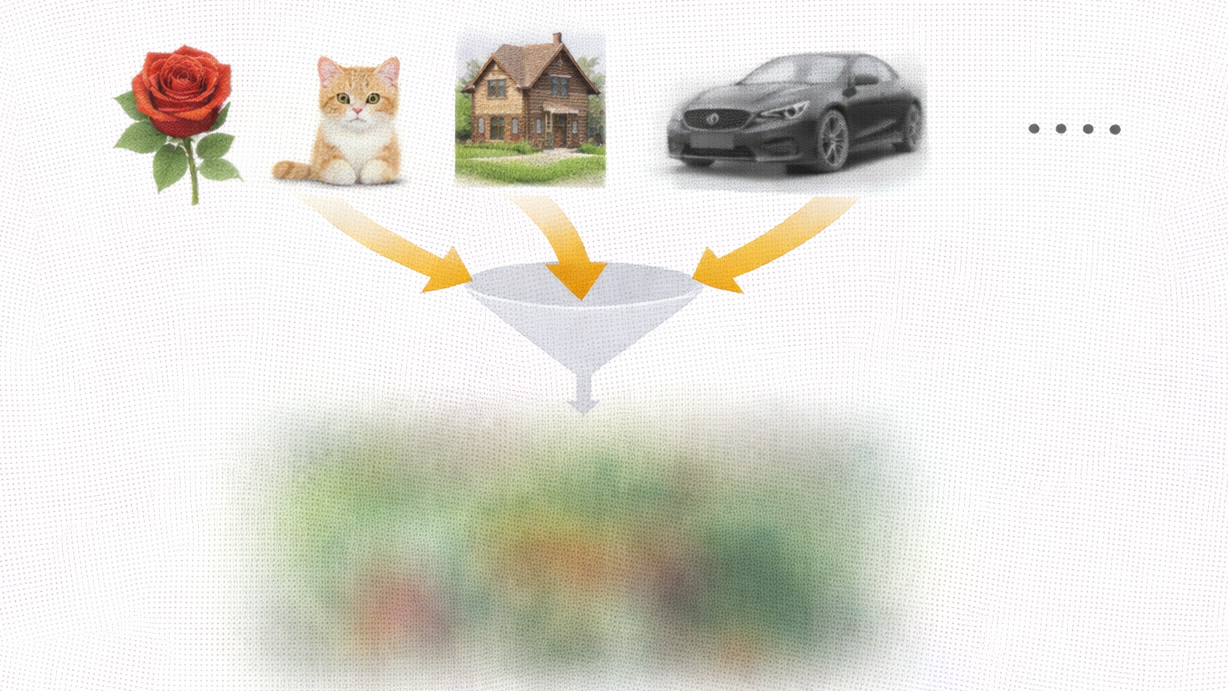 微调中数据非“越多越好”,而是“越清楚越好”。它本质是约束而非燃料:重目标一致性、表达稳定性与边界清晰度,而非规模。小而精的数据更易定位问题、验证假设;盲目扩量反致模型平均化、难调试、掩盖目标缺陷。关键在明确“教模型什么”,而非堆砌数量。
微调中数据非“越多越好”,而是“越清楚越好”。它本质是约束而非燃料:重目标一致性、表达稳定性与边界清晰度,而非规模。小而精的数据更易定位问题、验证假设;盲目扩量反致模型平均化、难调试、掩盖目标缺陷。关键在明确“教模型什么”,而非堆砌数量。
当你开始怀疑“是不是数据还不够多”的时候,事情往往已经不对了
如果你做过大模型微调,很可能经历过这样一个心理过程。
一开始,你对效果还有信心。
模型确实发生了一些变化,虽然不完美,但方向看起来是对的。
然后你开始测试更多问题。
有些好,有些不太好,还有些开始变得奇怪。
这时候,一个几乎是条件反射式的念头就会冒出来:
“是不是数据还不够多?”
于是你开始继续收集数据。
多抓一点日志,多爬一点问答,多加一些历史样本。
数据集从几百条变成几千条,从几千条变成几万条。
但结果往往是:
- 训练时间变长了
- 显存压力更大了
- 模型输出却越来越说不清楚“好在哪里”
很多微调项目,正是在这个阶段,从“有点希望”,慢慢走向“彻底失控”。
一个必须先说清楚的前提:数据在微调里不是“燃料”,而是“约束”
这是理解“数据不是越多越好”的关键。
在预训练阶段,数据确实更像燃料。
数据越多,模型见过的语言模式越丰富,整体能力上限越高。
但在微调阶段,数据的角色发生了根本变化。
微调数据,并不是在“拓展模型视野”,而是在收紧模型的行为空间。
你给模型看的每一条数据,都在告诉它:
“在类似情况下,你应该更像这样,而不是那样。”
也正因为如此,数据越多,约束越强。
第一个常见误区:把“覆盖面”当成“质量”
很多人在准备微调数据时,第一反应是追求覆盖面。
- 要覆盖尽可能多的场景
- 要包含尽可能多的问法
- 要让模型“什么都见过一点”
听起来很合理,但在微调里,这往往是个陷阱。
因为当你的数据覆盖面不断扩大,但目标却没有随之拆分清楚时,你其实是在给模型传递一条非常模糊的信息:
“什么情况都学一点,但没有哪一类是特别重要的。”
模型最后学到的,很可能只是一个“平均态”。
看起来什么都能说一点,但没有任何一个方向是真正可靠的。
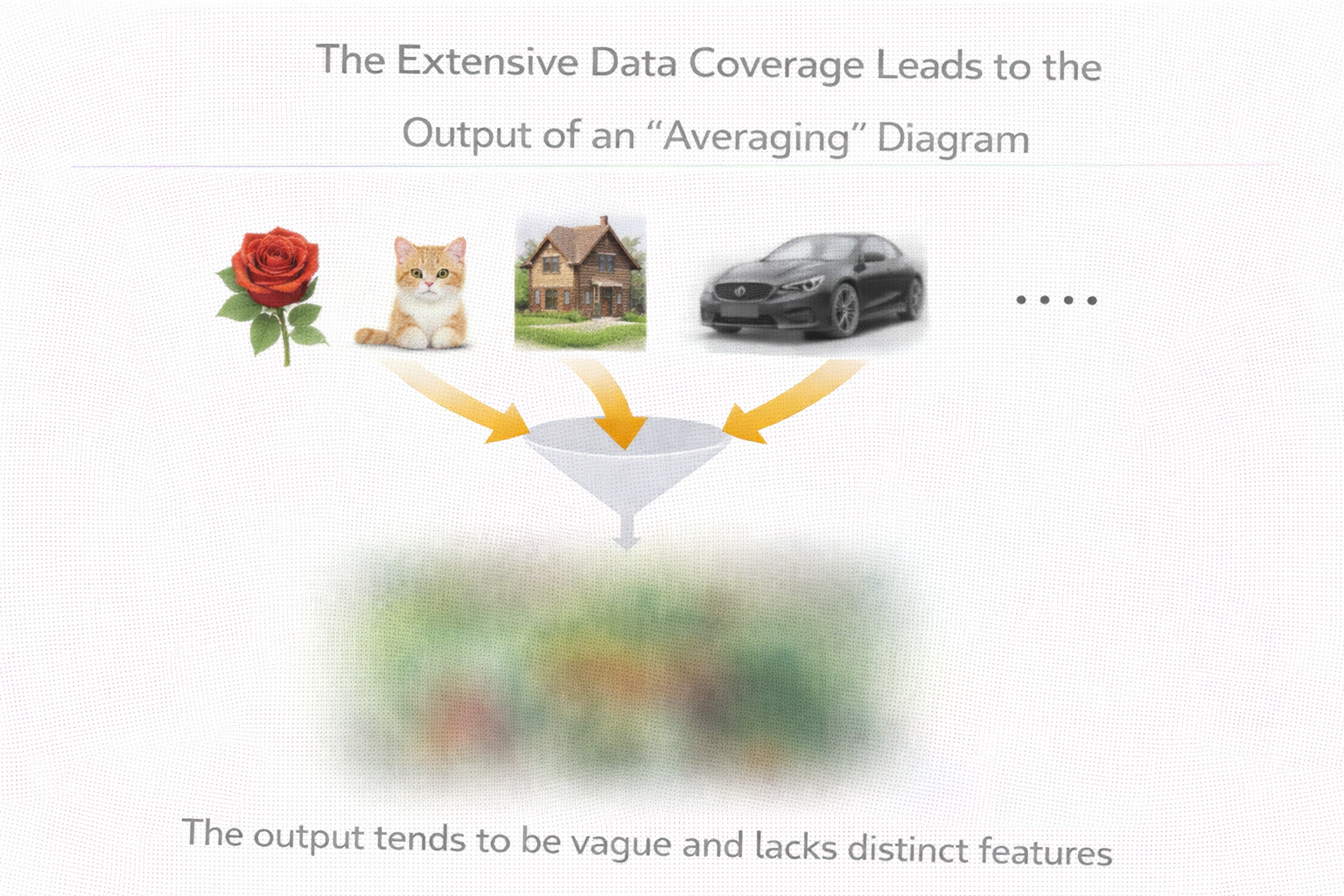
数据覆盖过广导致输出“平均化”的示意图
第二个误区:把“真实世界的噪声”原封不动塞给模型
很多人会觉得:
“这些都是线上真实数据,肯定很有价值。”
但真实世界的数据,往往也是最脏、最矛盾的。
真实客服对话里:
- 有情绪化表达
- 有不完整信息
- 有前后矛盾的回答
- 有人工临时发挥的措辞
这些数据,对“理解业务”当然有价值,
但对“教模型学稳定行为”,未必合适。
如果你没有先想清楚:
- 哪些是你希望模型学的
- 哪些只是背景噪声
那你给模型的,其实是一堆互相冲突的信号。
一个非常危险的情况:数据越多,问题越难定位
这是“数据不是越多越好”最工程化的一个原因。
当你的数据集只有 200 条时,模型输出变怪了,你还能去翻数据,看看是不是哪几条示例在“带偏模型”。
但当你的数据集有 2 万条时,情况就完全不同了。
你会发现:
- 你不知道是哪一类数据在影响模型
- 你不知道问题是出在格式、风格,还是内容
- 你甚至不知道该从哪里开始排查
数据一旦超过你认知可控的规模,它就不再是资产,而会迅速变成负担。
微调数据最重要的三个特性,而不是“数量”
在我自己的经验里,微调数据是否有效,几乎从来不取决于量,而取决于这三点。
第一,目标一致性
这些数据,是不是在反复强调同一类行为?
第二,表达稳定性
同一类场景,回答风格是不是高度一致?
第三,边界是否清晰
数据有没有明确告诉模型:什么情况下该这么做,什么情况下不该这么做?
只要这三点成立,哪怕数据量不大,模型也很容易学到你真正想要的东西。
为什么“小而干净”的数据,反而更容易成功
这是一个非常反直觉、但在工程里被反复验证的结论。
小数据集有几个天然优势:
- 你更清楚每一条数据在教什么
- 你能快速定位异常样本
- 你能更快验证方向是否正确
- 你不容易被“数据规模幻觉”迷惑
在这个阶段,微调更像是一种“对齐实验”,而不是规模化训练。
一个非常实用的建议:先用数据“教会一句话”
在准备微调数据时,我经常会用一个非常简单的自检方法。
假设你只能用一句话来描述这批数据在教模型什么,那句话你能不能说清楚?
比如:
- “遇到不确定问题,优先澄清而不是直接回答。”
- “客服回答要先安抚情绪,再给信息。”
- “技术问题回答要先给结论,再给解释。”
如果你说不出来,那说明你的数据目标本身就是混乱的。
数据重复,其实比你想象中更危险
很多人会觉得:
“重复的数据没关系,反正模型多看几遍。”
但在微调里,重复样本等价于人为放大某些信号的权重。
如果这些信号本身是你想强化的,那还好;
如果不是,那模型会被推向一个你没预料到的极端。
这也是为什么,数据去重在微调里远比很多人想象得重要。
下面是一个非常简单的示意代码,用来检测高相似样本:
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = model.encode(texts, convert_to_tensor=True)
scores = util.cos_sim(embeddings, embeddings)
# 找出相似度过高的样本对
duplicates = [(i, j) for i in range(len(texts))
for j in range(i+1, len(texts))
if scores[i][j] > 0.95]
这段代码不是为了“完美去重”,
而是帮你意识到:
你可能在无意中,让模型反复学同一件事。
一个很少被提到的问题:数据其实在“定义评估标准”
很多人以为:
数据是训练用的,评估是后面的事。
但在微调里,这两者是强绑定的。
你用什么样的数据训练模型,
你就会不自觉地用“类似的数据风格”去评估它。
这也是为什么很多项目在内部测试时感觉很好,一上线就问题百出。
不是模型突然变了,
而是你从一开始,就在一个很窄的世界里看它。
数据越多,越容易掩盖“目标本身的问题”
这是一个非常现实、也非常残酷的事实。
当数据量很小的时候,效果不好,你会被迫反思:
“是不是目标定义错了?”
但当数据量变大之后,你更容易给自己一个心理安慰:
“方向应该没问题,可能只是数据还不够多。”
于是你继续加数据,
继续训练,
却从未真正质疑过:
我到底想让模型学会什么?
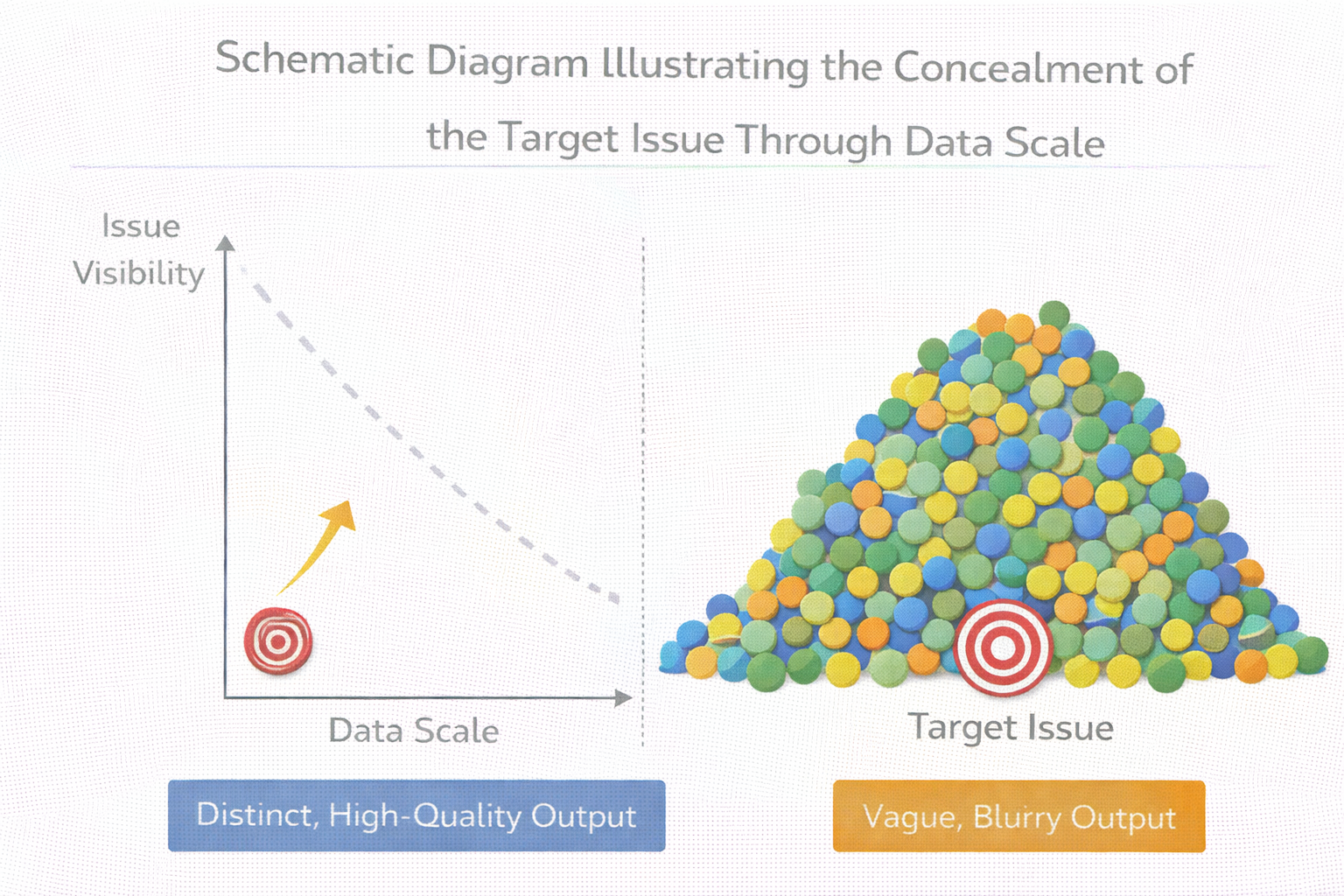
用数据规模掩盖目标问题的示意图
一个更健康的节奏:数据是用来“验证假设”的
在成熟的微调流程里,数据不是一次性准备完的。
它更像是:
提出一个假设 → 准备一小批数据 → 看模型是否朝这个方向变化 → 再决定是否扩展。
在这个阶段,速度和可控性,远比规模重要。
在验证数据方向是否有效时,先通过 LLaMA-Factory online 这类方式快速跑通小规模微调、对比输出变化,比一开始就准备大数据集更省力,也更安全。
一个非常重要的判断:什么时候你应该“停止加数据”
我给一个非常朴素、但很好用的判断标准。
如果你现在已经说不清楚:
“新加的这些数据,具体是想强化模型哪一类行为?”
那你就应该停下来。
继续加数据,只会让模型和你一起更困惑。
总结:数据不是“越多越好”,而是“越清楚越好”
写到这里,其实结论已经非常明确了。
在微调里,数据不是燃料,而是规则;
不是资源,而是约束。
当你把“多”当成目标时,模型往往会变得模糊;
当你把“清楚”当成目标时,哪怕数据不多,模型也能学得很准。
真正成熟的微调,不是“谁的数据多”,
而是谁更清楚自己在教模型什么。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号