
PPO vs DPO:不是谁淘汰谁,而是你用错了位置
为什么大家突然开始“只谈 DPO,不谈 PPO”
如果你最近在刷技术社区、看分享或者听内部讨论,很容易产生一种感觉:
PPO 好像有点“过时”了,DPO 才是新一代对齐方案。
很多文章在反复强调:
- DPO 不需要 reward model
- DPO 更稳定
- DPO 更简单
- DPO 是对 PPO 的“降维打击”
说实话,这种说法在某些前提下并不算错,但问题在于,这些前提往往被省略了。而真实业务,恰恰就是最不满足这些前提的地方。
我见过不少团队,在还没完全搞清楚自己要解决什么问题的情况下,就急着从 PPO “迁移”到 DPO,最后发现效果并没有变好,反而失去了很多原本可以控制的东西。
所以这篇文章我不打算回答“PPO 和 DPO 谁更好”这种问题,而是想聊清楚一件更重要的事:
PPO 和 DPO 在工程里解决的,本来就不是同一类问题。
技术原理:PPO 和 DPO 的核心差异到底在哪
如果只从公式上看,PPO 和 DPO 的差异会显得非常复杂,但从工程角度,其实可以用一句话概括。
PPO 是在优化一个“带约束的策略”。
DPO 是在直接学习“偏好关系”。
这个差异,决定了它们在真实业务里的使用边界。
PPO 的核心,是 reward。模型生成一个结果,然后你告诉它“这样好不好”。这个“好不好”,可以来自 reward model、规则、线上指标,甚至人工反馈。PPO 并不关心 reward 从哪里来,它只关心 reward 是否能稳定地引导策略更新。
DPO 则完全不一样。DPO 假设你已经有了非常清晰的偏好数据:
在同一个输入下,A 比 B 好。
模型要做的,只是调整参数,让这种偏好在概率分布中体现出来。
这也解释了为什么 DPO 不需要显式的 reward model,因为偏好本身就已经隐含了 reward 信息。
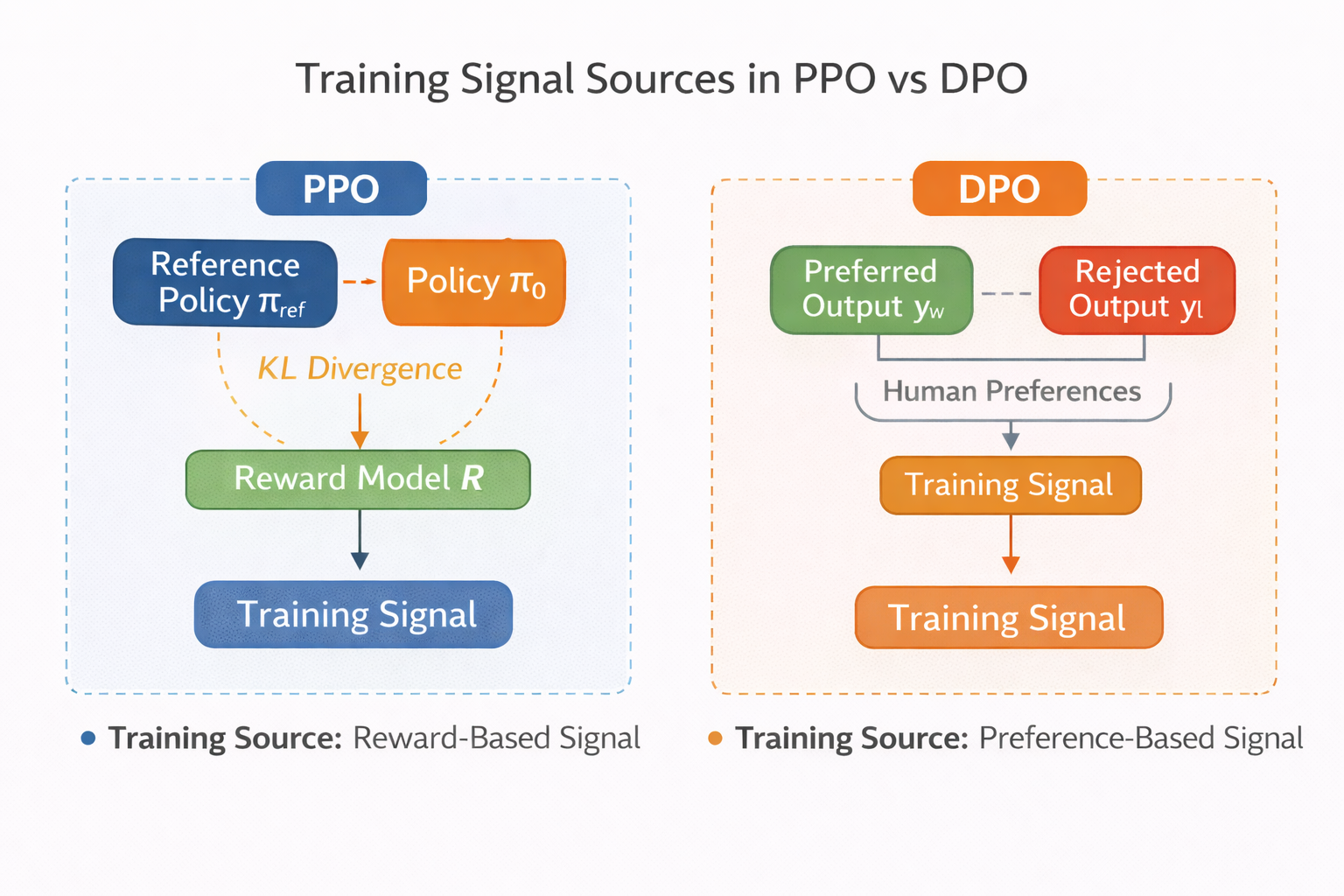
PPO 与 DPO 在训练信号来源上的差异示意图
一个很容易被忽略的问题:你真的有“干净的偏好数据”吗
很多团队在选择 DPO 的时候,都会默认一个前提:
“我们有偏好数据。”
但在真实工程里,这句话往往需要打一个大大的问号。
什么叫“偏好数据”?
不是“这个回答看起来还行”;
也不是“业务同事说更喜欢这个”;
而是在同一个输入条件下,偏好关系清晰、稳定、可复现。
如果你的偏好数据是从线上日志里捞出来的,是受场景、用户、时间影响的,那它其实已经非常接近 reward 信号了。这种情况下,你用 DPO,往往只是把复杂性藏到了数据里,而不是消除了复杂性。
这也是为什么很多人觉得 DPO“很简单”,但一落地就开始遇到各种奇怪问题。不是 DPO 本身有问题,而是数据假设不成立。
真实业务里的第一个分水岭:你是在“对齐行为”,还是“学习选择”
这是我自己在项目中慢慢总结出来的一个判断标准。
如果你要解决的问题是:
- 模型该不该这么说
- 模型什么时候该拒答
- 模型在不确定时该偏向保守还是激进
那你大概率是在做行为对齐,PPO 通常会更合适。
如果你要解决的问题是:
- 在多个候选中选哪个更好
- A 和 B 谁更符合偏好
- 输出风格哪种更受欢迎
那你更可能是在做偏好学习,DPO 会更自然。
这两类问题,在工程实现上看起来很像,但本质是不同的。
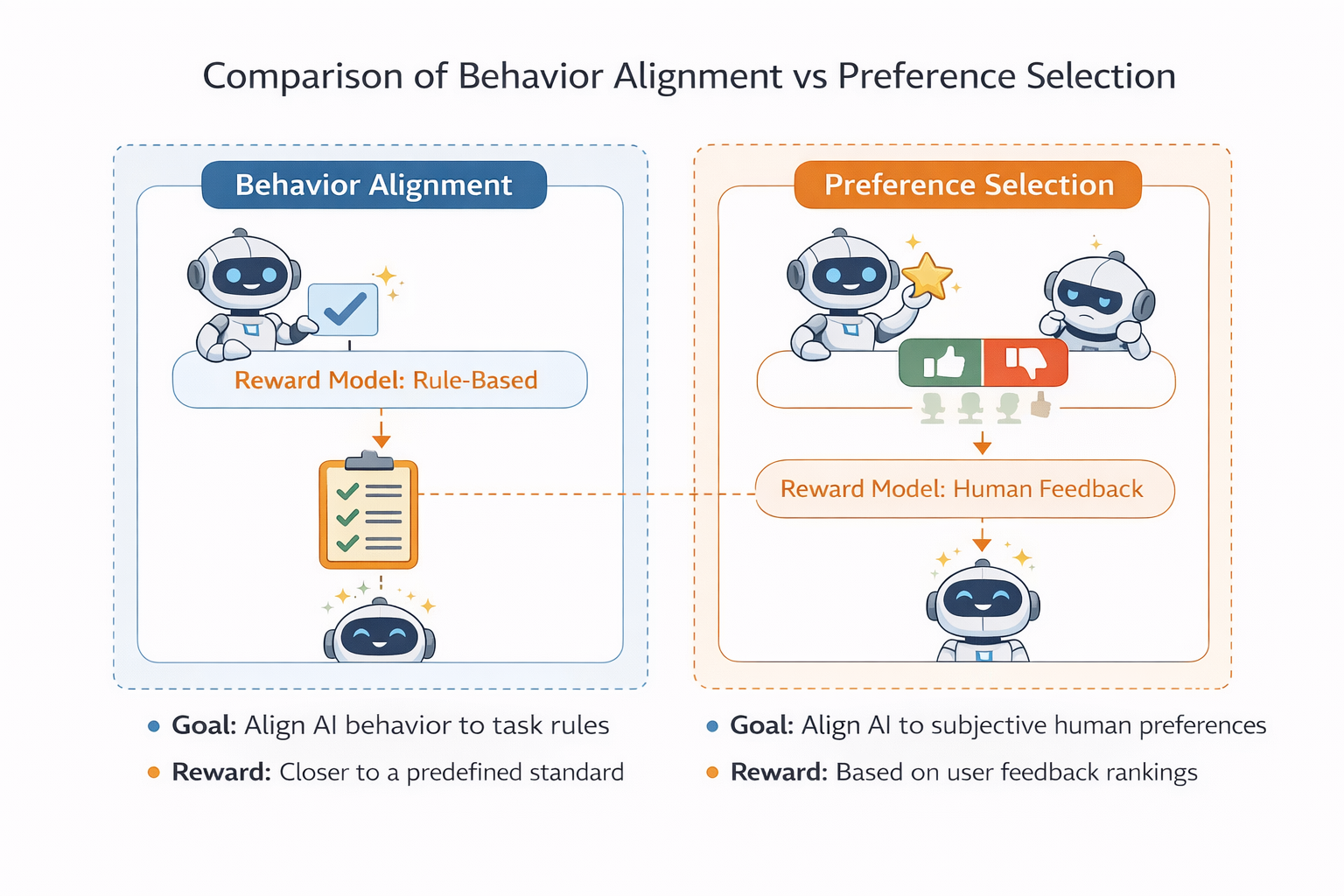
行为对齐 vs 偏好选择的场景对比图
为什么很多团队觉得 DPO 比 PPO “稳”
这是一个非常常见、也非常真实的感受。
PPO 在工程上确实不算“省心”。reward 设计不好就会抖,KL 控制不好就会崩,训练过程需要反复观察输出,而不是只盯着指标。
相比之下,DPO 的训练过程显得异常“安静”。loss 稳定下降,训练流程清晰,几乎不会出现 PPO 那种“一觉醒来模型废了”的情况。
但这种“稳”,其实是有代价的。
DPO 的稳定,来自于它对问题空间的强约束。你只能在给定的偏好数据范围内优化,模型几乎不会学到偏好之外的东西。这在很多场景下是优点,但一旦你的业务规则发生变化,或者偏好不再那么清晰,这种稳定就会变成限制。
一个真实但不太被提及的事实:PPO 更“脏”,但也更灵活
从工程角度看,PPO 是一个非常“脏”的方法。
- reward 可以来自任何地方
- 规则可以随时改
- 指标可以不断加
- 训练目标可以动态调整
这些特性让 PPO 看起来不够优雅,但也正是这些特性,让 PPO 在真实业务中非常好用。
尤其是在你还不完全确定“什么是好输出”的阶段,PPO 往往比 DPO 更适合探索。你可以先用非常粗糙的 reward,把模型往一个大致正确的方向推,然后再逐步收紧。
DPO 则更像是一个“收尾工具”,在偏好已经非常明确的情况下,把模型打磨得更一致。
实践建议:不要在 PPO 和 DPO 之间二选一
在我参与过的项目里,最理想的状态,几乎从来不是“只用 PPO”或者“只用 DPO”。
一个非常常见、也非常合理的组合是:
- 先用 SFT 让模型具备基础能力
- 用 PPO 做一轮行为层面的粗对齐
- 在偏好逐渐清晰后,用 DPO 做精细化调整
这种流程的好处在于,你既保留了探索空间,又能在后期获得 DPO 的稳定性。
在尝试这种组合策略时,如果能先通过 LLaMA-Factory online 这类工具快速验证 PPO 和 DPO 各自的效果,再决定是否深度投入工程化,会更符合真实团队的节奏。
如何判断你当前阶段更适合 PPO 还是 DPO
如果你问我有没有一个“快速判断表”,我一般会从几个非常现实的问题入手。
- 你的偏好是否稳定?
- 你的 reward 是否会频繁调整?
- 你是否需要快速试错?
- 你是否能接受模型行为的探索性变化?
如果这些问题的答案偏向“是”,那 PPO 往往更合适;
如果你的答案偏向“否”,而且偏好关系非常清晰,那 DPO 会省你很多事。
这里没有绝对正确的选择,只有是否匹配当前阶段。
总结:别再问“谁淘汰谁”了
写到最后,其实结论已经很明确了。
PPO 和 DPO 并不是新旧关系,也不是替代关系。它们更像是两种解决不同问题的工具,被放在了同一个舞台上,于是看起来像在竞争。
真正的问题,从来不是“PPO 会不会被淘汰”,而是你是否清楚自己在解决什么问题。
当你把对齐当成一个持续演进的工程过程,而不是一次性算法选择时,能够低成本尝试不同方案的工具,反而会变得越来越重要。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号