
什么是大模型微调?从原理到实操,新手也能轻松上手
什么是大模型微调?从原理到实操,新手也能轻松上手

引言:为什么“微调”能让大模型从“通用”变“专属”?
现在提起AI,谁还没试过用通义千问、ChatGPT写文案、查资料?这些通用大模型就像“全能学霸”,能应对常见需求,但一到具体业务场景就容易“水土不服”
电商运营想让AI写敏感肌防晒霜文案,它堆砌网络用语,不突出“无酒精、防水防汗”核心卖点;客服负责人希望AI听懂“工单闭环”“SLA时效”黑话,它却答非所问;金融从业者想让AI生成标准化报告,输出格式五花八门,无法对接系统。
这时候就会发现:提示词只能解决临时简单需求,想让大模型真正融入业务,成为“专属助手”,核心技术就是微调。
简单说,微调就是给现成大模型“补课”:在预训练大模型基础上,用你的业务数据继续训练,让它记住行业知识、熟悉输出格式、贴合使用场景。它不用海量算力,也能长期稳定生效,是中小企业和个人实现大模型定制化的首选。
今天这篇文章,从“什么是微调?”“有哪些方式?”“怎么实操?”“怎么验证效果?”四个维度,用通俗语言讲透,看完你既能判断自身场景是否需要微调,还能动手落地。

技术原理:3种核心微调方式,比喻讲透
微调不是“一刀切”,按需求分为3种核心方式——CPT(继续预训练)、SFT(监督微调)、DPO(偏好训练),用“学生补课”比喻就能秒懂:
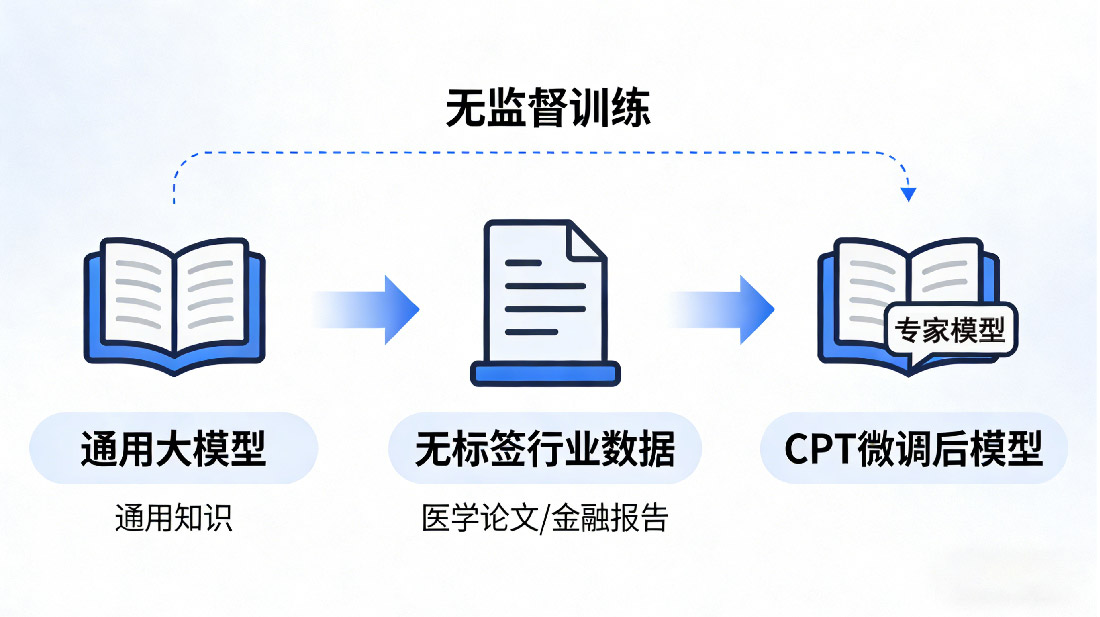
1. CPT(Continual Pre-Training):继续预训练——给模型“补专业课”
核心定义
给模型喂 “纯原始文本”(不用提前做任何标注),让模型自己从文本里 “读” 懂专业知识,整个过程不用人干预 “什么是对、什么是错” —— 就像让学生自己读一本专业书,不用老师划重点、给习题答案,全靠自己吸收知识。
数据要求
- 量:几GB到几十GB,数据越多样,专业知识越扎实;
- 质:目标领域专业内容,无杂乱信息;
- 格式:无需标注“问题-答案”,直接喂原始文本即可。
适用场景
- 专业领域知识补充(医疗诊断、法律文书、金融分析);
- 特定语言/方言/行业黑话理解(粤语、小语种、“埋点”“平仓”等);
- 行业特定表达习惯适配(法条引用、报告规范、论文逻辑)。
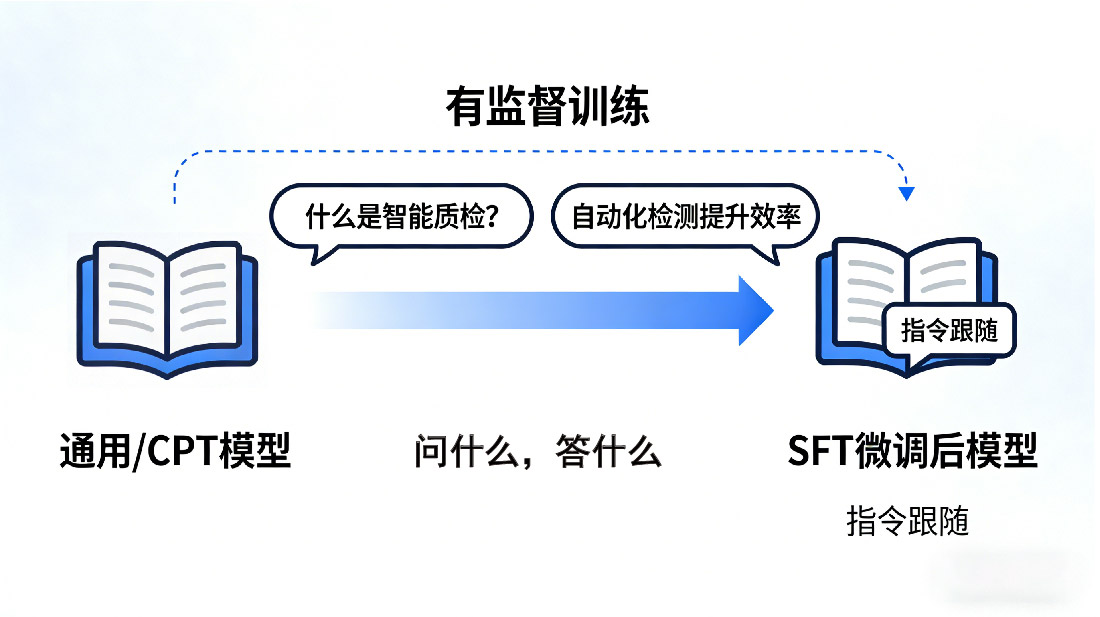
2. SFT(Supervised Fine-Tuning):监督微调——给模型“做练习题”
核心定义
最常用的微调方式,“用户的需求 / 指令” 和 “模型该输出的正确响应” 组成的一对数据 —— 简单说,就是给模型明确 “问什么、答什么”,像老师给学生出的 “真题 + 标准答案”,让模型照着学 “指令跟随”。
数据要求
- 量:100条-几万条,新手100-500条即可见效果;
- 质:答案准确、风格统一,无矛盾信息;
- 格式:“指令+响应”标准格式(如“instruction: 写敏感肌防晒霜文案 → response: XXX”)。
适用场景
- 客服机器人训练(回应快递时效、售后申请等);
- 特定任务助手创建(代码、写作、行业翻译助手);
- 对话风格定制(客服亲切语气、学术严谨语气、文案活泼语气)。
3. DPO(Direct Preference Optimization):偏好训练——给模型“评优劣”
核心定义
最新微调技术,相当于给“会做题的学生”批改错题、对比优劣。给模型同一个问题的“好答案”和“坏答案”,明确告知优先级,让模型学习人类偏好,减少有害内容和“幻觉”。
数据要求
- 量:几百-几千条,每条含“问题+好答案+坏答案”;
- 质:好坏差异清晰(准确vs错误、简洁vs冗长、合规vs有害);
- 标准:贴合目标用户习惯(客服场景“亲切”优于“生硬”,学术场景“严谨”优于“口语”)。
适用场景
- 优化回答贴合人类偏好(文案口语化、回答简洁化);
- 过滤有害内容(暴力、歧视、虚假信息);
- 提升回答准确性(降低“一本正经胡说八道”的概率)。

关键补充:非必要不微调!先试2个低成本替代方案
微调有门槛(GPU、技术、数据),优先尝试以下2种方案,效果达标就不用折腾:
1. 提示词工程:简单需求“临时解决”
相当于“划重点”,直接告诉模型“怎么答”(如“写敏感肌防晒霜文案,突出无酒精、语气亲切”)。优势:零成本、见效快、易调整,适合写短文、查信息等简单需求。
2. RAG(检索增强生成):需最新信息“实时解决”
相当于“配参考书”,模型回答前先检索相关文档(企业知识库、最新政策),再生成答案。优势:实时更新、维护成本低,适合企业知识问答、政策解读等场景。
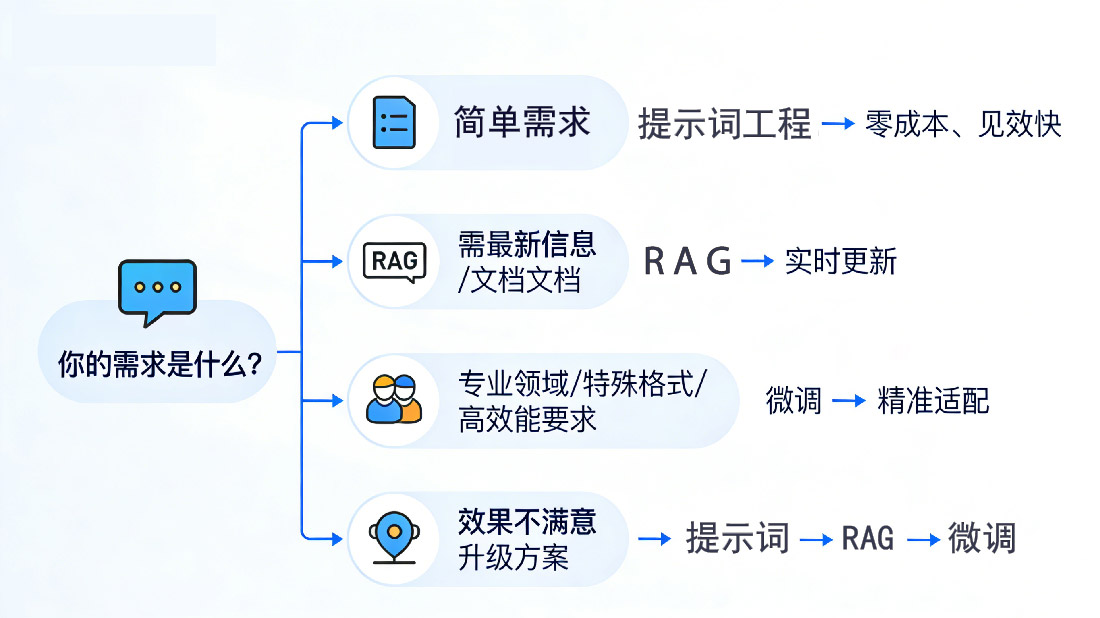
什么时候必须用微调?
尝试提示词和RAG后效果不佳,再考虑微调:
- 特定领域专业知识(医疗诊断、法律文书,通用模型知识不足);
- 特殊输出格式要求(结构化数据、固定报告格式,提示词难控制);
- 私有数据深度理解(企业知识库、用户偏好分析,RAG检索效果差);
- 高性能要求场景(实时客服、高频交易,需毫秒级响应+高准确率)。
实践步骤:新手从零落地微调,5步搞定
以最常用的SFT监督微调为例,整理“从准备到落地”完整步骤,跟着做就能成功:
第一步:明确目标——让模型“学会什么”?
- 具体需求:如“写符合品牌风格的电商文案”“听懂客服黑话精准回应”;
- 输出要求:风格(口语化/严谨)、格式(分点/表格)、长度(≤100字);
- 业务边界:明确模型不需要做什么(如不涉及敏感词、不超售后政策承诺)。
第二步:准备数据——微调的“核心燃料”(最关键)
SFT需要“问题-答案”对,按以下标准准备:
1. 推荐格式(工具通用)
- 格式1:JSONL(兼容性好)
{"instruction": "写敏感肌防晒霜文案,突出无酒精、防水防汗", "response": "SPF50+高倍防晒,无酒精无香精,敏感肌安心上脸~ 防水防汗配方,海边/通勤都适用,一抹成膜不泛白粘腻!"}
{"instruction": "通俗解释什么是工单闭环?", "response": "用户提的问题,客服从受理、处理、反馈到确认解决,全流程有结果,不遗漏不悬置。"}
- 格式2:Excel(新手友好)
| instruction(指令) | response(响应) |
|---------------------|------------------|
| 写敏感肌防晒霜文案,突出无酒精、防水防汗 | SPF50+高倍防晒,无酒精无香精,敏感肌安心上脸~ 防水防汗配方,海边/通勤都适用,一抹成膜不泛白粘腻! |
| 通俗解释什么是工单闭环? | 用户提的问题,客服从受理、处理、反馈到确认解决,全流程有结果,不遗漏不悬置。 |
复制技巧:选中整个表格,复制后直接粘贴到 Excel,新增行就能填自己的 “指令 - 响应” 数据;
工具适配:填完后无需转换格式,直接上传 LLaMA-Factory Online,平台会自动识别,新手零报错。
2. 数据质量要求
- 准确:答案无错误(不把“SPF50+”写成“SPF30+”);
- 统一:风格、格式一致(文案均口语化,报告均分点);
- 足量:新手≥100条,理想500-1000条;
- 无冗余:无重复、无关数据。
3. 数据清洗(5步搞定)
- 删除重复数据→修正错误信息→统一格式→过滤无效数据(空白、敏感词)→人工抽检20-30条。
第三步:选择工具——新手优先“零代码工具”
1. 零代码工具
数据整理好后,下一步就是选择工具启动微调。对新手来说,工具选型不用纠结,核心看三个关键点:是否零代码、能否直接兼容 Excel/JSONL 格式、是否自带主流模型(不用自己找资源)。
市面上常见的微调工具里,Hugging Face Transformers 需要写代码、调参数,对零基础不友好;DeepSpeed 这类工具更适合大规模集群训练,个人和中小团队用不上;LLaMA-Factory Online 就比较契合新手的核心需求 —— 它有现成的 WebUI 界面,全程网页操作不用碰代码,之前整理的 Excel 表格或 JSONL 文件能直接上传,不用额外转格式。
而且它内置了 Qwen、DeepSeek、Llama 等主流基座模型,不用自己花时间下载、适配,系统还会根据你的数据类型自动推荐参数,不用琢磨复杂的学习率、训练轮数。新手入门不用投入高额算力,100 条数据的训练成本很低,平台给的免费额度完全够试错,跟着页面指引点一点,很快就能跑通整个微调流程,不用在环境部署、资源适配这些琐事上浪费时间。
2. 代码工具(懂基础Python)
- 核心工具:Hugging Face Transformers、PEFT、Datasets;
- 算力:Colab(免费)、阿里云PAI(按量计费);
- 步骤:安装依赖→加载数据→配置模型→训练→保存模型,适合需自定义参数的用户。
第四步:配置参数——新手“默认参数”先跑通
核心参数不用纠结,新手按默认值来,后续再优化:
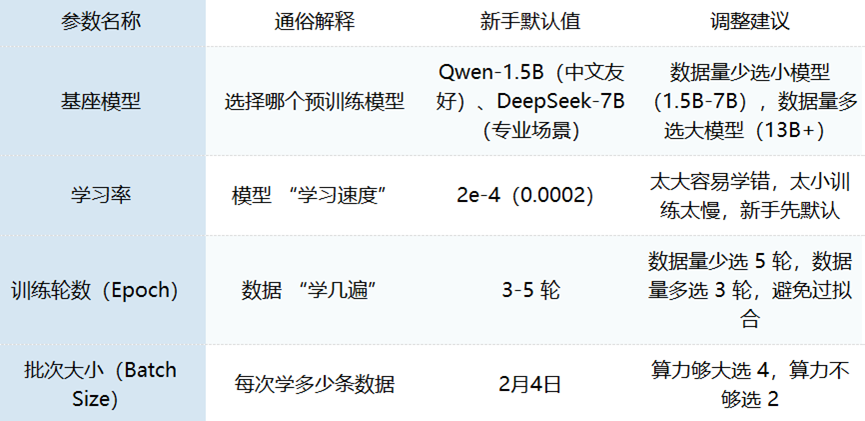
LLaMA-Factory Online等零代码工具会自动推荐参数,直接下一步即可。
第五步:启动训练+等待
- 零代码工具:点击“启动”后看实时进度(训练占比、剩余时间),完成后收提醒;
- 代码工具:运行脚本后看损失值(逐渐下降为正常);
- 时间:100条→30分钟-1小时,500条→2-3小时,1000条→4-6小时;
- 成本:免费额度覆盖100条,1000条约8-15元。
效果评估:怎么判断微调“成功了”?3个维度
训练完成后,从以下维度验证效果,核心看“是否比微调前更好”:
1. 主观评估(新手首选)
找10-20个核心问题,对比微调前后输出:
- 准确性:答案是否正确(如“工单闭环”解释是否专业);
- 相关性:是否贴合指令(如文案是否突出“无酒精”);
- 风格/格式:是否符合预期(口语化、分点格式)。
示例对比:
- 测试指令:“什么是工单闭环?”
- 微调前:“工单闭环可能是处理流程完成,细节需确认。”(模糊)
- 微调后:“用户提的问题,客服从受理→处理→反馈→确认解决,全流程有结果,不遗漏。”(准确)
2. 客观指标(进阶需求)
- 困惑度:衡量模型对数据理解程度,数值越低越好(≤10为佳);
- 准确率:有明确答案的场景(如客服问答),答对比例越高越好。
3. 场景测试(最终验证)
模拟真实业务使用:
- 电商文案:生成10条产品文案,看是否能直接用于推广;
- 客服:用10个常见咨询测试,看是否精准回应、无需人工补充;
- 报告:生成5份报告,看格式是否统一、能否对接系统。
效果不好怎么调整?(新手避坑)
- 优化数据:补充数据、修正错误、统一格式(优先改数据);
- 调整参数:学习率1e-4/3e-4,训练轮数5轮;
- 换基座模型:中文换Qwen-1.5B,专业场景换DeepSeek-7B;
- 加DPO训练:SFT效果不佳时,用偏好数据优化。
总结与展望:微调让大模型“为你所用”
未来趋势
微调门槛会越来越低,“模型定制化”是必然趋势,中小企业和个人都能打造专属AI工具(客服、文案生成、数据分析)。
未来,会有更多行业知识通过微调注入AI,催生出无数行业专属智能体,让AI从“可用”变“好用”“专用”。期待你用微调打造专属AI助手,抓住大模型生产力革命机遇!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号