机器学习实战-原理篇
一.简介
机器学习之父 Arthur Samuel 对机器学习的定义是:在没有明确设置的情况下,使计算机具有学习能力的研究领域。国际机器学习大会的创始人之一 Tom Mitchell 对机器学习的定义是:计算机程序从经验 E 中学习,解决某一任务 T,进行某一性能度量 P,通过 P 测定在 T 上的表现因经验 E 而提高。
而机器学习的厉害之处就在于,它能利用计算机的运算能力,从大量的数据中发现一个“函数”或“模型”,并通过它来模拟现实世界事物间的关系,从而实现预测、判断等目的。这个过程的关键是建立一个合适的模型,并能主动地根据这个模型进行“推理”,而这个建模的过程就是机器的“学习”过程。
那么机器学习和我们传统的程序有什么区别呢?实际上,传统程序是程序员把已知的规则定义好后输入给机器的,而机器学习则从已知数据中,通过不断试错、自我优化、自身总结,归纳出规则来。下面这张图,直观地阐述了机器学习和传统程序的区别,你可以看一下。
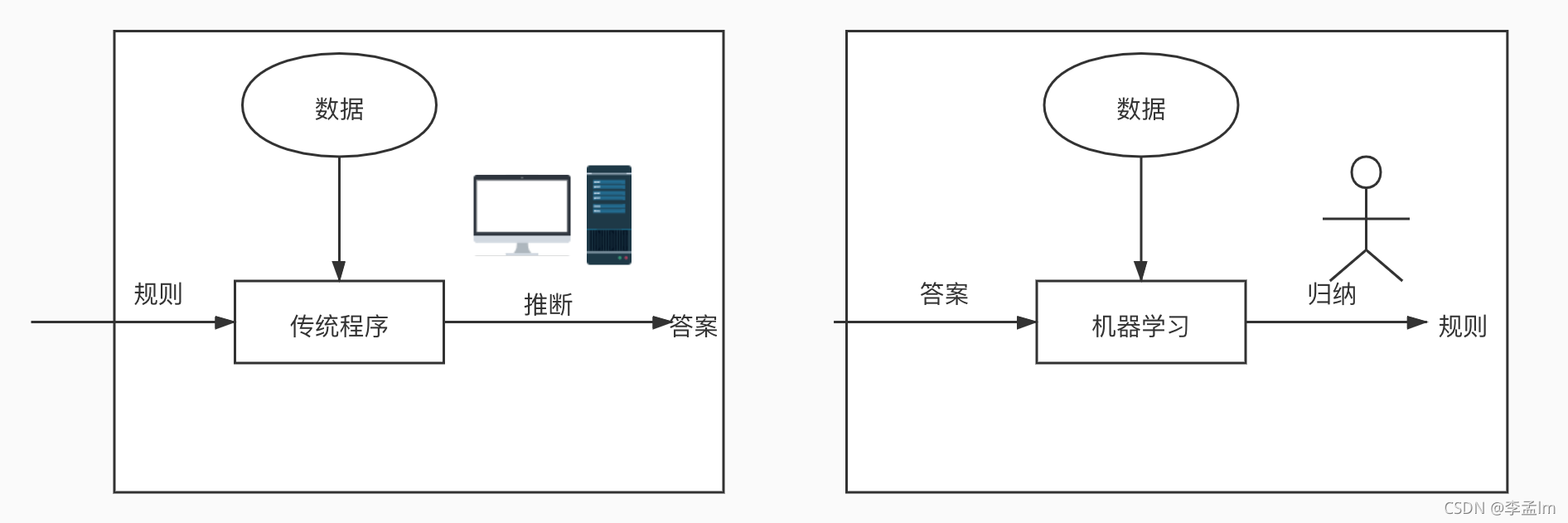
机器学习的本质特征,就是从数据中发现规则
二.建立模型
2.1 简介
机器具体选什么模型、如何训练、怎么调参,我们人类还是要在这个过程中给机器很多指导的。
2.2 示例
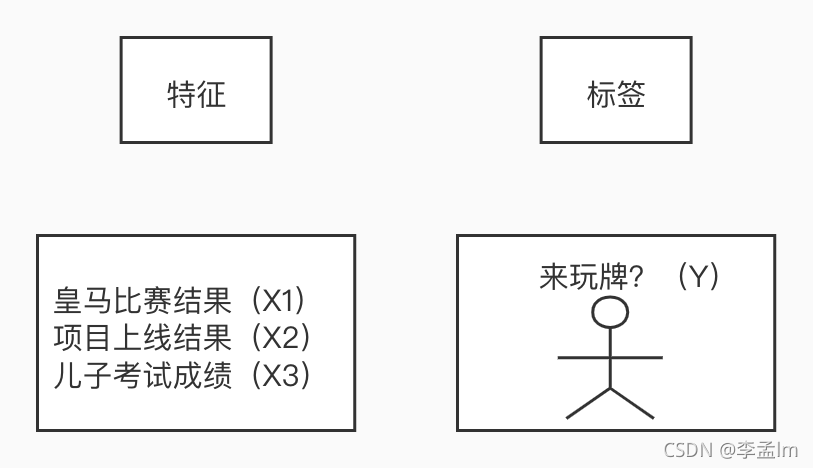
请你想象这样一个场景:你周日约了小李、老王打牌,小李先来了,老王没来。你想打电话叫老王过来。小李说:“你别打电话啦,昨天老王喜欢的球队皇马输球了,他的项目在上个礼拜也没成功上线,再加上他儿子期末考试不及格,他肯定没心情来。”
要预测老王的状况,我们就需要建立一个“预测老王会不会来”的函数,而“皇马输赢”、“项目情况”、“儿子成绩”都是输入到这个函数的自变量,我们设为 x1, x2, x3。这些自变量每一个发生变化,都会影响到函数的结果,也就是因变量 y。
2.3 小结
在机器学习中,这些自变量,就叫作特征(feature),因变量y叫做标签(label)。而一批历史特征和一批历史标签的集合,就是机器学习的数据集。
理解了这些,我们就可以更加“精准”地定义机器是怎么“学习”的了,就是在已知数据集的基础上,通过反复的计算,选择最贴切的函数去描述数据集中自变量 x1, x2, x3, …, xn 和因变量 y 之间的因果关系。这个过程,就叫做机器学习的训练,也叫拟合。
传统程序员来定义函数,而在机器学习中机器训练出函数。
最初用来训练的数据集,就是训练数据集(training dataset)。当机器通过训练找到了一个函数,我们还需要验证和评估,也就是说,这时候我们要给机器另一批同类数据特征,看机器能不能用这个函数推出这批数据的标签。这一过程就是在验证模型是否能够被推广、泛化,而此时我们用到的数据集,就叫验证数据集(validation dataset)。
简单来说,在验证、评估的过程里,我们就是要验证这个函数到底好不好。如果这个函数通过了评估,那就可以在测试数据集(test dataset)上做最终的测试;如果通过不了,就需要继续找新的模型。
三.分类
3.1 简介
标签似乎对于机器学习模型有很重要的指导性意义,因为机器必须根据已有的数据来找到特征和标签之间的关系。
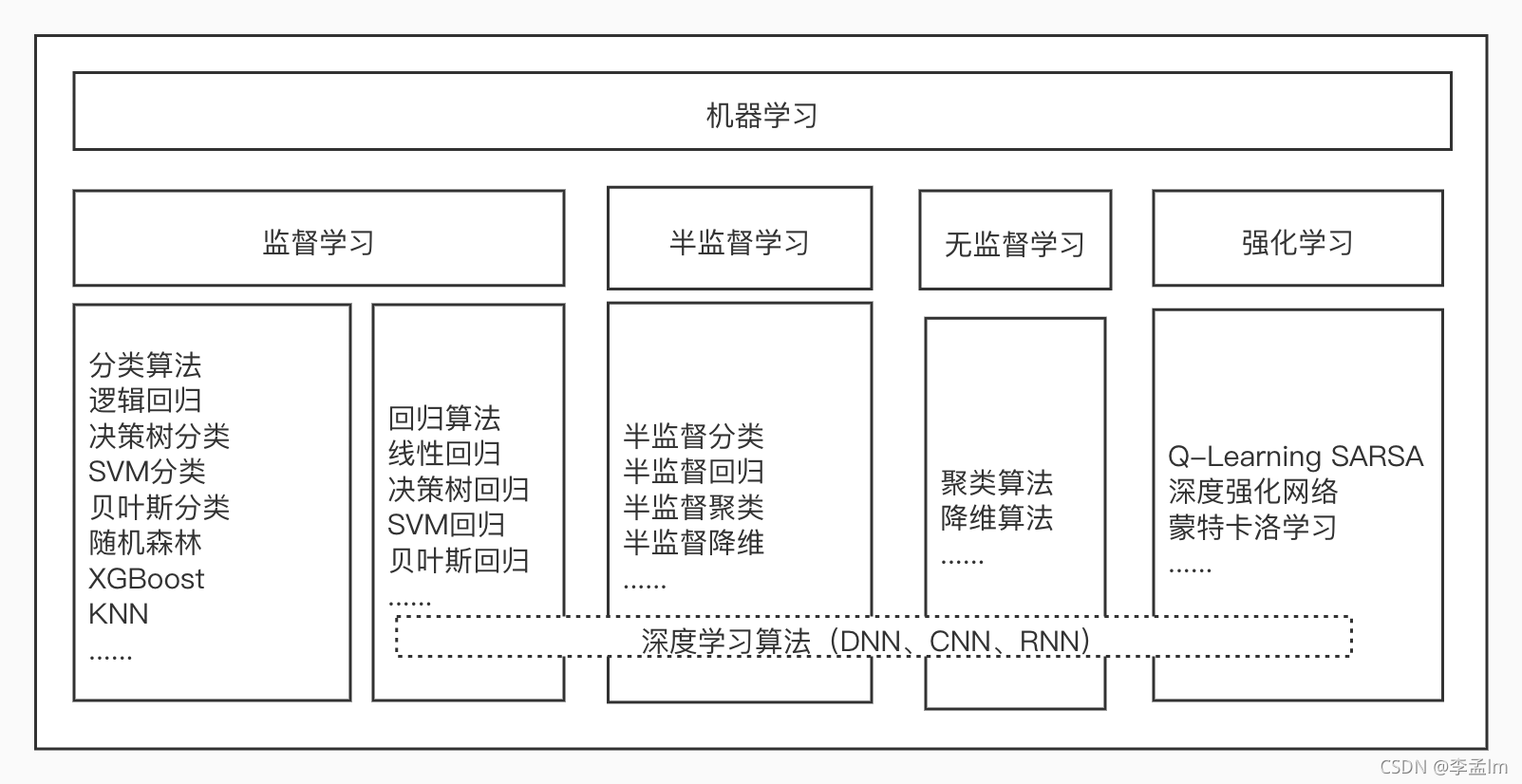
3.2 监督学习
训练集全部有标签。
在监督学习中,我们需要重点关注的是监督学习问题的分类。
明确要解决的问题是机器学习项目的第一步,也是非常重要的一步。如果我们不了解问题的类型,就无法选择合适的算法。
根据标签特点,监督学习可以分为两类
回归问题的标签是连续数值
比如,如果我们天天给老王的情绪从 1 到 100 打分,那要预测老王今天的情绪,这就是个回归问题。再比如说预测房价,股市,天气情况,这都是回归类型的问题。在我们这个课程里,我特地准备了预测客户的生命周期价值、预测产品转化率等回归项目,你可以在这些项目里学会解决各种回归问题的算法和实战套路。
分类问题的标签是离散性数值
比如,预测老王今天会不会来打牌,这就是个分类问题。而我们平时看到的鉴别高欺诈风险的客户、辅助诊断来访者是否患病、人脸识别等等,这些都属于分类问题的应用。在我们的课程中,我也为你设置了对应的分类实战,包括判断客户是否会流失、判断两款裂变模式哪个更有效等,帮你掌握解决各种分类问题的算法和实战套路。
3.3 无监督学习
无监督学习就是为没有标签的数据而建的模型,目前它大多只应用在聚类、降维等有限的场景中,往往是作为数据预处理的一个子步骤显显身手。
训练集没有标签
3.4 半监督学习
在训练数据集中,有的数据有标签,有的数据没有标签,我们叫做半监督学习(semi-supervised learning)。
就是使用大量无标签数据和一部分有标签数据建模。这往往是因为获取数据标签的难度很高。半监督学习的原理、功能和流程与监督学习是很相似的,区别主要在于多了“伪标签的生成”环节,也就是给无标签的数据人工“贴标签”。
四.强化学习
强化学习研究的目标,智能体如何基于环境而做出行动反应,以取得最大化的累积奖励。这里的"智能体",其实我们可以把它理解一种机器学习模型。
强化学习和监督学习的差异在于:监督学习是从数据中学习,而强化学习是从环境给它的奖惩中学习。
强化学习智能体在调整策略的时候需要思路比较长远,它不一定每次都明确地选择最优动作,而是要在探索(未知领域)和利用(当前知识)之间找到平衡。它反复试错、不断收集反馈,收集可供自己学习的信号,每经过一个训练周期,都变得比原来强一点,经过亿万次的训练能变得非常强大。
从监督学习,到无监督学习,到半监督学习再到强化学习,这就形成了一个完整的闭环。所有机器学习领域中的问题和算法都可以归入其中的某个类别。
五.深度学习
深度学习是一种使用深层神经网络算法的机器学习模型,也就是一种算法。这个算法可以应用在监督学习、半监督学习和无监督学习里,也可以应用在强化学习中。
虽说深度学习中用的算法叫神经网络算法,但是这个“神经网络”(Artificial Neural Network, ANN)和人脑中的神经网络没啥大的关联,它是数据结构和算法形成的机器学习模型。
我们知道,长期以来,图形图像、自然语言和文本的处理是计算机行业的难题,因为这类信息的数据集,并不是结构化的,需要人工根据信息的类型来选择特征进行提取,这样对于特征的提取是有限的,就拿图像来说,只能提取出一些简单的滤波器。
深层神经网络的厉害之处在于,它能对非结构的数据集进行自动的复杂特征提取,完全不需要人工干预。也就是说,深度学习让这个曾经的“难题”一下子变得非常容易。
六.总结
- 机器学习是一种从数据生成规则、发现模型,来帮助我们预测、判断、分组和解决问题的技术。
- 机器和传统程序最大的不同就是,机器学习不是程序员直接编写函数的技术,是让机器通过“训练”得出函数。而我们做机器学习项目,就是要选定一个算法,然后用数据训练机器,找到一族函数中最适合的那一个,形成模型。
- 机器学习分为四大类,分别是监督学习、无监督学习和半监督学习和强化学习。
- 深度学习,我们说它是一种使用深层神经网络的模型,可以应用于上述四类机器学习中。深度学习擅长处理非结构化的输入,在视觉处理和自然语言处理方面都很厉害。
参考
《零基础实战机器学习》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号