Multi-Paxos不是一个算法,而是统称
简介
兰伯特提到的 Multi-Paxos 是一种思想,不是算法。而 Multi-Paxos 算法是一个统称,它是指基于 Multi-Paxos 思想,通过多个 Basic Paxos 实例实现一系列值的共识的算法(比如 Chubby 的 Multi-Paxos 实现、Raft 算法等)。
兰伯特关于 Multi-Paxos 的思考
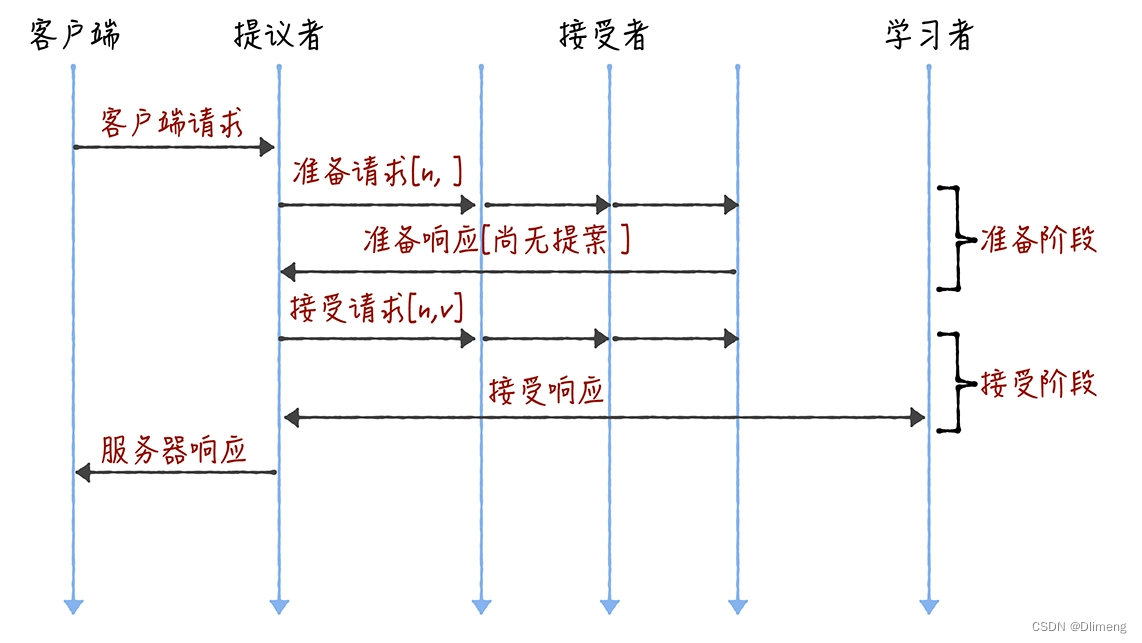
Basic Paxos 是通过二阶段提交来达成共识的。
在第一阶段,也就是准备阶段,接收到大多数准备响应的提议者,才能发起接受请求进入第二阶段(也就是接受阶段)
问题
如果多个提议者同时提交提案,可能出现因为提案编号冲突,在准备阶段没有提议者接收到大多数准备响应,协商失败,需要重新协商。你想象一下,一个 5 节点的集群,如果 3 个节点作为提议者同时提案,就可能发生因为没有提议者接收大多数响应(比如 1 个提议者接收到 1 个准备响应,另外 2 个提议者分别接收到 2 个准备响应)而准备失败,需要重新协商。
2 轮 RPC 通讯(准备阶段和接受阶段)往返消息多、耗性能、延迟大。你要知道,分布式系统的运行是建立在 RPC 通讯的基础之上的,因此,延迟一直是分布式系统的痛点,是需要我们在开发分布式系统时认真考虑和优化的。
领导者(Leader)
领导者节点作为唯一提议者
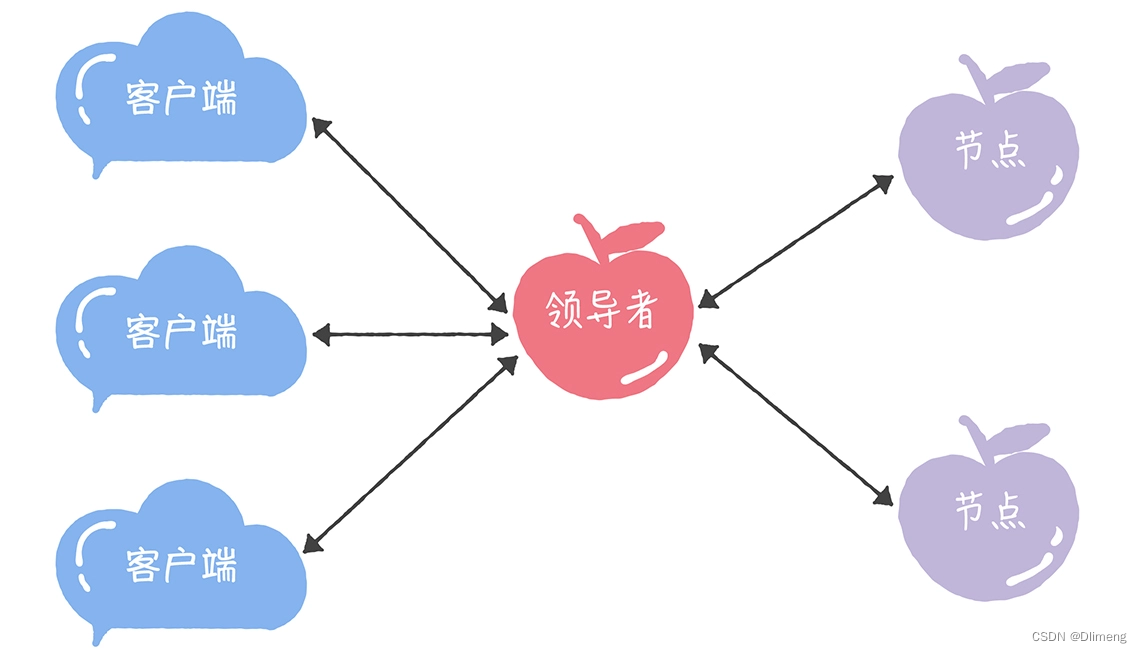
- 在论文中,兰伯特没有说如何选举领导者,需要我们在实现 Multi-Paxos 算法的时候自己实现。
- 比如在 Chubby 中,主节点(也就是领导者节点)是通过执行 Basic Paxos 算法,进行投票选举产生的
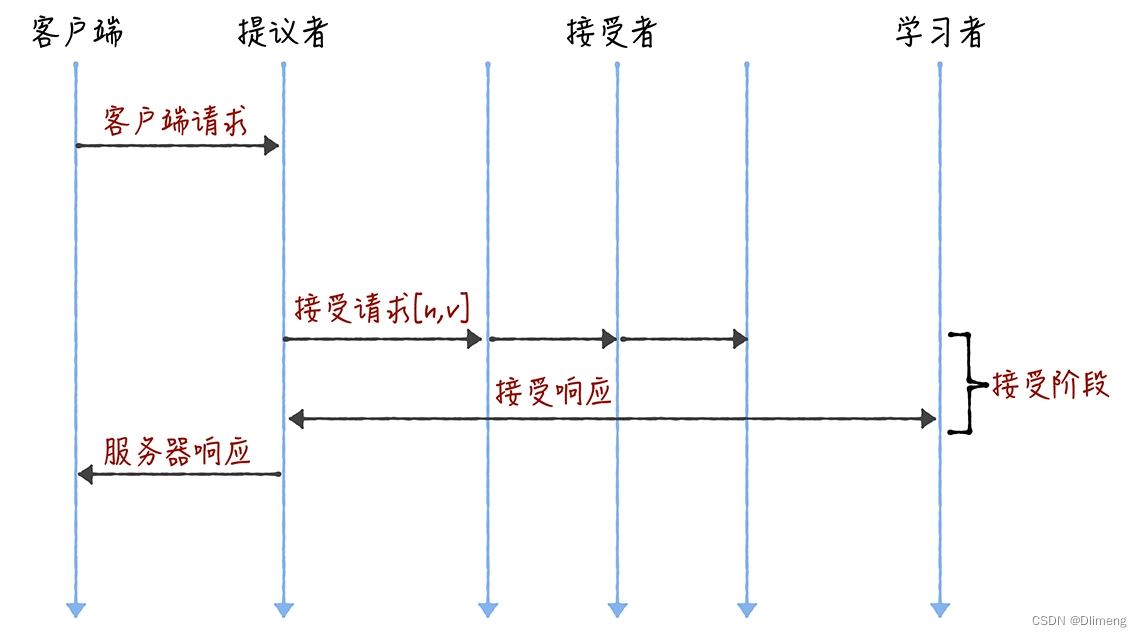
优化 Basic Paxos 执行
当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段
Chubby 的 Multi-Paxos 实现
首先,它通过引入主节点,实现了兰伯特提到的领导者(Leader)节点的特性。也就是说,主节点作为唯一提议者,这样就不存在多个提议者同时提交提案的情况,也就不存在提案冲突的情况了。
另外,在 Chubby 中,主节点是通过执行 Basic Paxos 算法,进行投票选举产生的,并且在运行过程中,主节点会通过不断续租的方式来延长租期(Lease)。比如在实际场景中,几天内都是同一个节点作为主节点。如果主节点故障了,那么其他的节点又会投票选举出新的主节点,也就是说主节点是一直存在的,而且是唯一的。
其次,在 Chubby 中实现了兰伯特提到的,“当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段”这个优化机制。
最后,在 Chubby 中,实现了成员变更(Group membership),以此保证节点变更的时候集群的平稳运行。
最后,我想补充一点:在 Chubby 中,为了实现了强一致性,读操作也只能在主节点上执行。 也就是说,只要数据写入成功,之后所有的客户端读到的数据都是一致的。具体的过程,就是下面的样子。
所有的读请求和写请求都由主节点来处理。当主节点从客户端接收到写请求后,作为提议者,执行 Basic Paxos 实例,将数据发送给所有的节点,并且在大多数的服务器接受了这个写请求之后,再响应给客户端成功

 浙公网安备 33010602011771号
浙公网安备 33010602011771号