数据结构之哈夫曼树
数据结构之哈夫曼树
实验要求:
- 设有字符集:S={a,b,c,d,e,f,g,h,i,j,k,l,m,n.o.p.q,r,s,t,u,v,w,x,y,z}。
给定一个包含26个英文字母的文件,统计每个字符出现的概率,根据计算的概率构造一颗哈夫曼树。
并完成对英文文件的编码和解码。 - 要求:
- 准备一个包含26个英文字母的英文文件(可以不包含标点符号等),统计各个字符的概率
- 构造哈夫曼树
- 对英文文件进行编码,输出一个编码后的文件
- 对编码文件进行解码,输出一个解码后的文件
- 撰写博客记录实验的设计和实现过程,并将源代码传到码云
- 把实验结果截图上传到云班课
什么是哈夫曼树?
- 基本概念
- 最优二叉树:平均编码长度最短。
- 结点之间的路径:一个结点到另一个结点所经过的结点次序。
- 结点之间的路径长度:两个结点之间边的条数。
- 树的路径长度:从根结点到每个叶子结点的路径长度之和。
- 带权路径: 路径上加上的实际意义 。如汽车到下一站的距离我们叫做权值.
- 树的带权路经长度:每个叶子结点到根的路径长度权值之和,记作WPL。
还是汽车的例子,汽车到达天津有2条路 可以走。第一条路经过3个站,每个站相距13km。第二条有2个站,每个站相距18km。那么有距离的路我们叫做带权路径。根结点为天津的树,那么第一条路带权路径为 3*13 = 39,第二条为2*18。树的带权路径WPL 313+218.
- 哈夫曼树: 二叉树是n个结点的结合,它的度(所有孩子个数的最大值)小于等于2。n个结点构成一个二叉树有许多方法。使二叉树的带权路径最小的树,我们叫做哈夫曼树。
- 哈夫曼树的特点:权值越大,所离根结点越近。
哈夫曼树有什么用?
- 介绍了这么多概念,不知道它有什么用,让初学者感觉数据结构没什么劲。
- 哈夫曼树主要用在数据的压缩如JPEG格式图片,在通信中我们可以先对发送的数据进行哈夫曼编码压缩数据提高传输速度。
- 查询优化:在工作中我们我们身边放许多工具,由于空间限制我们不能把所有工具放在我们最容易拿到的地方,所有我们把使用频率最高的工具放在最容易的位置。同样的道理在查询的时候我们把查询频率最高的数据建立索引,这些都是使用了哈夫曼算法的思想。
怎么构造哈夫曼树?
- 为了理解怎么构造哈夫曼树我们举个例子:
- 我们现在有一组字符:
- 他们出现的概率为:{0.19, 0.21, 0.02, 0.03, 0.06, 0.07, 0.1, 0.32}.
- 为了让我们看起来清楚,我们把它整数化::{19, 21, 2, 3, 6, 7, 10, 32}.
- 即:8个结点的权值大小如下:
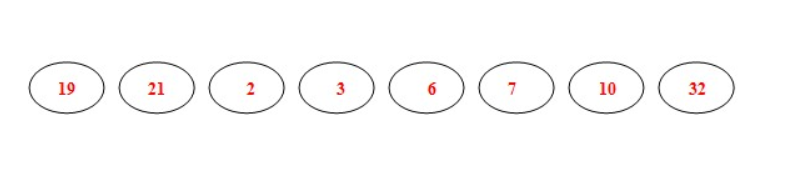
- 从19,21,2,3,6,7,10,32中选择两个权小结点。选中2,3。同时算出这两个结点的和5。
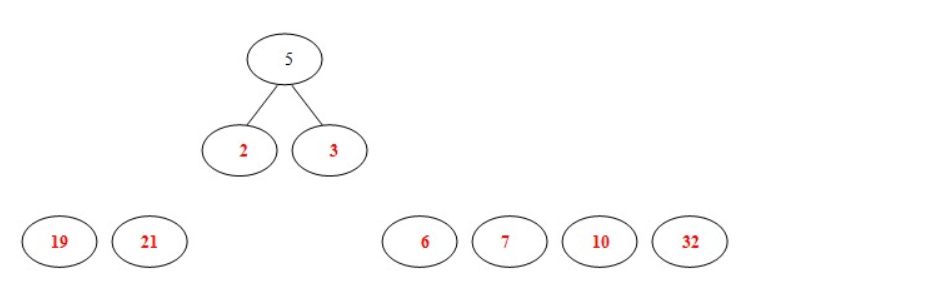
- 从19,21,6,7,10,32,5中选出两个权小结点。选中5,6。同时计算出它们的和11。
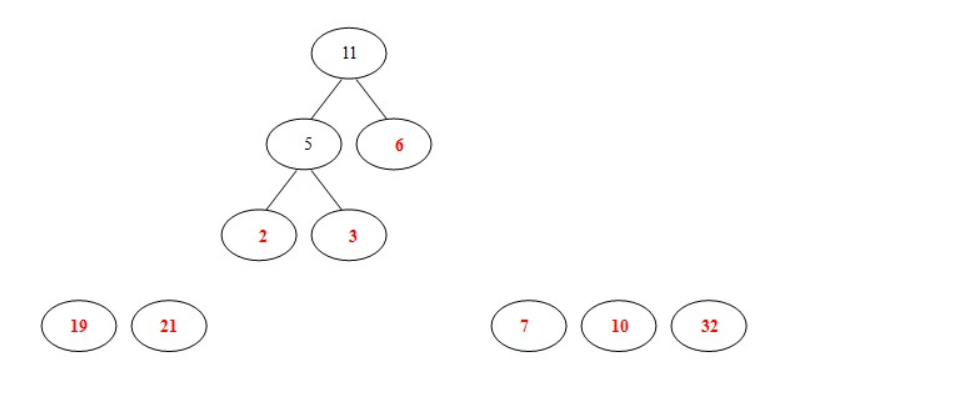
- 从19,21,7,10,32,11中选出两个权小结点。选中7,10。同时计算出它们的和17。
注:这时选出的两个数字都不是原来的二叉树里面的结点,所以要另外开一棵二叉树。
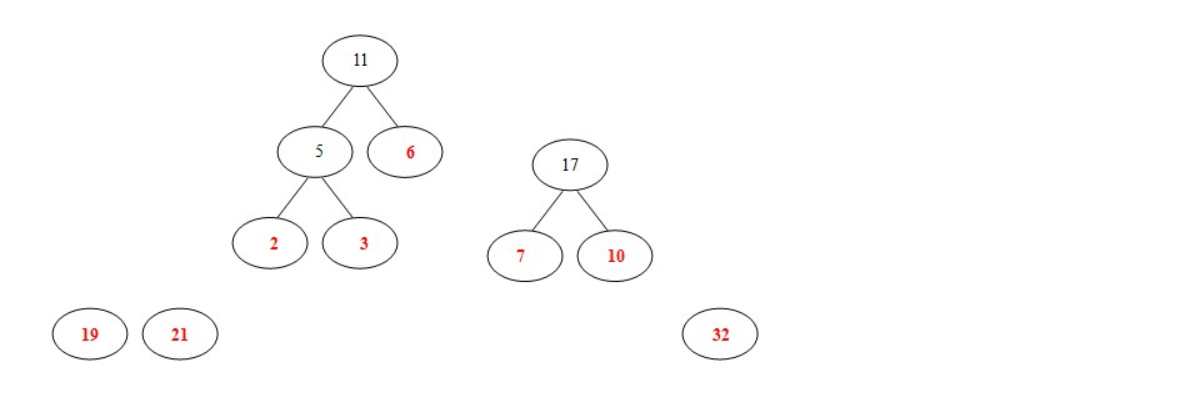
- 从19,21,32,11,17中选出两个权小结点。选中11,17。同时计算出它们的和28。
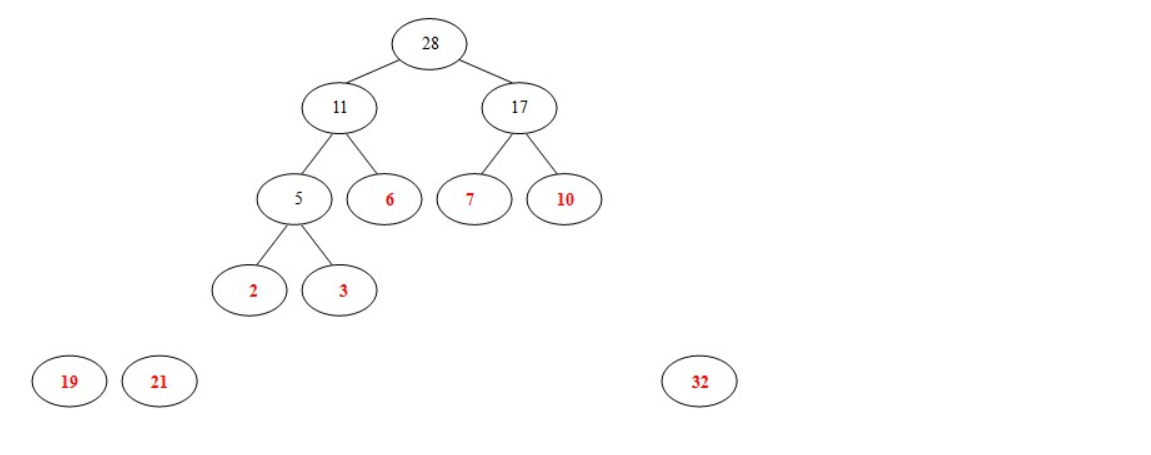
- 从19,21,32,28中选出两个权小结点。选中19,21。同时计算出它们的和40。 另起一颗二叉树。
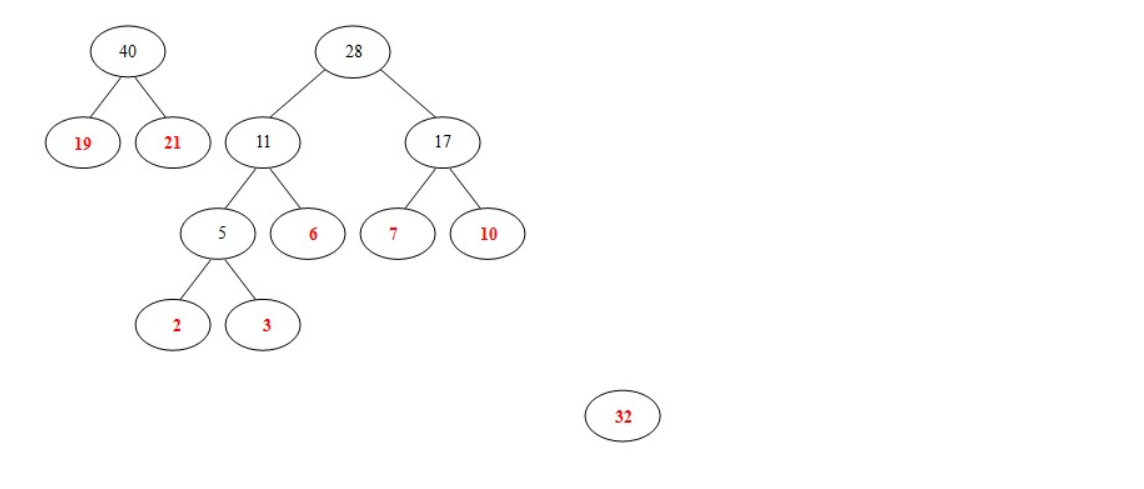
- 从32,28, 40中选出两个权小结点。选中28,32。同时计算出它们的和60。
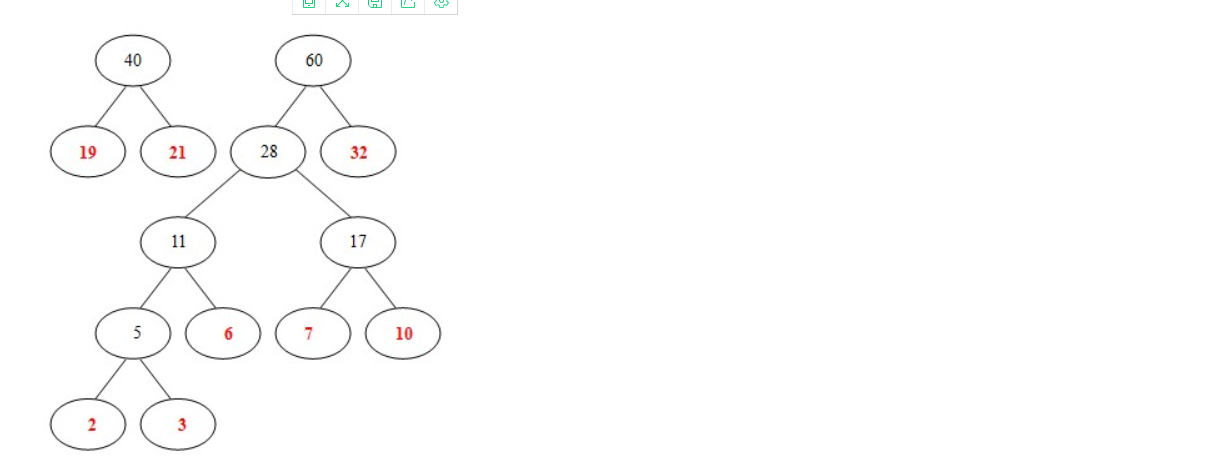
- 从 40, 60中选出两个权小结点。选中40,60。同时计算出它们的和100。 好了,此时哈夫曼树已经构建好了。

构造哈夫曼树会出现什么问题?
- 在课堂时间的时候我就出现了以问题:当一组数据中最小的两个数加起来的时候如果出现和原来的一个数据相同怎么办?
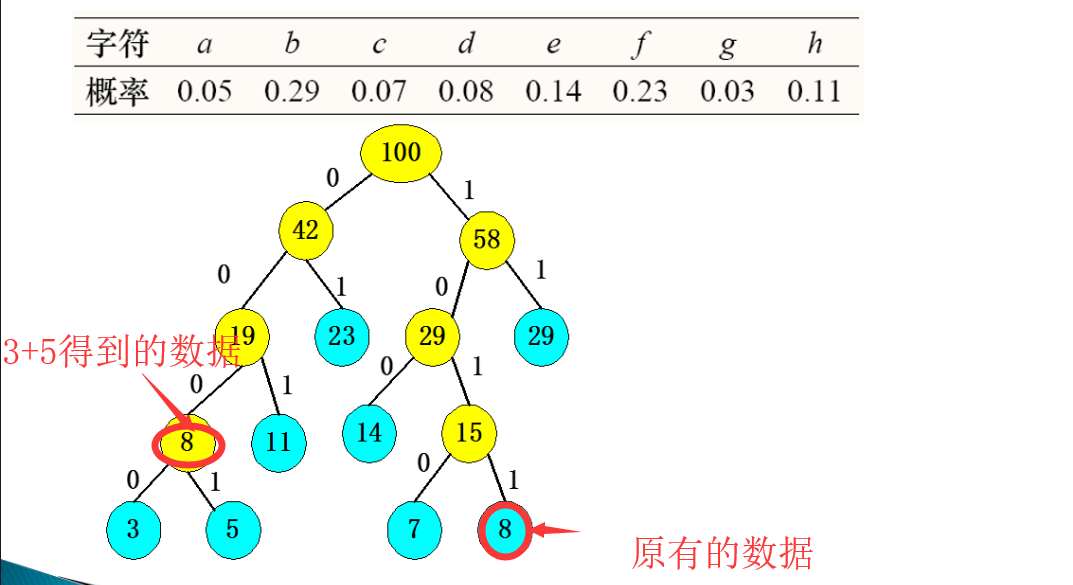
- 还有可能出现这种情况:

- 现在我们来算一下这两种结果的路径长度:
- WPL1=(3+5+7+8)*4+(11+14)*3+(23+29)*2=271
- WPL2= (3+5)*+7*4+(8+11+14)*3+(23+29)*2=271
- 经过计算,这两种方式的路径长度经计算得到的WPL相等
- 但是,为了得到统一的结果,我们统一将生成相等放到与之相等的后面,也就是说我们生成的结果为第一种。
Huffman算法实现。
- 构造哈夫曼树结点:
- 结点类我们必须用几个属性来完善它,使它能更好地为我们工作:

public class HuffmanTreeNode implements Comparable<HuffmanTreeNode>{ private int weight;//结点所带的权重,一般为概率的大小 private HuffmanTreeNode parent;//父结点 private HuffmanTreeNode left;//左子结点 private HuffmanTreeNode right;//右子节点 private char element;//元素值 } //CompareTo 方法 用于比较结点之间的权重weight @Override public int compareTo(HuffmanTreeNode huffmanTreeNode) { if (this.weight>huffmanTreeNode.weight) return 1; else{ if (this.weight<huffmanTreeNode.weight) return -1; else return 0; } } - 结点类我们必须用几个属性来完善它,使它能更好地为我们工作:
- 构造哈夫曼树:
- 首先构造一个根结点以及放26个英文字母的数组:
private HuffmanTreeNode mRoot; // 根结点 private String[] codes = new String[26];- 然后构造哈夫曼树:
/** * 构造哈夫曼树的方法 * @param array 一个数组,里面的数据是元素对应的权值 */ public HuffmanTree(HuffmanTreeNode[] array) { HuffmanTreeNode parent = null; ArrayHeap<HuffmanTreeNode> heap = new ArrayHeap(); for (int i=0;i<array.length;i++) { heap.addElement(array[i]); } for(int i=0; i<array.length-1; i++) { //去除最小的两个元素生成一棵树 HuffmanTreeNode left = heap.removeMin(); HuffmanTreeNode right = heap.removeMin(); parent = new HuffmanTreeNode(left.getWeight()+right.getWeight(),' ',null,left,right); left.setParent(parent); right.setParent(parent); heap.addElement(parent); } mRoot = parent; } - 编写哈夫曼码:
- 首先编写一个中序遍历的方法,把结点都放在数组中。
protected void inOrder( HuffmanTreeNode node, ArrayList<HuffmanTreeNode> tempList) { if (node != null) { inOrder(node.getLeft(), tempList); if (node.getElement()!=' ') tempList.add(node); inOrder(node.getRight(), tempList); } }- 然后进行编码:从下往上,若为左孩子,则为0,反之为1,放入栈中,直至根节点,再将栈中元素全部取出,得到该结点的编码。
public String[] getEncoding() { ArrayList<HuffmanTreeNode> arrayList = new ArrayList(); inOrder(mRoot,arrayList); for (int i=0;i<arrayList.size();i++) { HuffmanTreeNode node = arrayList.get(i); String result =""; int x = node.getElement()-'a'; Stack stack = new Stack(); while (node!=mRoot) { if (node==node.getParent().getLeft()) stack.push(0); if (node==node.getParent().getRight()) stack.push(1); node=node.getParent(); } while (!stack.isEmpty()) { result +=stack.pop(); } codes[x] = result; } return codes; } - 哈夫曼解码:
- 思想:从我们产生的编码文件中读取编码,如果遇到为0,则指向左孩子,遇到1指向右孩子,直到指向叶子节点,即我们要找的结点,然后又从根结点重新开始进行下面的编码。
- 代码方法:
for (int i = 0; i < s1.length(); i++) { if (s1.charAt(i) == '0') { if (huffmanTreeNode.getLeft() != null) { huffmanTreeNode = huffmanTreeNode.getLeft(); } } else { if (s1.charAt(i) == '1') { if (huffmanTreeNode.getRight() != null) { huffmanTreeNode = huffmanTreeNode.getRight(); } } } if (huffmanTreeNode.getLeft() == null && huffmanTreeNode.getRight() == null) { result2 += huffmanTreeNode.getElement(); huffmanTreeNode = huffmanTree.getmRoot(); } } - 写入文件:
- 方法代码:
File file2 = new File("F:\\HuffmanCode2.txt"); FileWriter fileWriter1 = new FileWriter(file1); fileWriter1.write(result2);
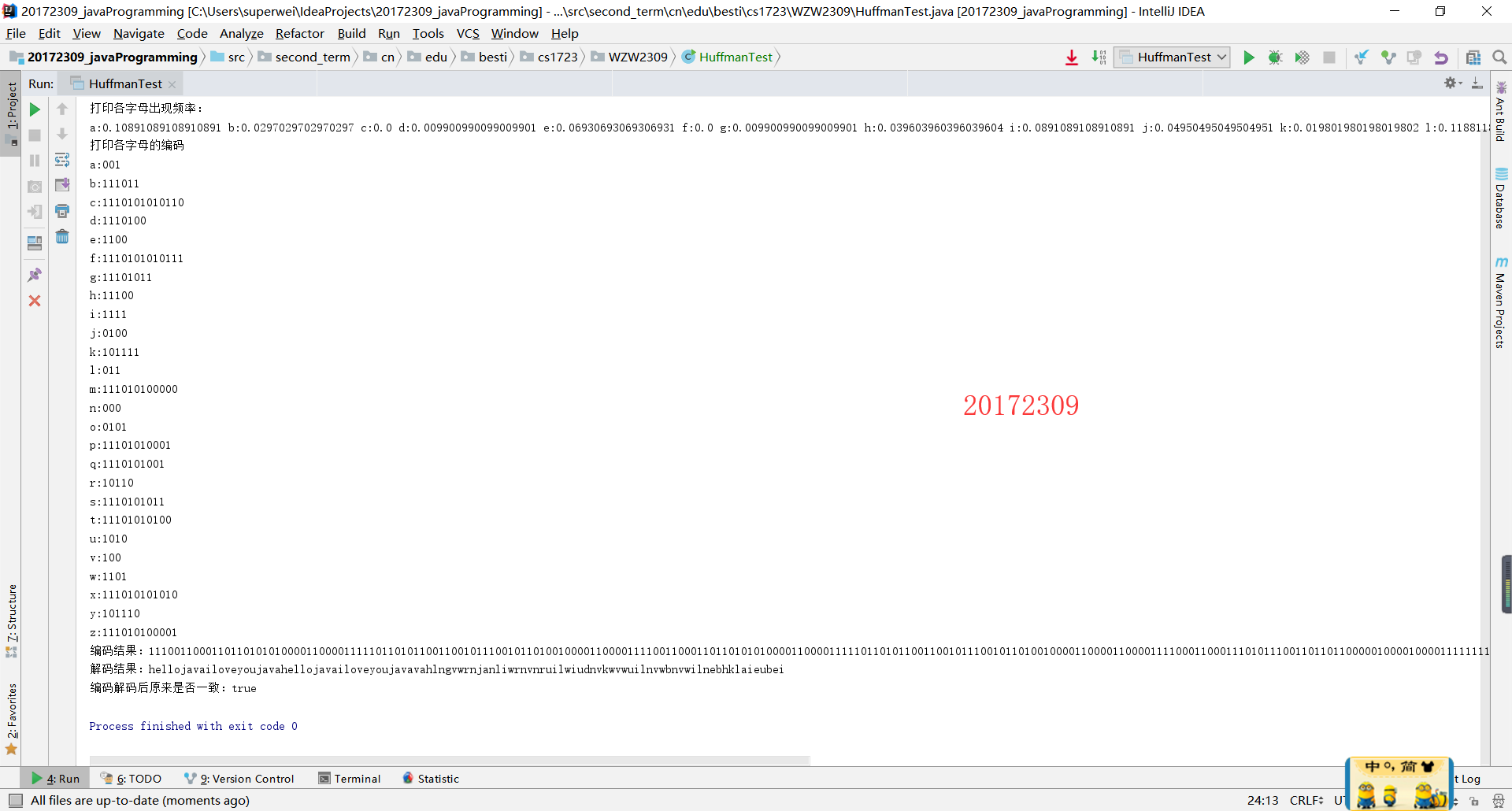
运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号