
组合数据类型练习,英文词频统计实例
1、列表实例:由字符串创建一个作业评分列表,做增删改查询统计遍历操作。例如,查询第一个3分的下标,统计1分的同学有多少个,3分的同学有多少个等
score=list('21223113321') print('作业评分列表:',score) score.append('3') print('增加:',score) score.pop() print('删除:',score) score.insert(2,'1') print('插入:',score) score[2]='2' print('修改:',score) print('第一个3分的下标:',score.index('3')) print('1分的个数:',score.count('1')) print('3分的个数:',score.count('3'))
2.字典实例:建立学生学号成绩字典,做增删改查遍历操作
students = {'01':'1','02':'3','03':'2','04':'3','05':'2','06':'1','07':'2'}
ID = students.keys()
mark = students.values()
print("学生信息",students)
print("学生学号",ID)
print("学生成绩",mark)
print("成绩查询:",students.get('05'))
students['07']='4'
print("成绩修改:",students)
students.pop('07')
print("删除学生:",students)
students['08']='3'
print("增加学生:",students)
 3、列表,元组,字典,集合的遍历,总结列表,元组,字典,集合的联系与区别
3、列表,元组,字典,集合的遍历,总结列表,元组,字典,集合的联系与区别
a = list('21456') b = tuple('12626') c = {'01':132,'03':2326,'03':51532,'04':2561,'05':5561,'06':521} d = {2,9,1,4,7,12,8,6} print("列表的遍历:") for i in a: print(i,end=' ') print("\n元组的遍历:") for i in b: print(i,end=' ') print("\n字典的遍历:") for i in c: print(i,":",c.get(i)) print("集合的遍历:") for i in d: print(i,end=' ')

4、英文词频统计实例
A.待分析字符串
news = '''BERLIN - It's almost certain that German Chancellor Angela Merkel's Union Party will win the most votes in the federal election on Sept 24, but uncertainties still remain concerning the performance of smaller parties, which may play key roles in the formation of a new German government. According to the latest polling, the Union, formed by Merkel's Christian Democratic Union (CDU) and its Bavarian sister Christian Social Union (CSU), are enjoying a comfortable lead over the Social Democratic Party (SPD), with a support rate of around 36 percent versus around 23 percent. German people and media organizations believe that the CDU/CSU will win the most votes and the SPD the second most in the election to be held in less than a week. Despite SPD leader Martin Schulz's spare-no-effort attitude, many German people believe that the SPD lost their last chance to change the game after the bloodless TV debate between Merkel and the former European Parliament president. But the story will not end here, as what's more important is the formation of the new government, in which smaller parties will play key roles, or even serve as kingmakers by joining hands with one of the two big parties. These smaller parties -- the Greens, the Free Democratic Party (FDP), Die Linke (The Left), and the far-right Alternative fuer Deutschland (AfD) -- are in a tight race to become the third largest party in the Bundestag. According to polling results, the support rates of all four of the smaller parties stand at eight to 11 percent. However, voter turnout, uncertain as it is, could still be a game changer in the election. Many people have not yet decided whether they will vote or, if they do, which party they will vote for. Schulz said, perhaps in exaggeration, that almost half of voters had not decided. Among those who are undecided, some believe that Merkel's refugee policies are too radical and don't take into consideration the interests of the German people. However, they do not want to support the anti-immigration AfD either. Some German voters perceive all the parties as having little difference to one another and their policies are converging, thus resulting in their indecision. Voter turnout and swing votes may not change the situation between the CDU/CSU and the SPD, but may largely decide the standings of smaller parties. The German election rule sets a 5-percent-vote hurdle to be elected into the Bundestag, excluding other smaller parties. The German electoral system makes it very difficult for any one party to form a government on its own.'''
B.分解提取单词
a.大小写 txt.lower()
news = open('test.txt','r').read() news = news.lower() print("全部小写字母:",news)

b.分隔符'.,:;?!-_’
news = open('test.txt','r').read() news = news.lower() for i in '.,:;?!-_': news = news.replace(i,' ') print("去除分隔符后:",news)

C.计数字典
news = open('test.txt','r').read() news = news.lower() for i in '.,:;?!-_': news = news.replace(i,' ') news = news.split(' ') dic= {} keys = set(news) for i in keys: dic[i] = news.count(i) print("字典模式:",dic)

D.排序list.sort()
news = open('test.txt','r').read() news = news.lower() for i in '.,:;?!-_': news = news.replace(i,' ') news = news.split(' ') dic= {} keys = set(news) for i in keys: dic[i] = news.count(i) wc = list(dic.items()) wc.sort(key=lambda x:x[1],reverse=True) print("出现次数排列:",wc)

E.输出TOP(10)
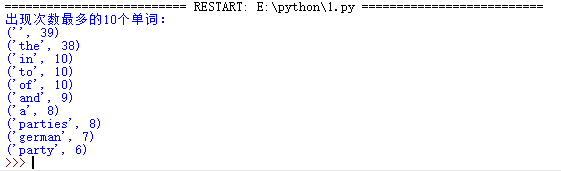
news = open('test.txt','r').read() news = news.lower() for i in '.,:;?!-_': news = news.replace(i,' ') news = news.split(' ') dic= {} keys = set(news) for i in keys: dic[i] = news.count(i) wc = list(dic.items()) wc.sort(key=lambda x:x[1],reverse=True) print("出现次数最多的10个单词:") for i in range(10): print(wc[i])
F.去除部分单词
news = open('test.txt','r').read() exc = {'the','a','of','is','are','to','and','in','will','not','as','that','they',''} news = news.lower() for i in '.,:;?!-_': news = news.replace(i,' ') news = news.split(' ') dic= {} keys = set(news) for i in exc: keys.remove(i) for i in keys: dic[i] = news.count(i) wc = list(dic.items()) wc.sort(key=lambda x:x[1],reverse=True) print("出现次数最多的10个主要单词:") for i in range(10): print(wc[i])



