数据采集与融合第四次作业——董婕
作业1
要求
- 熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内
容。 - 使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、
“深证 A 股”3 个板块的股票数据信息。 - 候选网站:东方财富网http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息
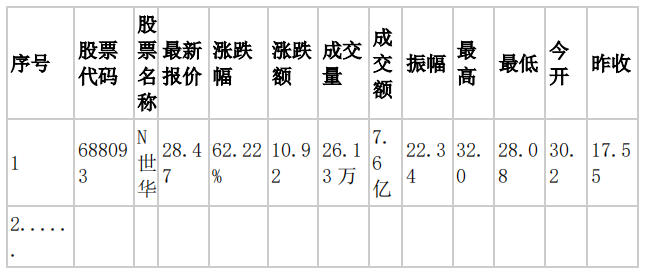
MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
gitee链接
实现过程
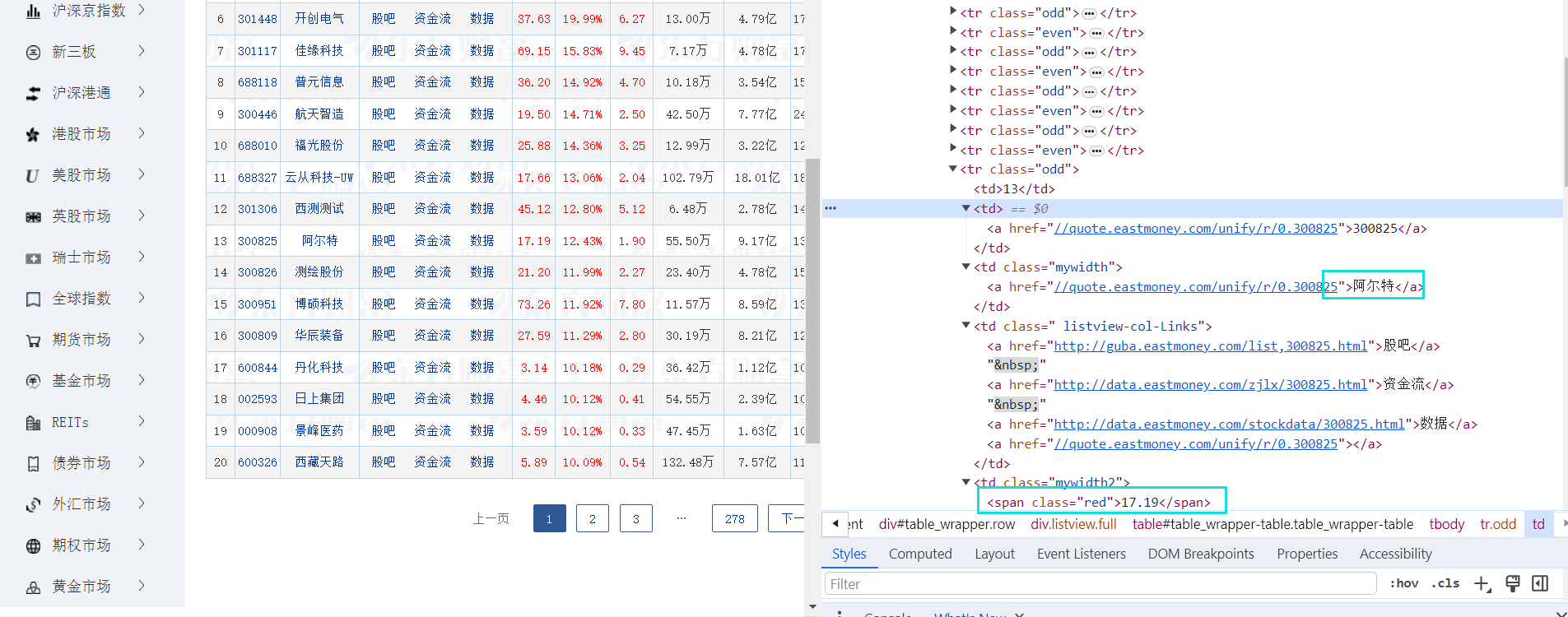
观察页面结构
有些信息在td下的a标签里,有些在span标签里。
翻页
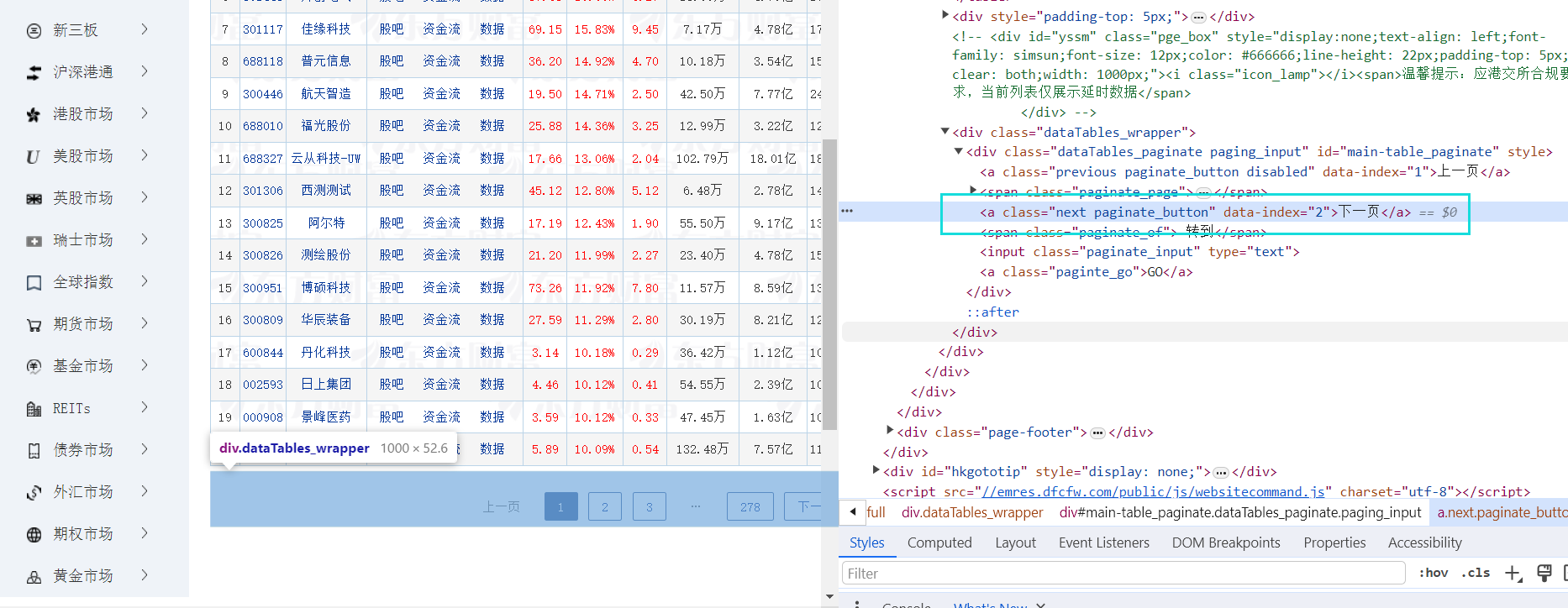
nextPage = self.driver.find_element(By.XPATH, "//div[@class='dataTables_paginate paging_input']/a[2]")
nextPage.click()
完整代码
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
from selenium.webdriver.common.by import By
class MySpider:
# 设置请求头信息
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def startUp(self, url):
# 配置 Chrome 浏览器的选项
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
# 初始化 WebDriver
self.driver = webdriver.Chrome(options=chrome_options)
self.page = 0
self.section = ["nav_hs_a_board", "nav_sh_a_board", "nav_sz_a_board"]
self.sectionid = 0
self.driver.get(url)
try:
print("连接到 MySQL 数据库")
# 连接到 MySQL 数据库
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd="1", db="dong", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
for table in self.section:
# 如果表存在,先删除再创建
self.cursor.execute(f"DROP TABLE IF EXISTS {table}")
# 创建数据表
self.cursor.execute(f"CREATE TABLE {table}(id INT(4) PRIMARY KEY, StockNo VARCHAR(16), StockName VARCHAR(32), StockQuote VARCHAR(32), Changerate VARCHAR(32), Chg VARCHAR(32), Volume VARCHAR(32), Turnover VARCHAR(32), StockAmplitude VARCHAR(32), Highest VARCHAR(32), Lowest VARCHAR(32), Pricetoday VARCHAR(32), PrevClose VARCHAR(32))")
except Exception as err:
print(err)
def closeUp(self):
try:
# 提交事务并关闭连接
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
def insertDB(self, section, id, StockNo, StockName, StockQuote, Changerate, Chg, Volume, Turnover, StockAmplitude, Highest, Lowest, Pricetoday, PrevClose):
try:
# 插入数据到数据库
sql = f"insert into {section}(id,StockNo,StockName,StockQuote,Changerate,Chg,Volume,Turnover,StockAmplitude,Highest,Lowest,Pricetoday,PrevClose) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql, (id, StockNo, StockName, StockQuote, Changerate, Chg, Volume, Turnover, StockAmplitude, Highest, Lowest, Pricetoday, PrevClose))
except Exception as err:
print(err)
def processSpider(self):
time.sleep(2)
try:
# 获取当前页面的所有行
trr = self.driver.find_elements(By.XPATH, "//table[@id='table_wrapper-table']/tbody/tr")
for tr in trr:
# 解析每一行的数据
id = tr.find_element(By.XPATH, ".//td[1]").text
StockNo = tr.find_element(By.XPATH, "./td[2]/a").text
StockName = tr.find_element(By.XPATH, "./td[3]/a").text
StockQuote = tr.find_element(By.XPATH, "./td[5]/span").text
Changerate = tr.find_element(By.XPATH, "./td[6]/span").text
Chg = tr.find_element(By.XPATH, "./td[7]/span").text
Volume = tr.find_element(By.XPATH, "./td[8]").text
Turnover = tr.find_element(By.XPATH, "./td[9]").text
StockAmplitude = tr.find_element(By.XPATH, "./td[10]").text
highest = tr.find_element(By.XPATH, "./td[11]/span").text
lowest = tr.find_element(By.XPATH, "./td[12]/span").text
Pricetoday = tr.find_element(By.XPATH, "./td[13]/span").text
PrevClose = tr.find_element(By.XPATH, "./td[14]").text
section = self.section[self.sectionid]
# 将数据插入数据库
self.insertDB(section, id, StockNo, StockName, StockQuote, Changerate, Chg, Volume, Turnover, StockAmplitude, highest, lowest, Pricetoday, PrevClose)
# 爬取前2页
if self.page < 2:
self.page += 1
print(f"第 {self.page} 页已经爬取完成")
nextPage = self.driver.find_element(By.XPATH, "//div[@class='dataTables_paginate paging_input']/a[2]")
nextPage.click()
time.sleep(10)
self.processSpider()
elif self.sectionid < 3:
# 爬取下一个板块
print(f"{self.section[self.sectionid]} 爬取完成")
self.sectionid += 1
self.page = 0
nextsec = self.driver.find_element(By.XPATH, f"//li[@id='{self.section[self.sectionid]}']/a")
self.driver.execute_script("arguments[0].click();", nextsec)
time.sleep(10)
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url):
print("——————————开始爬取——————————")
self.startUp(url)
print("爬虫进行中")
self.processSpider()
print("——————————爬取结束——————————")
self.closeUp()
spider = MySpider()
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
while True:
print("1.进行爬取")
print("0.退出")
s = input("选择:")
if s == "1":
spider.executeSpider(url)
continue
elif s == "0":
break
结果
运行
数据库
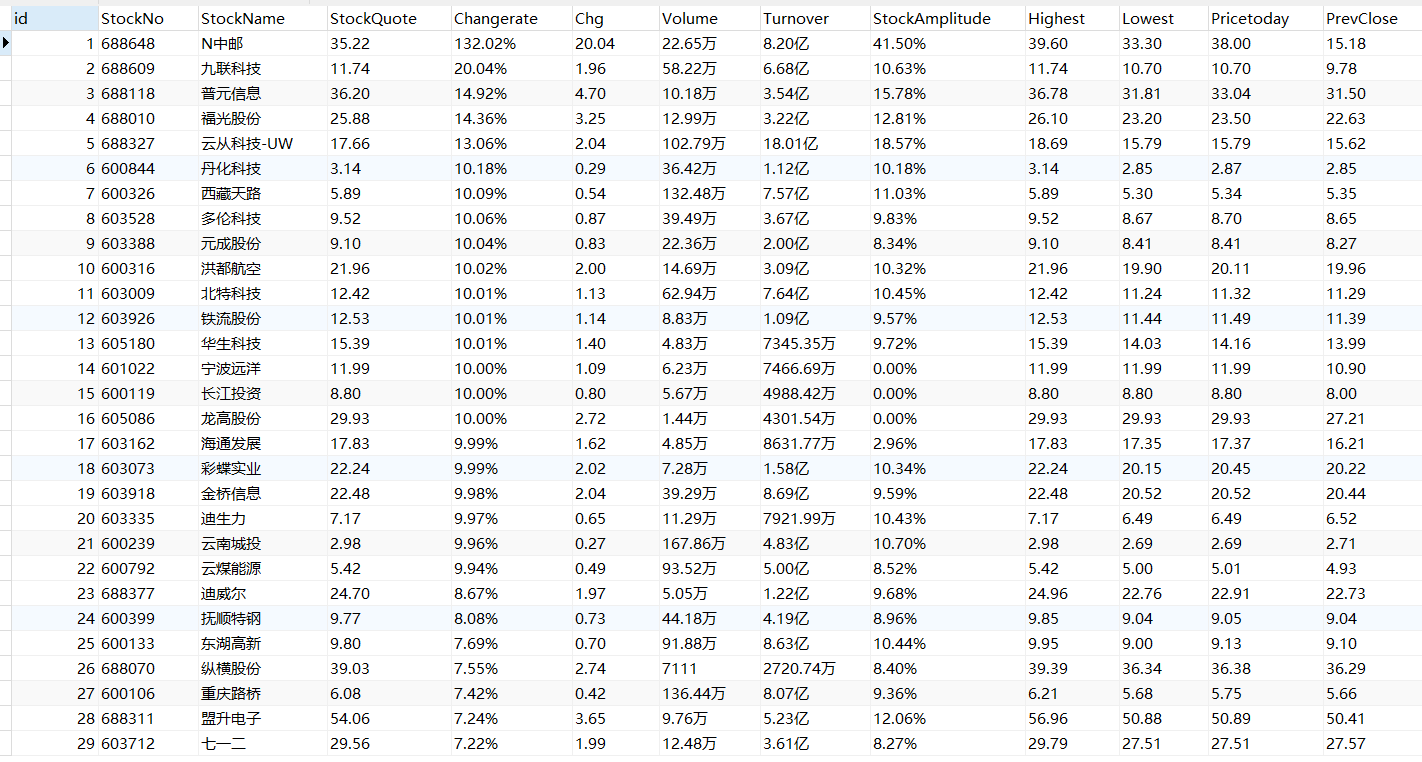
上证 A 股
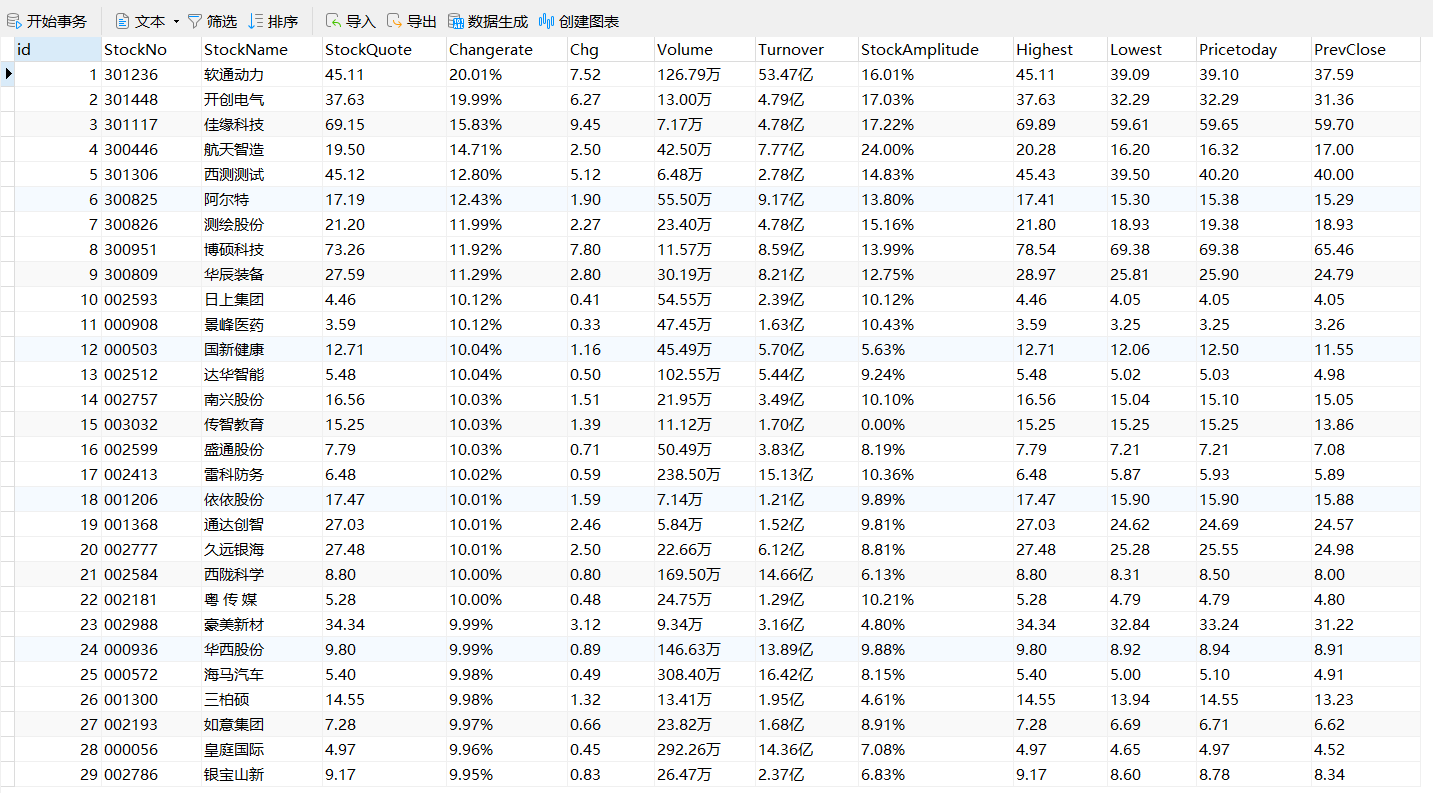
深证 A 股
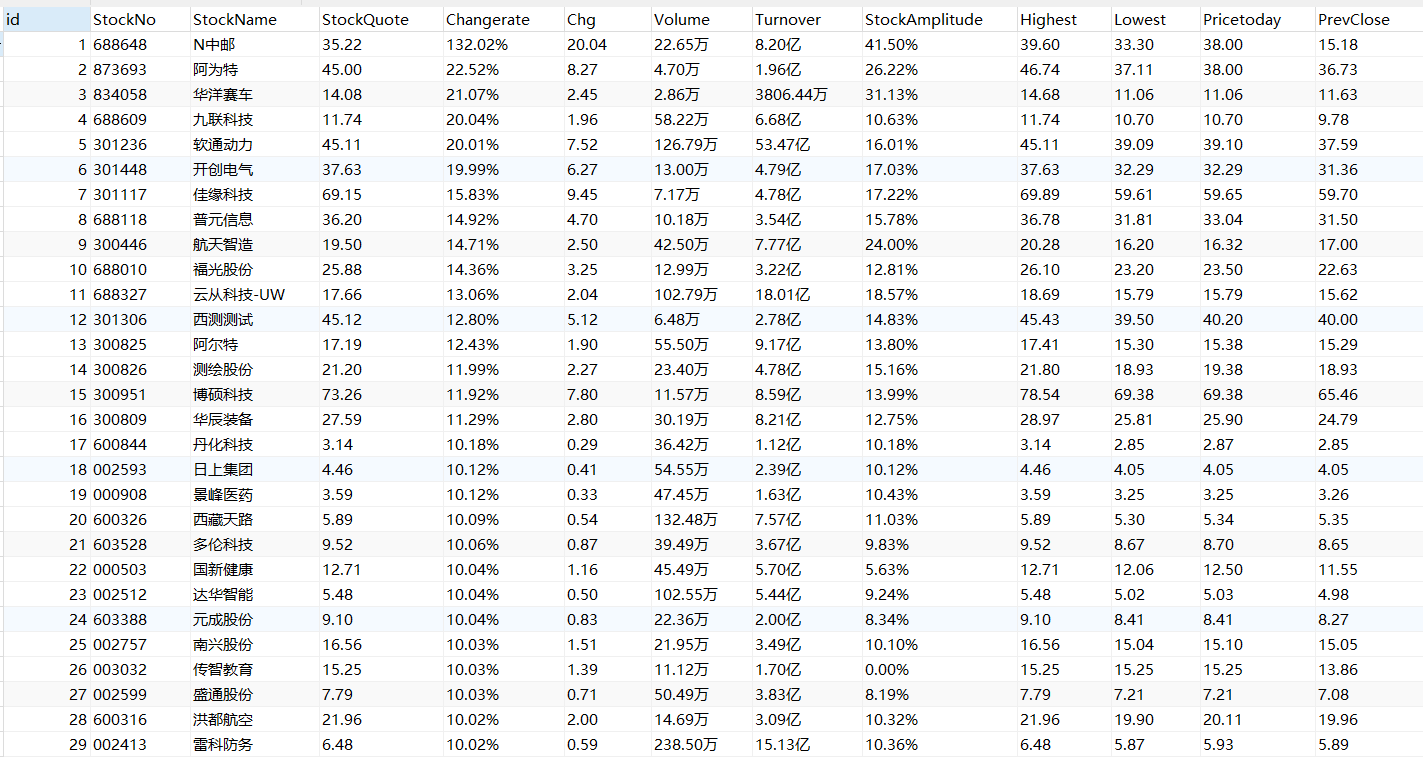
沪深 A 股
心得
跟之前比较类似,但使用了selenium,操作和代码简化了很多,感受到了selenium的强大。
此外,谷歌浏览器总是自动更新,之前118版本的又不能用了,重新下了119版本的。
作业2
要求
- 熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
等待 HTML 元素等内容。 - 使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介) - 候选网站:中国 mooc 网:https://www.icourse163.org
输出信息:MYSQL 数据库存储和输出格式
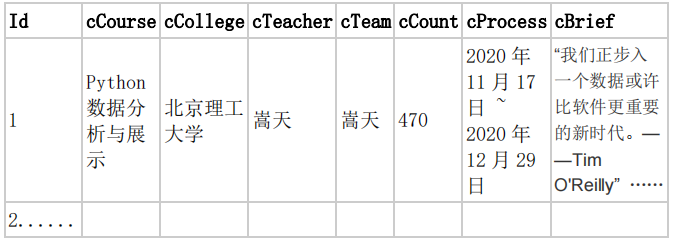
gitee链接:
实现过程
观察页面结构
它有两种登录界面,虽然界面不一样但是登录框的样式是一样的。
另外一种
跟之前的实验题目区别比较大的地方就是要自己写代码实现登录,要先切换到登录框的iframe
# 输入用户名和密码
username = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input')))
username.clear()
username.send_keys("13855980701")
password = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
password.send_keys("DongJie031217")
# 点击登录按钮
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.ID, "submitBtn"))).click()
点击登录按钮后再切换会主界面,定位搜索框进行搜索
# 切换回主页面
driver.switch_to.default_content()
# 等待搜索框出现
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[1]/div/div/div/div/div/div/input')))
# 定位搜索框
search_box = driver.find_element(By.XPATH, '/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[1]/div/div/div/div/div/div/input')
# 在搜索框输入关键词
search_box.send_keys("高数", Keys.RETURN)
完整代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import random
import pymysql
from selenium.common.exceptions import NoSuchElementException
# 连接数据库
conn = pymysql.connect(
host="127.0.0.1",
user="root",
password="1",
database="mooc",
charset="utf8mb4",
cursorclass=pymysql.cursors.DictCursor
)
cursor = conn.cursor()
# 创建表格
cursor.execute('''CREATE TABLE IF NOT EXISTS mooc (
id INTEGER PRIMARY KEY,
course TEXT,
college TEXT,
teacher TEXT,
team TEXT,
count INTEGER,
process TEXT,
brief TEXT
)''')
# 初始化浏览器
driver = webdriver.Chrome()
# 打开网页
driver.maximize_window()
driver.get("https://www.icourse163.org/")
# 登录
login_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')))
login_button.click()
# 切换到登录框的iframe
driver.switch_to.default_content()
driver.switch_to.frame(driver.find_elements(By.TAG_NAME, 'iframe')[0])
# 输入用户名和密码
username = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input')))
username.clear()
username.send_keys("13855980701")
password = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
password.send_keys("DongJie031217")
# 点击登录按钮
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.ID, "submitBtn"))).click()
# 切换回主页面
driver.switch_to.default_content()
# 等待搜索框出现
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[1]/div/div/div/div/div/div/input')))
# 定位搜索框
search_box = driver.find_element(By.XPATH, '/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[1]/div/div/div/div/div/div/input')
# 在搜索框输入关键词
search_box.send_keys("高数", Keys.RETURN)
# 开始爬取数据的函数
def start_spider():
# 等待课程列表加载完成
WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="m-course-list"]/div/div')))
# 模拟滚动到页面底部
driver.execute_script('document.documentElement.scrollTop=10000')
# 等待加载新的课程列表
WebDriverWait(driver, random.randint(3, 6)).until(EC.presence_of_element_located((By.XPATH, '//div[@class="m-course-list"]/div/div')))
# 滚动到页面顶部
driver.execute_script('document.documentElement.scrollTop=0')
num = 0
for link in driver.find_elements(By.XPATH, '//div[@class="m-course-list"]/div/div'):
num += 1
course_name = link.find_element(By.XPATH, './/span[@class=" u-course-name f-thide"]').text
try:
school_name = link.find_element(By.XPATH, './/a[@class="t21 f-fc9"]').text
except NoSuchElementException:
school_name = ''
try:
teacher_element = link.find_element(By.XPATH, ".//div[@class='t2 f-fc3 f-nowrp f-f0']//a[@class='f-fc9']")
teacher = teacher_element.text
except NoSuchElementException:
teacher = ''
try:
teachers_element = link.find_element(By.XPATH,
".//div[@class='t2 f-fc3 f-nowrp f-f0']//span[@class='f-fc9']")
teachers = teachers_element.text
team_member = teachers + teacher
except NoSuchElementException:
team_member = ''
try:
join = link.find_element(By.XPATH, './/span[@class="hot"]').text.replace('参加', '')
except NoSuchElementException:
join = ''
try:
process = link.find_element(By.XPATH, './/span[@class="txt"]').text
except NoSuchElementException:
process = ''
try:
introduction = link.find_element(By.XPATH, './/span[@class="p5 brief f-ib f-f0 f-cb"]').text
except NoSuchElementException:
introduction = ''
try:
join_number = ''.join(filter(str.isdigit, join))
count_value = int(join_number)
# 插入数据库
cursor.execute(
"INSERT INTO mooc (`id`, `course`, `college`, `teacher`, `team`, `count`, `process`, `brief`) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)",
(num, str(course_name), str(school_name), str(teacher), str(team_member), count_value, str(process),
str(introduction)))
except Exception as err:
print("出现错误:", err)
conn.commit()
print("爬取成功")
# 主函数
def main():
start_spider()
if __name__ == '__main__':
main()
driver.quit()
conn.close()
结果
自动登录
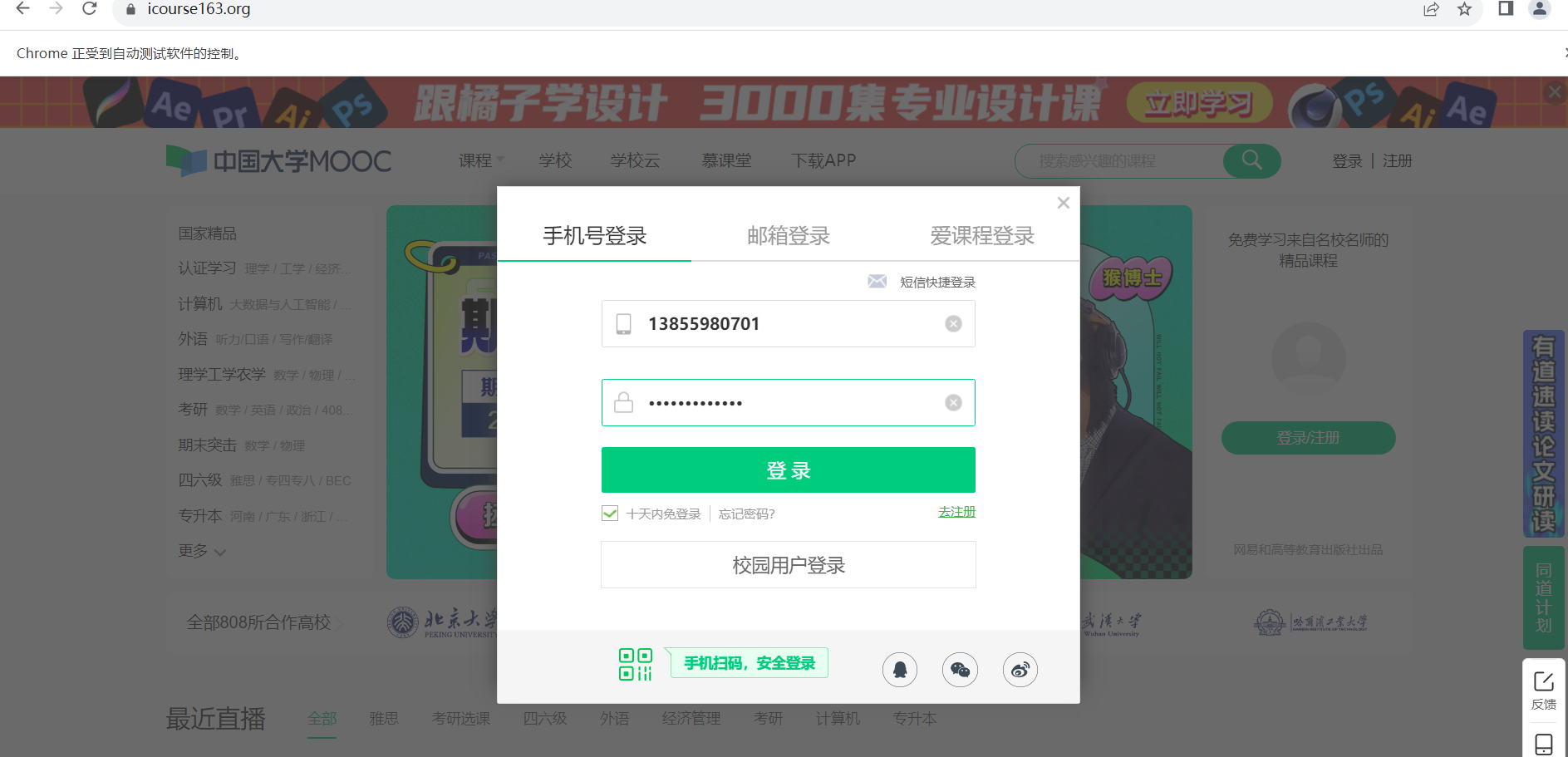
爬取成功
数据库
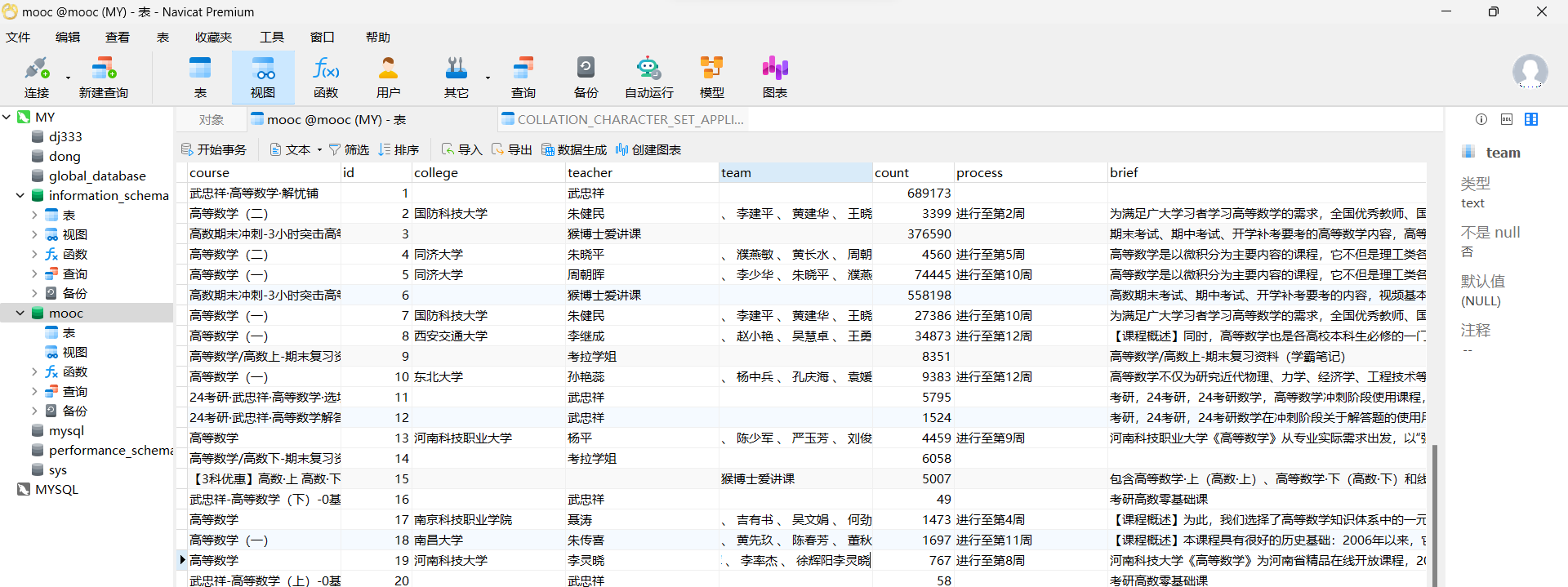
结果中有些是没有相关大学信息的,因为不同类型的高数视频的结构也不太一样,a class的值不同,有些的发布方不是某大学。比如下图。

如果发布方是某大学则可以爬取

因为是通过'.//a[@class="t21 f-fc9"]'来查找大学信息的,故如果发布方不是某大学那一列会用空值填补,team值同理。
心得
一开始爬取的时候报错,error: (1265, "Data truncated for column 'count' at row 1"),这个信息表示长度超过了列的定义,查看页面信息发现人数不只是数字,是550人,要去除 '人' 字,再转化成整数即可。
join_number = ''.join(filter(str.isdigit, join))
count_value = int(join_number)
此外,还是要仔细观察页面结构,多观察几个课程,一开始没注意有些课程是相关大学发布,有些是个人比如一些网课up主发布的,他们课程的结构就不太一样。
虽然过程有些曲折,但这次实验收获还是挺多的,学会了模拟登录以及使用关键词进行课程的爬取,要注意的是要仔细观察页面,定位要准确,如果超过指定时间未找到特定信息的话代码会报错,通过此次实验,加深了我对selenium的理解与认识。
作业3
要求
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建
- 任务一:开通MapReduce服务
实时分析开发实战:
- 任务二:Python脚本生成测试数据
- 任务三:配置Kafka
- 任务四:安装Flume客户端
- 任务五:配置Flume采集数据
任务一:开通MapReduce服务
成功配置。
弹性云服务器
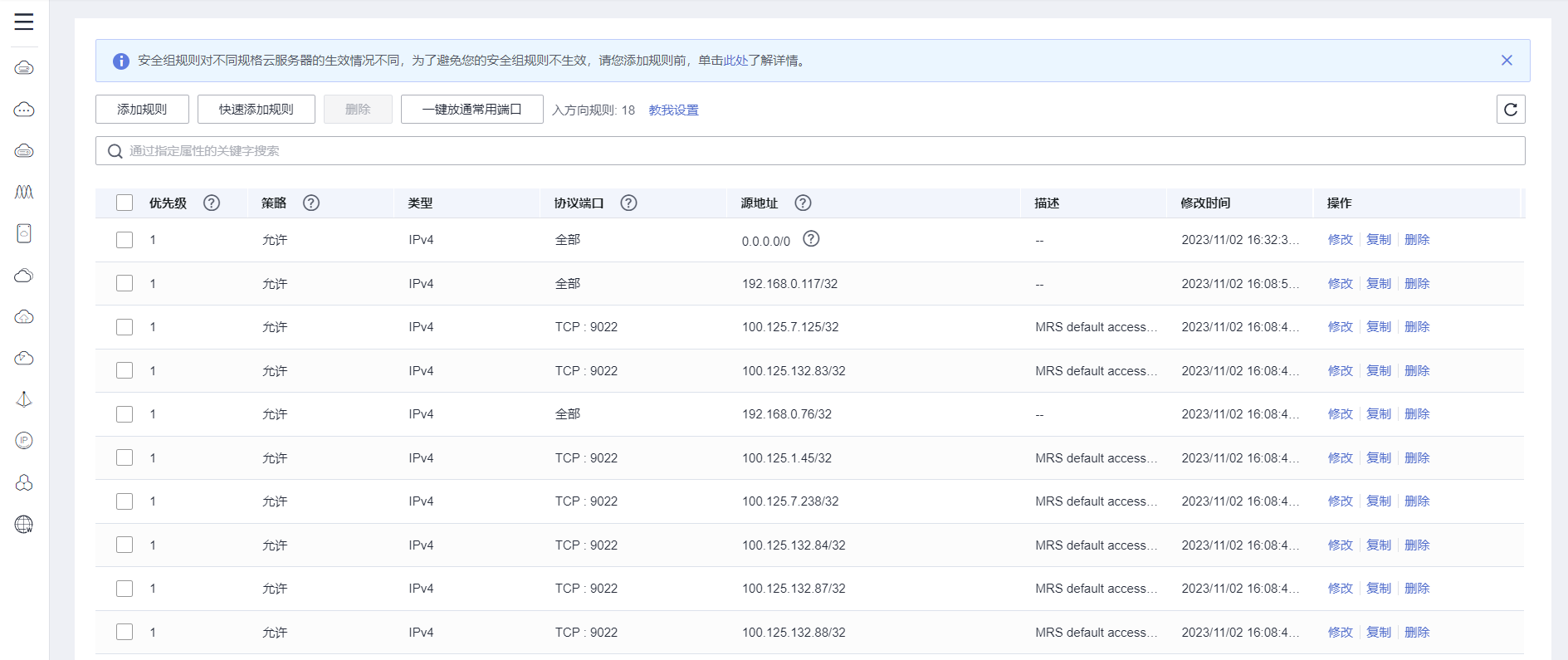
安全组
弹性公网
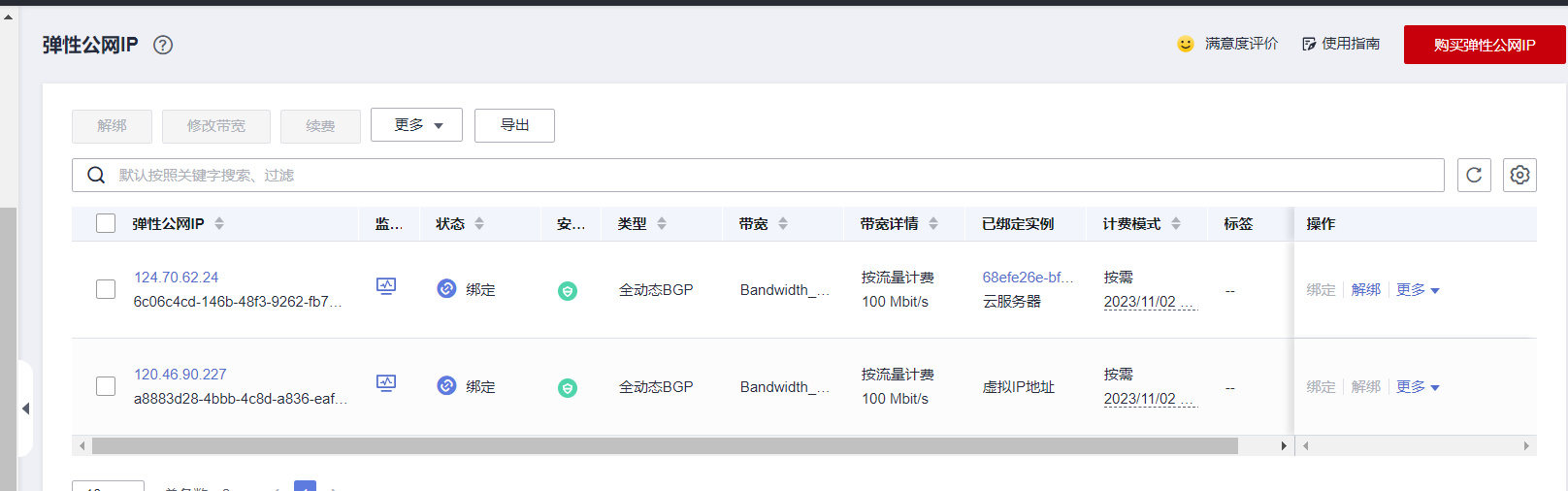
入方向规则配置
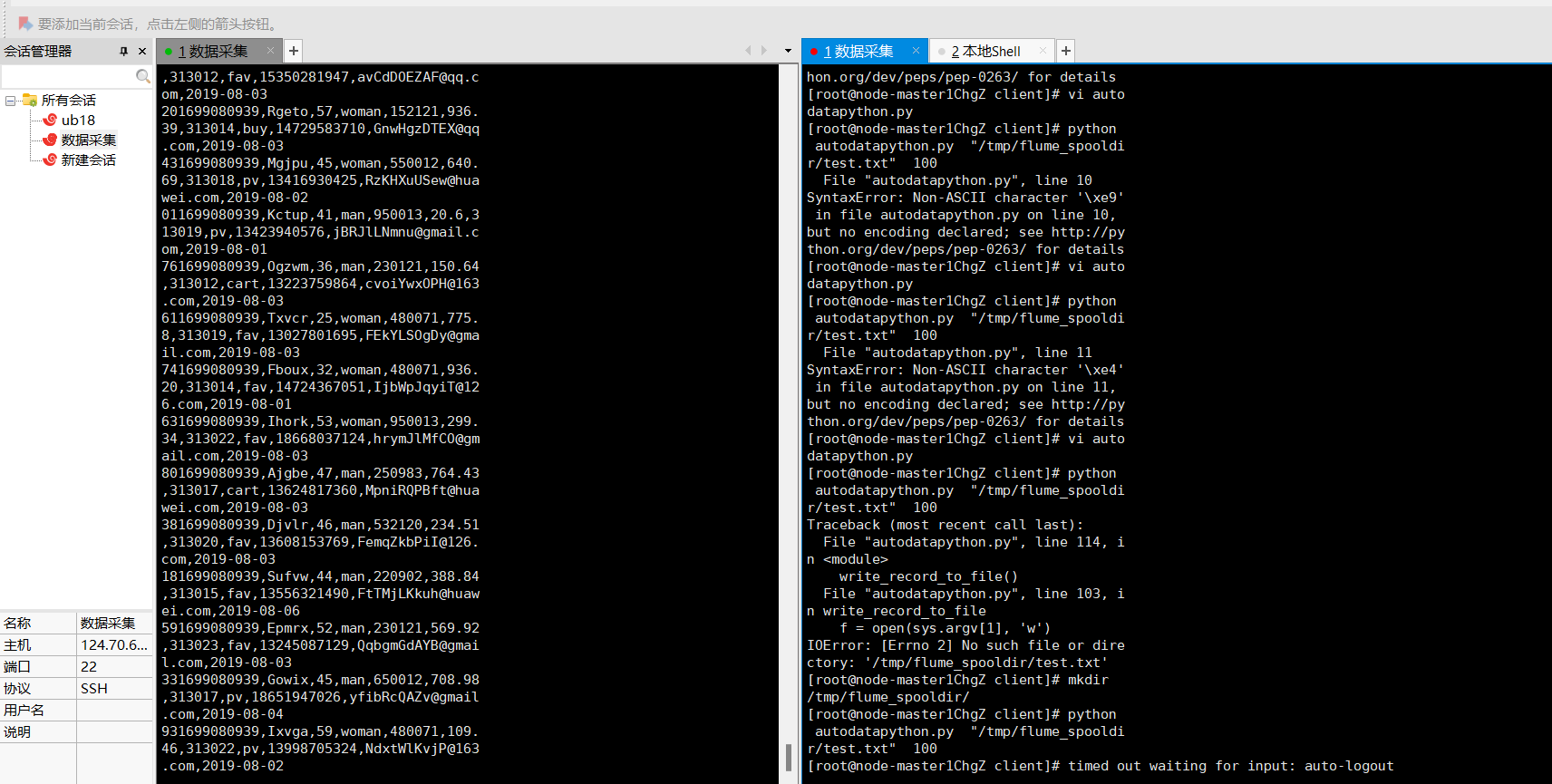
任务二:Python脚本生成测试数据
X-shell连接
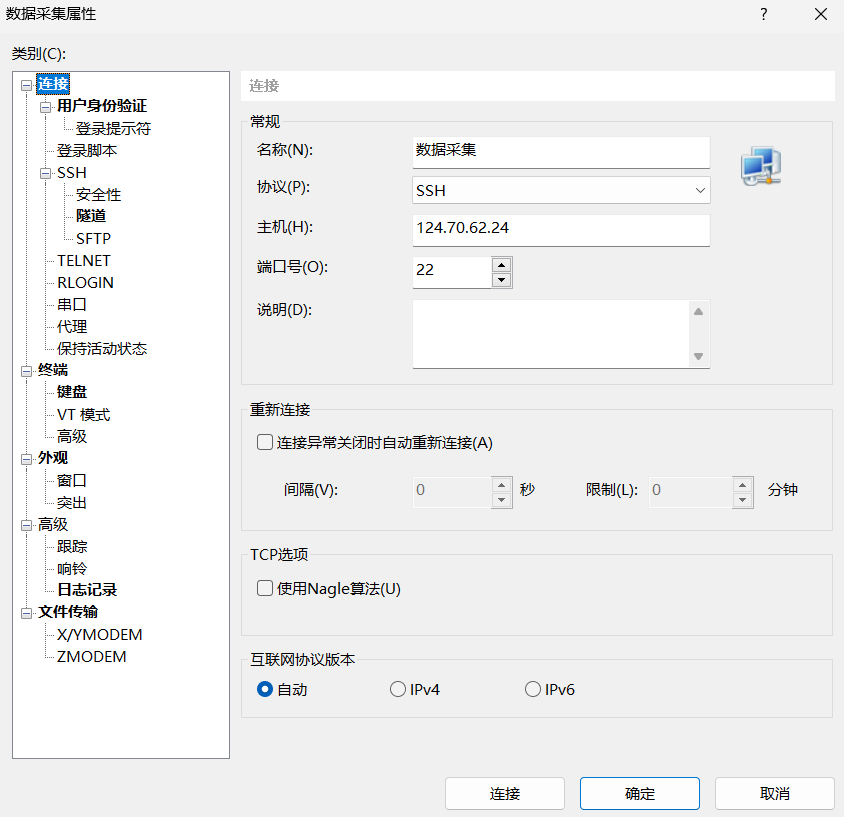
终端代码




任务三:配置Kafka
进入manager并获取zookeeper IP
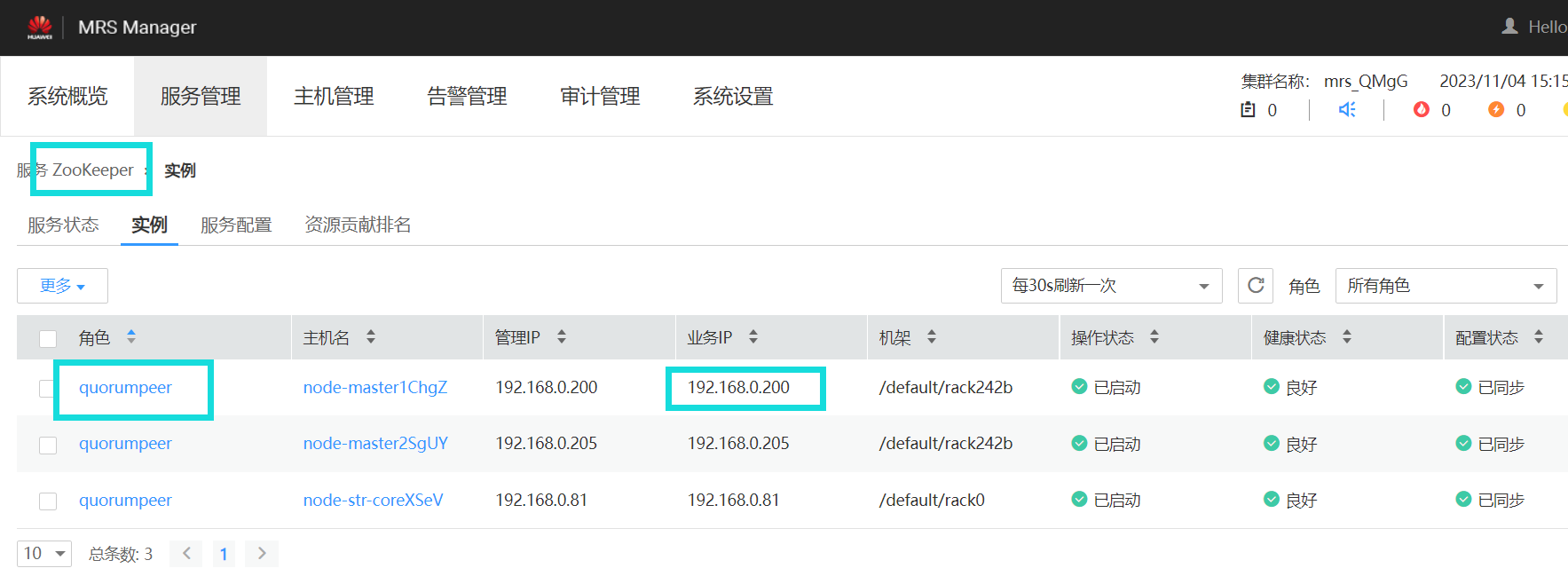
终端代码
成功配置
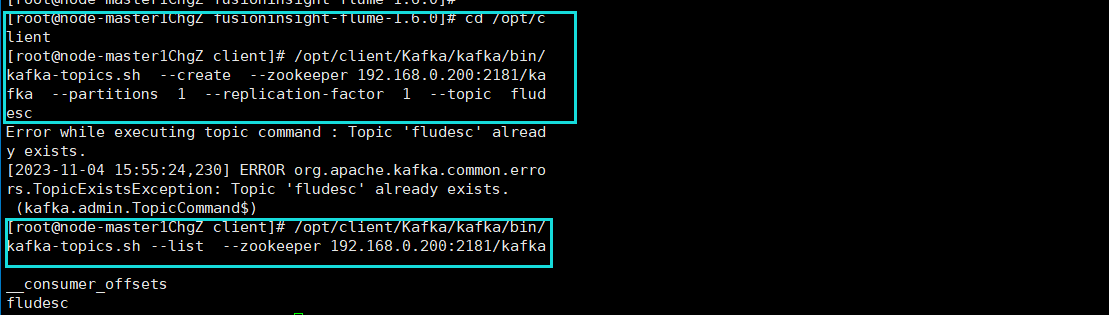
因为之前已经做过一次,所以执行第二条命令时会显示已存在。
任务四:安装Flume客户端
获取Flume IP
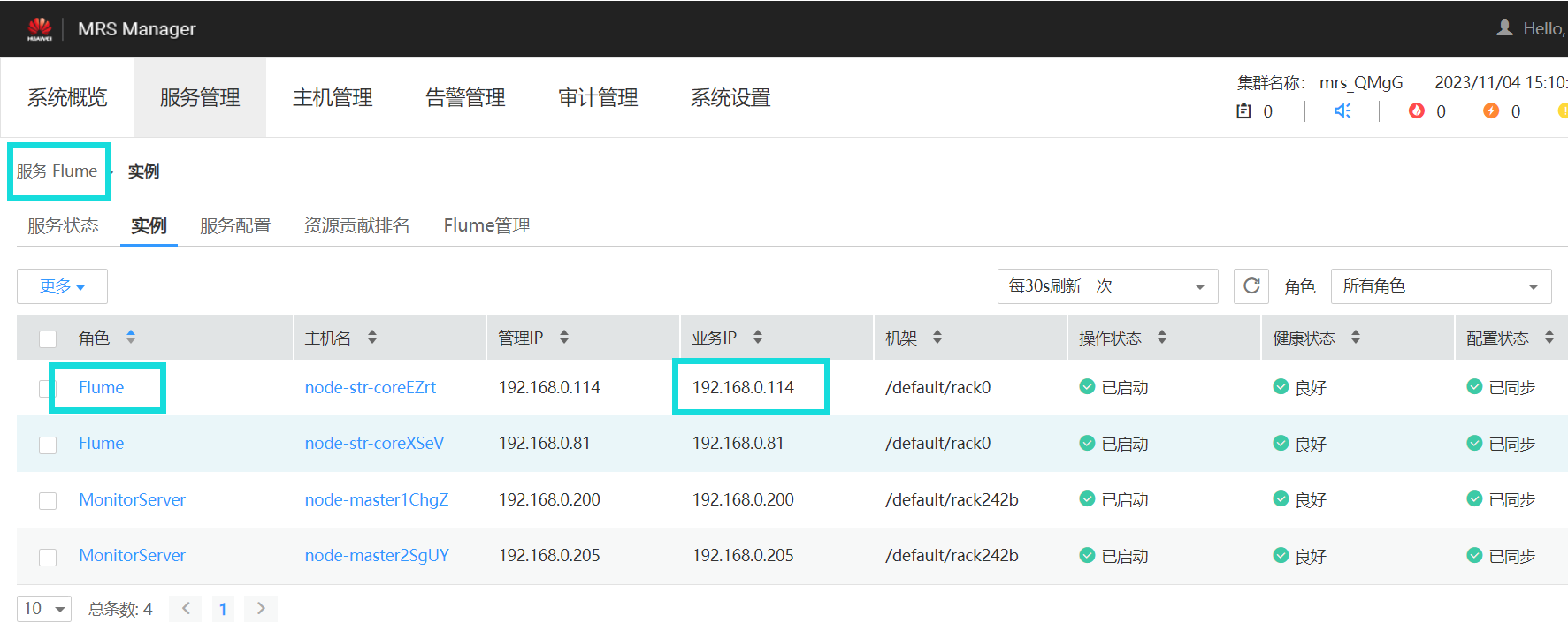
终端代码
下载及解压
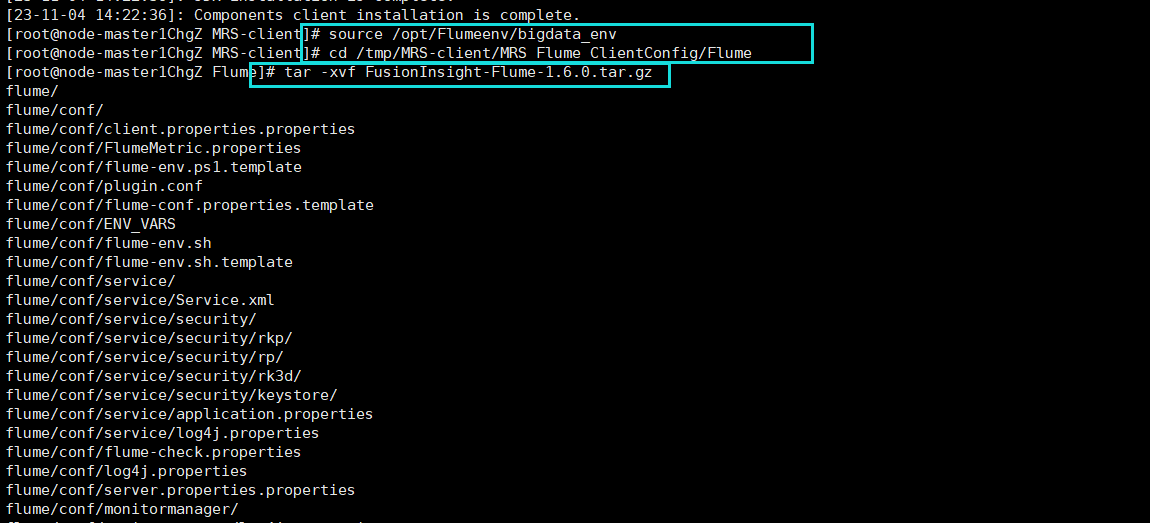
安装Flume客户端并重启
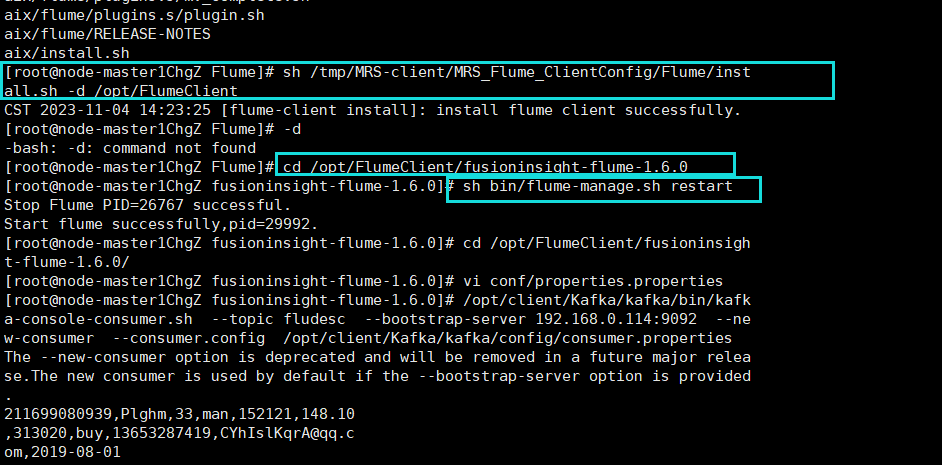
任务五:配置Flume采集数据
获取Kafka IP
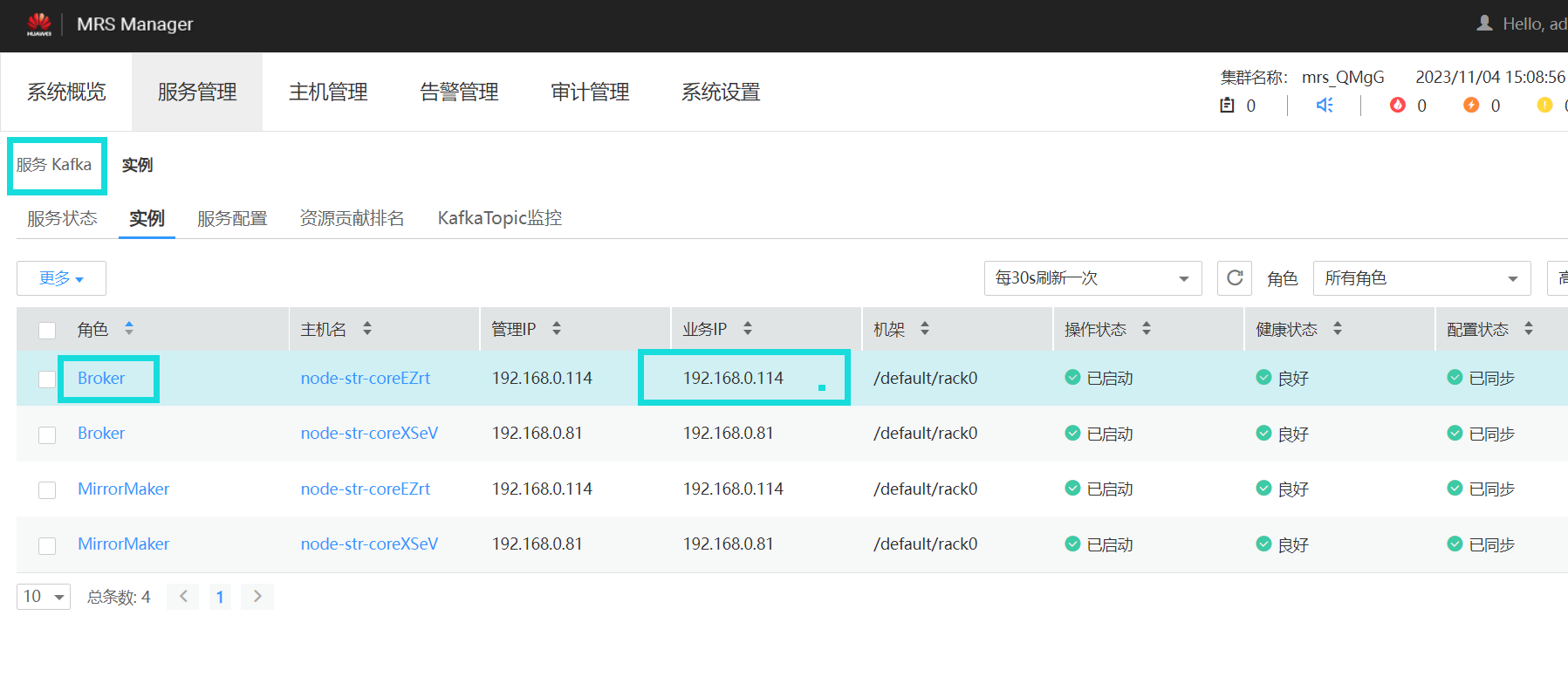
终端代码
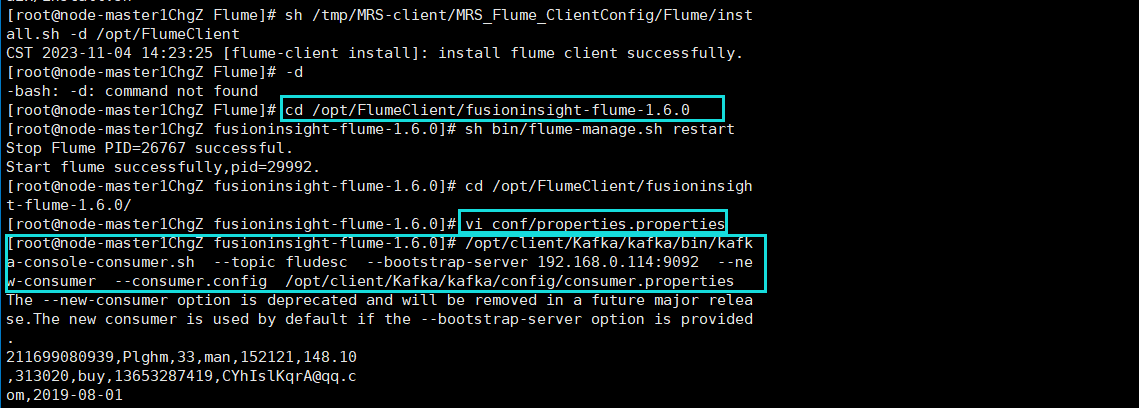
Flume到Kafka成功打通
心得
根据实验手册进行就行,但文档里有的图片和给出的文字的指令有的会有一些细小的差别,按照图片里输入会报错,但是直接复制给出的指令就可以,还是要仔细观察。
此外,有些ip要改成自己的,一开始没注意,直接复制命令会报错,要找到自己的zookeeper IP等,文档里都有给出相应的位置。
还需要及时关闭资源,不然真的挺费钱的。经过这次实验,我初步了解了华为云以及x-shell相关的操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号