数据采集与融合第三次作业——董婕
作业1
要求
指定一个网站,爬取这个网站中的所有图片(中国气象网(http://www.weather.com.cn),使用scrapy框架分别实现 单线程和多线程的方式爬取。
输出信息
将下载的UrI信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
gitee链接
实现过程
观察页面结构
打开开发者模式,观察图片信息,可以发现图片信息均在a标签下的img标签中,提取img标签的src属性值即可。
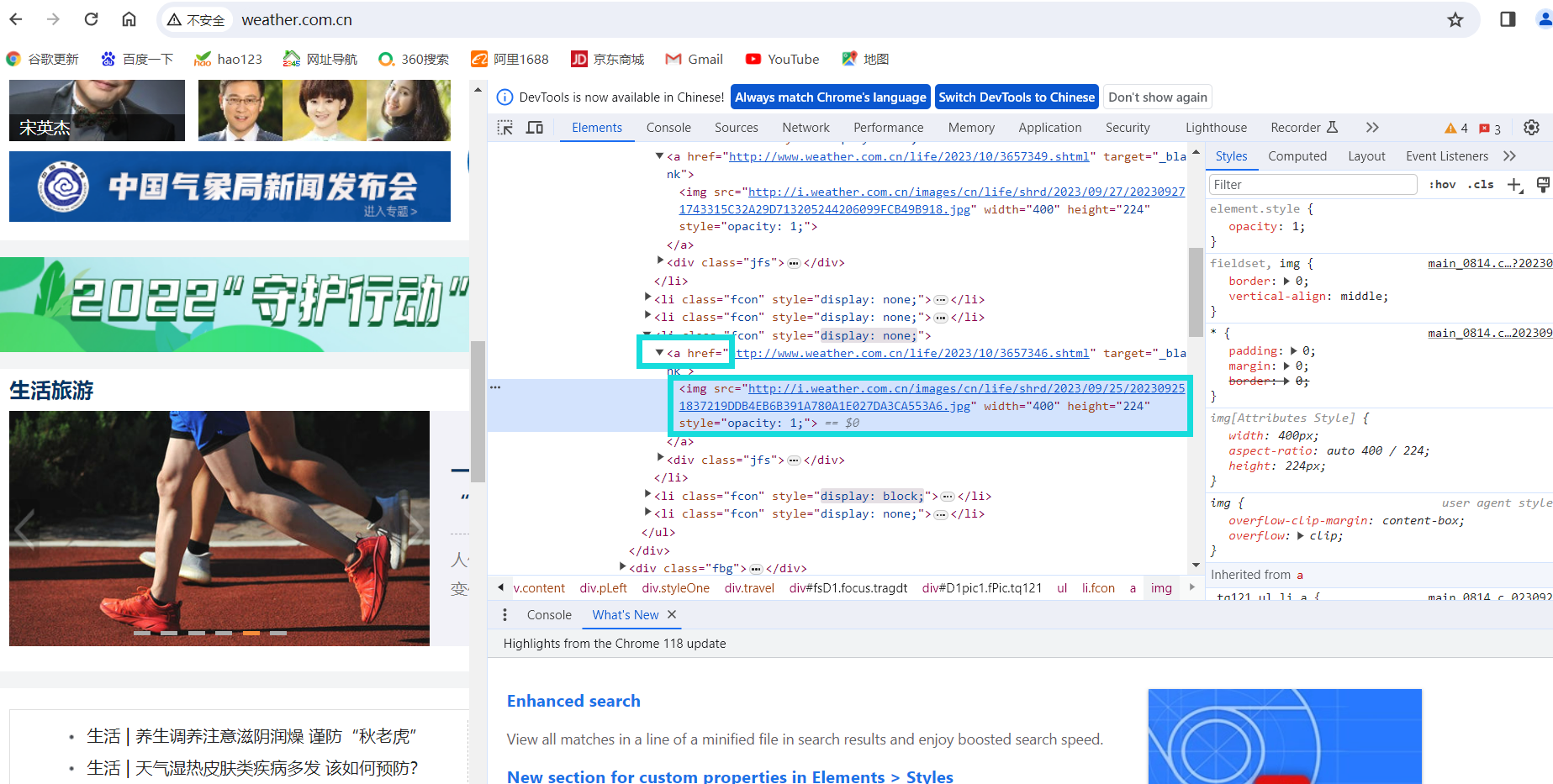
代码如下。
def extract_image_links(html):
imgList = re.findall(r'<img.*?src="(.*?)"', html, re.S)
return imgList
作业要求自动翻页爬取网站图片,但本网站与当当网,财富网不太一样,不是通过改变page或者pn值来进行翻页,是通过点击图片进入下一个页面,随机点了几张图片,但他们的链接都不大一样,没有什么规律。随机截取了几个url。



故不可通过之前的方式来实现自动翻页,继续观察页面,发现图片包含的url均在a标签里的herf属性中。
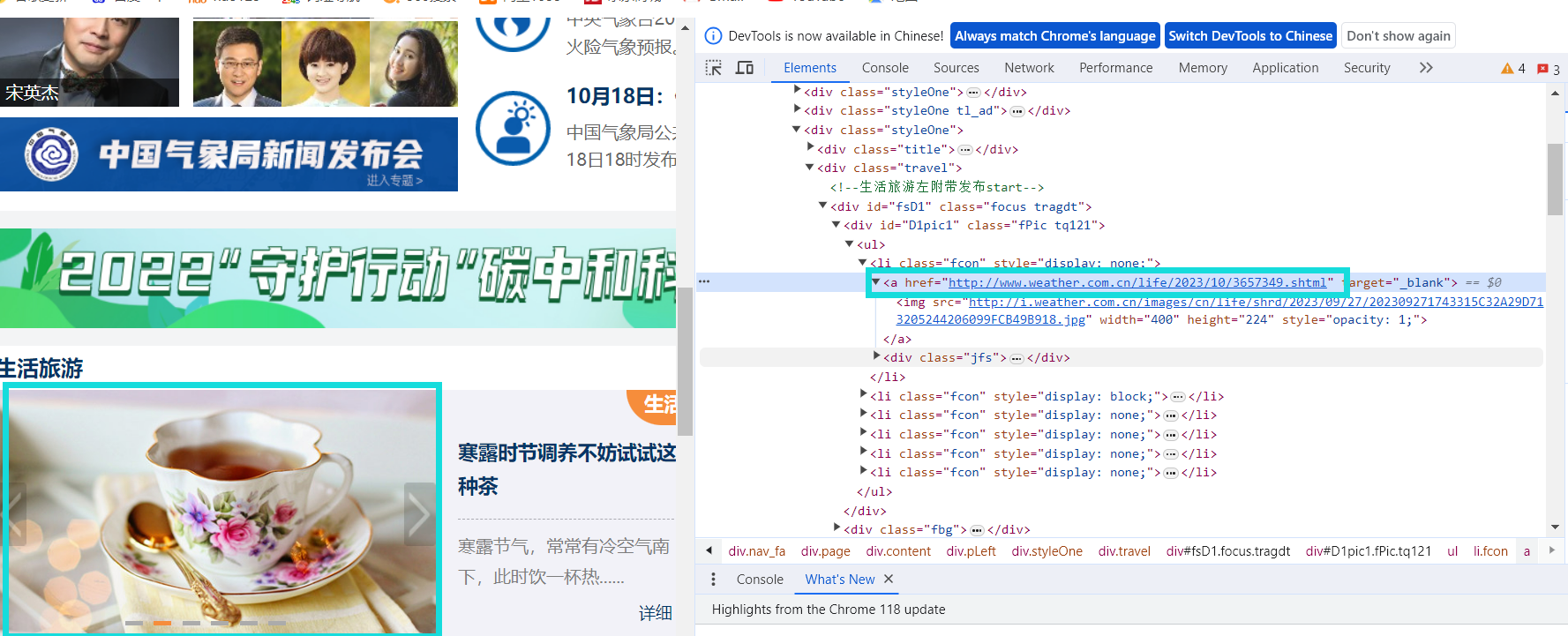
提取herf属性
next_page_match = re.search('<a href="([^"]*)">', html)
获取herf属性的链接后,可将其赋给url,设定最大爬取页数为11(学号后两位)和最大爬取图片数111(学号后三位),通过while语句循环爬取。
while page_count <= max_pages and image_count < image_limit:
# 爬取HTML内容
html = get_html(url, headers)
imgList = extract_image_links(html)
# 多线程下载图片
remaining_images = min(image_limit - image_count, len(imgList))
download_images_multi_threaded(imgList[:remaining_images], remaining_images, image_folder)
image_count += remaining_images
# 查找下一页的链接
next_page_match = re.search('<a href="([^"]*)">', html)
if next_page_match:
url = next_page_match.group(1)
page_count += 1
else:
break
此外,题目还要求我们用单线程和多线程两种方式,定义单线程函数与多线程函数。
#单线程
def download_image(url, name, folder):
try:
resp = requests.get(url)
with open(os.path.join(folder, name), 'wb') as f:
f.write(resp.content)
with print_lock:
print(f"下载完成: {name} {url}")
except Exception as e:
with print_lock:
print(f"下载失败: {name} {url} -> {e}")
# 函数:多线程下载图片
def download_images_multi_threaded(img_list, limit, folder):
threads = []
for i, url in enumerate(img_list[:limit + 1]):
thread = threading.Thread(target=download_image, args=(url, f'{i}.jpg', folder))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
完整代码
import requests
import re
import os
import threading
from datetime import datetime
# 锁用于同步打印消息
print_lock = threading.Lock()
# 函数:获取HTML内容
def get_html(url, headers):
response = requests.get(url, headers=headers)
return response.text
# 函数:提取图片链接
def extract_image_links(html):
imgList = re.findall(r'<img.*?src="(.*?)"', html, re.S)
return imgList
# 函数:下载单张图片
def download_image(url, name, folder):
try:
resp = requests.get(url)
with open(os.path.join(folder, name), 'wb') as f:
f.write(resp.content)
with print_lock:
print(f"下载完成: {name} {url}")
except Exception as e:
with print_lock:
print(f"下载失败: {name} {url} -> {e}")
# 函数:多线程下载图片
def download_images_multi_threaded(img_list, limit, folder):
threads = []
for i, url in enumerate(img_list[:limit + 1]):
thread = threading.Thread(target=download_image, args=(url, f'{i}.jpg', folder))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
# 函数:爬取HTML内容并自动翻页下载
def scrape_and_download_auto_pagination(url, headers, image_limit, max_pages):
start_time = datetime.now()
page_count = 1
image_count = 1
# 在桌面上创建一个名为`images`的文件夹
desktop_path = os.path.expanduser("~/Desktop")
image_folder = os.path.join(desktop_path, "images")
if not os.path.exists(image_folder):
os.makedirs(image_folder)
while page_count <= max_pages and image_count < image_limit:
# 爬取HTML内容
html = get_html(url, headers)
imgList = extract_image_links(html)
# 多线程下载图片
remaining_images = min(image_limit - image_count, len(imgList))
download_images_multi_threaded(imgList[:remaining_images], remaining_images, image_folder)
image_count += remaining_images
# 查找下一页的链接
next_page_match = re.search('<a href="([^"]*)">', html)
if next_page_match:
url = next_page_match.group(1)
page_count += 1
else:
break
end_time = datetime.now()
print(f"自动翻页爬取和下载完成,总耗时: {end_time - start_time}")
if __name__ == "__main__":
url = "http://www.weather.com.cn/" # 你需要替换成目标网站的URL
headers = {
'User-Agent': 'Your User Agent',
}
image_limit = 111 # 限制下载图片数量
max_pages = 11 # 最大翻页次数
print("===== 自动翻页爬取和下载 =====")
scrape_and_download_auto_pagination(url, headers, image_limit, max_pages)
结果
单线程
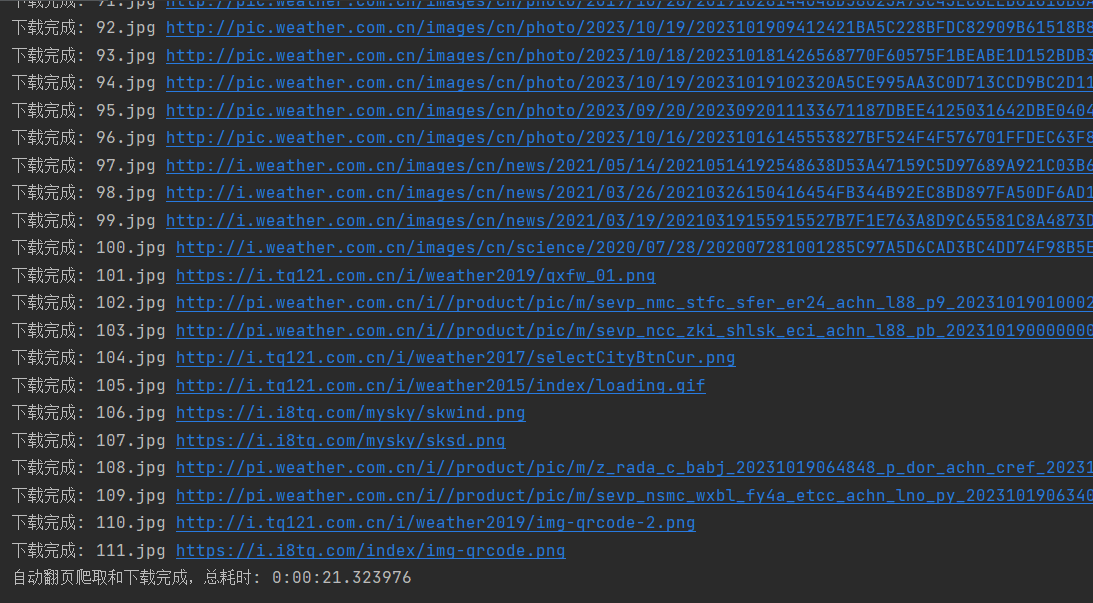
可观察到输出有序。
多线程
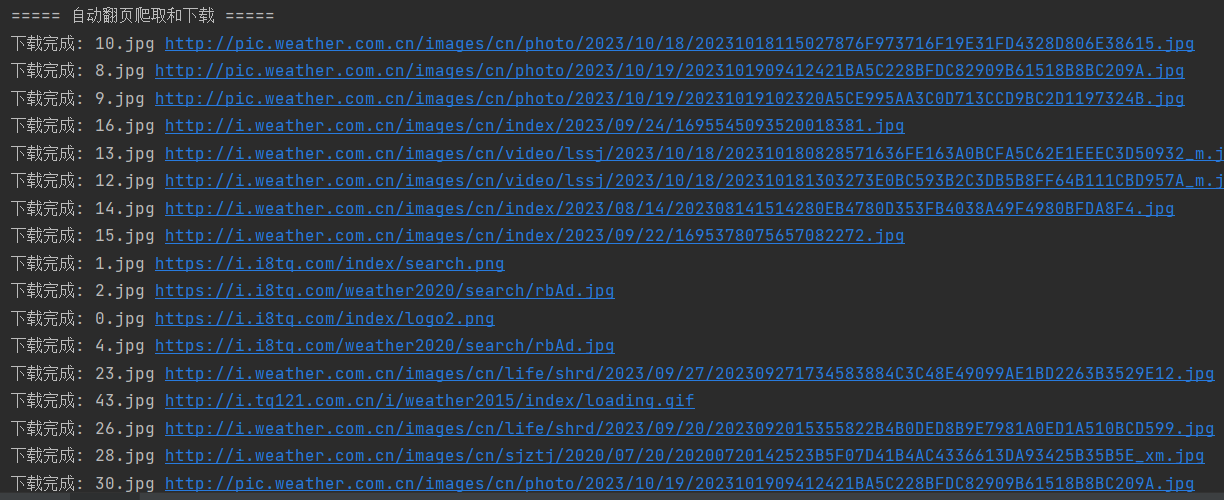
可观察到输出是被打乱的,不过速度快了很多。
images文件夹部分图片
心得
这题跟之前总体类似,就是新添了一个循环爬取页面的功能,页面结构与之前翻页的页面略有不同,需要自己提取新界面的url循环爬取。
作业2
要求
熟练掌握scrapy中Item、 Pipeline 数据的序列化输出方法; Scrapy+ Xpath+MySQl+数据库存储技术路线爬取股票相关信息。网站:东方财富网(https://www.eastmoney.com)
输出信息
gitee链接
实现过程
抓包
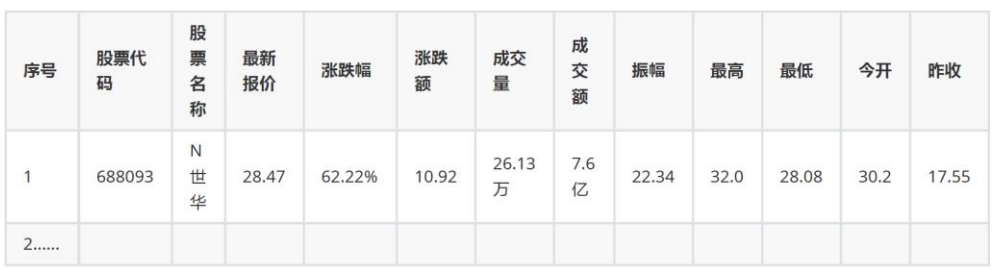
在search栏里面搜索相关信息,找到对应的包,获取url,并且将f1-18与页面上的表头相对应。
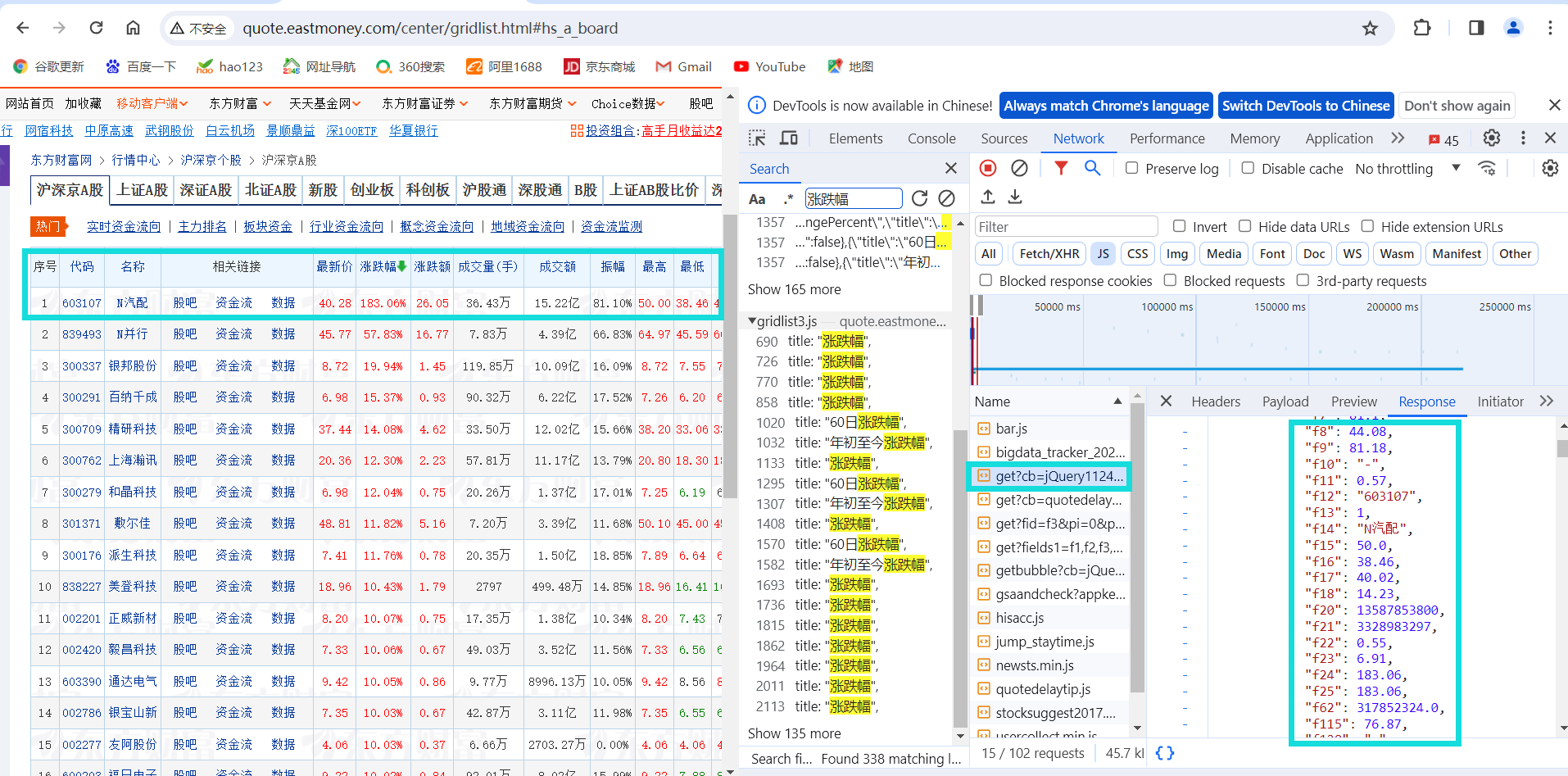
对应信息如下:
co=data_value['f12'],
name=data_value['f14'],
latest=data_value['f2'],
change=data_value['f4'],
Randf=data_value['f3'],
volume=data_value['f5'],
turnover=data_value['f5'],
amplitude=data_value['f7'],
max=data_value['f15'],
min=data_value['f16'],
today=data_value['f17'],
yesterday=data_value['f18']
dj.py代码
import scrapy
import json
from ..items import Dj3Item
class DjSpider(scrapy.Spider):
name = 'dj'
# 允许的域名
allowed_domains = ['65.push2.eastmoney.com']
# 起始URL
start_urls = ['http://65.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124008516432775777205_1697696898159&pn=1&pz=100&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=1697696898163']
def parse(self, response):
# 解析JSON数据
data = self.parse_json(response.text)
# 从JSON数据中提取需要的信息
data_values = data['data']['diff']
items = self.parse_data_values(data_values)
# 通过生成器方式返回提取的数据
yield from items
def parse_json(self, jsonp_response):
# 从JSONP响应中提取JSON字符串
json_str = jsonp_response[len("jQuery1124008516432775777205_1697696898159("):len(jsonp_response) - 2]
return json.loads(json_str)
def parse_data_values(self, data_values):
# 遍历数据值列表,创建爬取的数据项
return [Dj3Item(
co=data_value['f12'],
name=data_value['f14'],
latest=data_value['f2'],
change=data_value['f4'],
Randf=data_value['f3'],
volume=data_value['f5'],
turnover=data_value['f5'],
amplitude=data_value['f7'],
max=data_value['f15'],
min=data_value['f16'],
today=data_value['f17'],
yesterday=data_value['f18']
) for data_value in data_values]
items.py
import scrapy
class Dj3Item(scrapy.Item):
# 定义要爬取的数据字段
co = scrapy.Field()
name = scrapy.Field()
latest = scrapy.Field()
change = scrapy.Field()
Randf = scrapy.Field()
volume = scrapy.Field()
turnover = scrapy.Field()
amplitude = scrapy.Field()
max = scrapy.Field()
min = scrapy.Field()
today = scrapy.Field()
yesterday = scrapy.Field()
pass
pipelines.py
import scrapy
import json
import pymysql
class Dj3Pipeline(object):
conn = None
cursor = None
def open_spider(self, spider):
# 在爬虫启动时执行,用于初始化数据库连接和创建数据表
self.conn = pymysql.connect(
host='localhost',
user='root',
port=3306,
password='1',
database='dong'
)
self.cursor = self.conn.cursor()
with self.conn.cursor() as cursor:
# 创建数据库和表,如果不存在的话
cursor.execute('CREATE DATABASE IF NOT EXISTS dj333')
cursor.execute('USE dj333')
cursor.execute("""
CREATE TABLE IF NOT EXISTS dj333 (
股票代码 VARCHAR(255),
股票名称 VARCHAR(255),
最新报价 VARCHAR(255),
涨跌幅 VARCHAR(255),
涨跌额 VARCHAR(255),
成交量 VARCHAR(255),
成交额 VARCHAR(255),
振幅 VARCHAR(255),
最高 VARCHAR(255),
最低 VARCHAR(255),
今开 VARCHAR(255),
昨收 VARCHAR(255)
)
""")
def process_item(self, item, spider):
# 在爬虫处理每个item时执行,用于将数据插入数据库
sql = """
INSERT INTO dj333 (股票代码, 股票名称, 最新报价, 涨跌幅, 涨跌额, 成交量, 成交额, 振幅, 最高, 最低, 今开, 昨收)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
data = (
item["co"], item["name"], item["latest"], item["change"], item["Randf"],
item["volume"], item["turnover"], item["amplitude"], item["max"], item["min"],
item["today"], item["yesterday"]
)
with self.conn.cursor() as cursor:
try:
cursor.execute(sql, data) # 执行SQL插入操作
except Exception as e:
print(e)
return item
def close_spider(self, spider):
# 在爬虫关闭时执行,用于提交事务和关闭数据库连接
self.conn.commit() # 提交事务
self.conn.close() # 关闭数据库连接
settings.py
BOT_NAME = 'dj3'
SPIDER_MODULES = ['dj3.spiders']
NEWSPIDER_MODULE = 'dj3.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
ROBOTSTXT_OBEY = False
结果
命令行运行程序
数据库存储
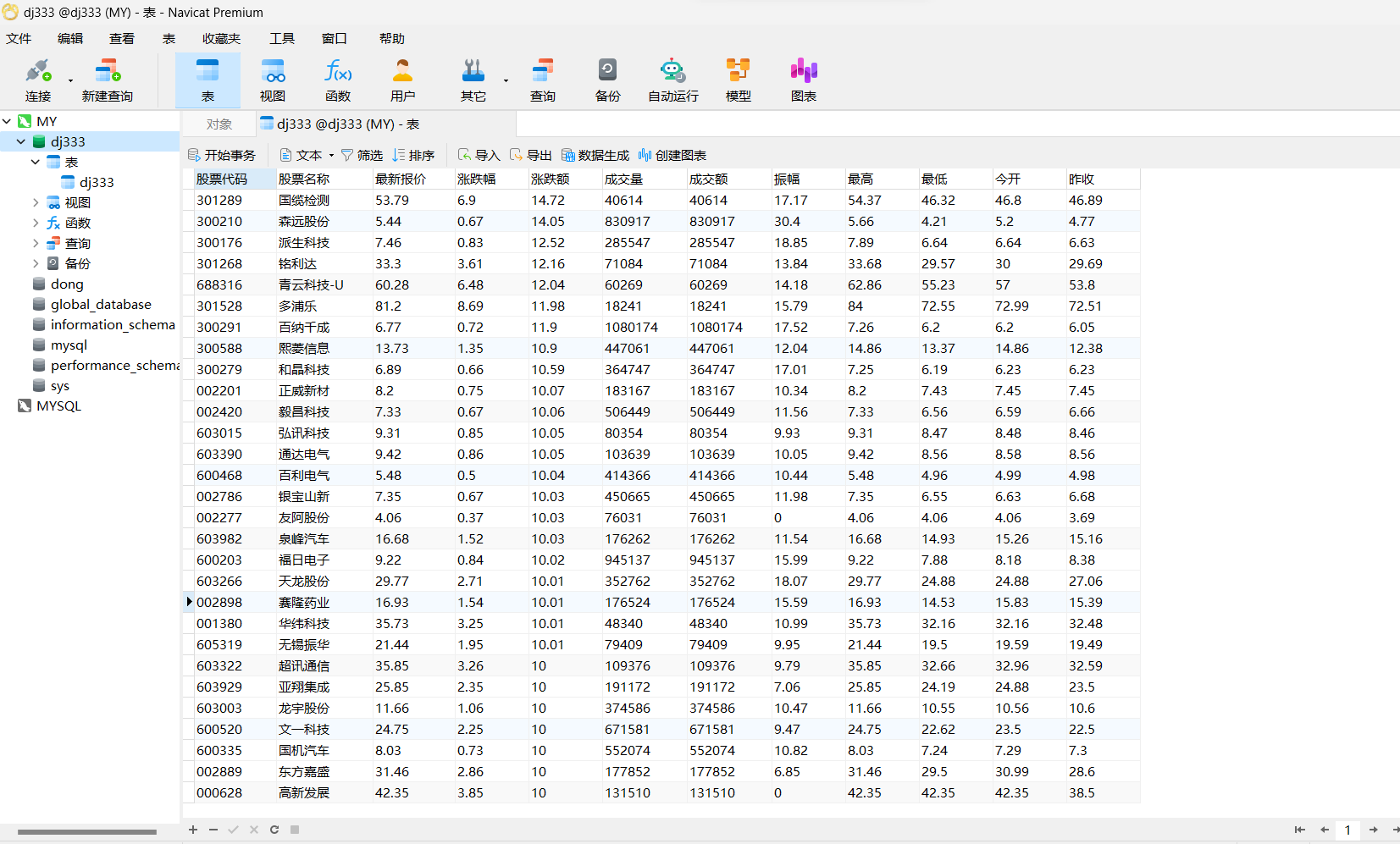
心得
与之前作业类似,加了个scrapy框架,找包的时候可以先看自己要获取哪些信息,再在search栏里面搜索,并且筛选出特定js包,会更快一些。
作业3
要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
输出信息

gitee链接
实现过程
提取信息
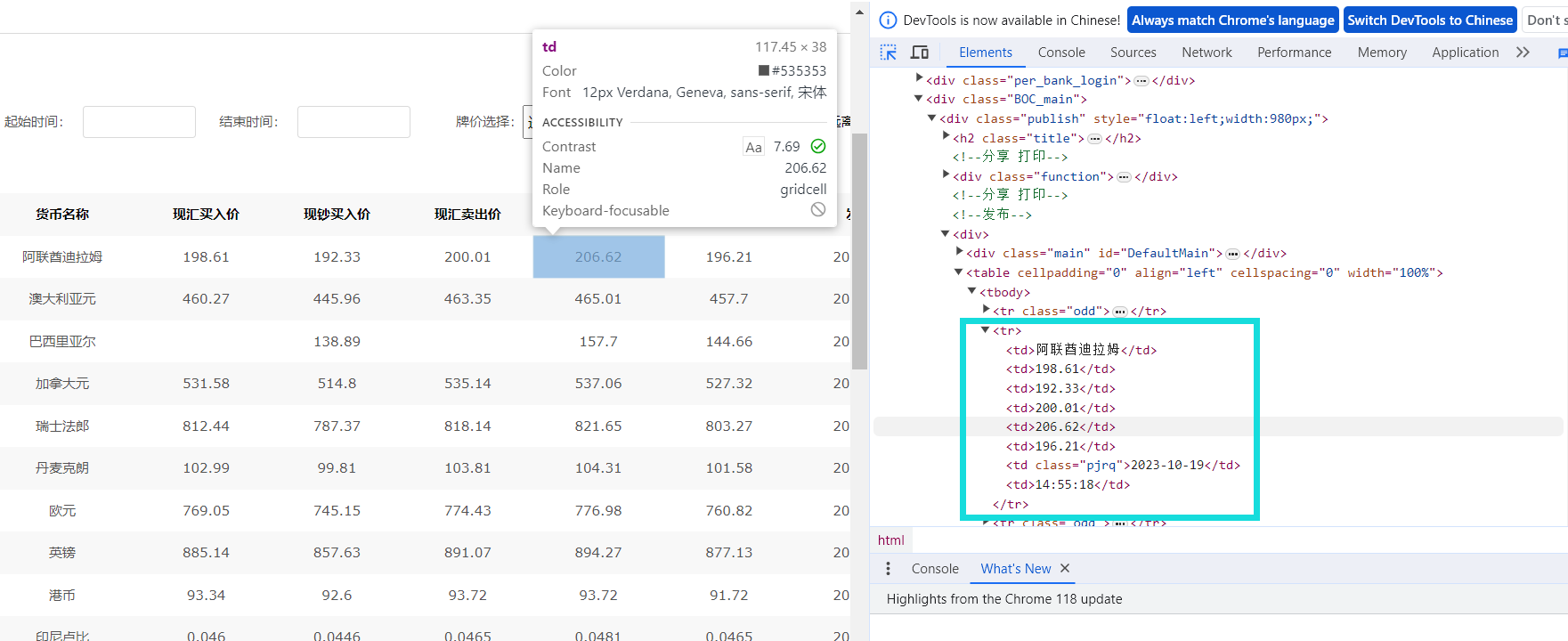
可观察到要提取的信息在tr标签下的td标签的文本中,可使用xpath工具帮助定位
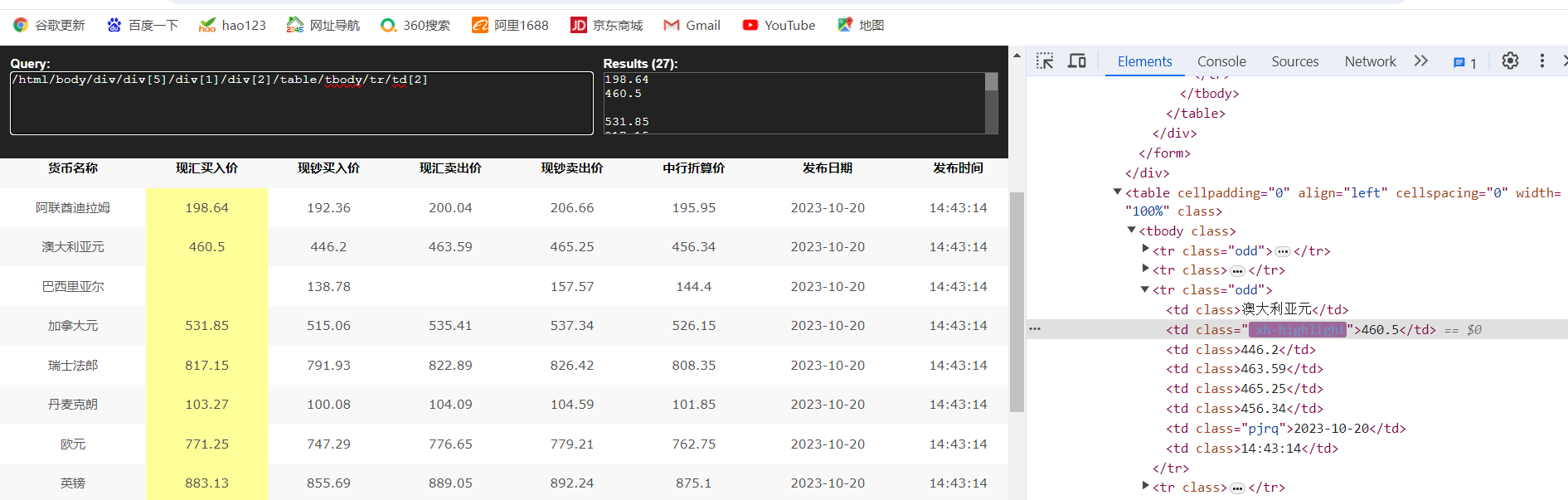
由于题目要求输出信息中没有中行折算价,故只提取了TBP、CBP、TSP、BCP、TSP、pub_time六项。提取信息的代码如下。
def parse(self, response):
# 使用Selenium WebDriver来获取页面内容
self.driver.get(response.url)
# 创建一个Scrapy Selector对象,用于解析页面内容
sel = scrapy.Selector(text=self.driver.page_source)
# 选择包含汇率信息的表格
table = sel.xpath("/html/body/div/div[5]/div[1]/div[2]/table")
# 选择表格中的<tbody标签
tbody = table.xpath(".//tbody")
# 选择tbody中的所有行(tr标签)
trs = tbody.xpath(".//tr")
# 遍历每一行,从中提取数据
for line in trs[1:]:
# 提取各列数据,使用XPath选择器
currency = line.xpath("td[1]/text()").extract_first()
TBP = line.xpath("td[2]/text()").extract_first()
CBP = line.xpath("td[3]/text()").extract_first()
TSP = line.xpath("td[4]/text()").extract_first()
CSP = line.xpath("td[5]/text()").extract_first()
BCP = line.xpath("td[6]/text()").extract_first()
pub_time = line.xpath("td[7]/text()").extract_first()
# 创建ExchangeRateItem对象,用于存储提取的数据
items = ExchangeRateItem()
items['currency'] = currency
items['TBP'] = TBP
items['CBP'] = CBP
items['TSP'] = TSP
items['CSP'] = CSP
items['pub_time'] = pub_time
# 使用yield将ExchangeRateItem对象传递给Scrapy引擎
yield items
设置settings文件
在settings文件中设置USER_AGENT,ITEM_PIPELINES以及将ROBOTSTXT_OBEY改为False
BOT_NAME = 'boc2'
SPIDER_MODULES = ['boc2.spiders']
NEWSPIDER_MODULE = 'boc2.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
ROBOTSTXT_OBEY =False
ITEM_PIPELINES = {
'boc2.pipelines.MyprojectPipeline': 300,
}
定义表
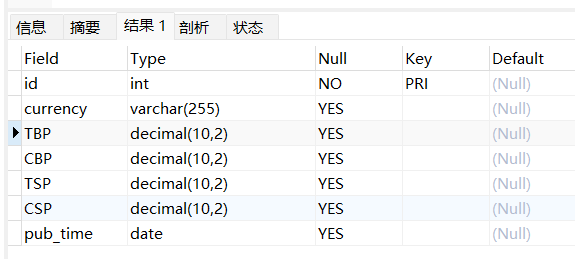
在数据库新建表rates并定义items.py
表rates
items.py
class ExchangeRateItem(scrapy.Item):
currency = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
pub_time = scrapy.Field()
定义pipelines
自定义Scrapy管道,编写pipelines.py,将爬取到的数据存储到MySQL数据库中。
定义open_spider函数建立数据库连接
def open_spider(self, spider):
self.conn = pymysql.connect(
host='localhost',
user='root',
port=3306,
password='1',
database='dong'
)
self.cursor = self.conn.cursor()
定义process_item函数,将爬取到的数据存储到item对象中,然后通过执行SQL语句,将item对象中的数据插入到数据库中的相应字段中
def process_item(self, item, spider):
self.cursor.execute("""
INSERT INTO rates (currency, TBP, CBP, TSP, CSP, pub_time)
VALUES (%s, %s, %s, %s, %s, %s)
""", (
item['currency'],
item['TBP'],
item['CBP'],
item['TSP'],
item['CSP'],
item['pub_time']
))
return item
关闭数据库
def close_spider(self, spider):
self.conn.commit()
self.conn.close()
定义run.py
在scrapy项目的目录下新建run.py,可直接在pycharm中运行,便于加断点调试程序。
from scrapy import cmdline
cmdline.execute("scrapy crawl myproject -s LOG_ENABLED=True".split())
结果
命令行运行程序
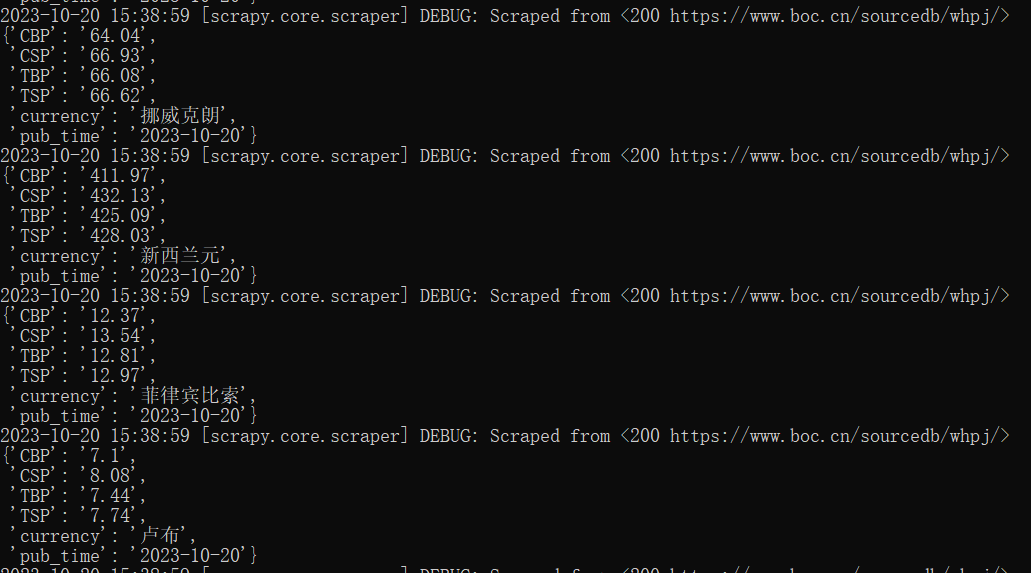
程序成功运行
数据库存储
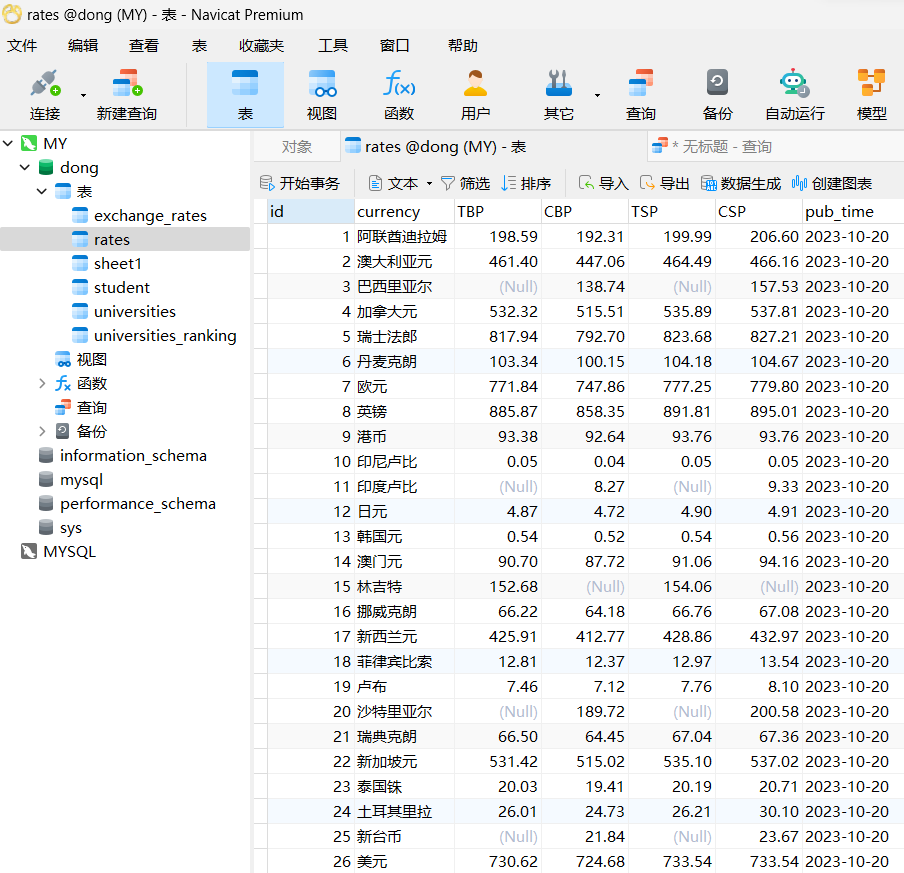
成功保存数据
心得
之前scrapy程序能运行,就是一直没结果,弄了好久,后来发现是自己提取元素的代码有问题,学会了使用xpath工具,利用这个可以更好地检验自己提取元素的代码是否正确。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号