subword-nmt 在分子smiles分词的实践
注意!这个只是在分子smiles(简化分子线性规范输入)上的实践。
环境:Python3.7
分两种方法:
一.直接从github拉取subword-nmt,本地运行。(这个方法查到实验后发现不好用!)
二.安装subword-nmt包(这个包已经被集成到Python的安装包里)
1命令:
pip install subword-nmt

2使用 subword-nmt 工具训练一个子词模型,并将结果保存到 bpe-smiles.codes 文件中。以上命令将学习子词单元,并设置子词单元的最小频率为1000。< >符号内的文件名换成自己的文件名
subword-nmt learn-bpe -s 1000 <smiles.txt> bpe-smiles.codes

3使用训练好的模型对SMILES字符串进行分割,并将结果保存到 smiles.bpe 文件中。
这里可以自己创建bpe-smiles.vocab空文件,不然无法继续,可以自己搜一个有效的文件复制内容,也可以不要--vocabulary bpe-smiles.vocab --vocabulary-threshold 50 这两个参数
这里,--vocabulary 参数用于指定词汇表文件,--vocabulary-threshold 参数用于设置词汇表的最小频率。如果不想限制词汇表大小,可以省略这两个参数。

subword-nmt apply-bpe -c bpe-smiles.codes --vocabulary bpe-smiles.vocab --vocabulary-threshold 50 < smiles.txt > smiles.bpe
成果:
原始smiles文件内容:
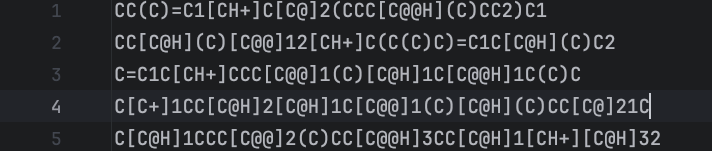
分词后结果内容:
这里分词后,分词的标识符应该是"@@ ",两个@@加一个空格。因项目需要,自己改成了"|"

这里没有使用--vocabulary bpe-smiles.vocab ,如果有对应的文件,可以添加上,结果可以更精确。
简单学习总结,勿喷!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号