
小鸭五笔在win11系统中的替代方案
背景
小鸭五笔由于长时间未更新,已经不适应新的系统版本。在最新的win11系统中,会偶发出现开机后,不能切换到小鸭五笔输入法的情况(临时解决方案,运行 Duckling.exe 两次,先卸载,再安装),尝试安装其它输入法,都没有小鸭五笔,单字优先,简码置后功能。
方案
- 使用小鸭五笔导出词库,如果需要单字优先,可以在小鸭五笔中,先调整词条顺序(小鸭五笔-设置与管理-码表管理-全部单词优先)
- 简码、重码置后功能,小鸭独有,可以通过调整词条顺序解决,如有需要,可使用后文中的代码进行调整
- 系统安装或添加其它支持更换码表的五笔输入法(如QQ五笔,冰凌五笔,微软五笔输入法),然后导入小鸭码表,对输入法进行配置模拟小鸭五笔的功能
微软五笔
- 下载 WubiLex,打开WubiLex.exe,点击添加码表,导入小鸭五笔词库
- 选择刚才导入的词库,点击安装到系统码表
- 输入法设置中,关闭“单字输入模式”
QQ五笔
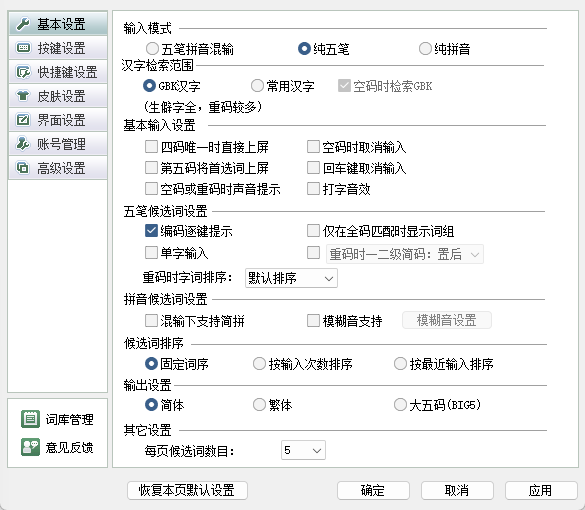
- 输入法设置,关闭“重码时一二级简码置后“,勾选”固定词序“
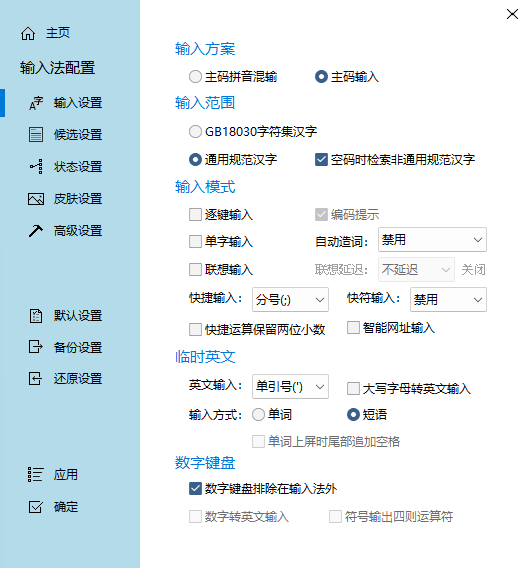
冰凌五笔
- 使用转换代码将小鸭五笔词库转换为冰凌五笔的词库格式
- 设置-词库管理-导入,选择转换好的词库文件
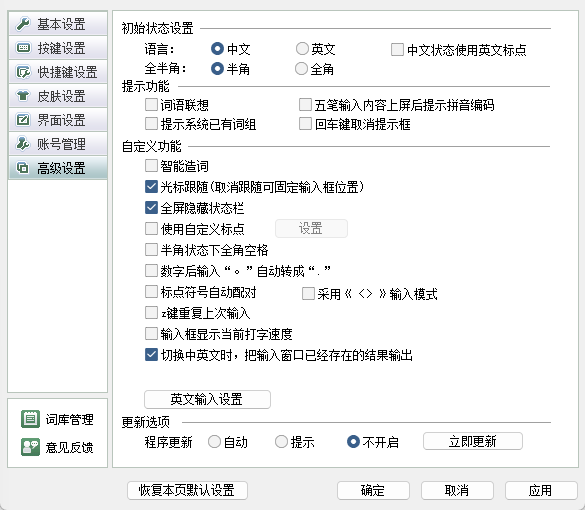
- 输入法配置,取消勾选“逐渐提示”,由于词库中的频率不对,此选项会侯选词中导致出现简码字
- “侯选项词序”,选择“词库自然顺序”
小鸭五笔,简码置后
inFileName = r'小鸭98_单字优先.txt' outFileName = r'小鸭98_单字优先_简码置后.txt' class LineInfo: def __init__(self, line, code, words): self.line = line self.code = code self.words = words def main(): with open(inFileName, 'r', encoding='utf-16-le') as fp: lines = fp.readlines() headLines = lines[0:4] # 前4行为小鸭五笔词库信息 lines = lines[4:] codes = [] lineInfos = [] for line in lines: parts = line.strip().split(' ') if len(parts) < 1: print(f'Error: not word! {line}') continue code = parts[0] # 第0个位置为编码字符串 words = parts[1:] lineInfos.append(LineInfo(line, code, words)) codes.append(code) sortedLineInfos = sorted(lineInfos, key=lambda l: len(l.code)) idx = 1 wordMap = {} codeLineMap = {} for lineInfo in sortedLineInfos: line: str = lineInfo.line code: str = lineInfo.code words: list = lineInfo.words parts = [code] + words if len(words) <= 1: # 该编码只有一个字或词 codeLineMap[code] = line word = words[0] wordMap[word] = parts continue newParts = list(parts) for word in words: if word in wordMap: preParts: list = wordMap[word] preIndex = preParts.index(word) curIndex = newParts.index(word) if curIndex >= preIndex: newParts.remove(word) newParts.append(word) wordMap[word] = newParts else: wordMap[word] = parts if parts != newParts: sortedParts = [newParts[0]] newParts = newParts[1:] sortedParts += [w for w in newParts if len(w) == 1] sortedParts += [w for w in newParts if len(w) > 1] codeLineMap[code] = ' '.join(sortedParts) + '\n' if parts != sortedParts: print(f'{parts} -> {sortedParts}') idx += 1 else: codeLineMap[code] = line else: codeLineMap[code] = line with open(outFileName, 'w', encoding='utf-16-le') as fp: fp.write('\ufeff') # Unicode BOM字符 for line in headLines: fp.write(line) for code in codes: fp.write(codeLineMap[code]) if '__main__' == __name__: main()
小鸭五笔转冰凌五笔
inFileName = r'小鸭98_单字优先_简码置后.txt' outFileName = r'冰凌(小鸭98).txt' headLines = r'''[CODETABLEHEADER] Name=小鸭98词库 Version=1.1.1.260106 Author=阿Hai CodeScheme=小鸭98_单字优先_简码置后 CodeLength=4 BWCodeLength=0 SpecialPrefix=z PhraseRule=1 [CODETABLE] ''' def main(): with open(inFileName, 'r', encoding='utf-16-le') as fp: lines = fp.readlines() # 前4行为小鸭五笔词库信息 lines = lines[4:] newParts = [] for line in lines: parts = line.strip().split(' ') if len(parts) < 1: print(f'Error: not word! {line}') continue code = parts[0] # 第0个位置为编码字符串 words = parts[1:] freq = len(words) for word in words: newPart = f'{code}\t{word}\t{freq}\n' newParts.append(newPart) freq = freq - 1 with open(outFileName, 'w', encoding='utf-16-le') as fp: fp.write('\ufeff') # Unicode BOM字符 fp.write(headLines) for line in newParts: fp.write(line) if '__main__' == __name__: main()
98五笔码表文件
代码养活自己

 浙公网安备 33010602011771号
浙公网安备 33010602011771号