


HBase的一个列簇本质上就是一棵LSM树。 LSM树分为内存部分和磁盘部分。内存部分是一个维护有序数据集合的数据结构。一般来讲,内存数据结构可以选择平衡二叉树、红黑树、跳跃表等维护有序集的数据结构,这里由于考虑并发性能,HBase选择了表现更优秀的跳跃表。磁盘部分是由一个个独立的文件组成,每一个文件又是由一个个数据块组成。对于数据存储在磁盘上的数据库系统来说,磁盘寻道以及数据读取都是非常耗时的操作(简称IO耗时)。因此,为了避免不必要的IO耗时,可以在磁盘中存储一些额外的二进制数据,这些数据用来判断对于给定的key是否有可能存储在这个数据块中,这个数据结构称为布隆过滤器
跳跃表
跳跃表(SkipList)是一种能高效实现插入、删除、查找的内存数据结构,这些操作的期望复杂度都是O(logN)。与红黑树以及其他的二分查找树相比,跳跃表的优势在于实现简单,而且在并发场景下加锁粒度更小,从而可以实现更高的并发性。正因为这些优点,跳跃表广泛使用于KV数据库中,诸如Redis、LevelDB、HBase都把跳跃表作为一种维护有序数据集合的基础数据结构。
链表这种数据结构的查询复杂度为O(N),这里N是链表中元素的个数。在已经找到要删除元素的情况下,再执行链表的删除操作其实非常高效,只需把待删除元素前一个元素的next指针指向待删除元素的后一个元素即可,复杂度为O(1)
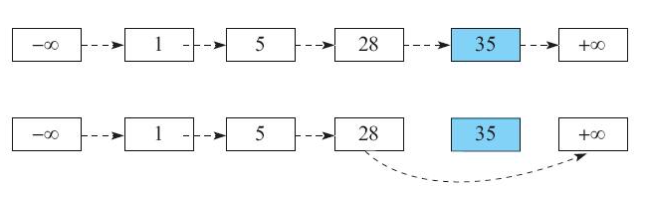
链表的查询复杂度太高,因为链表在查询的时候,需要逐个元素地查找。如果链表在查找的时候,能够避免依次查找元素,那么查找复杂度将降低。而跳跃表就是利用这一思想,在链表之上额外存储了一些节点的索引信息,达到避免依次查找元素的目的,从而将查询复杂度优化为O(logN)。将查询复杂度优化之后,自然也优化了插入和删除的复杂度
跳跃表的定义
- 从上到下,上层链表元素集合是下层链表元素集合的子集,即S1是S0的子集,S2是S1的子集
- 跳跃表的高度定义为水平链表的层数
![]()
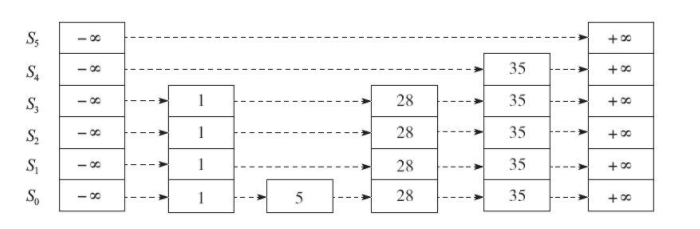
跳跃表的查找
在跳跃表中查找一个指定元素的流程比较简单。如图2-3所示,以左上角元素(设为currentNode)作为起点,如果发现currentNode后继节点的值小于等于待查询值,则沿着这条链表向后查询,否则,切换到当前节点的下一层链表。

跳跃表的写入
按照上述查找流程找到待插入元素的前驱和后继;然后按照随机算法生成一个高度值:
// p是一个(0,1)之间的常数,一般取p=1/4或者1/2
public void randomHeight(double p){
int height = 0 ;
while(random.nextDouble() < p) height ++ ;
return height + 1;
}
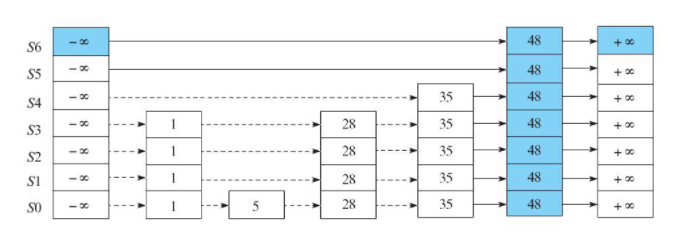
如上所示,跳跃表的查询时间复杂度为O(logN),跳跃表的插入/删除时间复杂度为O(logN)。
LSM树
LSM树本质上和B+树一样,是一种磁盘数据的索引结构。但和B+树不同的是,LSM树的索引对写入请求更友好。因为无论是何种写入请求,LSM树都会将写入操作处理为一次顺序写,而HDFS擅长的正是顺序写(且HDFS不支持随机写),因此基于HDFS实现的HBase采用LSM树作为索引是一种很合适的选择。
LSM树的索引一般由两部分组成,一部分是内存部分,一部分是磁盘部分。内存部分一般采用跳跃表来维护一个有序的KeyValue集合。磁盘部分一般由多个内部KeyValue有序的文件组成。
LSM树的索引主要由两部分构成:内存部分和磁盘部分。内存部分一般采用跳跃表来维护一个有序的KeyValue集合,是一个ConcurrentSkipListMap数据接结构,Key就是前面所说的Key部分,Value是一个字节数组。数据写入时,直接写入MemStore中。随着不断写入,一旦内存占用超过一定的阈值时,就把内存部分的数据导出,形成一个有序的数据文件,存储在磁盘上。

随着写入的增加,内存数据会不断地刷新到磁盘上。最终磁盘上的数据文件会越来越多。如果数据没有任何的读取操作,磁盘上产生很多的数据文件对写入并无影响,而且这时写入速度是最快的,因为所有IO都是顺序IO。但是,一旦用户有读取请求,则需要将大量的磁盘文件进行多路归并,之后才能读取到所需的数据。因为需要将那些Key相同的数据全局综合起来,最终选择出合适的版本返回给用户,所以磁盘文件数量越多,在读取的时候随机读取的次数也会越多,从而影响读取操作的性能;为了优化读取操作的性能,我们可以设置一定策略将选中的多个hfile进行多路归并,合并成一个文件。文件个数越少,则读取数据时需要seek操作的次数越少,读取性能则越好。
总结
LSM树的索引结构本质是将写入操作全部转化成磁盘的顺序写入,极大地提高了写入操作的性能。但是,这种设计对读取操作是非常不利的,因为需要在读取的过程中,通过归并所有文件来读取所对应的KV,这是非常消耗IO资源的。因此,在HBase中设计了异步的compaction来降低文件个数,达到提高读取性能的目的。由于HDFS只支持文件的顺序写,不支持文件的随机写,而且HDFS擅长的场景是大文件存储而非小文件,所以上层HBase选择LSM树这种索引结构是最合适的。
布隆过滤器
如何高效判断元素w是否存在于集合A之中?首先想到的答案是,把集合A中的元素一个个放到哈希表中,然后在哈希表中查一下w即可。这样确实可以解决小数据量场景下元素存在性判定,但如果A中元素数量巨大,甚至数据量远远超过机器内存空间,该如何解决问题呢?
布隆过滤器由一个长度为N的01数组array组成。首先将数组array每个元素初始设为0。
对集合A中的每个元素w,做K次哈希,第i次哈希值对N取模得到一个index(i),即index(i)=HASH_i(w)%N,将array数组中的array[index(i)]置为1。最终array变成一个某些元素为1的01数组。
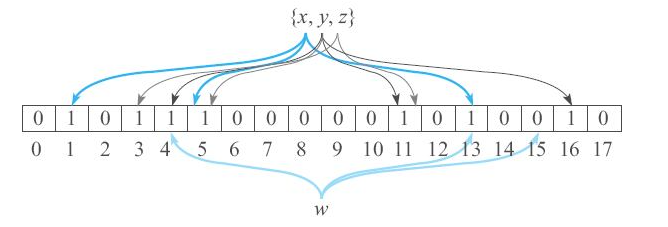
由于布隆过滤器只需占用极小的空间,便可给出“可能存在”和“肯定不存在”的存在性判断,因此可以提前过滤掉很多不必要的数据块,从而节省了大量的磁盘IO。HBase的Get操作就是通过运用低成本高效率的布隆过滤器来过滤大量无效数据块的,从而节省大量磁盘IO。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号