


hbase读写流程
hbase写流程
从整体架构的视角来看,写入流程可以概括为三个阶段4
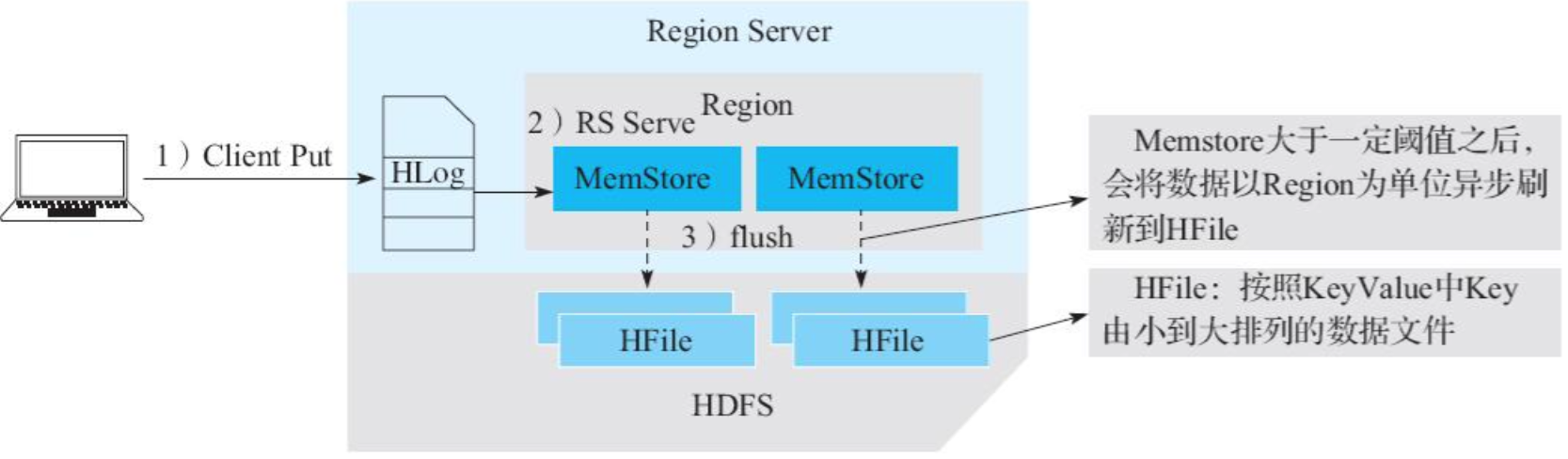
1)客户端处理阶段:客户端将用户的写入请求进行预处理,并根据集群元数据定位写入数据所在的RegionServer,将请求发送给对应的RegionServer。
2)Region写入阶段:RegionServer接收到写入请求之后将数据解析出来,首先写入WAL,再写入对应Region列簇的MemStore。
3)MemStore Flush阶段:当Region中MemStore容量超过一定阈值,系统会异步执行flush操作,将内存中的数据写入文件,形成HFile。
1、客户端处理阶段
步骤1: 用户提交put请求后,HBase客户端会将写入的数据添加到本地缓冲区中,符合一定条件就会通过AsyncProcess异步批量提交。HBase默认设置autoflush=true,表示put请求直接会提交给服务器进行处理;用户可以设置autoflush=false,这样,put请求会首先放到本地缓冲区,等到本地缓冲区大小超过一定阈值(默认为2M,可以通过配置文件配置)之后才会提交。很显然,后者使用批量提交请求,可以极大地提升写入吞吐量,但是因为没有保护机制,如果客户端崩溃,会导致部分已经提交的数据丢失。
步骤2:在提交之前,HBase会在元数据表hbase:meta中根据rowkey找到它们归属的RegionServer,这个定位的过程是通过HConnection的locateRegion方法完成的。如果是批量请求,还会把这些rowkey按照HRegionLocation分组,不同分组的请求意味着发送到不同的RegionServer,因此每个分组对应一次RPC请求
2、region 写入阶段
数据写入Region的流程可以抽象为两步:追加写入HLog,随机写入MemStore
1.追加写入HLog
HBase中系统故障恢复以及主从复制都基于HLog实现。默认情况下,所有写入操作(写入、更新以及删除)的数据都先以追加形式写入HLog,再写入MemStore。大多数情况下,HLog并不会被读取,但如果RegionServer在某些异常情况下发生宕机,此时已经写入MemStore中但尚未flush到磁盘的数据就会丢失,需要回放HLog补救丢失的数据。此外,HBase主从复制需要主集群将HLog日志发送给从集群,从集群在本地执行回放操作,完成集群之间的数据复制。
HLog生命周期
-
1)HLog构建:HBase的任何写入(更新、删除)操作都会先将记录追加写入到HLog文件中。
-
2)HLog滚动:HBase后台启动一个线程,每隔一段时间(由参数'hbase.regionserver.logroll.period'决定,默认1小时)进行日志滚动。日志滚动会新建一个新的日志文件,接收新的日志数据。日志滚动机制主要是为了方便过期日志数据能够以文件的形式直接删除。
-
3)HLog失效:写入数据一旦从MemStore中落盘,对应的日志数据就会失效。为了方便处理,HBase中日志失效删除总是以文件为单位执行。查看某个HLog文件是否失效只需确认该HLog文件中所有日志记录对应的数据是否已经完成落盘,如果日志中所有日志记录已经落盘,则可以认为该日志文件失效。一旦日志文件失效,就会从WALs文件夹移动到oldWALs文件夹。注意此时HLog并没有被系统删除。
-
4)HLog删除:Master后台会启动一个线程,每隔一段时间(参数'hbase.master.cleaner.interval',默认1分钟)检查一次文件夹oldWALs下的所有失效日志文件,确认是否可以删除,确认可以删除之后执行删除操作。
3.MemStore Flush阶段
随着数据的不断写入,MemStore中存储的数据会越来越多,系统为了将使用的内存保持在一个合理的水平,会将MemStore中的数据写入文件形成HFile。flush阶段是HBase的非常核心的阶段,理论上需要重点关注三个问题:
-
MemStore Flush的触发时机。即在哪些情况下HBase会触发flush操作。
-
MemStore Flush的整体流程。
-
HFile的构建流程。HFile构建是MemStore Flush整体流程中最重要的一个部分,这部分内容会涉及HFile文件格式的构建、布隆过滤器的构建、HFile索引的构建以及相关元数据的构建等。
hbase读流程
由于HBase使用的Megre on Read模式,HBase读数据的流程更加复杂。主要基于两个方面的原因:
- 一是因为HBase一次范围查询可能会涉及多个Region、多块缓存甚至多个数据存储文件;
- 二是因为HBase中更新操作以及删除操作的实现都很简单,更新操作并没有更新原有数据,而是使用时间戳属性实现了多版本;删除操作也并没有真正删除原有数据,只是插入了一条标记为"deleted"标签的数据,而真正的数据删除发生在系统异步执行Major Compact的时候。很显然,这种实现思路大大简化了数据更新、删除流程,但是对于数据读取来说却意味着套上了层层枷锁:读取过程需要根据版本进行过滤,对已经标记删除的数据也要进行过滤。
客户端
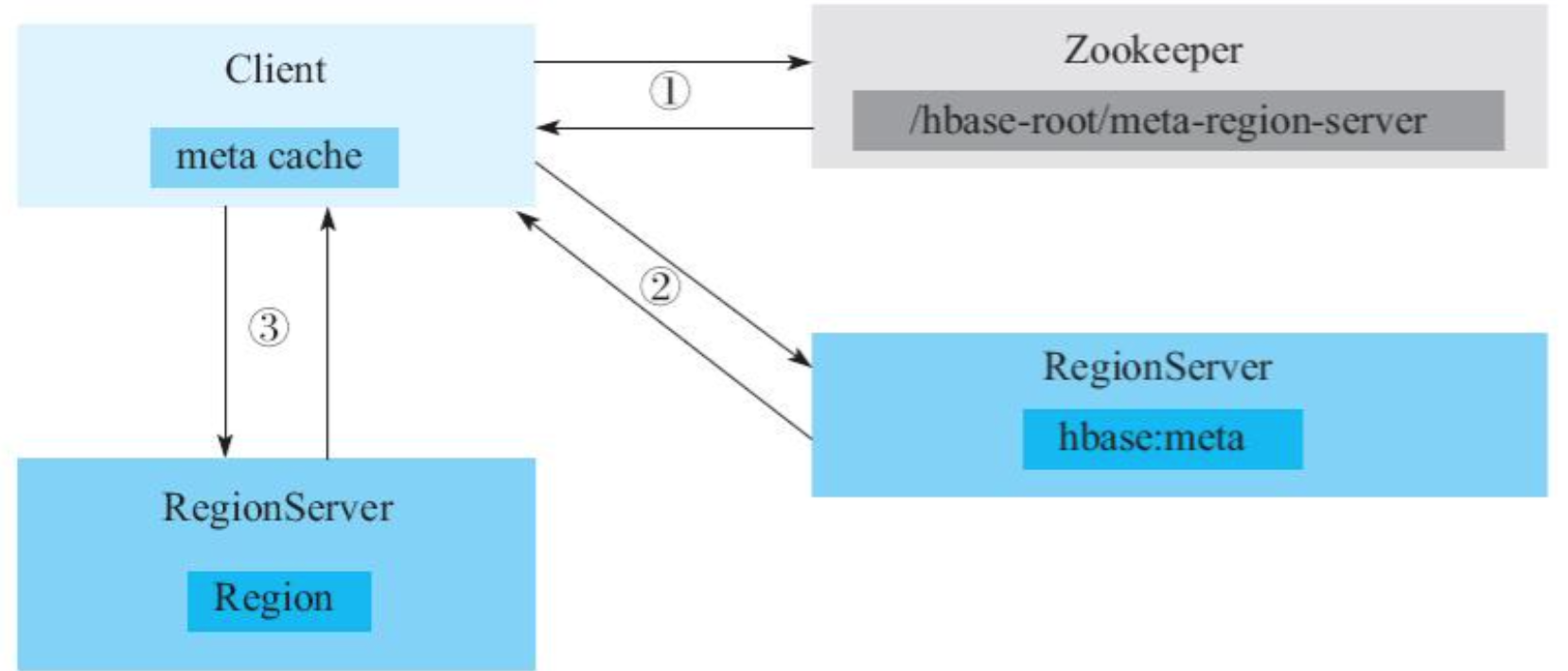
Client首先会从ZooKeeper中获取元数据hbase:meta表所在的RegionServer,然后根据待读写rowkey发送请求到元数据所在RegionServer,获取数据所在的目标RegionServer和Region(并将这部分元数据信息缓存到本地),最后将请求进行封装发送到目标RegionServer进行处理。
HBase Client端与Server端的scan操作并没有设计为一次RPC请求,这是因为一次大规模的scan操作很有可能就是一次全表扫描,扫描结果非常之大,通过一次RPC将大量扫描结果返回客户端会带来至少两个非常严重的后果:
- 大量数据传输会导致集群网络带宽等系统资源短时间被大量占用,严重影响集群中其他业务。
- 客户端很可能因为内存无法缓存这些数据而导致客户端OOM。
Region Server
一次scan可能会同时扫描一张表的多个Region,对于这种扫描,客户端会根据hbase:meta元数据将扫描的起始区间[startKey,stopKey)进行切分,切分成多个互相独立的查询子区间,每个子区间对应一个Region。比如当前表有3个Region,Region的起始区间分别为:["a","c"),["c","e"),["e","g"),客户端设置scan的扫描区间为["b","f")。因为扫描区间明显跨越了多个Region,需要进行切分,按照Region区间切分后的子区间为["b","c"),["c","e"),["e","f")。
HBase中每个Region都是一个独立的存储引擎,因此客户端可以将每个子区间请求分别发送给对应的Region进行处理。下文会聚焦于单个Region处理scan请求的核心流程。
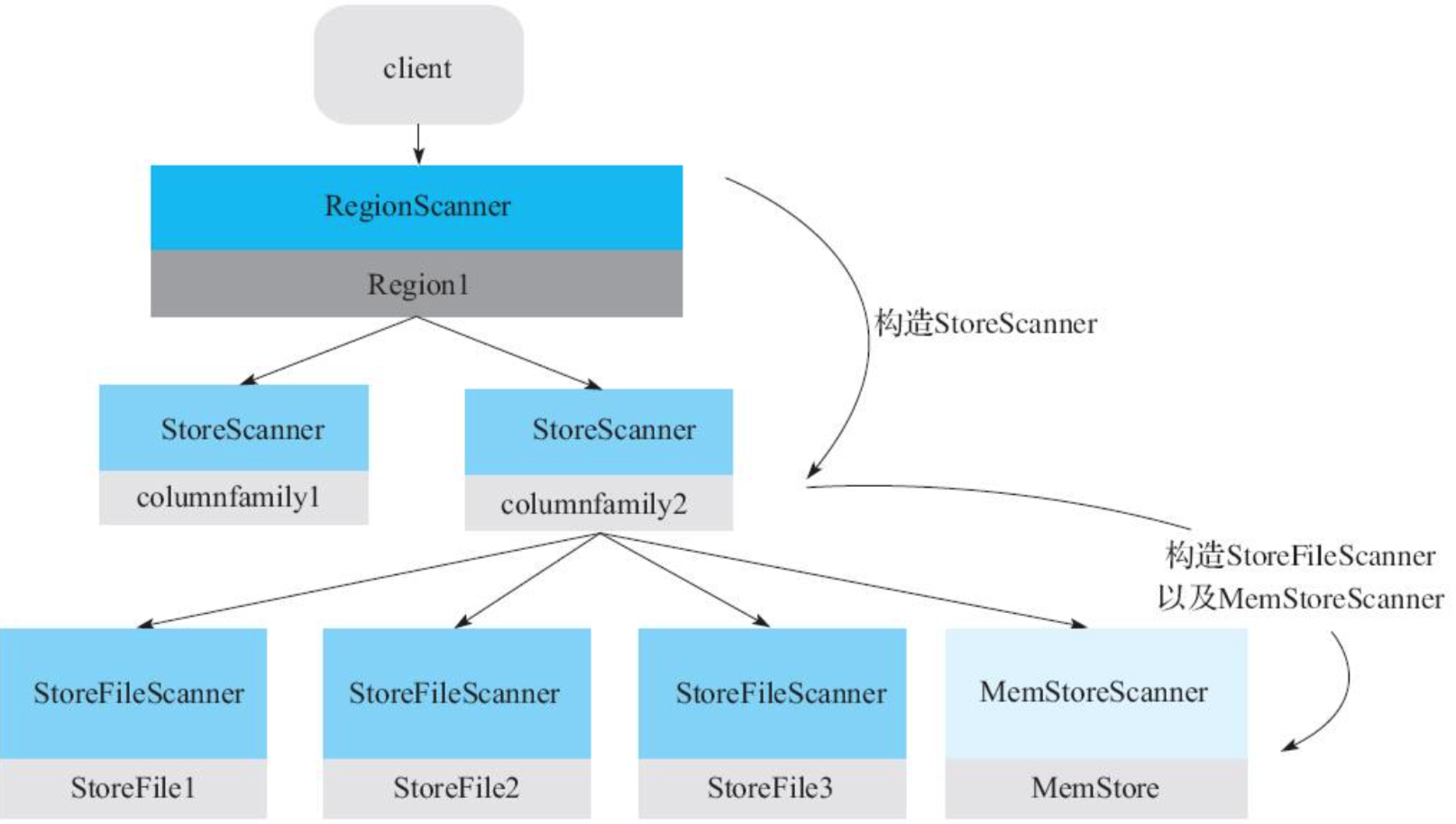
Scanner的核心体系包括三层Scanner:RegionScanner,StoreScanner,MemStoreScanner和StoreFileScanner。
BlockCache
为了提升读取性能,HBase也实现了一种读缓存结构——BlockCache。客户端读取某个Block,首先会检查该Block是否存在于Block Cache,如果存在就直接加载出来,如果不存在则去HFile文件中加载,加载出来之后放到Block Cache中,后续同一请求或者邻近数据查找请求可以直接从内存中获取,以避免昂贵的IO操作。
BlockCache是RegionServer级别的,一个RegionServer只有一个BlockCache,在RegionServer启动时完成BlockCache的初始化工作。到目前为止,HBase先后实现了3种BlockCache方案,LRUBlockCache是最早的实现方案,也是默认的实现方案;HBase 0.92版本实现了第二种方案SlabCache,参见HBASE-4027;HBase 0.96之后官方提供了另一种可选方案BucketCache
LRUBlockCache
LRUBlockCache是HBase目前默认的BlockCache机制,实现相对比较简单。它使用一个ConcurrentHashMap管理BlockKey到Block的映射关系,缓存Block只需要将BlockKey和对应的Block放入该HashMap中,查询缓存就根据BlockKey从HashMap中获取即可。同时,该方案采用严格的LRU淘汰算法,当Block Cache总量达到一定阈值之后就会启动淘汰机制,最近最少使用的Block会被置换出来。在具体的实现细节方面,需要关注以下三点。
1.缓存分层策略
HBase采用了缓存分层设计,将整个BlockCache分为三个部分:single-access、multi-access和in-memory,分别占到整个BlockCache大小的25%、50%、25%。
在一次随机读中,一个Block从HDFS中加载出来之后首先放入single-access区,后续如果有多次请求访问到这个Block,就会将这个Block移到multi-access区。而in-memory区表示数据可以常驻内存,一般用来存放访问频繁、量小的数据,比如元数据,用户可以在建表的时候设置列簇属性IN_MEMORY=true,设置之后该列簇的Block在从磁盘中加载出来之后会直接放入in-memory区
2.LRUBlockCache方案优缺点
UBlockCache方案使用JVM提供的HashMap管理缓存,简单有效。但随着数据从single-access区晋升到multi-access区或长时间停留在single-access区,对应的内存对象会从young区晋升到old区,晋升到old区的Block被淘汰后会变为内存垃圾,最终由CMS回收(Conccurent Mark Sweep,一种标记清除算法),显然这种算法会带来大量的内存碎片,碎片空间一直累计就会产生臭名昭著的Full GC。尤其在大内存条件下,一次Full GC很可能会持续较长时间,甚至达到分钟级别
SlabCache
为了解决LRUBlockCache方案中因JVM垃圾回收导致的服务中断问题,SlabCache方案提出使用Java NIO DirectByteBuffer技术实现堆外内存存储,不再由JVM管理数据内存。默认情况下,系统在初始化的时候会分配两个缓存区,分别占整个BlockCache大小的80%和20%,每个缓存区分别存储固定大小的Block,其中前者主要存储小于等于64K的Block,后者存储小于等于128K的Block,如果一个Block太大就会导致两个区都无法缓存。
BucketCache
SlabCache方案在实际应用中并没有很大程度改善原有LRUBlockCache方案的GC弊端,还额外引入了诸如堆外内存使用率低的缺陷。然而它的设计并不是一无是处,至少在使用堆外内存这方面给予了后续开发者很多启发。站在SlabCache的肩膀上,社区工程师设计开发了另一种非常高效的缓存方案——BucketCache。
BucketCache通过不同配置方式可以工作在三种模式下:heap,offheap和file。heap模式表示这些Bucket是从JVM Heap中申请的;offheap模式使用DirectByteBuffer技术实现堆外内存存储管理;file模式使用类似SSD的存储介质来缓存Data Block。无论工作在哪种模式下,BucketCache都会申请许多带有固定大小标签的Bucket,和SlabCache一样,一种Bucket存储一种指定BlockSize的Data Block,但和SlabCache不同的是,BucketCache会在初始化的时候申请14种不同大小的Bucket,而且如果某一种Bucket空间不足,系统会从其他Bucket空间借用内存使用,因此不会出现内存使用率低的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号