

实验一
单机伪分布式安装
-
在 ubuntu:latest 运行容器并完成安装(时间为2025.9.22)
-
cp /etc/apt/sources.list /etc/apt/sources.list.bak对源文件备份 -
apt update && apt install nano安装nano -
nano /etc/apt/sources.list修改源文件如下# Ubuntu sources have moved to the /etc/apt/sources.list.d/ubuntu.sources # file, which uses the deb822 format. Use deb822-formatted .sources files # to manage package sources in the /etc/apt/sources.list.d/ directory. # See the sources.list(5) manual page for details. deb http://mirrors.aliyun.com/ubuntu/ noble main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ noble-updates main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ noble-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ noble-backports main restricted universe multiverse -
apt update && apt-get update更新源操作 -
apt-get install openssh-server安装SSH -
配置公私钥:
cd ~/.ssh/ssh-keygen -t rsacat ./id_rsa.pub >> ./authorized_keys
-
apt-get install default-jre default-jdk安装Java -
编辑环境变量
-
nano ~/.bashrc -
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export PATH=$JAVA_HOME/bin:$PATH -
source ~/.bashrc
-
-
-
下载并解压 hadoop,然后配置环境变量
wget https://downloads.apache.org/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gztar -zxf /workspace/hadoop-3.4.0.tar.gz -C /usr/local-
export HADOOP_HOME=/usr/local/hadoop-3.4.0 # 同样添加到.bashrc中 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
-
将 java 环境写入配置文件
cd /usr/local/hadoop-3.4.0/etc/hadoopnano hadoop-env.sh- 添加`export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
- 激活配置
source hadoop-env.sh
-
编辑配置文件
-
core-site.xml:设置存放目录以及主机号、端口号
-
nano core-site.xml -
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop-3.4.0/etc/hadoop/tmp</value> <description>A base for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
-
-
hdfs-site.xml:配置复制块的数目,namenode 节点以及 datanode 节点存储的本地路径
-
nano hdfs-site.xml -
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop-3.4.0/etc/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop-3.4.0/etc/hadoop/tmp/dfs/data</value> </property> </configuration>
-
-
mapred-site.xml
-
nano mapred-site.xml -
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.4.0</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.4.0</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.4.0</value> </property> </configuration>
-
-
yarn-site.xml
-
nano yarn -site.xml -
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
-
-
/usr/local/hadoop-3.4.0/bin/hdfs namenode -format格式化 hadoop -
启动系统
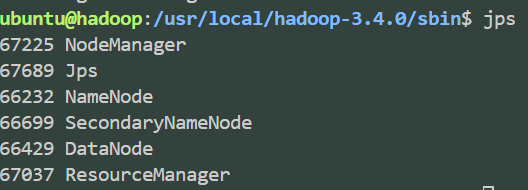
cd /usr/local/hadoop-3.4.0/sbin进入对应路径start-all.sh启动系统- 使用
jps检查运行状态 ![image]()
-
运行测试
- 创建文件夹
hdfs dfs -mkdir /userhdfs dfs -mkdir /user/ubuntuhdfs dfs -mkdir /user/ubuntu/input
hdfs dfs -put /workspace/example.txt input放入实验输入数据- 实验输入数据
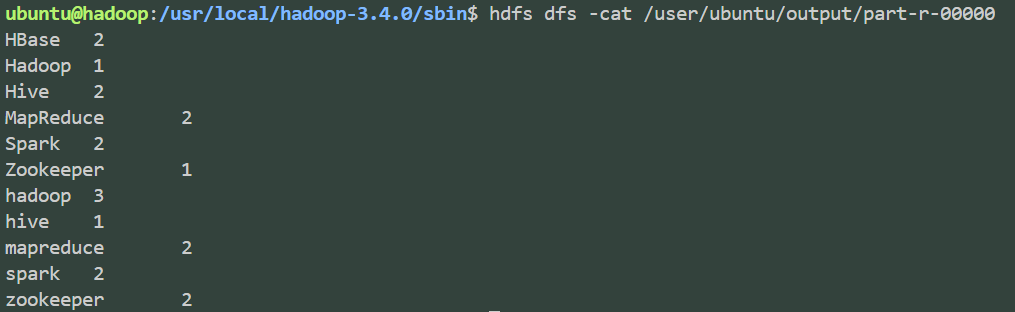
hadoop jar /usr/local/hadoop-3.4.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.0.jar wordcount /user/ubuntu/input /user/ubuntu/output使用官方jar包执行wordcount任务,输出如下ubuntu@hadoop:/usr/local/hadoop-3.4.0/sbin$ hadoop jar /usr/local/hadoop-3.4.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.0.jar wordcount /user/ubuntu/input /user/ubuntu/output 2025-09-24 19:20:53,784 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032 2025-09-24 19:20:54,257 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/ubuntu/.staging/job_1758712791889_0001 2025-09-24 19:20:55,183 INFO input.FileInputFormat: Total input files to process : 1 2025-09-24 19:20:55,278 INFO mapreduce.JobSubmitter: number of splits:1 2025-09-24 19:20:55,472 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1758712791889_0001 2025-09-24 19:20:55,472 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2025-09-24 19:20:55,662 INFO conf.Configuration: resource-types.xml not found 2025-09-24 19:20:55,662 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 2025-09-24 19:20:56,155 INFO impl.YarnClientImpl: Submitted application application_1758712791889_0001 2025-09-24 19:20:56,192 INFO mapreduce.Job: The url to track the job: http://hadoop:8088/proxy/application_1758712791889_0001/ 2025-09-24 19:20:56,192 INFO mapreduce.Job: Running job: job_1758712791889_0001 2025-09-24 19:21:03,316 INFO mapreduce.Job: Job job_1758712791889_0001 running in uber mode : false 2025-09-24 19:21:03,317 INFO mapreduce.Job: map 0% reduce 0% 2025-09-24 19:21:08,388 INFO mapreduce.Job: map 100% reduce 0% 2025-09-24 19:21:13,426 INFO mapreduce.Job: map 100% reduce 100% 2025-09-24 19:21:14,445 INFO mapreduce.Job: Job job_1758712791889_0001 completed successfully 2025-09-24 19:21:14,551 INFO mapreduce.Job: Counters: 54 File System Counters FILE: Number of bytes read=154 FILE: Number of bytes written=618419 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=265 HDFS: Number of bytes written=104 HDFS: Number of read operations=8 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 HDFS: Number of bytes read erasure-coded=0 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=2566 Total time spent by all reduces in occupied slots (ms)=2752 Total time spent by all map tasks (ms)=2566 Total time spent by all reduce tasks (ms)=2752 Total vcore-milliseconds taken by all map tasks=2566 Total vcore-milliseconds taken by all reduce tasks=2752 Total megabyte-milliseconds taken by all map tasks=2627584 Total megabyte-milliseconds taken by all reduce tasks=2818048 Map-Reduce Framework Map input records=4 Map output records=20 Map output bytes=229 Map output materialized bytes=154 Input split bytes=116 Combine input records=20 Combine output records=11 Reduce input groups=11 Reduce shuffle bytes=154 Reduce input records=11 Reduce output records=11 Spilled Records=22 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=55 CPU time spent (ms)=1290 Physical memory (bytes) snapshot=532426752 Virtual memory (bytes) snapshot=5536251904 Total committed heap usage (bytes)=312475648 Peak Map Physical memory (bytes)=288735232 Peak Map Virtual memory (bytes)=2760597504 Peak Reduce Physical memory (bytes)=243691520 Peak Reduce Virtual memory (bytes)=2775654400 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=149 File Output Format Counters Bytes Written=104- 输出结果
hdfs dfs -cat output/*
![image]()
- 创建文件夹
问题及解决
- Hadoop一般不在root用户下运行,所以上面的命令最开始的一些命令没有加
sudo,是因为是在root用户下运行的;后面发现不行之后切换了用户重新安装了一次。切换用户的话,~目录会变化,所以只需要重新执行与~相关的操作即可 - 中途使用
start-all.sh的时候,会遇到很多错误,重启的话要使用stop-all.sh,同时rm -rf /usr/local/hadoop-3.4.0/etc/hadoop/tmp/dfs/data/*
docker 集群安装
- 在上一个实验的容器中修改四个配置文件如下
core-site.xml<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop-3.4.0/etc/hadoop/tmp</value> <description>A base for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <value>hdfs://h01:9000</value> </property> </configuration>hdfs-site.xml<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop-3.4.0/etc/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop-3.4.0/etc/hadoop/tmp/dfs/data</value> </property> </configuration>yarn-site.xml<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>h01</value> </property> </configuration>mapred-site.xml<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.4.0</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.4.0</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.4.0</value> </property> <property> <name>mapreduce.application.classpath</name> <value> /usr/local/hadoop-3.4.0/etc/hadoop, /usr/local/hadoop-3.4.0/share/hadoop/common/*, /usr/local/hadoop-3.4.0/share/hadoop/common/lib/*, /usr/local/hadoop-3.4.0/share/hadoop/hdfs/*, /usr/local/hadoop-3.4.0/share/hadoop/hdfs/lib/*, /usr/local/hadoop-3.4.0/share/hadoop/mapreduce/*, /usr/local/hadoop-3.4.0/share/hadoop/mapreduce/lib/*, /usr/local/hadoop-3.4.0/share/hadoop/yarn/*, /usr/local/hadoop-3.4.0/share/hadoop/yarn/lib/* </value> </property> </configuration>
- 同时在
.bashrc的末尾加上export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_CONF_DIR=$HADOOP_HOME export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HDFS_DATANODE_USER=root export HDFS_DATANODE_SECURE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_NAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root - 然后在
hadoop-env.sh末尾加上export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root - 最后修改
workers为h01 h02 h03 h04 h05 - 将当前容器导出为镜像,命名为
hadoop - 在宿主机终端运行
docker network create --driver=bridge hadoop创建网络 - 在宿主机终端中运行
docker run -dit --network hadoop -h "h01" --name "h01" hadoop(以及h02,h03,h04,h05) - 进入每一个容器,启动SSH服务之后,执行
stop-all.sh,然后rm -rf /usr/local/hadoop-3.4.0/etc/hadoop/tmp/dfs/data/* - 进入
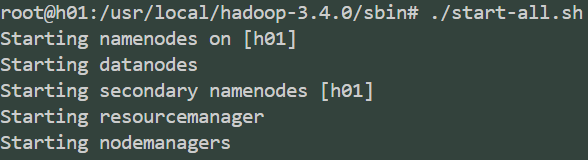
h01,执行start-all.sh
![image]()
- 查看HDFS状态
root@h01:/usr/local/hadoop-3.4.0/bin# ./hadoop dfsadmin -report WARNING: Use of this script to execute dfsadmin is deprecated. WARNING: Attempting to execute replacement "hdfs dfsadmin" instead. Configured Capacity: 5405505884160 (4.92 TB) Present Capacity: 5037934489600 (4.58 TB) DFS Remaining: 5037934366720 (4.58 TB) DFS Used: 122880 (120 KB) DFS Used%: 0.00% Replicated Blocks: Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 Erasure Coded Block Groups: Low redundancy block groups: 0 Block groups with corrupt internal blocks: 0 Missing block groups: 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (5): Name: 172.18.0.2:9866 (h01) Hostname: h01 Decommission Status : Normal Configured Capacity: 1081101176832 (1006.85 GB) DFS Used: 24576 (24 KB) Non DFS Used: 18521923584 (17.25 GB) DFS Remaining: 1007586873344 (938.39 GB) DFS Used%: 0.00% DFS Remaining%: 93.20% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 0 Last contact: Fri Sep 26 10:52:39 CST 2025 Last Block Report: Fri Sep 26 10:51:53 CST 2025 Num of Blocks: 0 Name: 172.18.0.3:9866 (h02.hadoop) Hostname: h02 Decommission Status : Normal Configured Capacity: 1081101176832 (1006.85 GB) DFS Used: 24576 (24 KB) Non DFS Used: 18521923584 (17.25 GB) DFS Remaining: 1007586873344 (938.39 GB) DFS Used%: 0.00% DFS Remaining%: 93.20% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 0 Last contact: Fri Sep 26 10:52:39 CST 2025 Last Block Report: Fri Sep 26 10:51:53 CST 2025 Num of Blocks: 0 Name: 172.18.0.4:9866 (h03.hadoop) Hostname: h03 Decommission Status : Normal Configured Capacity: 1081101176832 (1006.85 GB) DFS Used: 24576 (24 KB) Non DFS Used: 18521923584 (17.25 GB) DFS Remaining: 1007586873344 (938.39 GB) DFS Used%: 0.00% DFS Remaining%: 93.20% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 0 Last contact: Fri Sep 26 10:52:39 CST 2025 Last Block Report: Fri Sep 26 10:51:53 CST 2025 Num of Blocks: 0 Name: 172.18.0.5:9866 (h04.hadoop) Hostname: h04 Decommission Status : Normal Configured Capacity: 1081101176832 (1006.85 GB) DFS Used: 24576 (24 KB) Non DFS Used: 18521923584 (17.25 GB) DFS Remaining: 1007586873344 (938.39 GB) DFS Used%: 0.00% DFS Remaining%: 93.20% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 0 Last contact: Fri Sep 26 10:52:39 CST 2025 Last Block Report: Fri Sep 26 10:51:53 CST 2025 Num of Blocks: 0 Name: 172.18.0.6:9866 (h05.hadoop) Hostname: h05 Decommission Status : Normal Configured Capacity: 1081101176832 (1006.85 GB) DFS Used: 24576 (24 KB) Non DFS Used: 18521923584 (17.25 GB) DFS Remaining: 1007586873344 (938.39 GB) DFS Used%: 0.00% DFS Remaining%: 93.20% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 0 Last contact: Fri Sep 26 10:52:39 CST 2025 Last Block Report: Fri Sep 26 10:51:53 CST 2025 Num of Blocks: 0 - 创建输入文件夹
root@h01:/usr/local/hadoop-3.4.0/bin# ./hdfs dfs -mkdir /user root@h01:/usr/local/hadoop-3.4.0/bin# ./hdfs dfs -mkdir /user/root root@h01:/usr/local/hadoop-3.4.0/bin# ./hdfs dfs -mkdir /user/root/input - 放入实验输入数据
root@h01:/usr/local/hadoop-3.4.0/bin# ./hdfs dfs -put /usr/local/hadoop-3.4.0/etc/hadoop/*.xml input - 运行程序
root@h01:/usr/local/hadoop-3.4.0/bin# ./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.0.jar grep input output 'dfs[a-z.]+' 2025-09-26 11:01:15,210 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at h01/172.18.0.2:8032 2025-09-26 11:01:15,972 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1758855123579_0001 2025-09-26 11:01:16,904 INFO input.FileInputFormat: Total input files to process : 10 2025-09-26 11:01:17,157 INFO mapreduce.JobSubmitter: number of splits:10 2025-09-26 11:01:17,411 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1758855123579_0001 2025-09-26 11:01:17,411 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2025-09-26 11:01:17,615 INFO conf.Configuration: resource-types.xml not found 2025-09-26 11:01:17,615 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 2025-09-26 11:01:18,265 INFO impl.YarnClientImpl: Submitted application application_1758855123579_0001 2025-09-26 11:01:18,329 INFO mapreduce.Job: The url to track the job: http://h01:8088/proxy/application_1758855123579_0001/ 2025-09-26 11:01:18,330 INFO mapreduce.Job: Running job: job_1758855123579_0001 2025-09-26 11:01:30,509 INFO mapreduce.Job: Job job_1758855123579_0001 running in uber mode : false 2025-09-26 11:01:30,510 INFO mapreduce.Job: map 0% reduce 0% 2025-09-26 11:01:52,717 INFO mapreduce.Job: map 100% reduce 0% 2025-09-26 11:01:59,789 INFO mapreduce.Job: map 100% reduce 100% 2025-09-26 11:02:00,806 INFO mapreduce.Job: Job job_1758855123579_0001 completed successfully 2025-09-26 11:02:00,936 INFO mapreduce.Job: Counters: 54 File System Counters FILE: Number of bytes read=115 FILE: Number of bytes written=3411758 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=35119 HDFS: Number of bytes written=219 HDFS: Number of read operations=35 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 HDFS: Number of bytes read erasure-coded=0 Job Counters Launched map tasks=10 Launched reduce tasks=1 Data-local map tasks=10 Total time spent by all maps in occupied slots (ms)=186042 Total time spent by all reduces in occupied slots (ms)=4430 Total time spent by all map tasks (ms)=186042 Total time spent by all reduce tasks (ms)=4430 Total vcore-milliseconds taken by all map tasks=186042 Total vcore-milliseconds taken by all reduce tasks=4430 Total megabyte-milliseconds taken by all map tasks=190507008 Total megabyte-milliseconds taken by all reduce tasks=4536320 Map-Reduce Framework Map input records=898 Map output records=4 Map output bytes=101 Map output materialized bytes=169 Input split bytes=1119 Combine input records=4 Combine output records=4 Reduce input groups=4 Reduce shuffle bytes=169 Reduce input records=4 Reduce output records=4 Spilled Records=8 Shuffled Maps =10 Failed Shuffles=0 Merged Map outputs=10 GC time elapsed (ms)=974 CPU time spent (ms)=22690 Physical memory (bytes) snapshot=3039399936 Virtual memory (bytes) snapshot=30466097152 Total committed heap usage (bytes)=2458910720 Peak Map Physical memory (bytes)=315047936 Peak Map Virtual memory (bytes)=2774376448 Peak Reduce Physical memory (bytes)=229793792 Peak Reduce Virtual memory (bytes)=2775670784 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=34000 File Output Format Counters Bytes Written=219 2025-09-26 11:02:00,988 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at h01/172.18.0.2:8032 2025-09-26 11:02:01,016 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1758855123579_0002 2025-09-26 11:02:01,150 INFO input.FileInputFormat: Total input files to process : 1 2025-09-26 11:02:01,567 INFO mapreduce.JobSubmitter: number of splits:1 2025-09-26 11:02:01,652 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1758855123579_0002 2025-09-26 11:02:01,653 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2025-09-26 11:02:01,891 INFO impl.YarnClientImpl: Submitted application application_1758855123579_0002 2025-09-26 11:02:01,898 INFO mapreduce.Job: The url to track the job: http://h01:8088/proxy/application_1758855123579_0002/ 2025-09-26 11:02:01,898 INFO mapreduce.Job: Running job: job_1758855123579_0002 2025-09-26 11:02:12,326 INFO mapreduce.Job: Job job_1758855123579_0002 running in uber mode : false 2025-09-26 11:02:12,327 INFO mapreduce.Job: map 0% reduce 0% 2025-09-26 11:02:17,372 INFO mapreduce.Job: map 100% reduce 0% 2025-09-26 11:02:21,397 INFO mapreduce.Job: map 100% reduce 100% 2025-09-26 11:02:21,423 INFO mapreduce.Job: Job job_1758855123579_0002 completed successfully 2025-09-26 11:02:21,463 INFO mapreduce.Job: Counters: 54 File System Counters FILE: Number of bytes read=115 FILE: Number of bytes written=619303 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=342 HDFS: Number of bytes written=77 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 HDFS: Number of bytes read erasure-coded=0 Job Counters Launched map tasks=1 Launched reduce tasks=1 Rack-local map tasks=1 Total time spent by all maps in occupied slots (ms)=2548 Total time spent by all reduces in occupied slots (ms)=2477 Total time spent by all map tasks (ms)=2548 Total time spent by all reduce tasks (ms)=2477 Total vcore-milliseconds taken by all map tasks=2548 Total vcore-milliseconds taken by all reduce tasks=2477 Total megabyte-milliseconds taken by all map tasks=2609152 Total megabyte-milliseconds taken by all reduce tasks=2536448 Map-Reduce Framework Map input records=4 Map output records=4 Map output bytes=101 Map output materialized bytes=115 Input split bytes=123 Combine input records=0 Combine output records=0 Reduce input groups=1 Reduce shuffle bytes=115 Reduce input records=4 Reduce output records=4 Spilled Records=8 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=42 CPU time spent (ms)=1310 Physical memory (bytes) snapshot=521785344 Virtual memory (bytes) snapshot=5536550912 Total committed heap usage (bytes)=418381824 Peak Map Physical memory (bytes)=281378816 Peak Map Virtual memory (bytes)=2764505088 Peak Reduce Physical memory (bytes)=240406528 Peak Reduce Virtual memory (bytes)=2772045824 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=219 File Output Format Counters Bytes Written=77
问题及解决
- 只遇到了一个问题,就是对第一个实验的容器commit之后需要先将datanode的资源删空,上面的步骤已经涉及

 浙公网安备 33010602011771号
浙公网安备 33010602011771号