


第十二课 问答

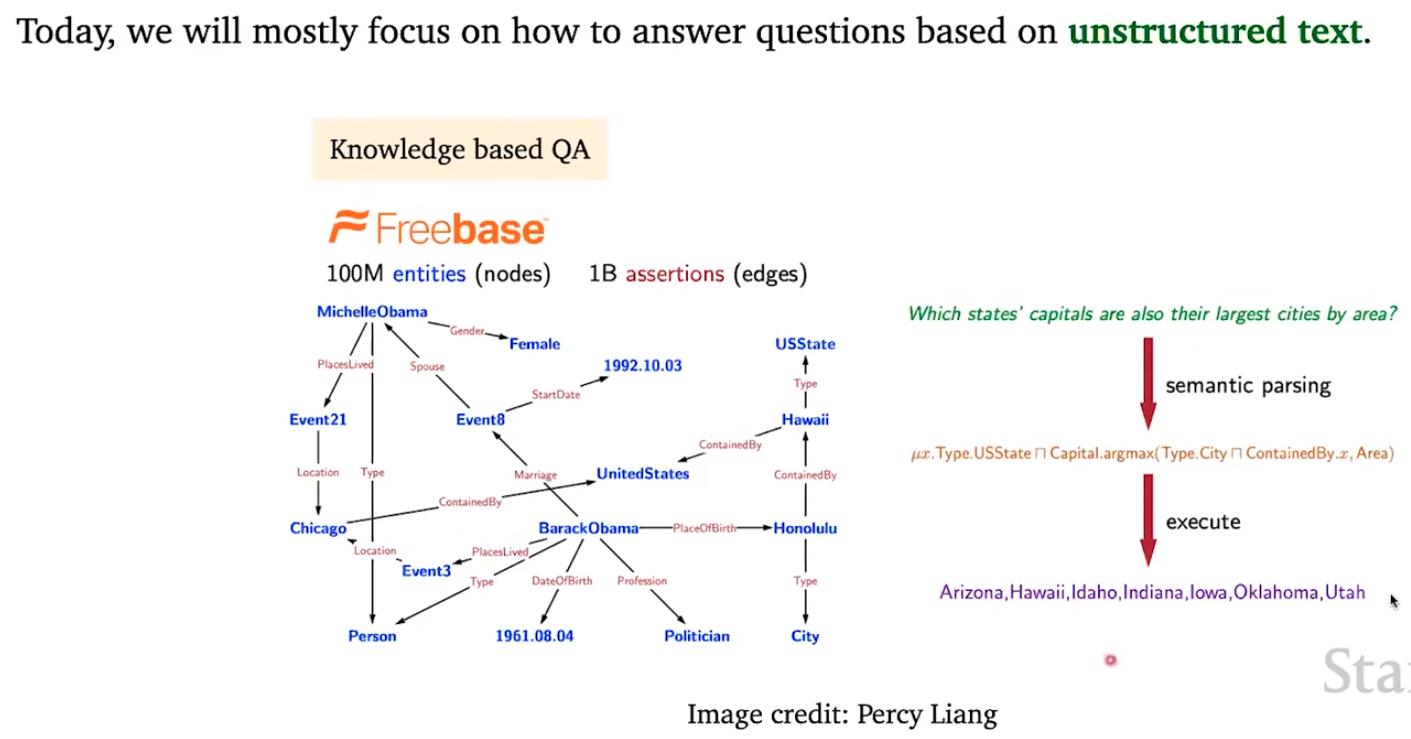
这张图片就是:左边给了一个知识图谱,右边给了一个自然语言转化成逻辑语言然后在知识图谱中进行查询的方法

这堂课的重点是谈一谈阅读理解(Reading Comprehension)



解释一下两个例子
- 信息提取:假设现在我们想要做一个关于奥巴马的背景信息提取,如图所示,我们现在想要知道奥巴马在哪里受的教育,我们将其转换成奥巴马在哪里毕业,然后进行阅读理解就好了
- 语义角色标注:假设现在我们想要知道单词"finish"的作用,我们问很多个关于"finish"的问题,然后一一进行回答就好了


这里交替使用这些词的原因就是这五个词在不同的论文中都有使用,表达的意思是相同的。例子中的计算如下:

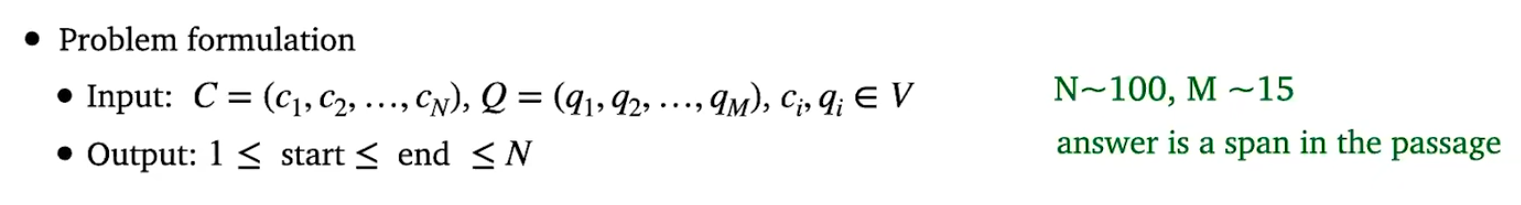
解决方法如下

首先介绍一下LSTM模型
类比seq2seq机器翻译,有些相似的地方,也有不同的地方

下面是一个典型的双向LSTM,在BERT出来之前,效果非常好

接下来我们逐层解析这个结构
- 编码层
编码层分为如下三个层次:字符嵌入层,单词嵌入层和短语嵌入层
![image]()
我们先对每一个字符映射到嵌入空间中,然后进行CNN得到一维向量(字符嵌入层);再将得到的一维向量与词向量(单词嵌入层)进行拼接;最后再使用LSTM进行上下文编码(短语嵌入层)
这里简要提一下,我们的解码器是不会使用双向LSTM的,因为解码器是自回归的,但是这里我们不关心生成(也就是实现的不是解码器),所以用双向的没有什么关系 - 注意力层
![image]()
![image]()
![image]()
这也是为什么这个模型叫做双向注意力流的原因:既有上下文到查询,也有查询到上下文的注意力
下面是详细的计算过程
![image]()
右下角的\(b_i\)写错了,应该就是一个向量\(b\);带点的圆圈就是哈达姆积,\(w_{\text{sim}}\)是可学习的参数;这里两个方向的注意力表达式不对称的原因CDQ说的稀里糊涂的(她想表达的就是,由于我们最终的目标是输出上下文中的答案起始点和答案结束点,所以我们最终给全连接层的只是上下文,不包含询问,所以我们没有必要以询问的单词为主体做注意力;这当然会有一个问题,就是我只使用一个方向的注意力可以吗,第二个注意力是不是多余的?答案当然是可以的),真搞不太清楚,明明上面的图片实例的注意力表达式就是对称的
![image]()
这里没有写错,就是\(c_i\)与\(b\)的哈达姆积,而不是\(q_i\)与\(b\)的哈达姆积 - 建模层和输出层
![image]()
![image]()
注意这里建模层为什么说是对上下文进行双向编码:看我们前面注意力层的输出\(g_i\),实际上主体就是上下文而不是询问,所以这里确实是对上下文进行建模
![image]()
![image]()
\(s^*\)和\(e^*\)是黄金文本(也就是给的标签)










下面是一些结果展示

接下来介绍一下阅读理解中的BERT

下面看一下效果

对比一下BERT和BiDAF


CDQ做了一个比普通BERT更牛逼的BERT

\(p_{i-s+1}\)是位置编码
看一下效果对比

从上面的一张对比图可以看到,当前的AI已经可以超过人类的阅读理解能力,但是仍然存在一些问题

- 对抗例子
![image]()
- 协变量偏移
![image]()
中间黑体对角线表示预训练数据 - 其他类型问题
![image]()
![image]()




最后介绍一下开放域问答

解决这个问题的方法:先通过一个检索程序找出所有相关的文本,再来一个阅读程序从这些少量的相关文本中得出答案。形式地说

我们也可以训练检索程序

甚至还可以不使用检索程序,直接使用T5

也可能不需要阅读程序

视频01:20:00之后是提问


 浙公网安备 33010602011771号
浙公网安备 33010602011771号