

第十一课 自然语言生成
先来按照任务的开放性对自然语言生成的任务进行分类
- 不那么开放的
- 机器翻译
![image]()
显然输出空间不是那么大 - 总结
- 机器翻译
- 一般开放的
- 对话
![image]()
- 对话
- 非常开放的
- 故事生成
![image]()
- 故事生成



将上面的任务总结成一条线如下

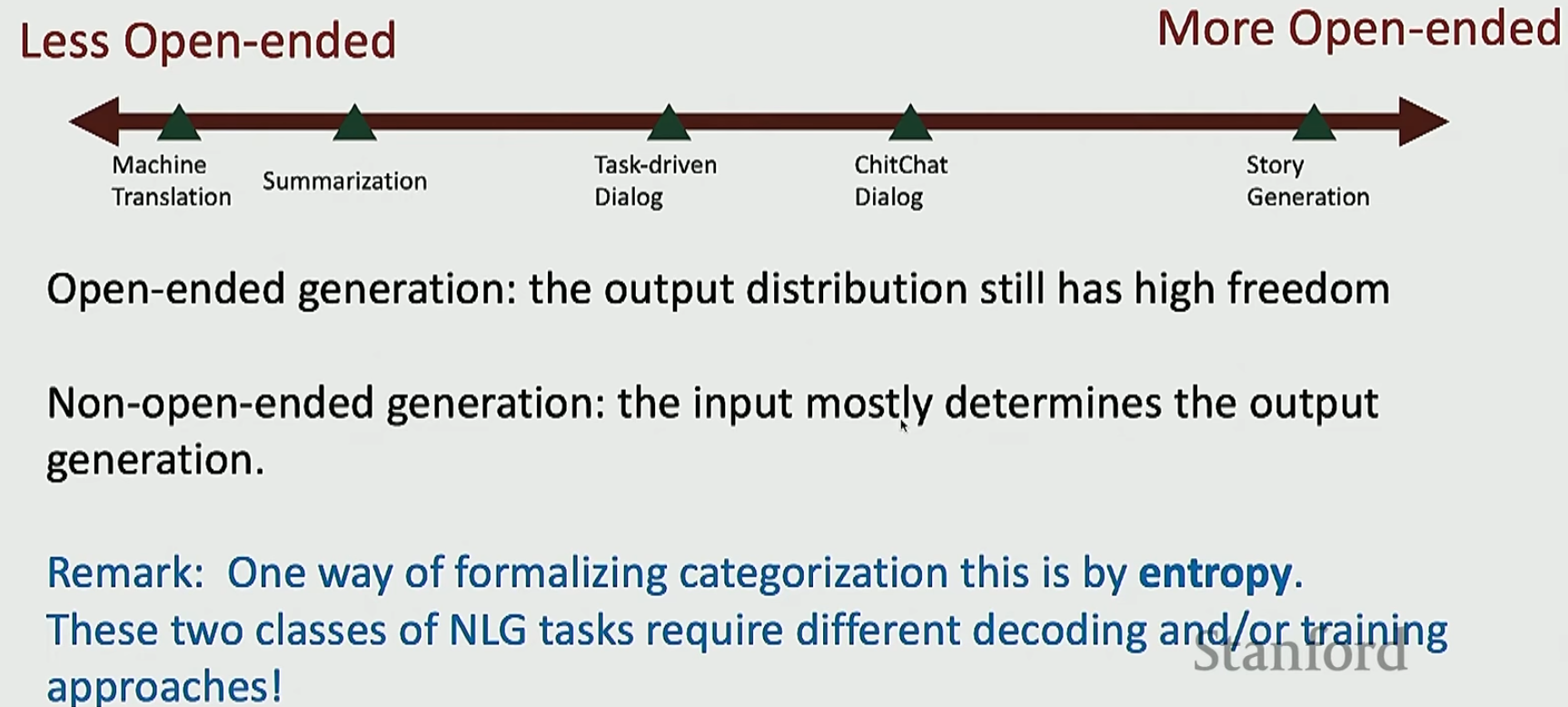
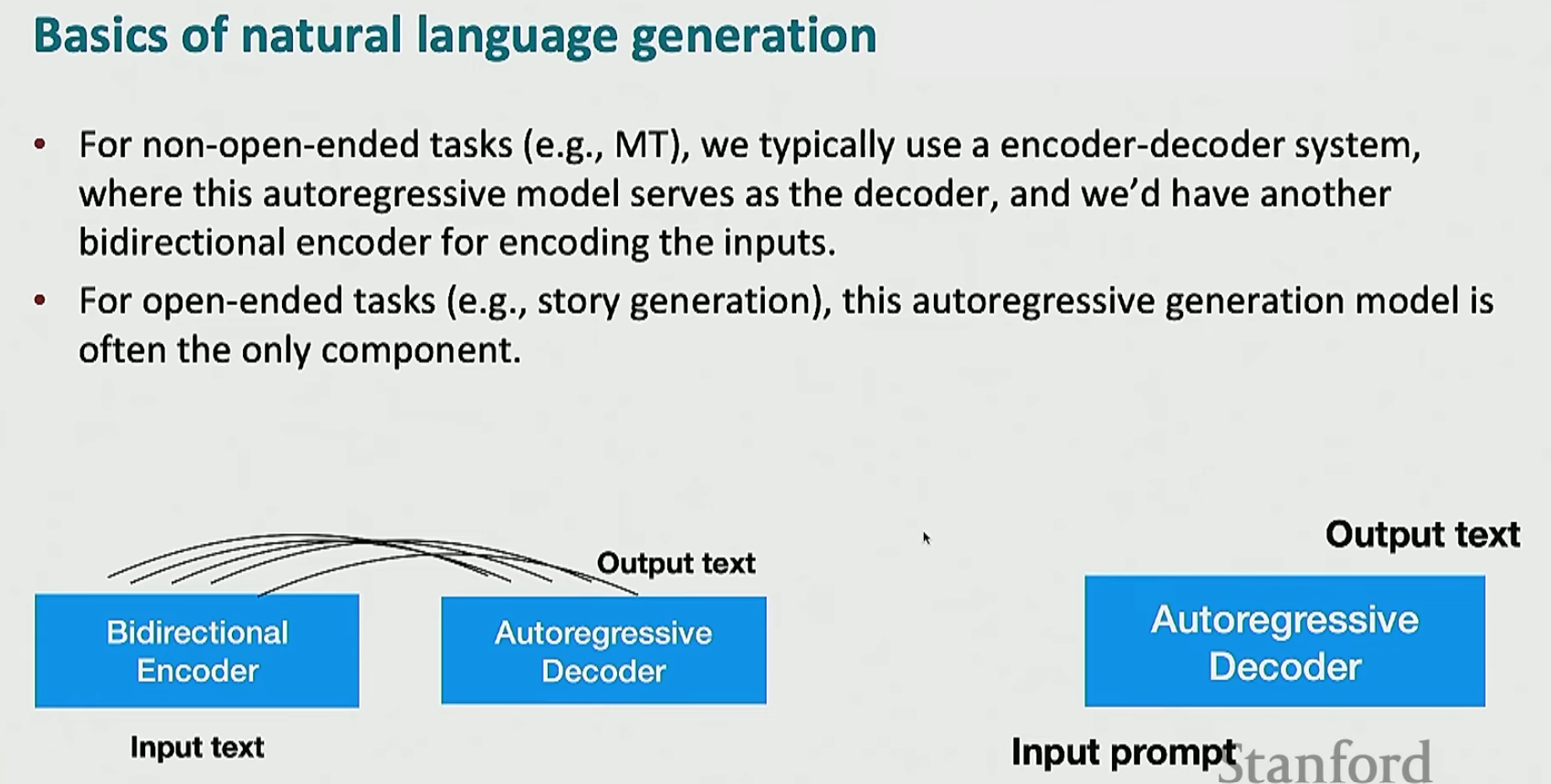
注意,不是说机器翻译就一定要用编码器-解码器,也不是说故事生成就一定要用解码器,上面只是一个惯例。只不过大家这么做是有原因的:机器翻译中如果仅仅使用解码器,那么会损害性能;故事生成中如果使用编码器-解码器,确实可以达到更好的效果,但是没有好到哪里去,我们却需要更多的成本去进行训练,这是不划算的

对于语言模型,书上讲了两种方法进行下一个词的预测,一种是贪心选择概率最大的,另一种是使用束搜索。这两种方式在处理不开放任务的时候效果还不错,但是在处理开放任务的时候效果就不好了,特别是容易重复生成相同的词,如下

这是因为这两种算法都认为重复是一个概率非常大的事情,如下
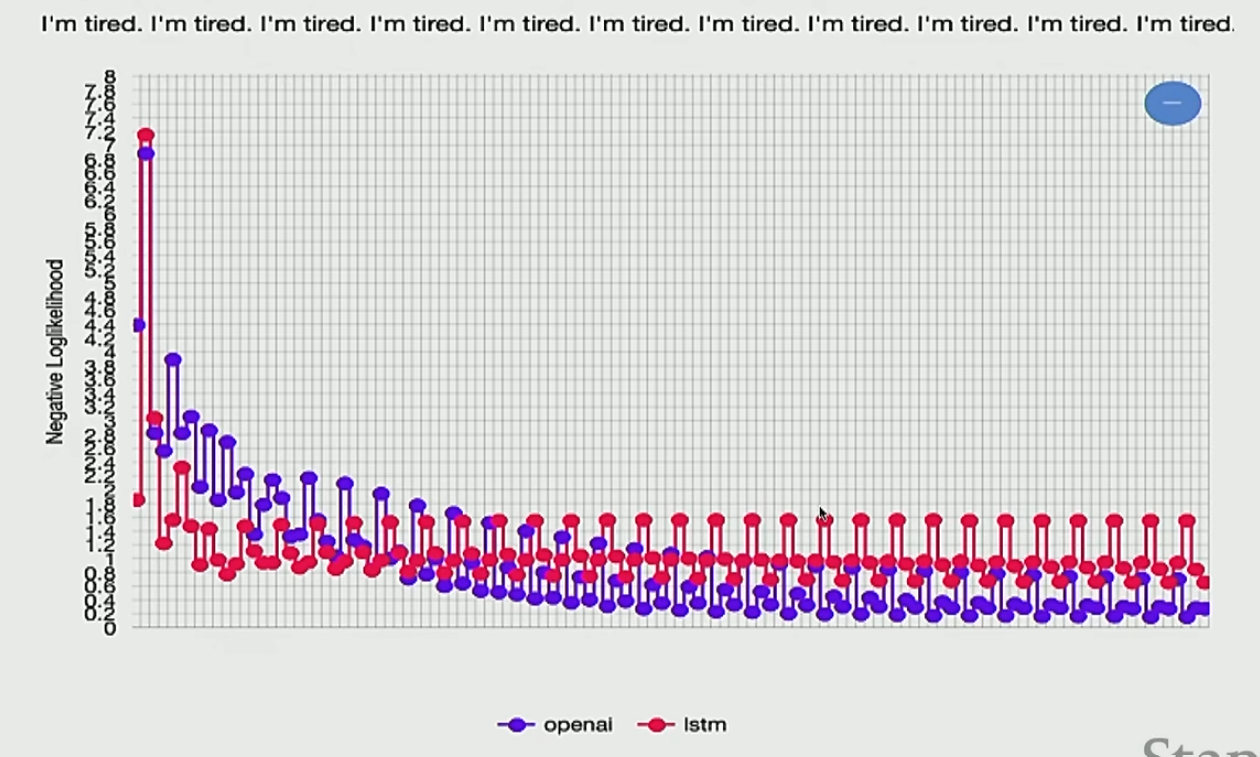
这种问题即使是对参数非常非常多的模型也是存在的
那么解决这个问题的方法如下
- n-gram blocking
简单来说,就是在生成过程中,如果当前生成的 n-gram 已经出现在之前的文本中,则阻止该 n-gram 再次生成。以3-gram为例,如果模型之前已经生成了I am happy,那么如果现在模型又预测了I am,下一个词模型就会直接把happy的概率变成\(0\).但是这个方法显然不是很好 - 使用不同的训练目标
普通的语言模型以交叉熵为损失函数(最大似然估计),我们可以更换如下的其他训练目标- 采用非似然方法
在这种方法中,模型会因为生成已经生成了的东西而受到惩罚。这就有点像将n-gram blocking放入训练中(而不是在预测中使用) - 使用注意力机制
我们使用注意力强制让模型关注没有生成的单词
- 采用非似然方法
- 使用不同的解码目标
不像之前那样选择概率最大的字符串,而是同时用两个语言模型,然后选择让这两个语言模型的概率差值最大的字符串。这样两个语言模型对重复词组预测的概率都很大的话,就可以互相抵消了
其实从下图可以看出,我们找概率最大的字符串可能根本就不符合人类的思维。人类的思维的不确定性是非常大的
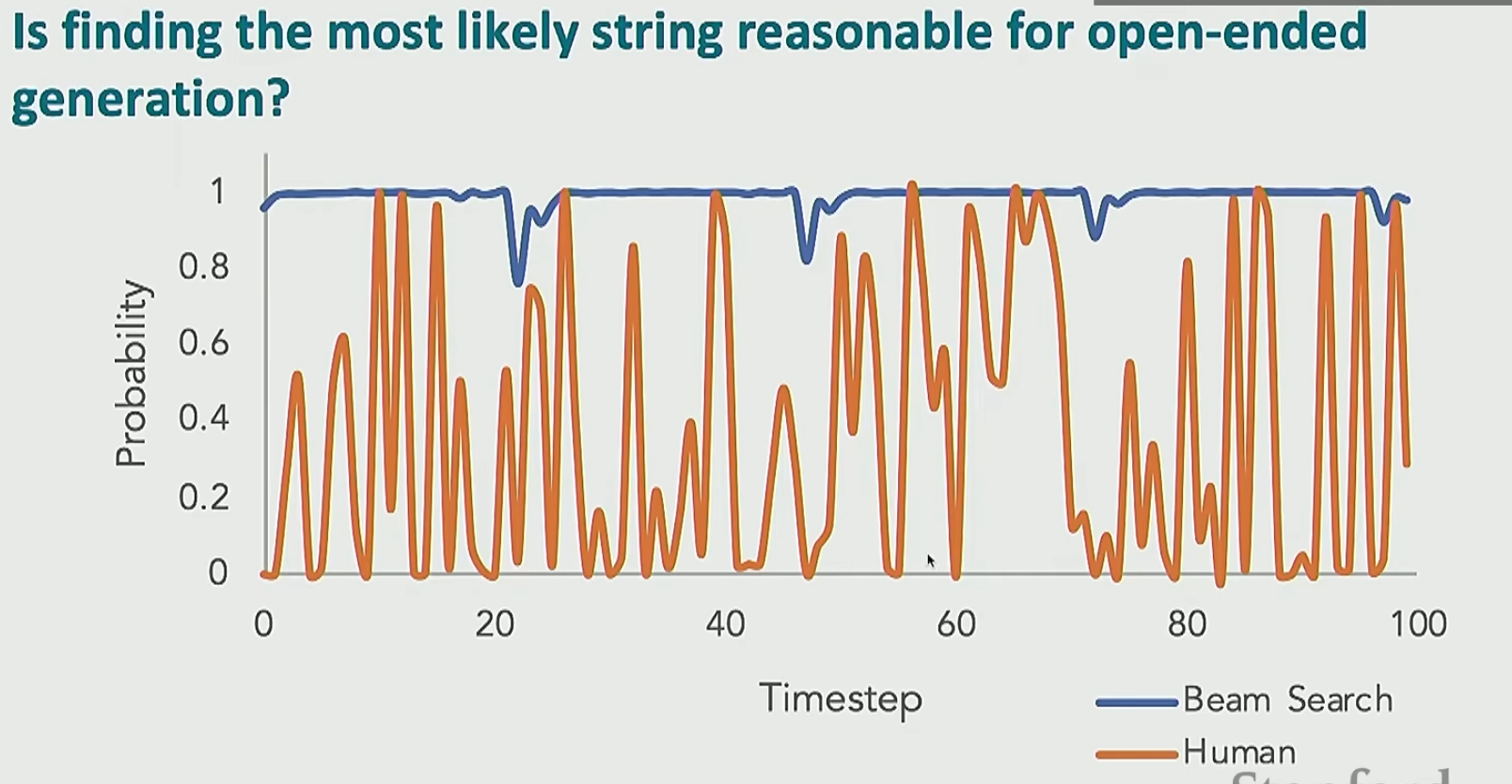
那么我们怎么样才能去模拟这个人类的思维呢?可以采用采样。也就是说我们算出了下一个词的分布,我们不是去选择概率最大的词也不是去进行束搜索,而是在这个分布里面进行随机采样。但是我们不能直接进行随机采样,因为我们的词表太大了,虽然有非常多的词的概率都很小,但是我们将这些概率小的词的概率全部加起来就很大了。解决这个问题的方法就是在概率最高的\(k\)个词里面进行随机采样。但这个解决方法仍然是有问题的
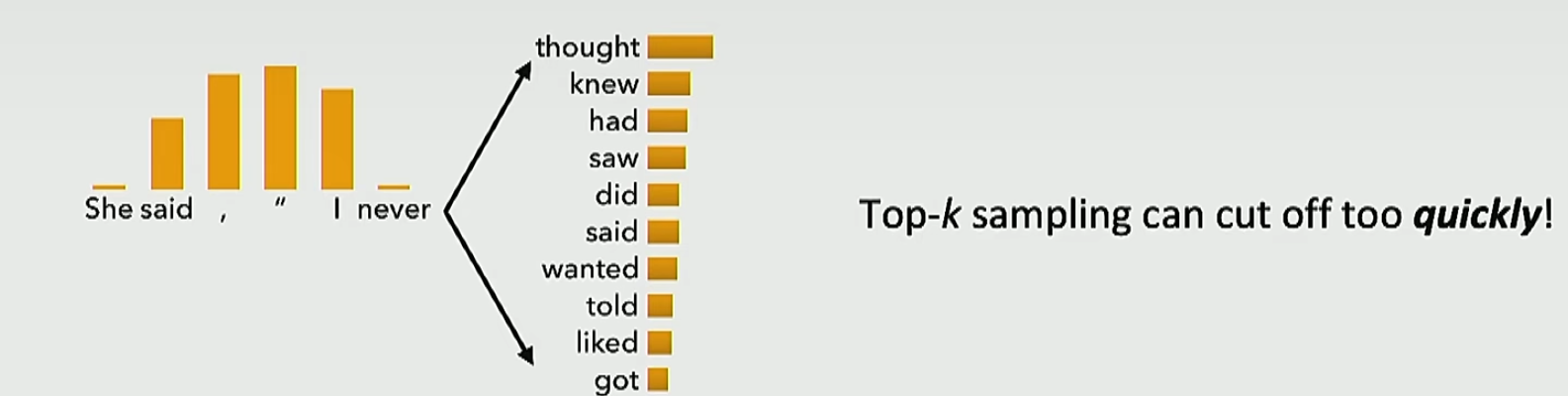
下一个词可能有很多很多种选择,比如eat等等,但是全给丢了
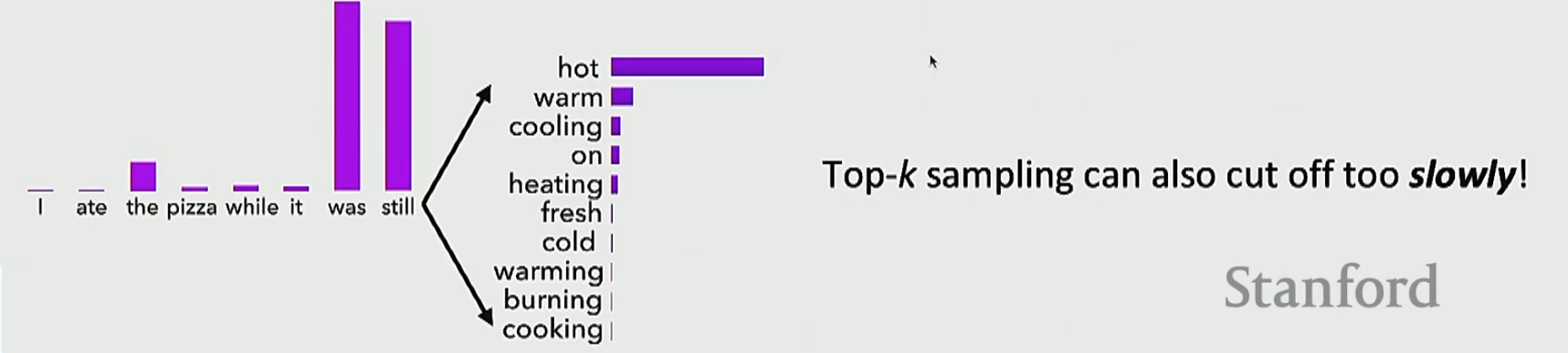
根据常识,不可能选择cold,但是却没有丢
我们分析一下这个现象出现的原因

于是我们借鉴动态学习率的思想,采用动态\(k\)


注意,无论是静态\(k\)还是动态\(k\),他的目的都是提高模型表现,而不是节省计算(实际上,为了获得概率分布,我们还是会遍历整个词表一遍的)
如果我们非要使用静态\(k\),我们也可以引入温度参数

但是,现在还是存在一个问题,无论我们做什么样的努力,我们的分布总是可能保存了一个看起来不太好的词(就算这个词的概率很低),然后在某一次生成中我们就把这个词给抽中了。解决这个问题的办法是我们一次性生成多个句子(句子的个数也是超参数,我们要在性能和效率之间做平衡),然后定义一个排序的方法,将得分最高的句子作为输出

上面问题为什么会出现呢?也就是说,为什么我们会一直输出重复的东西呢?实际上没有人知道,但是我们可以从累积误差的角度去理解。由于我们训练的时候使用的是强制教学,但是在预测的时候我们的文本生成是自回归的,这就可能导致误差累积。这个误差是怎么累积出来的呢?原因是我们使用了极大似然估计。注意我们在统计学习中的极大似然估计,每一个样本都是从真实的世界中进行采样得到的,所以极大似然估计的效果很好;但是在预测的过程中(训练由于使用的是强制学习所以还好),我们前面已经生成了的文本是自己的预测,而不是从真实的世界里面得到的,我们基于自己生成的东西进行极大似然估计,这个基础就错了,所以误差就累积起来了,这种现象叫做exposure bias
那么怎么解决呢?
- Scheduled Sampling(计划采样)
在训练过程中,逐步增加模型自己的预测结果作为输入的比例 ,减少对真实标签的依赖,从而让模型适应推理时的输入(即自己的预测结果)。但是训练的目标相当奇怪,会导致不稳定- 训练时 :模型在每一步以一定概率选择使用真实标签或自己的预测作为输入
- 概率调整 :初始阶段以较高概率使用真实标签,随着训练进行,逐渐增加使用模型预测的比例
- Dataset Aggregation(数据集聚合)
通过迭代训练 ,将模型生成的错误数据(推理时的输出)加入训练集,让模型在后续训练中修正这些错误,从而缩小训练与推理的差异。步骤如下- 初始模型用原始数据训练
- 用模型生成新数据(可能包含错误)
- 将生成的数据与原始数据混合,重新训练模型
- 重复迭代,直到模型收敛
- Retrieval Augmentation(检索增强)
模型在生成过程中,同时利用检索到的真实数据片段 (如文档、历史对话、标注数据等)作为输入或参考,减少对自身预测的完全依赖,让输入更像从真实世界中获取的。利用的方法就是添加/删除/修改自己预测的句子等 - Reinforcement Learning(强化学习)
视频00:44:55有讲,一直到00:55:08
接下来我们来讲一下如何评估自然语言生成系统。首先以非开放性任务为例
- 内容重叠度量
- 这个就是计算模型生成的文本与标准文本的重叠度。重叠度衡量的方法有一个很重要的就是n-gram重叠。这个方法比如BLEU(机器翻译)和ROUGE(摘要)
- 这个方法的优点是简单高效,运用非常广泛
- 这个方法的缺点也很明显,仅仅依赖与重叠的话,可能会错过相同语义不同词的情况,或者奖励词汇重叠很大但是实际意思相反的句子,如下
![image]()
- 基于模型的度量
- 这个方法使用模型生成的词向量,通过衡量词向量之间的相似性来得到语义的相似性
- 衡量词向量相似性的方法
- 余弦相似度。具体公式就不说了。但是以前都是衡量单词之间的相似性,如何衡量句子之间的相似性呢?一个比较简单的方法就是将句子的每个单词的词向量进行平均得到句子的词向量
- 词移距离。这个就是用来测量句子之间的相似性的比较高级的方法了。具体来说,首先将两个句子对应的词对齐(这个会使用特殊的算法),然后计算每个对齐的词之间的距离,最后加起来
- BERT分数。就是余弦相似度用来计算的词向量来自BERT
- 句移相似度。跟词移距离差不多,但是是直接计算句子的嵌入向量
- BLEURT.即基于BERT训练一个回归模型来评估效果

然后我们来看一下开放性任务评估的方法,假设下面的任务都基于故事生成
- MAUVE.首先我们有一个参考的文本,然后模型生成了一个文本,我们将这两个文本嵌入到嵌入空间里面;对嵌入空间使用k均值聚类将其划分为离散空间(视频01:03:25阐述了为什么要离散化,但是涉及很高深的数学知识;后面那一堆问题都可以听一下);此时可以对这两个文本生成直方图,然后通过前向KL计算精确度和后向KL计算召回率
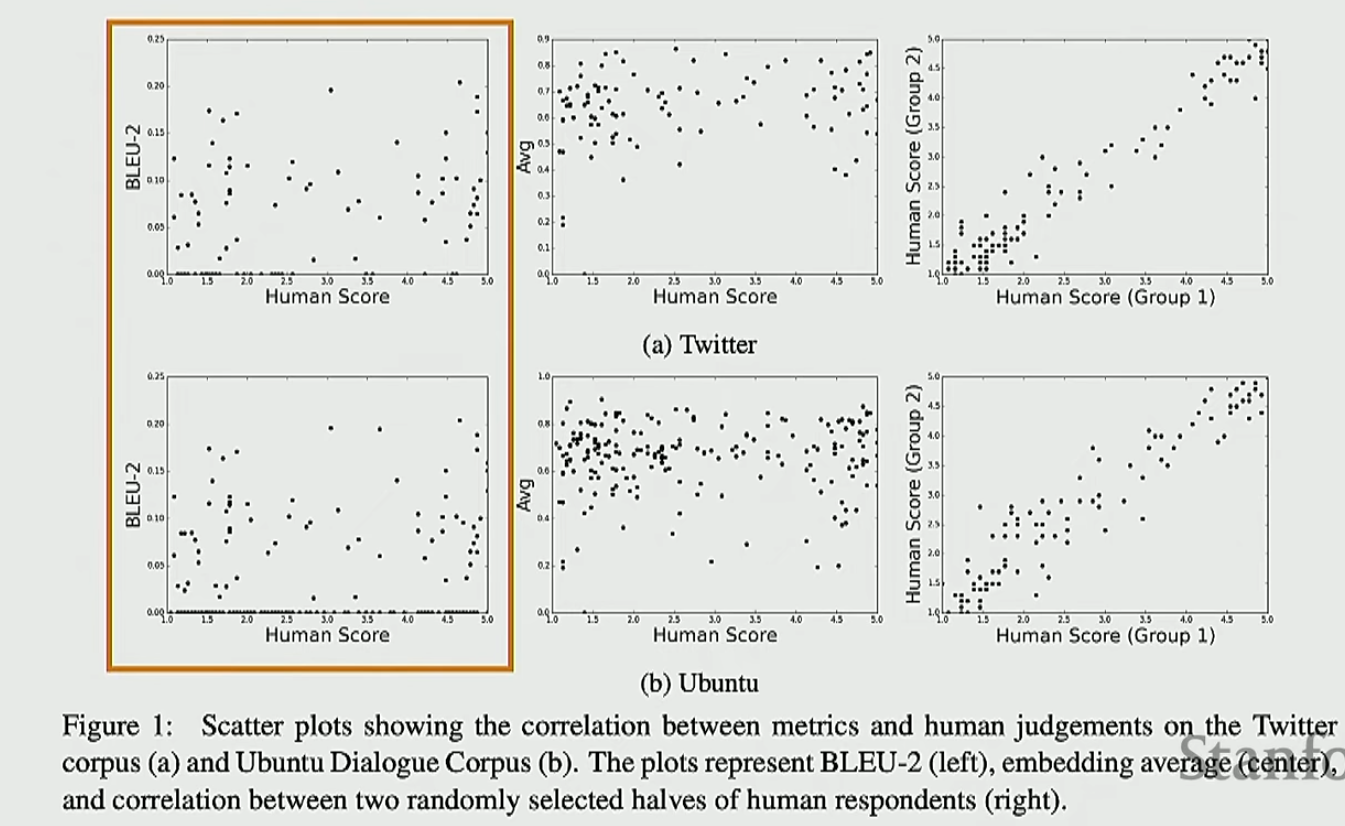
那么我们到底选择哪一个评估指标呢?一个黄金标准还是与人类判断契合的指标。下面展示一下BLEU和人类评估的对比,由于没有看到很强的相关性,可以知道BLEU不是一个非常好的评价指标
那么人类指标是怎么形成的呢?如下,我们会从多个方面让人类进行打分

但是人类指标是有缺点的,除了老生常谈的慢和贵,还有如下的缺点

于是就有一些解决办法,如下
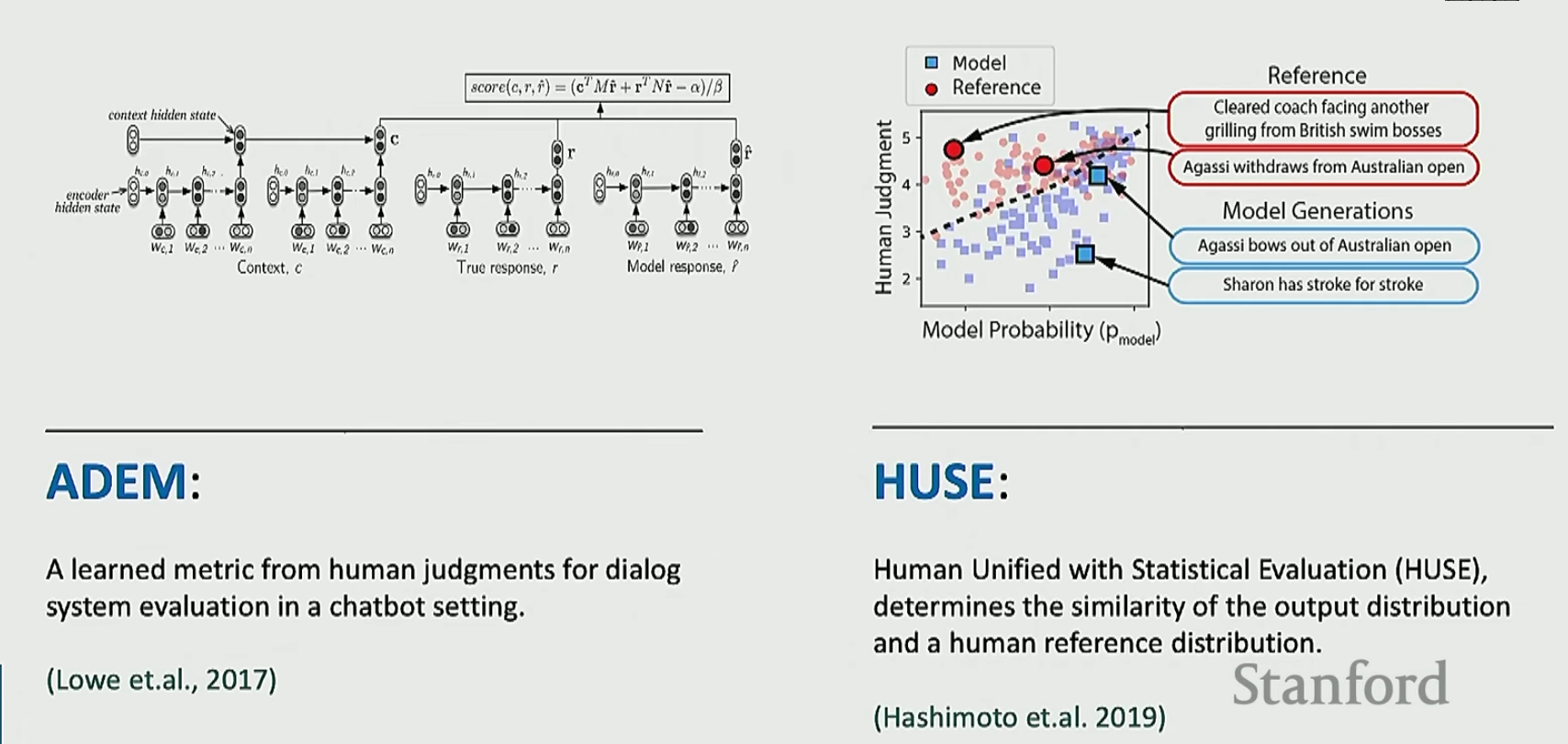
第一个就是训练一个与人类评估很像的模型,第二个就是让人类与模型合作,人类评估精确性,模型评估召回率(自然语言生成系统能生成的所有符合条件的文本站所有符合条件的文本的比例)
还有如下的交互式评估方法

最后来讨论一下伦理问题。模型在利用互联网的文本进行训练的时候,不可避免地会遇到一些伦理问题,我们就需要想办法解决,如下
- 人工数据清理。耗时麻烦,不可能
然后视频就没讲什么其他方法了,就是说你要做好检查

 浙公网安备 33010602011771号
浙公网安备 33010602011771号