

第九课 预训练
对于像BERT这种现代NLP编码器,有以下的优点

解释一下第二条:我们微调也是需要调整BERT的(不只是调整添加的全连接层),所以我们已经预训练好了的BERT的参数就是初始参数,这个参数比我们随机的参数更好训练;解释一下第三个:就是我们可以通过现代NLP预训练模型(BERT需要额外微调才能生成文本,但是GPT就是专门做这个的)生成一些很好的像人搞出来的句子,然后这些句子就可以作为我们的训练集
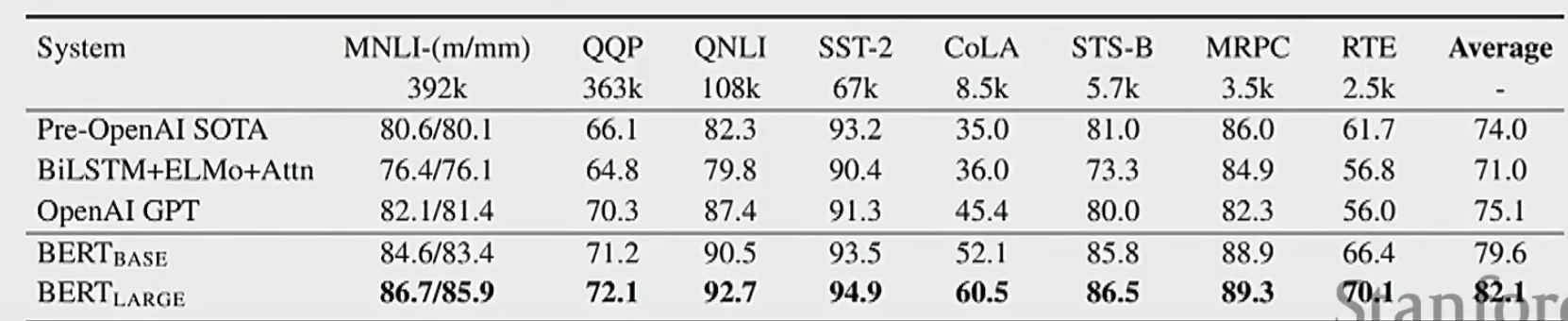
可以感受一下BERT的效果,如下
一些不同的调参方式

轻量微调与普通微调相比,就是我们不在调整BERT的所有参数,而是只调整BERT的一小部分,保持剩下的参数不变(这样子的好处就是可以保持BERT的通用性)
一些轻量微调的方式
- 前缀调参
前缀调参是一种参数高效调参(Parameter-Efficient Tuning) 方法,其核心思想是:在输入文本的前面添加一个可学习的参数前缀 ,而冻结预训练模型的所有参数 。这个前缀会被模型视为“虚拟的输入词”,与真实输入一起处理,从而在不改变主模型参数的情况下,让模型适应不同的任务或上下文。前缀通常是一个可学习的向量矩阵,形状为[prefix_length × hidden_size]。可以通过线性变换或位置编码进一步增强其表达能力。 - 低秩调参
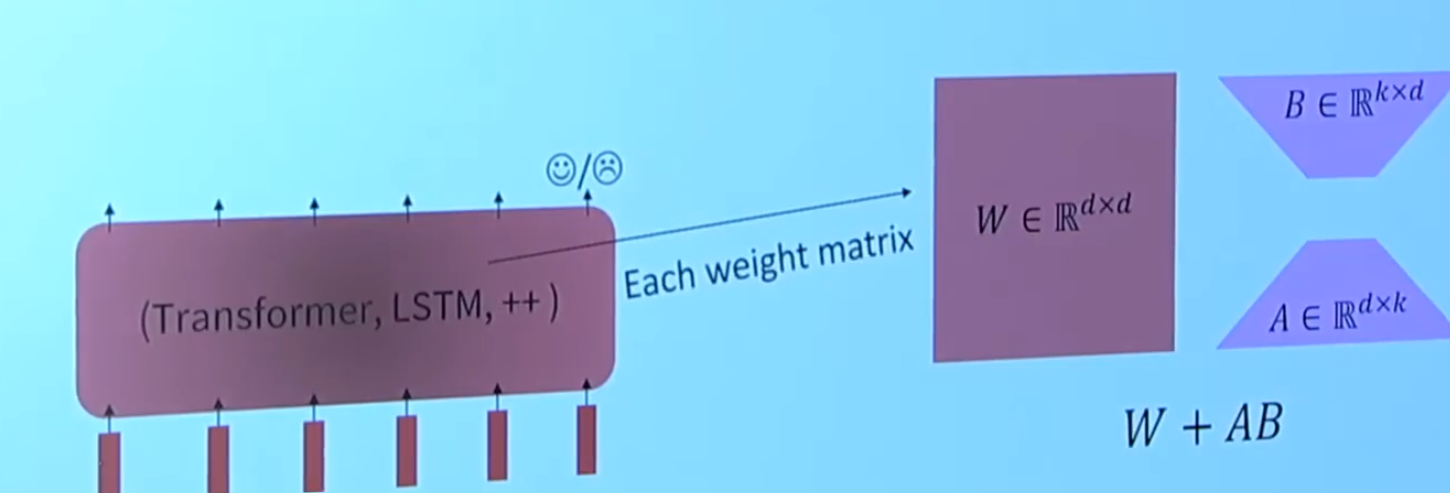
就是将Transformers里面的权重矩阵冻结,然后每个矩阵加上一个可以调整的低秩权重矩阵,如下
![image]()
在训练解码器与编码器的过程中,核心差异和输入处理方式如下:
1. 解码器与编码器的训练差异
-
解码器的核心任务:
解码器通常用于生成序列(如文本生成、翻译、摘要),其训练目标是学习自回归预测(即基于已生成的部分序列 \(w_{1:t-1}\) 预测下一个词 \(w_t\))。
示例模型:GPT、自回归语言模型。 -
编码器的核心任务:
编码器专注于理解输入序列并生成上下文表征(如BERT),通过双向上下文建模(如掩蔽语言模型)捕捉全局语义。关键区别:
- 解码器需要自回归生成(逐词预测,依赖历史输出),而编码器更强调双向上下文建模。
- 解码器通常以单向注意力(仅关注左侧上下文)为主,编码器则使用双向注意力。
2. 解码器的输入类型
解码器的输入是否经过编码,取决于模型架构:
-
纯解码器架构(如GPT):
- 输入为原始序列,无需编码器。
- 解码器直接处理原始输入(如对话历史、文档),通过自回归生成后续内容。
- 示例公式:\[h_t = \text{Decoder}(w_{1:t-1}), \quad w_t \sim Ah_{t-1} + b \]其中 \(A, b\) 是预训练好的线性层,用于生成词表分布。
-
编码器-解码器架构(如T5、BART):
- 输入为编码器的输出(即输入序列的上下文表示)。
- 解码器基于编码后的表示生成目标序列(如翻译结果)。
3. 预训练目标的适配性
- 解码器预训练:
通常以语言建模(预测下一个词)为目标,直接训练生成能力。适合任务如对话、文本续写。 - 编码器预训练:
常采用掩蔽语言模型(MLM)或Span Corruption,强调双向理解。适合任务如分类、问答。
总结
- 纯解码器模型(如GPT):输入是原始序列,直接生成输出。
- 编码器-解码器模型(如T5):解码器输入为编码后的表示,结合生成任务需求。
- 本质区别:解码器聚焦生成(自回归),编码器聚焦理解(双向建模)。两者输入是否经过编码,取决于架构设计。
GPT-3就有一个很厉害的特性,就是人类可以不明确任务,只是给出一些上下文,模型自己就会知道干什么,如下

有了前面三个例子,模型就知道我们是让他翻译
我们可以在下游任务微调的时候,加入思维链。原来的下游任务,我们输入一个问题,直接给出答案,而现在我们不仅给出答案,还要给出人类思考的过程,这个样子训练效果更好,如下


 浙公网安备 33010602011771号
浙公网安备 33010602011771号