7.2.1 VGG块
\(\text{AlexNet}\)最大的问题就是加的层很随意,这里加一点那里加一点,结构就不清晰,也就是说我们还不能够很好的回答“如何更深更大”这一个问题
考虑一下这个问题如何回答。想一下我们可能的选项如下

于是VGG就采用了最后一个选项

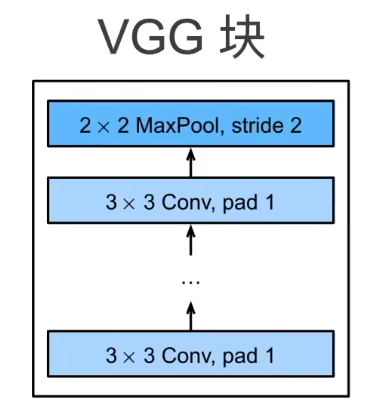
那么为什么不用\(5\times 5\)的卷积层呢?实际上试过的,在计算量相同的情况下,由于\(5\times 5\)的卷积层更大,所以能够叠加的深度就更少,学出来的效果就没有\(3\times 3\)的好(也就是深但是窄的效果会更好)。所以超参数就是\(n\)和\(m\)
最后全连接层那个地方,VGG跟\(\text{AlexNet}\)一样。简单来说,VGG就是更大更深的\(\text{AlexNet}\)
可以看下各种网络的对比,如下
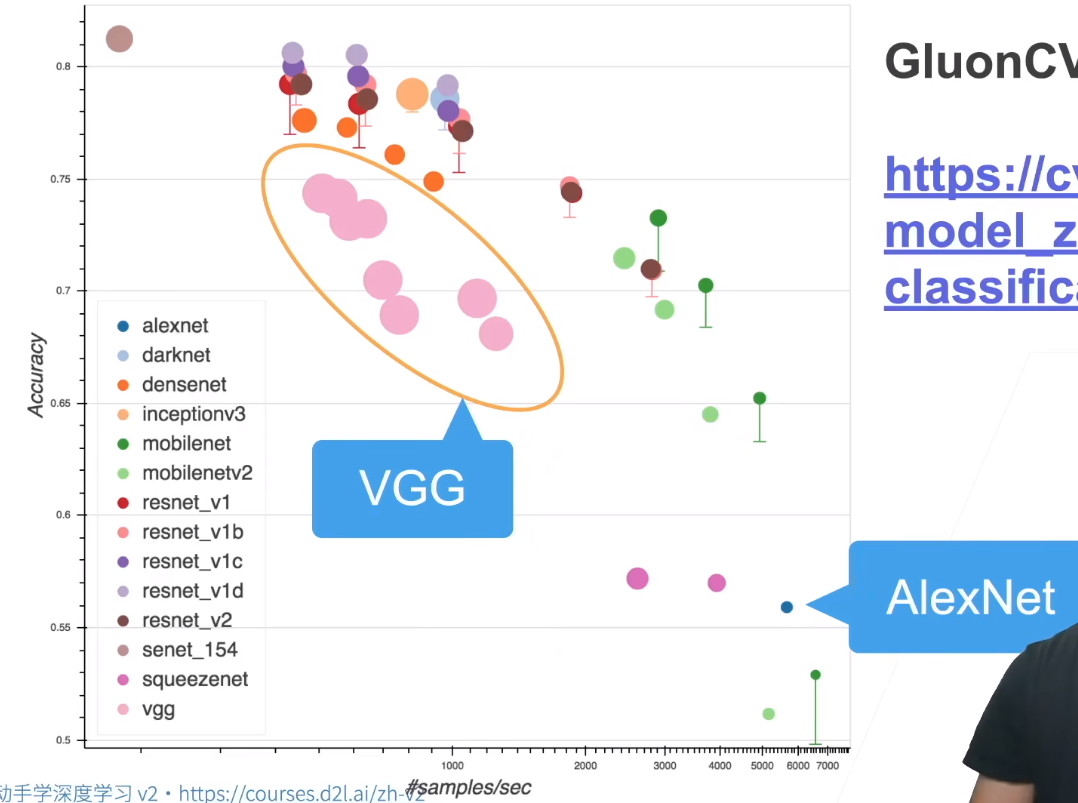
横轴是计算速度,纵轴是准确率。可以看到,同一个网络架构(比如都是VGG)有不同的表现,跑得快的准确率低,跑得慢的准确率高(不同的卷积块个数和超参数可以得到不同复杂度的变种)
在vgg_block函数中,不需要更新out_channels,原因如下:
1. VGG块的设计原则
VGG的核心思想是:在同一块内,所有卷积层的输出通道数保持一致。例如:
- 若定义
vgg_block(num_convs=2, in_channels=3, out_channels=64),块内会连续堆叠两个3×3卷积层,每个卷积层的输出通道均为64。 - 第一个卷积层将输入通道从3变为64,第二个卷积层保持输入和输出通道均为64(通过更新
in_channels = out_channels实现)。
这种设计让块内的所有卷积层共享相同的通道数,简化参数管理,同时通过堆叠多个小卷积核(3×3)来模拟更大感受野(等效于5×5或7×7)。
2. 代码逻辑分析
for _ in range(num_convs):
# 添加卷积层:输入通道为当前in_channels,输出通道固定为out_channels
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
layers.append(nn.ReLU())
# 更新输入通道为当前块的输出通道(保证下一层的输入与当前输出一致)
in_channels = out_channels
- 不更新
out_channels:因为块内所有卷积层的目标是保持输出通道数一致(由out_channels参数指定),只有输入通道数(in_channels)需要逐层更新。 - 最终效果:无论
num_convs是多少,块的输出通道数始终为初始的out_channels值。例如,num_convs=3时,块的输出通道数仍为初始设定的值(如64)。
3. 对比其他网络结构
- AlexNet/ResNet:不同阶段的块会逐步增加通道数(如64→128→256),但这是在跨块时通过手动调整
out_channels实现的。 - VGG:通过固定块内通道数,仅在跨块时通过池化层后手动调整通道数(例如,下一个块的
in_channels设为当前块的out_channels,out_channels设为更大的值)。
示例说明
假设定义两个连续的VGG块:
block1 = vgg_block(num_convs=2, in_channels=3, out_channels=64) # 输出通道64
block2 = vgg_block(num_convs=2, in_channels=64, out_channels=128) # 输出通道128
- 块内:每个块内部的卷积层输出通道数固定(如第一个块固定为64)。
- 跨块:通过手动指定下一个块的
in_channels和out_channels来增加通道数(如64→128),这是VGG的分阶段特征提取策略。
总结
不更新out_channels是因为VGG块的设计要求同一块内的所有卷积层保持相同的输出通道数,而通道数的增加是通过跨块时手动调整参数实现的。这种设计保证了块内结构的简洁性和一致性,符合VGG“通过堆叠相同配置的块构建深度网络”的核心思想。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号