再谈 RocketMQ broker busy(实战篇)
本文将在 RocketMQ 消息发送system busy、broker busy原因分析与解决方案 的基础上,结合生产上的日志尝试再次理解 broker busy 以及探讨解决方案。
首先,broker busy 相关的日志关键字如下:
- [REJECTREQUEST]system busy
- too many requests and system thread pool busy
- [PC_SYNCHRONIZED]broker busy
- [PCBUSY_CLEAN_QUEUE]broker busy
- [TIMEOUT_CLEAN_QUEUE]broker busy
上述前面4个关键字在上篇文章中已详细介绍,本文先对出现上述错误进行一个总结,具体的分析过程请查阅上篇文章。
本文先给出一张流程图,展示上述5种 broker busy 分别会在消息发送的哪个阶段抛出,以便大家能够清晰的了解其发生的原因。
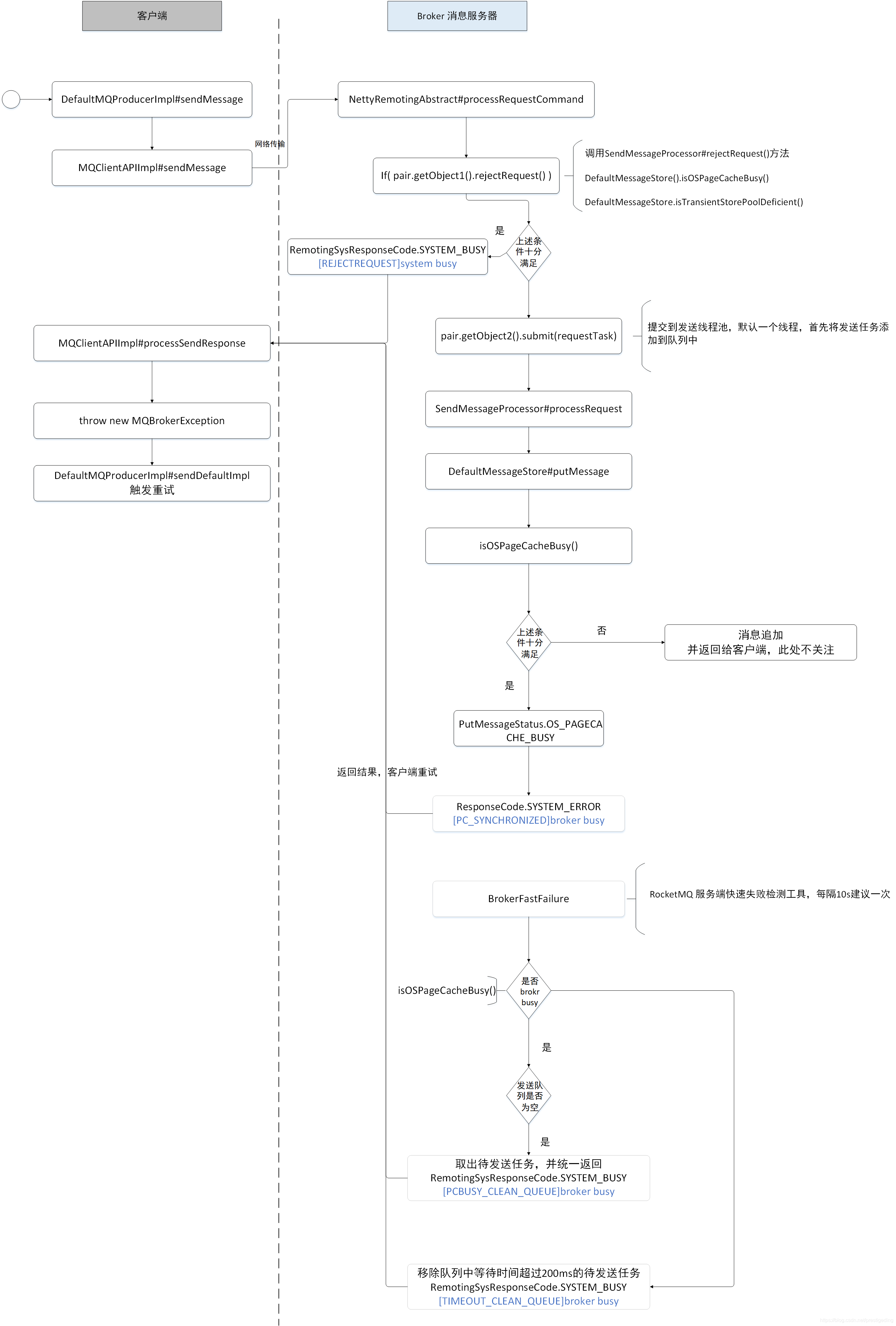
针对前4种 broker busy 出现的问题已经在上篇文章中详细介绍,主要是由于 Broker 在追加消息时持有的锁时间超过了设置的1s,Broker 为了自我保护,会抛出错误,客户端会选择其他 broker 服务器进行重试。如果对不是金融级服务,建议将 transientStorePoolEnable = true,可以有效避免前面 4 种 broker ,因为开启这个参数,消息首先会存储在堆外内存中,并且 RocketMQ 提供了内存锁定的功能,其追加性能能得到一定的保障,这样可以做到在内存使用层面的读写分离,即写消息是直接写入堆外内存,消费消息直接从 pagecache中读,然后定时将堆外内存的消息写入 pagecache。但这种方案随之带来的就是可能存在消息丢失,如果对消息非常严谨的话,建议扩容集群,或迁移topic到新的集群。
同时在做 Broker 服务器巡检的时候,可以通过去通过如下命令去查看 broker 一次消息追加是否会超过 500 ms。

在这个图中我们看到在设置了 transientStorePoolEnable 为 true 的情况下,虽然一天只有一条超过500ms的消息,但也值得警惕了,由于对系统内核参数掌握程度不够,这种情况,估计只能走集群扩容的路子了。但如果一天消息量巨大而且出现频率不高的情况,由于有重试机制,倒不会带来太大的问题。如果出现太多的错误,建议集群扩容。
本文接下来想重点探讨一下 [TIMEOUT_CLEAN_QUEUE]broker busy 这种情况。
BrokerFastFailure#cleanExpiredRequest
while (true) {
try {
if (!this.brokerController.getSendThreadPoolQueue().isEmpty()) {
final Runnable runnable = this.brokerController.getSendThreadPoolQueue().peek();
if (null == runnable) {
break;
}
final RequestTask rt = castRunnable(runnable);
if (rt == null || rt.isStopRun()) {
break;
}
final long behind = System.currentTimeMillis() - rt.getCreateTimestamp();
if (behind >= this.brokerController.getBrokerConfig().getWaitTimeMillsInSendQueue()) {
if (this.brokerController.getSendThreadPoolQueue().remove(runnable)) {
rt.setStopRun(true);
rt.returnResponse(RemotingSysResponseCode.SYSTEM_BUSY, String.format("[TIMEOUT_CLEAN_QUEUE]broker busy, start flow control for a while, period in queue: %sms, size of queue: %d", behind, this.brokerController.getSendThreadPoolQueue().size()));
}
} else {
break;
}
} else {
break;
}
} catch (Throwable ignored) {
}
}
可以看出来,抛出这种错误,在 broker 还没有发送“严重”的 pagecache 繁忙,即消息追加到内存中的最大时延没有超过 1s,通常追加是很快的,绝大部分都会低于1ms,但可能会由于出现一个超过200ms的追加时间,导致排队中的任务等待时间超过了200ms,则此时会触发broker 端的快速失败,让请求快速失败,便于客户端快速重试。但是这种请求并不是实时的,而是每隔10s 检查一遍。
值得注意的是,一旦出现 TIMEOUT_CLEAN_QUEUE,可能在一个点会有多个这样的错误信息,具体多少与当前积压在待发送队列中的个数有关。
关于 [TIMEOUT_CLEAN_QUEUE]broker busy 我们也可以适当调整 waitTimeMillsInSendQueue,默认值为200ms,可以适当调整到400ms。
如果大家觉得文章对您有帮助的话,麻烦帮忙点个赞,谢谢。
作者介绍:
丁威,《RocketMQ技术内幕》作者,RocketMQ 社区布道师,公众号:中间件兴趣圈 维护者,目前已陆续发表源码分析Java集合、Java 并发包(JUC)、Netty、Mycat、Dubbo、RocketMQ、Mybatis等源码专栏。欢迎加入我的知识星球,构建一个高质量的技术交流社群。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号