

sql语句优化
https://mp.weixin.qq.com/s/WsQZhZhuzfs2YZgamrGUOw
怎么建索引
阿里巴巴的开发者手册建议,单表索引数量控制在5个以内,组合索引字段数不允许超过5个
其他建议:
- 禁止给表中的每一列都建立单独的索引
- 每个Innodb表必须有个主键
- 要注意组合索引的字段的顺序
- 优先考虑覆盖索引
- 避免使用外键约束
避免索引失效
减少回表
覆盖索引
分批处理
大量数据的update和delete操作可采取分批处理。
业务描述:更新用户所有已过期的优惠券为不可用状态。
SQL语句:
update status=0 FROM `coupon` WHERE expire_date <= #{currentDate} and status=1;
如果大量优惠券需要更新为不可用状态,执行这条SQL可能会堵死其他SQL,分批处理伪代码如下:
int pageNo = 1; int PAGE_SIZE = 100; while(true) { List batchIdList = queryList('select id FROM `coupon` WHERE expire_date <= #{currentDate} and status = 1 limit #{(pageNo-1) * PAGE_SIZE},#{PAGE_SIZE}'); if (CollectionUtils.isEmpty(batchIdList)) { return; } update('update status = 0 FROM `coupon` where status = 1 and id in #{batchIdList}') pageNo ++; }
Like优化
like用于模糊查询,举个例子(field已建立索引):
SELECT column FROM table WHERE field like '%keyword%';
这个查询未命中索引,换成下面的写法:
SELECT column FROM table WHERE field like 'keyword%';
去除了前面的%查询将会命中索引,但是产品经理一定要前后模糊匹配呢?全文索引fulltext可以尝试一下,但Elasticsearch才是终极武器。
Limit优化
limit用于分页查询时越往后翻性能越差,解决的原则:缩小扫描范围,如下所示:
select * from orders order by id desc limit 100000,10
耗时0.4秒
select * from orders order by id desc limit 1000000,10
耗时5.2秒
先筛选出ID缩小查询范围,写法如下:
select * from orders where id > (select id from orders order by id desc limit 1000000, 1) order by id desc limit 0,10
耗时0.5秒
如果查询条件仅有主键ID,写法如下:
select id from orders where id between 1000000 and 1000010 order by id desc
耗时0.3秒
如果以上方案依然很慢呢?只好用游标了,感兴趣的朋友阅读JDBC使用游标实现分页查询的方法。
分页查询优化
join 语句
mysql的表关联常见有两种算法
1、 嵌套循环连接 Nested-Loop Join(NLJ) 算法
一次一行循环地从第一张表(称为驱动表)中读取行,在这行数据中取到关联字段,根据关联字段在另一张表(被驱动
表)里取出满足条件的行,然后取出两张表的结果合集。
‐‐ 往t1表插入1万行记录
‐‐ 往t2表插入100行记录
‐‐ 示例表: 2 CREATE TABLE `t1` ( 3 `id` int(11) NOT NULL AUTO_INCREMENT, 4 `a` int(11) DEFAULT NULL, 5 `b` int(11) DEFAULT NULL, 6 PRIMARY KEY (`id`), 7 KEY `idx_a` (`a`) 8 ) ENGINE=InnoDB DEFAULT CHARSET=utf8; 9 1 0 create table t2 like t1;

驱动表是 t2,被驱动表是 t1。先执行的就是驱动表(执行计划结果的id如果一样则按从上到下顺序执行sql);优
化器一般会优先选择小表做驱动表。所以使用 inner join 时,排在前面的表并不一定就是驱动表。
当使用left join时,左表是驱动表,右表是被驱动表,当使用right join时,右表时驱动表,左表是被驱动表,
当使用join时,mysql会选择数据量比较小的表作为驱动表,大表作为被驱动表。
使用了 NLJ算法。一般 join 语句中,如果执行计划 Extra 中未出现 Using join buffer 则表示使用的 join 算
法是 NLJ。
上面sql的大致流程如下:
1. 从表 t2 中读取一行数据(如果t2表有查询过滤条件的,会从过滤结果里取出一行数据);
2. 从第 1 步的数据中,取出关联字段 a,到表 t1 中查找;
3. 取出表 t1 中满足条件的行,跟 t2 中获取到的结果合并,作为结果返回给客户端;
4. 重复上面 3 步。
整个过程会读取 t2 表的所有数据(扫描100行),然后遍历这每行数据中字段 a 的值,根据 t2 表中 a 的值索引扫描 t1 表
中的对应行(扫描100次 t1 表的索引,1次扫描可以认为最终只扫描 t1 表一行完整数据,也就是总共 t1 表也扫描了100
行)。因此整个过程扫描了 200 行。
如果被驱动表的关联字段没索引,使用NLJ算法性能会比较低(下面有详细解释),mysql会选择Block Nested-Loop Join
算法。
2 基于块的嵌套循环连接 Block Nested-Loop Join(BNL)算法
把驱动表的数据读入到 join_buffer 中,然后扫描被驱动表,把被驱动表每一行取出来跟 join_buffer 中的数据做对比

Extra 中 的Using join buffer (Block Nested Loop)说明该关联查询使用的是 BNL 算法。
上面sql的大致流程如下:
1. 把 t2 的所有数据放入到 join_buffer 中
2. 把表 t1 中每一行取出来,跟 join_buffer 中的数据做对比
3. 返回满足 join 条件的数据
整个过程对表 t1 和 t2 都做了一次全表扫描,因此扫描的总行数为10000(表 t1 的数据总量) + 100(表 t2 的数据总量) =
10100。并且 join_buffer 里的数据是无序的,因此对表 t1 中的每一行,都要做 100 次判断,所以内存中的判断次数是
100 * 10000= 100 万次。
这个例子里表 t2 才 100 行,要是表 t2 是一个大表,join_buffer 放不下怎么办呢?
join_buffer 的大小是由参数 join_buffer_size 设定的,默认值是 256k。如果放不下表 t2 的所有数据话,策略很简单,
就是分段放。
比如 t2 表有1000行记录, join_buffer 一次只能放800行数据,那么执行过程就是先往 join_buffer 里放800行记录,然
后从 t1 表里取数据跟 join_buffer 中数据对比得到部分结果,然后清空 join_buffer ,再放入 t2 表剩余200行记录,再
次从 t1 表里取数据跟 join_buffer 中数据对比。所以就多扫了一次 t1 表。
被驱动表的关联字段没索引为什么要选择使用 BNL 算法而不使用 Nested-Loop Join 呢?
如果上面第二条sql使用 Nested-Loop Join,那么扫描行数为 100 * 10000 = 100万次,这个是磁盘扫描。
很显然,用BNL磁盘扫描次数少很多,相比于磁盘扫描,BNL的内存计算会快得多。
因此MySQL对于被驱动表的关联字段没索引的关联查询,一般都会使用 BNL 算法。如果有索引一般选择 NLJ 算法,有
索引的情况下 NLJ 算法比 BNL算法性能更高
对于关联sql的优化
关联字段加索引,让mysql做join操作时尽量选择NLJ算法
小表驱动大表,写多表连接sql时如果明确知道哪张表是小表可以用straight_join写法固定连接驱动方式,省去
mysql优化器自己判断的时间
straight_join解释:straight_join功能同join类似,但能让左边的表来驱动右边的表,能改表优化器对于联表查询的执
行顺序。
比如:select * from t2 straight_join t1 on t2.a = t1.a; 代表指定mysql选着 t2 表作为驱动表。
straight_join只适用于inner join,并不适用于left join,right join。(因为left join,right join已经代表指
定了表的执行顺序)
尽可能让优化器去判断,因为大部分情况下mysql优化器是比人要聪明的。使用straight_join一定要慎重,因
为部分情况下人为指定的执行顺序并不一定会比优化引擎要靠谱。
对于小表定义的明确
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与 join 的各个字段的总数据
量,数据量小的那个表,就是“小表”,应该作为驱动表。
group by
是否存在优化

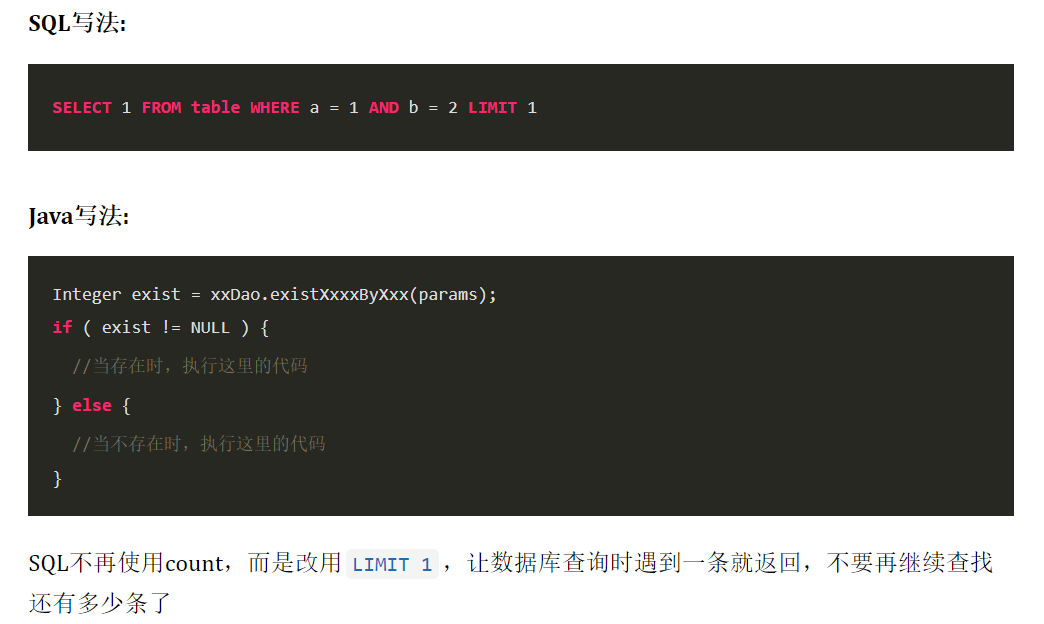
SQL不再使用count,而是改用LIMIT 1,让数据库查询时遇到一条就返回,不要再继续查找还有多少条了
业务代码中直接判断是否非空即可
总结
根据查询条件查出来的条数越多,性能提升的越明显,在某些情况下,还可以减少联合索引的创建
定位并优化慢查询sql
使用查询日志代码。查看日志的具体情况
slow_query_log
当这个参数设置为ON,可以搜寻到时间超过慢查询定义的时间(即1S)SQL语句,默认是off关闭的,使用时,需要改为on 打开。
long_query_time
默认是10S,执行后会浏览所有SQL语句,当某些SQL语句执行超过设定时间后,系统会自动的将该条语句记录到日志中。
slow_query_log_file 记录的是慢日志的记录文件
SHOW STATUS LIKE '%slow_queries%' 查看慢查询状态
Slow_queries 记录的是慢查询数量 当有一条sql执行一次比较慢时,这个vlue就是1 (记录的是本次会话的慢sql条数)
注意:
如何打开慢查询 : SET GLOBAL slow_query_log = ON;
将默认时间改为1S: SET GLOBAL long_query_time = 1;
(设置完需要重新连接数据库,PS:仅在这里改的话,当再次重启数据库服务时,所有设置又会自动恢复成默认值,永久改变需去my.ini中改)
https://www.cnblogs.com/xk920/p/11132038.html
https://mp.weixin.qq.com/s/5e3H1enFYrieVirLbDFOzA
https://mp.weixin.qq.com/s/D0wp9DJUvAZpCVU8eIyLdg
。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号