Andrew Ng机器学习公开课笔记 -- 支持向量机
先继续前面对线性分类器的讨论,
通过机器学习算法找到的线性分类的线,不是唯一的,对于一个训练集一般都会有很多线可以把两类分开,这里的问题是我们需要找到best的那条线
首先需要定义Margin,直观上来讲,best的那条线,应该是在可以正确分类的前提下,离所有的样本点越远越好,why?
因为越靠近分类线,表示该点越容易被分错,比如图中的C点,此时y=1,但是只要分类线略微调整一下角度,就有可能被分为y=-1
但对于A点,就可以非常confident的被分为y=1 。所以分类线越远离样本点,表示我们的分类越confident

那么如果定义“远”这个概念?
functional margin
图中的分类线为,wx+b=0 。那么点离这条线越远,有wx+b>>0或<<0,比如A点
前面加上y保证距离非负,所以functional margin定义为 :
![]() ,y取值{-1,1}
,y取值{-1,1}
可以看出当点离线越远时,这个margin会越大,表示分类越confident
并且margin>0时,证明这个点的分类是正确的。因为比如训练集中y=1,而由线性分类器wx+b得到的结果-0.8,这样表示分错了,margin一定是<0的。
对于训练集中m的样本,有
![]() ,即,整体的margin由最近的那个决定
,即,整体的margin由最近的那个决定
如果要用functional margin来寻找best分类线,那么我就需要找到使得 ![]() 最大的那条线。
最大的那条线。
但使用functional margin有个问题,因为你可以看到![]() 取决于w和b的值,你可以在不改变分类线的情况下,无限增加w和b的值,因为2x+1=0和4x+2=0是同一条线,但得到的functional margin却不一样。
取决于w和b的值,你可以在不改变分类线的情况下,无限增加w和b的值,因为2x+1=0和4x+2=0是同一条线,但得到的functional margin却不一样。
geometric margins
再来看另外一种margin,从几何角度更加直观的表示“远” 。即该点到线的垂直距离,比如图中A到线的距离![]()

现在问题是,如何可以求解出![]() ?
?
可以看到A和分类线垂直相交于B,B是满足wx+b=0的等式的。所以我们通过A的x和![]() ,推导出B的x,最终通过等式求出
,推导出B的x,最终通过等式求出![]() 。
。
如果A的x为 ![]() ,AB间距离为
,AB间距离为![]()
那么B的x为 ![]() ,于是有:
,于是有:![]()
求得:

考虑y=-1的情况,最终得到如下:

可以看到,如果||w|| = 1,那么functional margin 等于geometric margin
那么对于geometric margin,无论w,b的取值都不会改变margin的值,其实就是对functional margin做了标准化。
The optimal margin classifier
先简单看看凸优化的概念
凸优化问题
用一个比较通俗的方式理解
为什么要凸优化?
这种优化是一定可以找到全局最优的,因为不存在局部最优,只有一个最优点。
所以对于梯度下降或其他的最优化算法而言,在非凸的情况下,很可能找到的只是个局部最优。凸集,http://en.wikipedia.org/wiki/Convex_set
很好理解,对于二维的情况比较形象(作为例子)集合中任意两点的连线都在集合中:

凸函数,http://en.wikipedia.org/wiki/Convex_function
函数图上任意两点的连线都在above这个图中(这个应该取决于上凸或下凸,都below也一样)
换个说法,就是他的epigraph是个凸集,其中epigraph就是在这个函数上或以上区域所表示的点集。


典型的凸函数,如quadratic functionand the exponential function
for any real number x
凸优化问题的定义
在凸集上寻找凸函数的全局最值的过程称为凸优化。即,目标函数(objective function)是凸函数,可行集(feasible set)为凸集。
为何目标函数需要是凸函数?
这个比较容易理解,不是凸函数会有多个局部最优,如下图,不一定可以找到全局最优
为何可行集需要为凸集?
稍微难理解一些,看下图
虽然目标函数为凸函数,但是如果可行集非凸集,一样无法找到全局最优:





 and the
and the  for any real number x
for any real number x

接着看这个问题,根据上面的说法,要找到最优的classifier就是要找到geometric margin最大的那个超平面。
即,最大化geometric margin ![]() ,并且训练集中所有样本点的geometric margin都大于这个
,并且训练集中所有样本点的geometric margin都大于这个![]() (因为
(因为![]() )
)
这里假设||w||=1,所以function margin等同于geometric margin,这里用的是function margin的公式

这个优化的问题是:约束||w||=1会导致非凸集! (想想为什么?)
所以要去掉这个约束,得到

但这个优化仍然有问题,目标函数![]() 不是凸函数,因为是双曲线,明显非凸!
不是凸函数,因为是双曲线,明显非凸!
继续,由于function margin通过w,b的缩放可以是任意值,所以增加约束 ![]() ,这个约束是成立,因为无论
,这个约束是成立,因为无论![]() 得到什么值,通过w,b都除以
得到什么值,通过w,b都除以![]() ,就可以使
,就可以使![]() 。
。
于是就有:
![]() ,使这个最大化,即最小化
,使这个最大化,即最小化![]() (为什么要加上平方?因为二次函数是典型的凸函数,所以这样就把非凸函数转换为凸函数)
(为什么要加上平方?因为二次函数是典型的凸函数,所以这样就把非凸函数转换为凸函数)
最终得到,

这是一个凸优化问题,可以用最优化工具去解
Lagrange duality
先偏下题,说下拉格朗日乘数法,为什么要说这个?
因为我们在上面看到这种极值问题是带约束条件的,这种极值问题如何解?好像有些困难。
拉格朗日乘数法就是用来解决这种极值问题的,将一个有n 个变量与k 个约束条件的最优化问题转换为一个有n + k个变量的方程组的极值问题
参考http://zh.wikipedia.org/wiki/%E6%8B%89%E6%A0%BC%E6%9C%97%E6%97%A5%E4%B9%98%E6%95%B0
定义, 对于如下的极值问题,求最小化的f(w),同时需要满足i个约束条件h(w)
![]()
利用拉格朗日数乘法,变成如下的极值问题
 ,其中
,其中![]() 称为Lagrange multipliers(拉格朗日算子)
称为Lagrange multipliers(拉格朗日算子)
最终,求下面这个方程组,解出w和拉格朗日算子β,求出f(w)的极值。

再看看wiki上的例子,好理解一些:
假设有函数: ,要求其极值(最大值/最小值),且满足条件
,要求其极值(最大值/最小值),且满足条件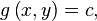

看图,画出f(x,y)的等高线,和约束条件g(x,y)=c的路径,会有多处相交。但只有当等高线和约束条件线相切的时候,才是极值点
因为如果是相交,你想象沿着g(x,y)=c继续前进,一定可以到达比现在f值更高或更低的点;那么求相切点,就是求解f和g的偏导为0的方程组。
说到这里,还不够,因为你发现上面的约束条件是不等式。。。
于是继续看更通用化的拉格朗日数乘法

既有等式,也有不等式的约束,称为generalized Lagrangian
 ,其中,
,其中,![]()
这里先引入primal optimization problem

这个啥意思?
这里注意观察,当约束条件不满足时,这个式子一定是无穷大,因为如果g>0或h不等于0,那么只需要无限增大![]() ,那么L的最大值一定是无限大, 而只要满足约束条件, 那么L的最大值就是f。
,那么L的最大值一定是无限大, 而只要满足约束条件, 那么L的最大值就是f。
即,

所以,primal optimization problem就等价于最开始的minf(), 并且primal optimization problem是没有约束条件的,因为已经隐含了约束条件。
min的那个一定不是无穷大,所以一定是满足约束条件的。

再引入dual optimization problem
![]()
和prime问题不一样,这里以![]() 为变量,而非w
为变量,而非w
![]()
而且可以看到和prime问题不一样的只是交换了min和max的顺序,并且简单可以证明:

这不是L的特殊特性,而是对于任意函数maxmin都是小于等于minmax的,可以随便找个试试呵呵
并且在特定的条件下
![]()
这样我们就可以解dual问题来替代prime问题。
为何这么麻烦?要引入dual问题,因为后面会看到dual问题有比较有用的特性,求解会比较简单。
前面说了,只有在特定条件下,才可以用dual问题替代prime问题
那么这条件是什么?这些条件先列在这里,不理解没事
所有g函数为凸函数,而h函数为affine,所谓affine基本等同于linear,![]() ,只是多了截距b
,只是多了截距b
假设存在w可以让gi(w)<0对所有i 都成立的,即约束gi 是严格可行的。
满足上面的假设后,就一定存在w∗, α∗, β∗满足p∗ = d∗ = L(w∗, α∗, β∗),并且这时的w∗, α∗ and β∗ 还满足KKT条件,

并且,只要任意w∗, α∗ and β∗满足KKT条件,那么它们就是prime和dual问题的解
注意其中的(5), 称为KKT dual complementarity condition ,要满足这个条件,α和g至少有一个为0,当α>0时,g=0,这时称“gi(w) ≤ 0” constraint is active,因为此时g约束由不等式变为等式。
在后面可以看到这意味着什么?g=0时是约束的边界,对于svm就是那些support vector。
Optimal margin classifiers – Continuing
谈论了那么多晦涩的东西,不要忘了目的,我们的目的是要求解optimal margin 问题,所以现在继续
前面说了optimal margin问题描述为 :

其中,g约束表示为 :
![]()
那么什么时候g=0?当functional margin为1(前面描述optimal margin问题的时候,已经假设funtional margin为1),所以只有靠近超平面最近的点的functional margin为1,即g=0,而其他训练点的functional margin都>1 。
该图中只有3个点满足这个条件,这些点称为support vector,只有他们会影响到分类超平面。
实现在训练集中只有很少的一部分数据点是support vector,而其他的绝大部分点其实都是对分类没有影响的。

前面说了半天prime问题和dual问题,就是为了可以用解dual问题来替代解prime问题。用dual问题的好处之一是,求解过程中只需要用到inner product![]() ,而表示直接使用x,这个对使用kernel解决高维度问题很重要。
,而表示直接使用x,这个对使用kernel解决高维度问题很重要。
好,下面就来求解optimal margin的dual问题 :

和上面讨论的广义拉格朗日相比,注意符号上的两个变化:
1) w变量—>w,b两个变量
2) 只有α,而没有β,因为只有不等式约束而没有等式约束
对于dual问题,先求
![]() ( 这里就是对于w,b求L的min,做法就是求偏导为0的方程组 )
( 这里就是对于w,b求L的min,做法就是求偏导为0的方程组 )
首先对w求偏导 :
![]()
得到如下式子,这样我们在解出dual问题后,可以通过α,进一步算出w

接着对b求偏导 :

现在把9,10,代入8,得到

这就是![]() , 下一步就是继续求极值 :
, 下一步就是继续求极值 :![]()
于是有,第一个约束本来就有,第二个约束是对b求偏导得到的结果 :

( 你可以验证我们这个问题是满足KKT条件的,所以可以解出这个dual问题来代替原来的prime问题。)
先不谈如何求解上面的极值问题(后面会介绍具体算法),我们先谈谈如果解出α,如何解出prime问题的w和b
w前面已经说过了,通过等式9就可以解出
那么如何解出b ?

其实理解就是, 找出-1和1中靠超平面最近的点,即支持向量,用他们的b的均值作为b* 。因为w定了,即超平面的方向定了,剩下的就是平移,平移到正负支持向量的中间位置为最佳。
求出w,b后,我们的支持向量机就已经准备好了,下面可以对新的数据点进行分类。很简单其实只要代入![]() ,-1或1来区分不同的类。
,-1或1来区分不同的类。
这里也把9代入,

你可能觉得多此一举,这样每次分类都要把训练集都遍历一遍。其实无论是使用dual优化问题或是这里,都是为了避免直接计算x,而是代替的计算x的内积,因为后面谈到kernel,对于高维或无限维数据直接计算x是不可行的,而我们可以使用kernel函数来近似计算x的内积。
而且其实,这里的计算量并不大,因为前面介绍了,α只有支持向量是不为0的,而支持向量是很少的一部分。
Kernels
先谈谈feature mapping,
比如想根据房屋的面积来预测价格,设范围面积为x,出于便于分类的考虑可能不光简单的用x,而是用![]() 做为3个feature
做为3个feature
其实将低维数据映射到高维数据的主要原因是,因为一些在低维度线性不可分的数据,到了高维度就是线性可分的了。
这里我们称,"original” input value(比如x)为输入属性(input attributes )
称new quantities(![]() ) 为输入特征(input features)
) 为输入特征(input features)
我们用 φ 表示特征映射( feature mapping)

在将低维度的x mapping到高维度的φ(x)后,只需要把φ(x)代入之前dual problem的式子求解就ok。
但问题在于,之前dual problem的<x,z>是比较容易算的,但是高维度或无限维的<φ(x), φ(z)>是很难算出的,所以这里无法直接算。
所以kernel函数出场 :
![]()
我们可以通过计算kernel函数来替代计算<φ(x), φ(z)>,kernel函数是通过x,z直接算出的。
所以往往都是直接使用kernel函数去替换<x,z>,将svm映射到高维,而其中具体的φ()你不用关心(因为计算φ本身就是很expensive的),你只要知道这个kernel函数确实对应于某一个φ()就可以。
polynomial kernel
我们先看一个简单的kernel函数的例子,称为polynomial kernel(多项式核)

这个kernel是可以推导出φ()的,

可以看出最终的结果是,φ将x mapping成xx,如下(假设n=3)

可见,如果这里如果直接计算![]() ,复杂度是
,复杂度是![]() ,因为x的维度为3,映射到φ就是9 ;而计算K函数,复杂度就只有O(n)
,因为x的维度为3,映射到φ就是9 ;而计算K函数,复杂度就只有O(n)
推广一下,加上常数项 :

这个推导出的φ为,n=3

再推广一下,
![]() ,将x mapping到
,将x mapping到![]() ,虽然在
,虽然在![]() ,但是计算K仍然都是O(n)的
,但是计算K仍然都是O(n)的
虽然上面都找到了φ, 其实你根本不用关心φ是什么, 或者到底mapping到多高的维度。
Gaussian kernel
在来看另外一种kernel函数(高斯核)
来想一想内积的含义,当两个向量越相近的时候,内积值是越大的,而越远的时候,内积值是越小的
所以我们可以把kernel函数,看成是用来衡量两个向量有多相似
于是给出下面的kernel函数,这个函数由于描述x,z的相似度是合理的
 ( 这个kernel函数对于的φ是个无限维的映射,你不用关心到底是什么)
( 这个kernel函数对于的φ是个无限维的映射,你不用关心到底是什么)
如何判定一个kernel函数是否是有效的?
下面就来证明一个判定方法 :
假设,K 对于特征映射φ是一个有效的kernel 函数,对于有限集m{x(1),...,x(m)},我们可以得到一个m-by-m的Kernel matrix K,其中
Kij = K(x(i),x(j)) = Φ(x(i))TΦ(x(j)) = Φ(x(j))TΦ(x(i)) = K(x(j),x(i)) = Kji,这里符号用重了,K同时表示kernel函数和kernel矩阵。
于是可以证明,K是个半正定矩阵 (positive semi-definite) ( 对于任何非0向量z,都有zTKz>=0,那么K称为半正定矩阵 )

即K函数是valid kernel函数,那么K矩阵一定是半正定矩阵,(其实满足这是个充分必要条件的是Mercer kernel的定义)
所以有了这个定理,就比较方便了,你不用去找是否有对应的φ,只需要判定K矩阵是否为半正定矩阵即可。
-----------------------------------------------------------------------------------------
下面NG讲了个很典型的使用SVM kernel的例子,
例:一个识别问题,就是根据16×16的像素点,来判断是否是0~9的数字
传统的方法是,神经网络,认为是解这个问题的最好的算法。
可是这里用polynomial kernel or the Gaussian kernel,SVM也得到了很好的效果,和神经网络的结果一样好。
这是很让人吃惊的,因为初始输入只是256维的向量,并且没有任何prior knowledge的情况下,可以得到和精心定制的神经网络一样好的效果!
NG还讲了另外一个例子,即初始输入的维数不固定的情况下,例如输入字符串的长度不固定,如何产生固定的维数的输入,参考讲义吧呵呵
这里看到Kernel在SVM里面的应用已经非常清晰了,但是其实Kernel不是只是可以用于SVM
其实它是个通用的方法,只要学习算法可以只含有输入的内积,那么都可以使用kernel trick来替换它(例如,这个核技巧可以用于感知器来获取核感知算法)
Regularization and the non-separable case(规则化和非可分离情况)
讨论异常点,或离群点
当样本线性不可分时,我们可以尝试使用核函数来将特征映射到高维,这样很可能就可分了。然而,映射后我们也不能100%保证可分。那怎么办?我们需要将模型进行调整,以保证在不可分的情况下也能尽可能地找出分隔超平面。
比如下图,是否值得为了左上角那个点,将划分线调整成右边这样?很明显那个是离群点(可能是噪声),而且造成超平面的移动,间隔缩小,可见以前的模型对噪声非常敏感。再有甚者,如果离群点在另外一个类中,那么这时候就是线性不可分了。

这时候我们应该允许一些点游离并在模型中违背限制条件(函数间隔大于1),重新优化函数如下(也称软间隔) :

其实就是加上修正值ξi(称为松弛变量),使得某些点的functional margin可以小于1,即容忍一些异常点。
同时需要对目标函数重新调整,以对离群点进行处罚,参数C为权重,C越大表明离群点对目标函数影响越大,也就越不希望看到离群点。目标函数后面加上的![]() 就表示离群点越多,目标函数值越大,而要求是最小化目标函数。
就表示离群点越多,目标函数值越大,而要求是最小化目标函数。
修改后的拉格朗日公式 :

最终得到的dual problem是 :

此时,我们发现没有了参数ξi ,与之前模型唯一的不同在于αi 又多了αi ≤ C 的限制条件。b的求值公式也发生了改变,改变结果在SMO算法里面介绍。
对于这个dual problem的KKT 条件变化为 :

第一个式子表明在两条间隔线外的样本点前面的系数为 0 ,离群样本点前面的系数为C,支持向量的样本点前面的系数在(0, C)上。通过KKT条件可知,某些在最大间隔线上的样本点也不是支持向量,相反也有可能是离群点。
The SMO algorithm by John Platt
前面都是给出了dual problem,可是没有说怎么解,现在就来谈如何解SVM的dual problem
Coordinate ascent (descent) (坐标上升法)
在讨论W(α)的求解之前,我们先看看坐标上升法的基本原理。假设要求解下面的优化问题 :
![]()
这里W是α向量的函数。有两种求最优解的方法:一种是梯度下降法,另一种是牛顿法。现在再讲一种坐标上升法(求解最小值问题时,称作坐标下降法,原理一样)
算法,不停迭代,每次迭代都是只改变某一个维度来做最优化,其他维度保持不变 :

最里面语言的意思是固定除αi 之外的所有αj(j≠i),这时W可看作只是关于αi 的函数,那么直接对αi 求导优化即可。这里我们进行最大化求导的顺序 i 是从1到m,可以通过更改优化顺序来使W能够更快地增加并收敛。如果W在内循环中能够很快地达到最优,那么坐标上升法会是一个很高效的求极值方法。
这个算法从图上看起来就像这样:

椭圆代表了二次函数的各个等高线,变量数为2,起始坐标是(2, -2)。图中的直线式迭代优化的路径,可以看到每一步都会向最优值前进一步,而且前进路线是平行于坐标轴的,因为每一步只优化一个变量。
前面学过梯度下降和牛顿法,有啥区别?
牛顿,收敛很快,但每次收敛的代价比较大;坐标上升,收敛比较慢,但是每次收敛的代价都很小。
梯度下降,不适合高维,因为每次迭代都需要算出梯度,需要考虑所有维度。
SMO (sequential minimal optimization)( 序列优化算法 )
SMO算法由Microsoft Research的John C. Platt在1998年提出,并成为最快的二次规划优化算法,特别对线性SVM和数据稀疏时,性能更优。
首先回到我们前面一直悬而未解的问题,对偶函数最后的优化问题 :

要解决的是在参数{α1,α2 ,...,αn} 上求最大值W的问题,至于x(i) 和y(i) 都是已知数。C由我们预先设定,也是已知数。
按照坐标上升的思路,我们首先固定除α1 外的所有参数,然后在α1 上求极值。但是,这个思路有问题!因为如果固定α1 以外的所有参数,那么α1 将不再是一个变量(可以由其他值推出),因为问题中规定了:

因此需要一次选取两个参数做优化,比如α1 和α2 ,此时α2 可以由α1 和其他参数表示出来。这样回带到W中,W就只是关于α1 的函数了,可解。
这样,SMO的主要步骤如下:

意思是:第一步选取一对αi 和αj ,选取方法使用启发式方法。第二步固定除αi 和αj 之外的其他参数,确定W极值条件下的αi ,αj 由αi 表示。
SMO之所以高效,是因为在固定其他参数后,对一个参数优化过程很高效。
下面讨论具体方法 :假设我们选取了初始值{α1,α2,...,αn}满足了问题中的约束条件。接下来,我们固定{α3,α4,...,αn},这样W就是α1和α2的函数。 并且α1和α2 满足条件:

由于{α3,α4,...,αn}都是已知固定值,因此为了方便,可将等式右边标记成实数值ζ :
![]()
当y(1)和y(2)异号时,(一个为1,一个为-1),它们可以表示成一条直线,斜率为1.如下图:

横轴是α1,纵轴是α2,α1和α2既要在矩形方框内,也要在直线上,因此
![]() ,
,![]()
同理,当y(1)和y(2)同号时,
![]() ,
,![]()
然后我们打算将α1用α2表示 :
![]()
然后反代入W中,得 :
![]()
展开后W可表示成 aα22+bα2+c 。其中a,b,c是固定值。这样,通过对W进行求导可以得到α2,然后要保证α2满足L≤α2≤H,使用α2new,unclipped表示求导求出来的α2,然而最后的α2要根据下面情况得到 :

这样得到α2new后,可以得到α1的新值α1new。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号