scrapy必要类相关知识


Scrapy爬虫支持多种HTML信息提取方法:
Beautiful Soup
lxml
re
XPath Selector
CSS Selector
***********************************************************
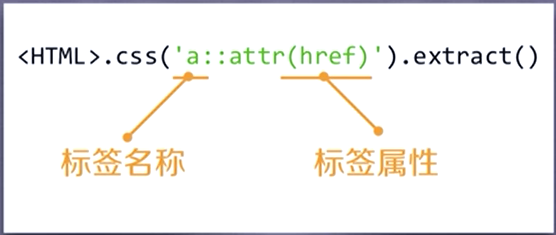
CSS Selector 的基本使用:
<HTML>.css('a::attr(href)').extract
新手尝试
Scrapy爬虫支持多种HTML信息提取方法:
Beautiful Soup
lxml
re
XPath Selector
CSS Selector
***********************************************************
CSS Selector 的基本使用:
<HTML>.css('a::attr(href)').extract

 浙公网安备 33010602011771号
浙公网安备 33010602011771号