beautifuf soup
beautifulsoup是解析html,xml文档
基本元素
1.Tag 标签
2.Name 标签的名字
3.Attributes 标签的属性
4.NavigableString 标签内非属性字符串,
5.Comment 标签内字符串的注释部分,一种特殊的Comment类型。
-------------------------------------------------------------------------------
>>> r = requests.get("http://python123.io/ws/demo.html")
>>> demo = r.text
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(demo,"html.parser")
soup.a 获得a标签,soup.p获得p标签
标签.<tag> (名称.name) (属性 .attrs) (类型.string)
HTML的基本格式
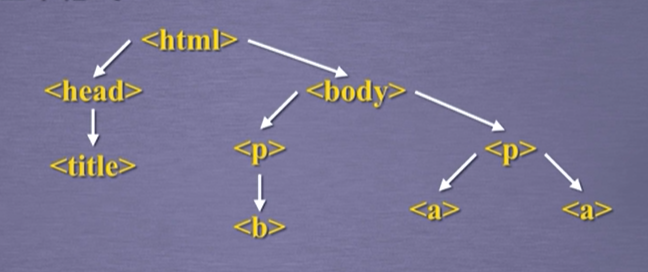
标签的下行遍历

标签树的上行遍历

标签树的平行遍历

更好的显示
soup.prettify() 加换行符
print(soup.prettify())
bs4 把HIML的编码格式转化成utf-8
新手尝试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号