MATLAB神经网络(3) 遗传算法优化BP神经网络——非线性函数拟合
3.1 案例背景
遗传算法(Genetic Algorithms)是一种模拟自然界遗传机制和生物进化论而形成的一种并行随机搜索最优化方法。
其基本要素包括:染色体编码方法、适应度函数、遗传操作和运行参数。
非线性函数:$y=x_{1}^{2}+x_{2}^{2}$
3.2 模型建立
3.2.1 算法流程

遗传算法优化使用遗传算法优化BP神经网络的权值和阔值,种群中的每个个体都包含了一 个网络所有权值和阔值,个体通过适应度函数计算个体适应度值,遗传算法通过选择、交叉和变异操作找到最优适应度值对应个体。神经网络预测用遗传算法得到最优个体对网络初始权值和阈值赋值,网络经训练后预测函数输出。
神经网络结构:2-5-1
3.2.2 遗传算法实现
种群初始化
个体编码方法为实数编码,每个个体均为一个实数串,由输入层与隐含层连接权值、隐含层阈值、隐含层与输出层连接权值以及输出层阈值4部分组成。个体包含了神经网络全部权值和阐值,在网络结构已知的情况下,就可以构成一个确定的神经网络。
适应度函数
把预测输出和期望输出之间的误差绝对值和$E$作为个体适应度$F$,计算公式为\[F = k\left( {\sum\limits_{i = 1}^n {{\rm{abs}}({y_i} - {o_i})} } \right)\]$k$为系数。
选择操作
轮盘赌:基于适应度比例的选择策略,每个个体$i$的选择概率$p_{i}$为\[\begin{array}{l}
{f_i} = k/{F_i}\\
{p_i} = \frac{{{f_i}}}{{\sum\limits_{j = 1}^N {{f_j}} }}
\end{array}\]式中,$F_{i}$为个体$i$的适应度值,由于适应度值越小越好,所以在个体选择前对适应度值取倒数,$k$为系数,$N$为种群个体数目。
交叉操作
由于个体采用实数编码,所以交叉操作方法采用实数交叉法,第$k$个染色体$a_{k}$和第$l$个染色体$a_{l}$在$j$位的交叉操作方法如下:\[\left\{ \begin{array}{l}
{a_{kj}} = {a_{kj}}(1 - b) + {a_{lj}}b\\
{a_{lj}} = {a_{lj}}(1 - b) + {a_{kj}}b
\end{array} \right.\]式中,$b$是[0,1]之间的随机数。
变异操作
选取第$i$个个体的第$j$个基因进行变异,变异操作方法如下:\[{a_{ij}} = \left\{ \begin{array}{l}
{a_{ij}} + ({a_{ij}} - {a_{\max }}) * f(g)\;\;r > 0.5\\
{a_{ij}} + ({a_{\min }} - {a_{ij}}) * f(g)\;\;r \le 0.5
\end{array} \right.\]式中,$a_{max}$、$a_{min}$为基因$a_{ij}$的上界和下界,$f(g) = {r_2}{(1 - g/{G_{\max }})^2}$,$r_{2}$为一个随机数,$g$为当前迭代次数,$G_{max}$为最大进化次数,$r$为[0,1]之间的随机数。
3.3 编程实现
3.3.1 数据加载
%% 基于遗传算法神经网络的预测代码 % 清空环境变量 clc clear % %% 网络结构建立 %读取数据 input=10*randn(2,2000); output=sum(input.*input); %训练数据和预测数据 input_train=input(:,1:1900); input_test=input(:,1901:2000); output_train=output(1:1900); output_test=output(1901:2000); %选连样本输入输出数据归一化 [inputn,inputps]=mapminmax(input_train); [outputn,outputps]=mapminmax(output_train);
3.3.2 参数预设
%节点个数 inputnum=2; hiddennum=5; outputnum=1; %构建网络 net=newff(inputn,outputn,hiddennum); %% 遗传算法参数初始化 maxgen=20; %进化代数,即迭代次数 sizepop=10; %种群规模 pcross=[0.2]; %交叉概率选择,0和1之间 pmutation=[0.1]; %变异概率选择,0和1之间 %节点总数 numsum=inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum; lenchrom=ones(1,numsum); bound=[-3*ones(numsum,1) 3*ones(numsum,1)]; %数据范围
3.3.3 种群初始化
%% 种群初始化
individuals=struct('fitness',zeros(1,sizepop), 'chrom',[]); %将种群信息定义为一个结构体
avgfitness=[]; %每一代种群的平均适应度
bestfitness=[]; %每一代种群的最佳适应度
bestchrom=[]; %适应度最好的染色体
%初始化种群
for i=1:sizepop
%随机产生一个种群
individuals.chrom(i,:)=Code(lenchrom,bound); %编码(binary和grey的编码结果为一个实数,float的编码结果为一个实数向量)
x=individuals.chrom(i,:);
%计算适应度
individuals.fitness(i)=fun(x,inputnum,hiddennum,outputnum,net,inputn,outputn); %染色体的适应度
end
FitRecord=[];
%找最好的染色体
[bestfitness,bestindex]=min(individuals.fitness);
bestchrom=individuals.chrom(bestindex,:); %最好的染色体
avgfitness=sum(individuals.fitness)/sizepop; %染色体的平均适应度
% 记录每一代进化中最好的适应度和平均适应度
trace=[avgfitness bestfitness];
编码函数:在bound边界范围内随机生成个体。
function ret=Code(lenchrom,bound)
%本函数将变量编码成染色体,用于随机初始化一个种群
% lenchrom input : 染色体长度
% bound input : 变量的取值范围
% ret output: 染色体的编码值
flag=0;
while flag==0
pick=rand(1,length(lenchrom));
ret=bound(:,1)'+(bound(:,2)-bound(:,1))'.*pick; %线性插值,编码结果以实数向量存入ret中
flag=test(lenchrom,bound,ret); %检验染色体的可行性
end
检验函数:必要的时候可以添加检验染色体可行性的代码。
function flag=test(lenchrom,bound,code) % lenchrom input : 染色体长度 % bound input : 变量的取值范围 % code output: 染色体的编码值 x=code; %先解码 flag=1;
适应度函数:以编码代表的初值进行神经网络训练,计算出误差绝对值和作为适应度。
function error = fun(x,inputnum,hiddennum,outputnum,net,inputn,outputn)
%该函数用来计算适应度值
%x input 个体
%inputnum input 输入层节点数
%outputnum input 隐含层节点数
%net input 网络
%inputn input 训练输入数据
%outputn input 训练输出数据
%error output 个体适应度值
%提取
w1=x(1:inputnum*hiddennum);
B1=x(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum);
w2=x(inputnum*hiddennum+hiddennum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum);
B2=x(inputnum*hiddennum+hiddennum+hiddennum*outputnum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum);
%网络进化参数
net.trainParam.epochs=20;
net.trainParam.lr=0.1;
net.trainParam.goal=0.00001;
net.trainParam.show=100;
net.trainParam.showWindow=0;
%网络权值赋值
net.iw{1,1}=reshape(w1,hiddennum,inputnum);
net.lw{2,1}=reshape(w2,outputnum,hiddennum);
net.b{1}=reshape(B1,hiddennum,1);
net.b{2}=B2;
%网络训练
net=train(net,inputn,outputn);
an=sim(net,inputn);
error=sum(abs(an-outputn));
3.3.4 进化过程
%% 迭代求解最佳初始阀值和权值
% 进化开始
for i=1:maxgen
% 选择
individuals=Select(individuals,sizepop);
avgfitness=sum(individuals.fitness)/sizepop;
%交叉
individuals.chrom=Cross(pcross,lenchrom,individuals.chrom,sizepop,bound);
% 变异
individuals.chrom=Mutation(pmutation,lenchrom,individuals.chrom,sizepop,i,maxgen,bound);
% 计算适应度
for j=1:sizepop
x=individuals.chrom(j,:); %解码
individuals.fitness(j)=fun(x,inputnum,hiddennum,outputnum,net,inputn,outputn);
end
%找到最小和最大适应度的染色体及它们在种群中的位置
[newbestfitness,newbestindex]=min(individuals.fitness);
[worestfitness,worestindex]=max(individuals.fitness);
% 代替上一次进化中最好的染色体
if bestfitness>newbestfitness
bestfitness=newbestfitness;
bestchrom=individuals.chrom(newbestindex,:);
end
% individuals.chrom(worestindex,:)=bestchrom;
% individuals.fitness(worestindex)=bestfitness;
avgfitness=sum(individuals.fitness)/sizepop;
trace=[trace;avgfitness bestfitness]; %记录每一代进化中最好的适应度和平均适应度
FitRecord=[FitRecord;individuals.fitness];
end
选择函数:sumf将[0,1]区间划分为sizepop个区间,生成随机数落在哪个区间就选取对应的个体。
function ret=Select(individuals,sizepop)
% 本函数对每一代种群中的染色体进行选择,以进行后面的交叉和变异
% individuals input : 种群信息
% sizepop input : 种群规模
% ret output : 经过选择后的种群
%根据个体适应度值进行排序
fitness1=10./individuals.fitness;
sumfitness=sum(fitness1);
sumf=fitness1./sumfitness;
index=[];
for i=1:sizepop %转sizepop次轮盘
pick=rand;
while pick==0
pick=rand;
end
for j=1:sizepop
pick=pick-sumf(j);
if pick<0
index=[index j];
break; %寻找落入的区间,此次转轮盘选中了染色体i,注意:在转sizepop次轮盘的过程中,有可能会重复选择某些染色体
end
end
end
individuals.chrom=individuals.chrom(index,:);
individuals.fitness=individuals.fitness(index);
ret=individuals;
交叉函数:原为v1=chrom(index(1),pos);,改为v1=chrom(index(1),pos:end);。
function ret=Cross(pcross,lenchrom,chrom,sizepop,bound)
%本函数完成交叉操作
% pcorss input : 交叉概率
% lenchrom input : 染色体的长度
% chrom input : 染色体群
% sizepop input : 种群规模
% ret output : 交叉后的染色体
for i=1:sizepop %每一轮for循环中,可能会进行一次交叉操作,染色体是随机选择的,交叉位置也是随机选择的,%但该轮for循环中是否进行交叉操作则由交叉概率决定(continue控制)
% 随机选择两个染色体进行交叉
pick=rand(1,2);
while prod(pick)==0
pick=rand(1,2);
end
index=ceil(pick.*sizepop);
% 交叉概率决定是否进行交叉
pick=rand;
while pick==0
pick=rand;
end
if pick>pcross
continue;
end
flag=0;
while flag==0
% 随机选择交叉位
pick=rand;
while pick==0
pick=rand;
end
pos=ceil(pick.*sum(lenchrom)); %随机选择进行交叉的位置,即选择第几个变量进行交叉,注意:两个染色体交叉的位置相同
pick=rand; %交叉开始
v1=chrom(index(1),pos:end);
v2=chrom(index(2),pos:end);
chrom(index(1),pos:end)=pick*v2+(1-pick)*v1;
chrom(index(2),pos:end)=pick*v1+(1-pick)*v2; %交叉结束
flag1=test(lenchrom,bound,chrom(index(1),:)); %检验染色体1的可行性
flag2=test(lenchrom,bound,chrom(index(2),:)); %检验染色体2的可行性
if flag1*flag2==0
flag=0;
else flag=1;
end %如果两个染色体不是都可行,则重新交叉
end
end
ret=chrom;
变异函数:
function ret=Mutation(pmutation,lenchrom,chrom,sizepop,num,maxgen,bound)
% 本函数完成变异操作
% pcorss input : 变异概率
% lenchrom input : 染色体长度
% chrom input : 染色体群
% sizepop input : 种群规模
% opts input : 变异方法的选择
% pop input : 当前种群的进化代数和最大的进化代数信息
% bound input : 每个个体的上届和下届
% maxgen input :最大迭代次数
% num input : 当前迭代次数
% ret output : 变异后的染色体
for i=1:sizepop %每一轮for循环中,可能会进行一次变异操作,染色体是随机选择的,变异位置也是随机选择的,
%但该轮for循环中是否进行变异操作则由变异概率决定(continue控制)
% 随机选择一个染色体进行变异
pick=rand;
while pick==0
pick=rand;
end
index=ceil(pick*sizepop);
% 变异概率决定该轮循环是否进行变异
pick=rand;
if pick>pmutation
continue;
end
flag=0;
while flag==0
% 变异位置
pick=rand;
while pick==0
pick=rand;
end
pos=ceil(pick*sum(lenchrom)); %随机选择了染色体变异的位置,即选择了第pos个变量进行变异
pick=rand; %变异开始
fg=(rand*(1-num/maxgen))^2;
if pick>0.5
chrom(i,pos)=chrom(i,pos)+(bound(pos,2)-chrom(i,pos))*fg;
else
chrom(i,pos)=chrom(i,pos)-(chrom(i,pos)-bound(pos,1))*fg;
end %变异结束
flag=test(lenchrom,bound,chrom(i,:)); %检验染色体的可行性
end
end
ret=chrom;
3.3.5 结果分析
%% 遗传算法结果分析
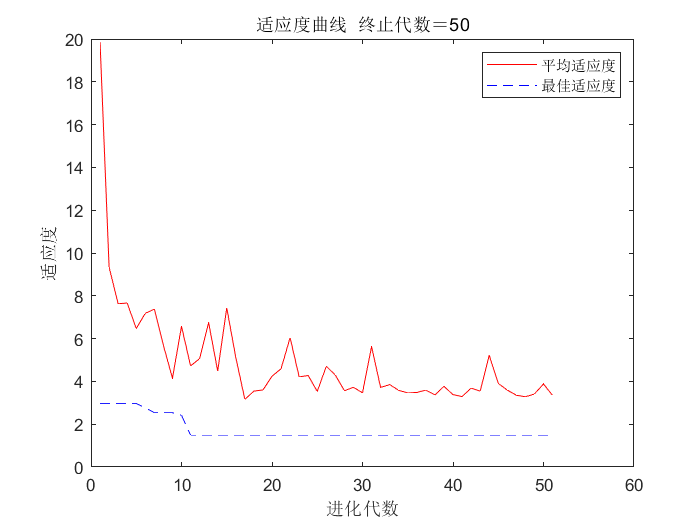
figure(1)
[r c]=size(trace);
plot([1:r]',trace(:,1),'r');
hold on
plot([1:r]',trace(:,2),'b--');
hold off
title(['适应度曲线 ' '终止代数=' num2str(maxgen)]);
xlabel('进化代数');ylabel('适应度');
legend('平均适应度','最佳适应度');
3.3.6 结果预测
%% 把最优初始阀值权值赋予网络预测
% %用遗传算法优化的BP网络进行值预测
w1=x(1:inputnum*hiddennum);
B1=x(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum);
w2=x(inputnum*hiddennum+hiddennum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum);
B2=x(inputnum*hiddennum+hiddennum+hiddennum*outputnum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum);
net.iw{1,1}=reshape(w1,hiddennum,inputnum);
net.lw{2,1}=reshape(w2,outputnum,hiddennum);
net.b{1}=reshape(B1,hiddennum,1);
net.b{2}=B2;
%% BP网络训练
%网络进化参数
net.trainParam.epochs=100;
net.trainParam.lr=0.1;
%net.trainParam.goal=0.00001;
%网络训练
[net,per2]=train(net,inputn,outputn);
%% BP网络预测
%数据归一化
inputn_test=mapminmax('apply',input_test,inputps);
an=sim(net,inputn_test);
test_simu=mapminmax('reverse',an,outputps);
error=test_simu-output_test;
plot(error)
title('误差');
xlabel('测试个体');ylabel('误差');

精度得到了一定的提高。
3.4 扩展
3.4.1 其他优化方法
粒子群算法、蚁群算法等同样可以。
3.4.2 网络结构优化
可以优化隐含层节点数目。
3.4.3 算法的局限性
它只能有限提高原有BP神经网络的预测精度,并不能把预测误差较大的BP神经网络优化为能够准确预测的BP神经网络。
其实遗传算法用处不大,主要还是靠神经网络,该用神经网络就用就完了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号