数据采集与融合技术作业4
作业4
要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内
容。
▪ 使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、
“深证 A 股”3 个板块的股票数据信息。
一、实验完整过程
导入所需库
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.edge.options import Options
import pymysql
数据表结构
CREATE TABLE IF NOT EXISTS {table_name} (
序号 INT,
代码 VARCHAR(10),
名称 VARCHAR(255),
最新价 DECIMAL(10,2),
涨跌幅 VARCHAR(10),
涨跌额 DECIMAL(8,2),
成交量 VARCHAR(10),
成交额 VARCHAR(10),
振幅 VARCHAR(10),
最高 DECIMAL(10,2),
最低 DECIMAL(10,2),
今开 DECIMAL(10,2),
昨收 DECIMAL(10,2)
);
爬取url
oringinal_url = 'https://quote.eastmoney.com/center/gridlist.html#hs_a_board'
因为进入页面后会有一个广告弹窗,找到关闭按钮的xpath,模拟鼠标点击这个元素关闭广告弹窗
ad = driver.find_element(By.XPATH, '/html/body/div[5]/img[1]')
ad.click()
关闭广告后进入页面,只需要找到想爬的三个表加载的三个按钮的xpath,点击后等待表格加载就可以看见需要爬取的数据
stockBotton = driver.find_elements(By.XPATH, "//*[@id='mainc']/div/div/div[2]/ul/li")[i].find_element(By.XPATH,"./a") #对应板块按钮
stockBotton.click()#点击按钮
driver.refresh()#刷新网页
接下来和之前实验步骤一样,解析想要数据的xpath,一一爬取下来后存到数据库即可
for stock in stocks:
td1 = stock.find_element(By.XPATH,'./td[1]').text#序号
td2 = stock.find_element(By.XPATH, './td[2]/a').text#代码
td3 = stock.find_element(By.XPATH, './td[3]/a').text#名称
td5 = stock.find_element(By.XPATH, './td[5]/span').text#最新价
td6 = stock.find_element(By.XPATH, './td[6]/span').text#涨跌幅
td7 = stock.find_element(By.XPATH, './td[7]/span').text#涨跌额
td8 = stock.find_element(By.XPATH, './td[8]').text#成交量
td9 = stock.find_element(By.XPATH, './td[9]').text#成交额
td10 = stock.find_element(By.XPATH, './td[10]').text#振幅
td11 = stock.find_element(By.XPATH, './td[11]/span').text#最高
td12 = stock.find_element(By.XPATH, './td[12]/span').text#最低
td13 = stock.find_element(By.XPATH, './td[13]/span').text#今开
td14 = stock.find_element(By.XPATH, './td[14]/span').text#昨收
实验结果
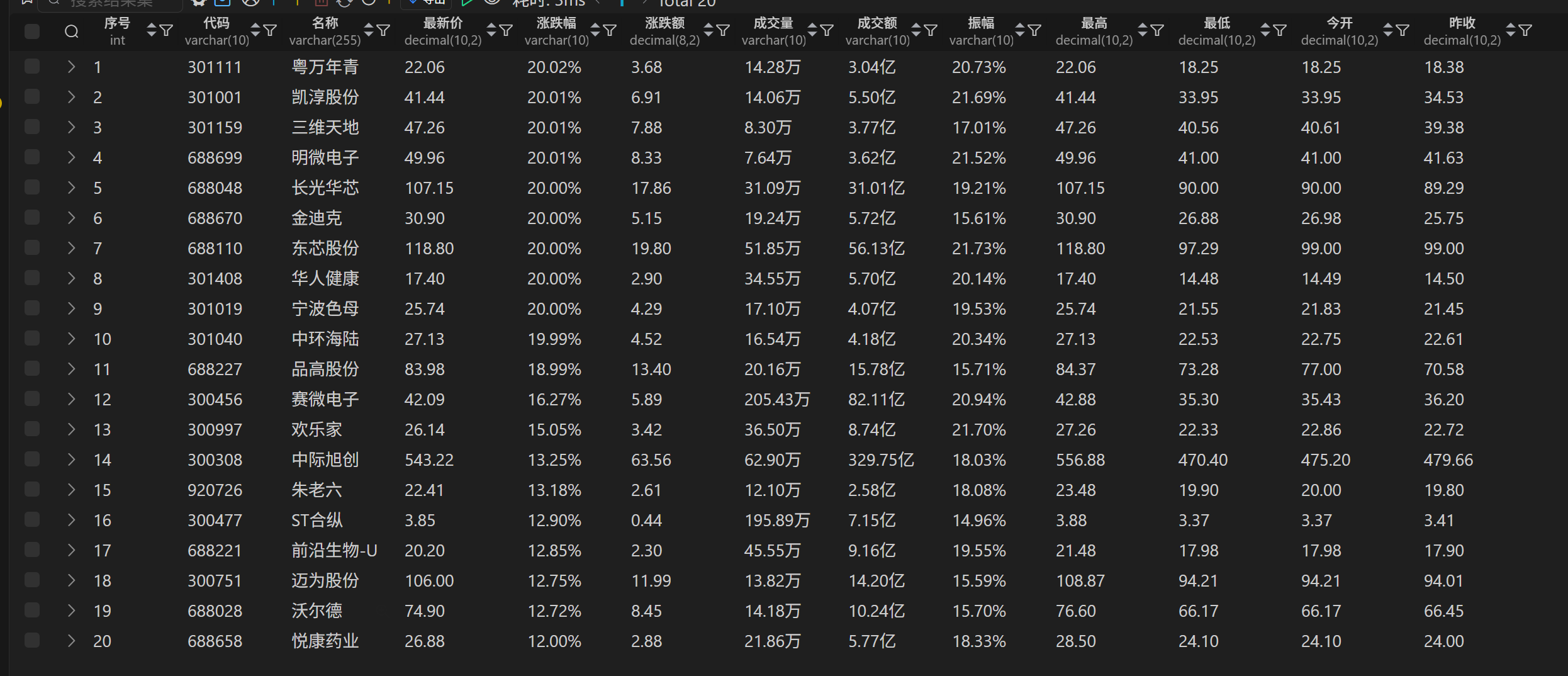
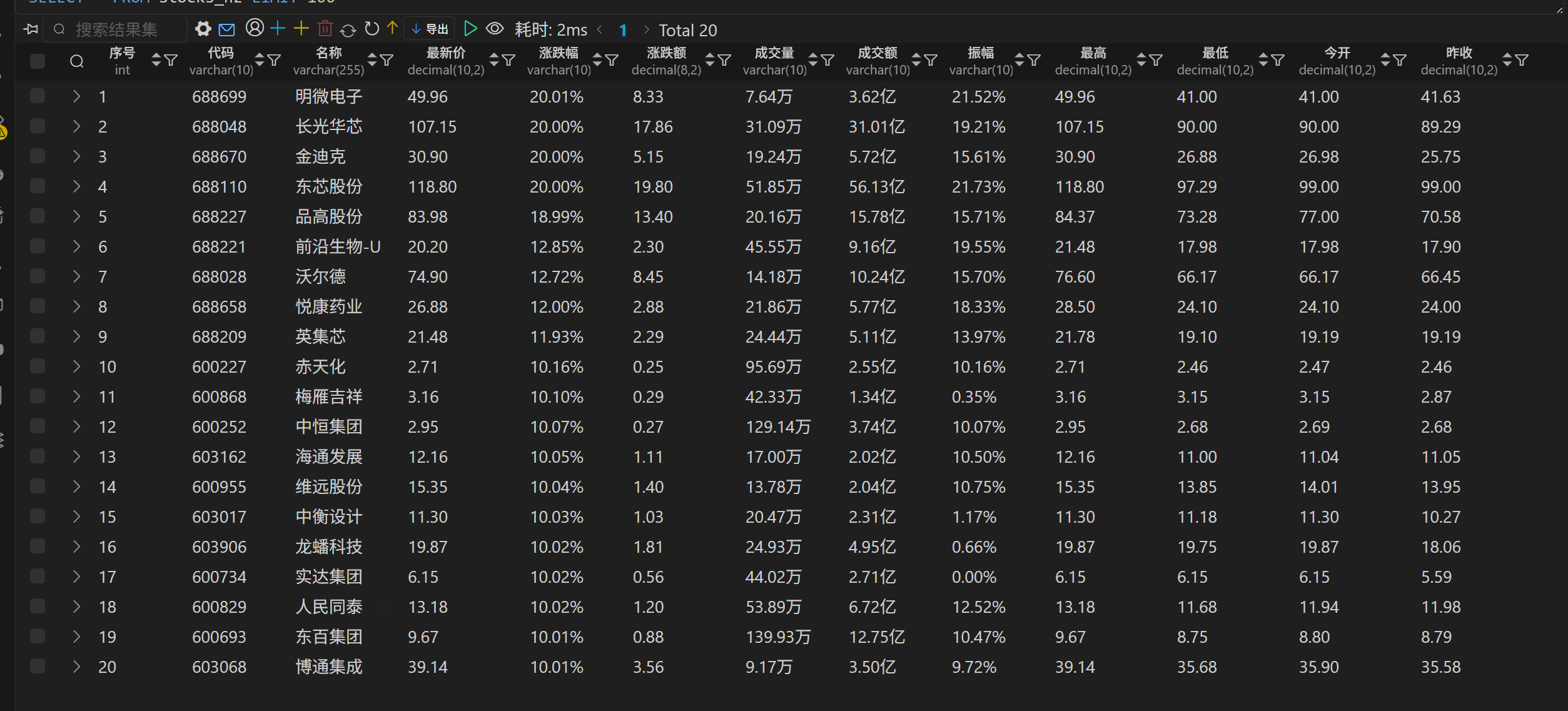
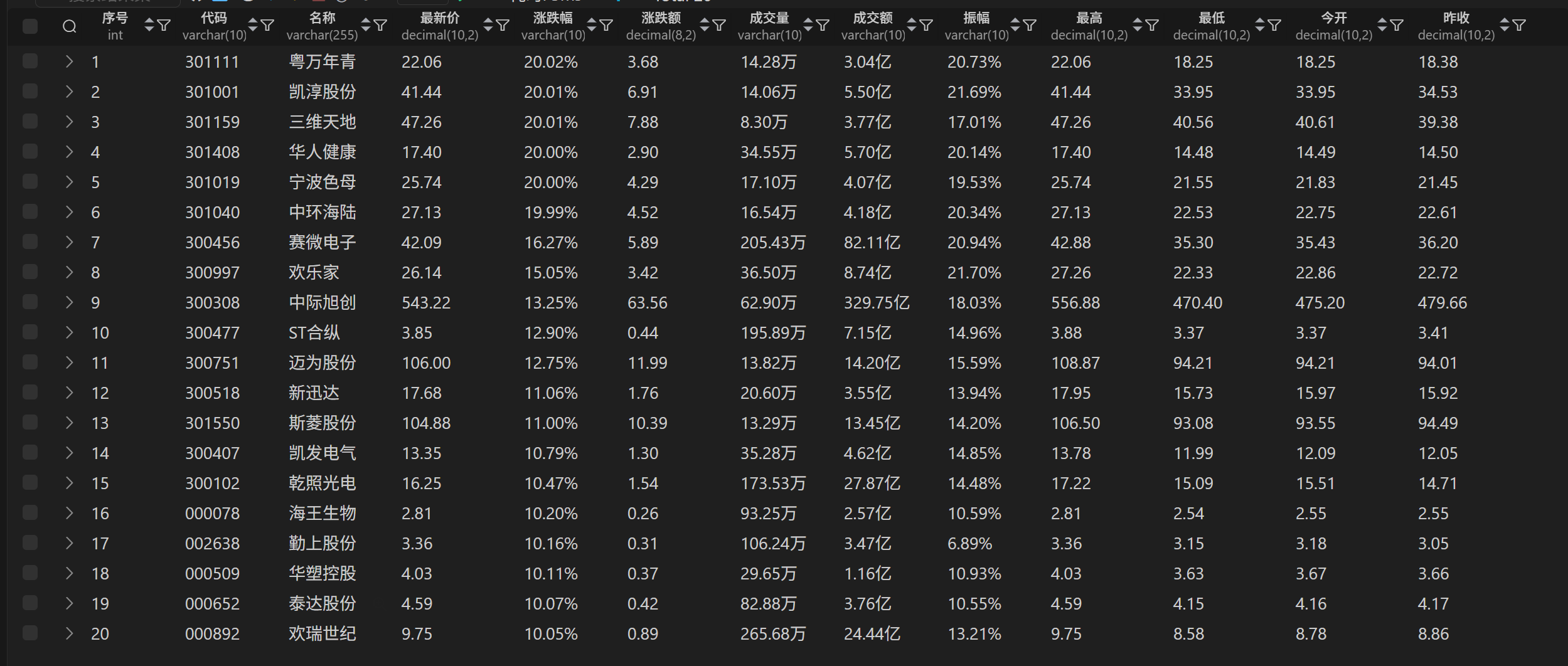
(2)心得体会
这个实验让我学会了selenium爬取网站的基本步骤,发现代码编写逻辑与我们真实的获取步骤基本一致,与bs4等需要抓包爬取方法差异很大。
作业2
要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
等待 HTML 元素等内容。
▪ 使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
二、实验完整过程
本次实验我爬取用户个人中心的课程的详细数据
导入所需库
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.edge.options import Options
import pymysql
import time
import re
数据库结构
CREATE TABLE IF NOT EXISTS mooc_courses (
id INT AUTO_INCREMENT PRIMARY KEY,
cCourse VARCHAR(500),
cCollege VARCHAR(200),
cTeacher VARCHAR(200),
cTeam VARCHAR(200),
cCount INT,
cProcess VARCHAR(100),
cBrief TEXT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
起始地址
self.driver.get('https://www.icourse163.org/')
首先先模拟用户登录
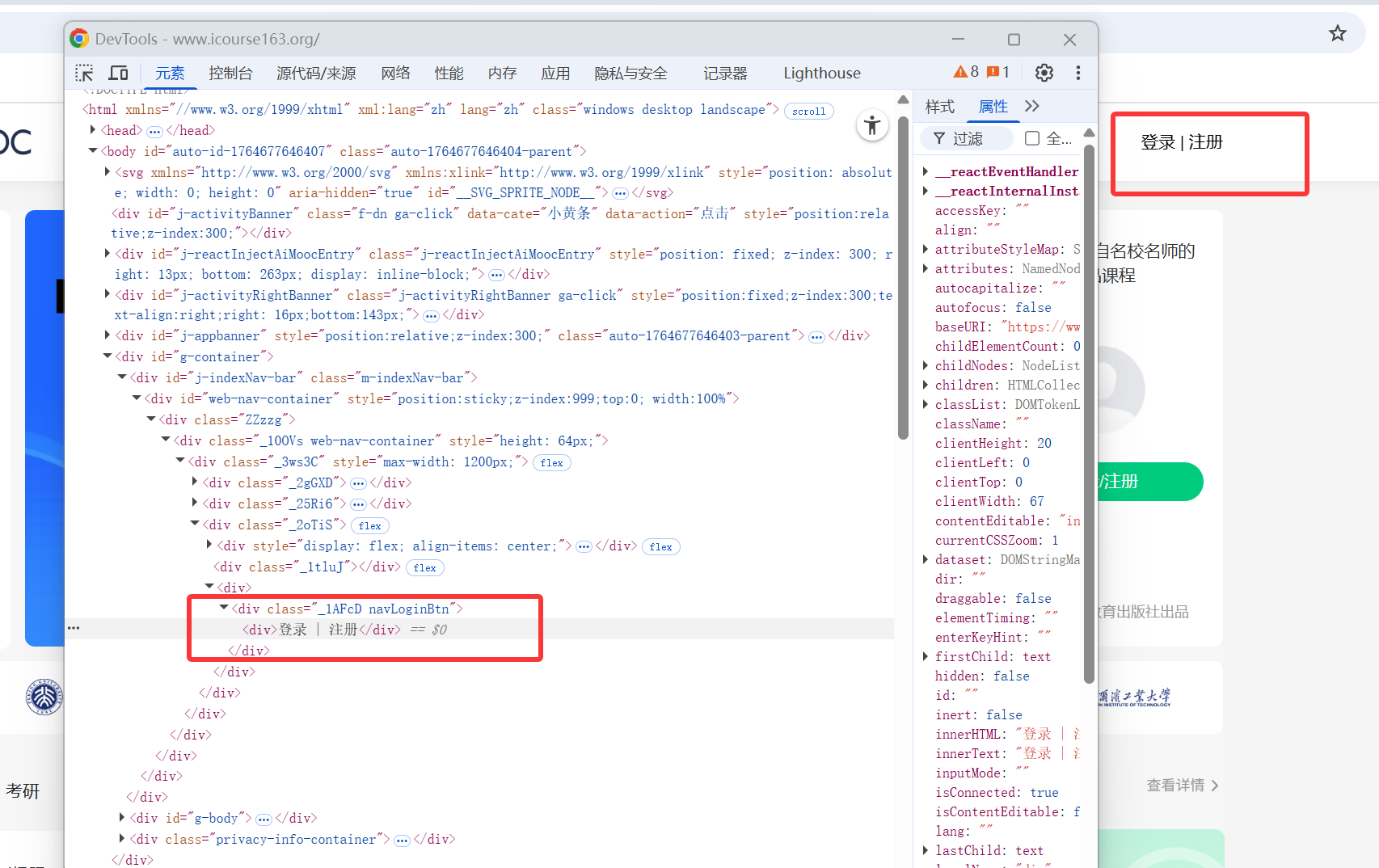
找到登录按键的xpath,点击等待登录窗口跳转出来
self.driver.maximize_window()
next_button = self.driver.find_element(By.XPATH, '//*[@id="web-nav-container"]/div/div/div/div[3]/div[3]/div/div')
next_button.click()
time.sleep(2)
然后依次输入账号密码,点击登录即可
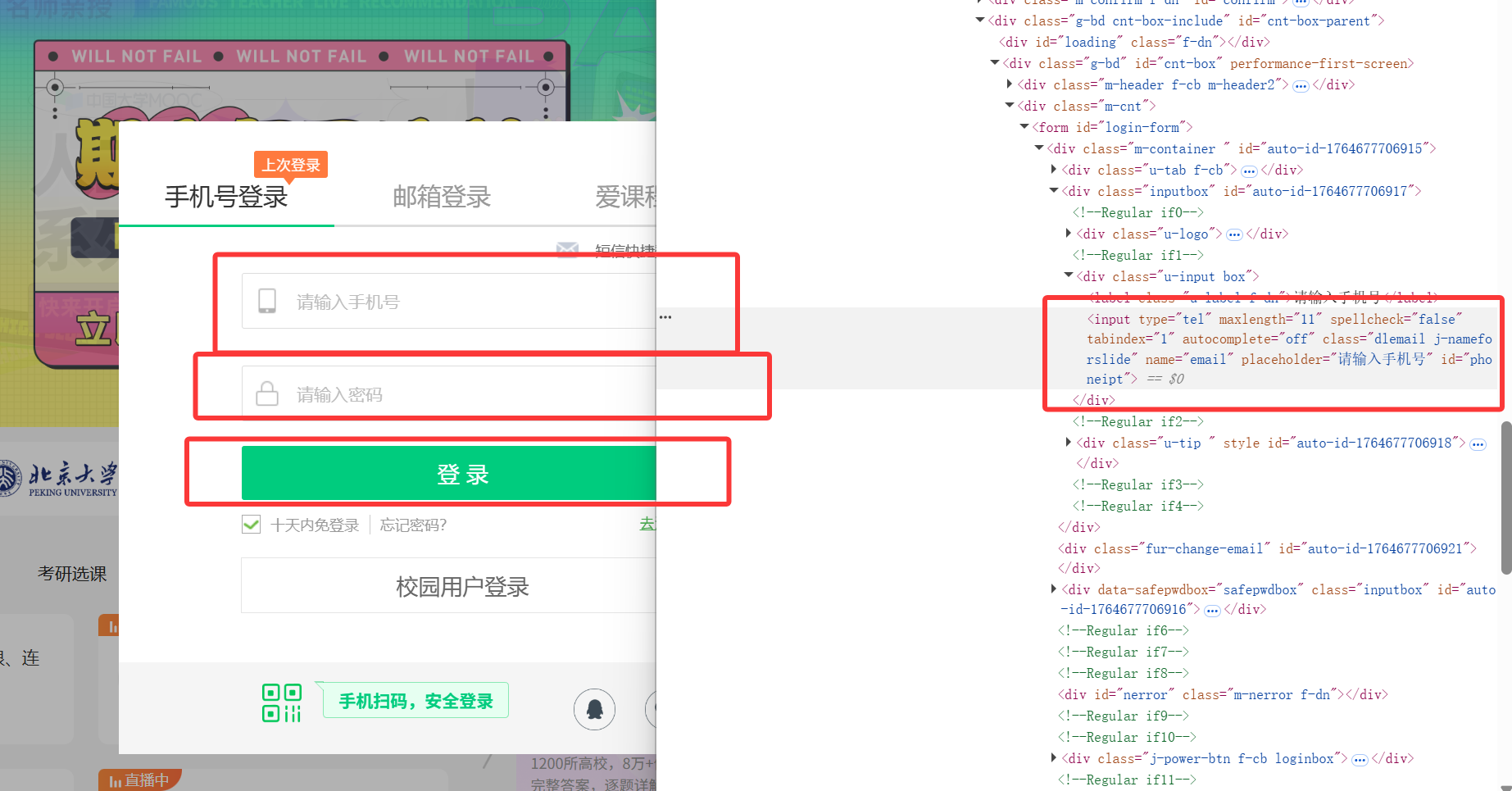
值得注意的是,因为登录窗口是在一个iframe里面的,如果不把句柄切换到iframe里,无法找到我们所需的元素
frame = self.driver.find_element(By.XPATH, '//*[@id="j-ursContainer-0"]/iframe')
self.driver.switch_to.frame(frame)
account = self.driver.find_element(By.ID, 'phoneipt').send_keys('18159379225')
password = self.driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]').send_keys("Happy181317")
logbutton = self.driver.find_element(By.XPATH, '//*[@id="submitBtn"]')
logbutton.click()
time.sleep(5)
登入后可以继续找进入个人中心的元素的xpath,进入个人中心
然后将所需的url都给记录下来

值得注意的是,因为进入个人中心会打开新窗口,所以要把句柄切换到新窗口
self.driver.switch_to.window(self.driver.window_handles[-1])
course_links = []
for i in range(1, 8):
course_xpath = f'//*[@id="j-coursewrap"]/div/div[1]/div[{i}]/div[4]/div[1]/a'
course_element=self.driver.find_element(By.XPATH,course_xpath)
course_url = course_element.get_attribute('href')
if course_url:
course_links.append(course_url)
有个每个课程介绍的url,接下来只需要按照之前的步骤,打开这个url,然后把所需的元素给获取下来就可以了
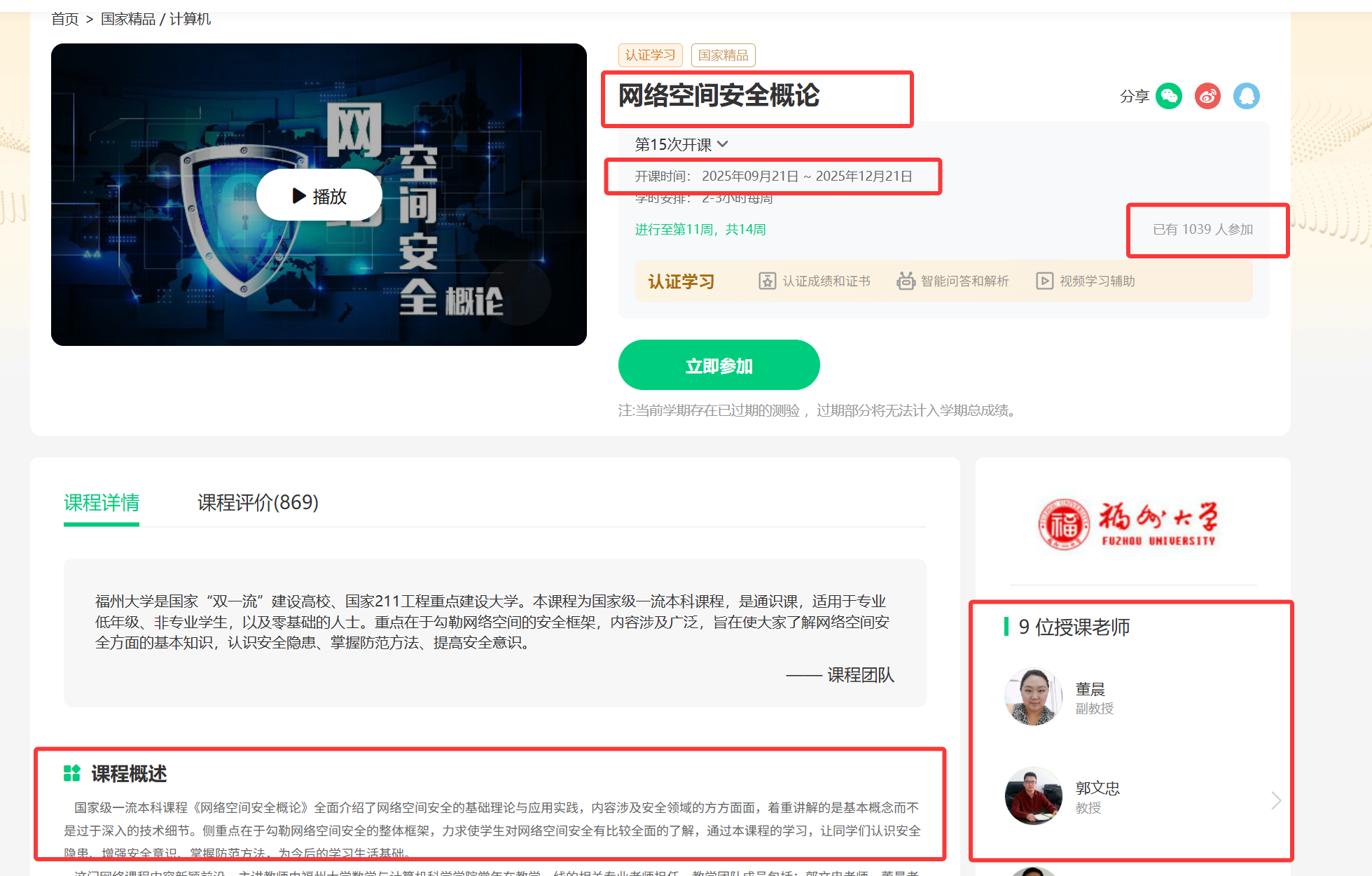
因为有的课程部分信息缺失,如没有写课程简介。
这时候可以用try-except捕获异常,填写缺失值
如下
# 爬取学院信息
try:
college_element = self.wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="j-teacher"]/div/a/img'))
)
course_data['cCollege'] = college_element.get_attribute('alt')
except Exception as e:
course_data['cCollege'] = 'None'
结果

(2)心得体会
这个任务让我熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
等待 HTML 元素等内容。
(1)在作业中,模拟用户登陆时代码一直报错,上网搜了后发现登录框是在iframe里面的,需要切换句柄(2)进入个人中心会新开一个窗口,也是一直找不到我需要的元素,搜了一下才知道也需要切换句柄
(3)直接复制浏览器给的xpath找不到元素,因为mooc元素的id是动态的,每一次加载分配的id都不一样。解决方法是自己写xpath
作业3
(1)要求:
• 掌握大数据相关服务,熟悉 Xshell 的使用
• 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部
分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
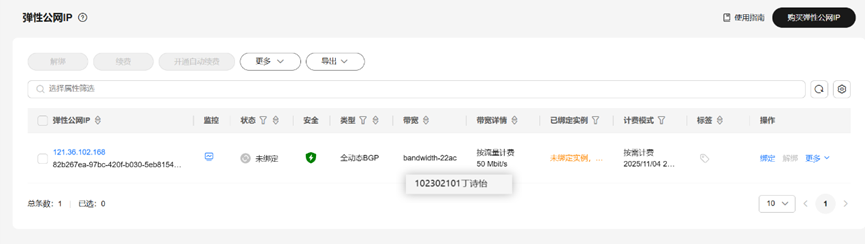
任务一:申请弹性公网IP
查看购买的弹性公网IP
返回到控制台后,点击刷新按钮可以看到已购买的弹性IP。
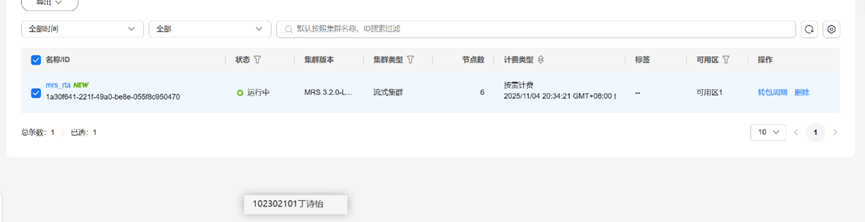
任务二:开通MapReduce服务
给集群的master节点绑定弹性IP
在集群页面点击“节点管理”,点击下箭头展开master_node_default_group节点组,点击master的节点名称进入master节点
选择“弹性公网IP”,点击“绑定弹性公网IP”
弹性公网IP绑定完毕
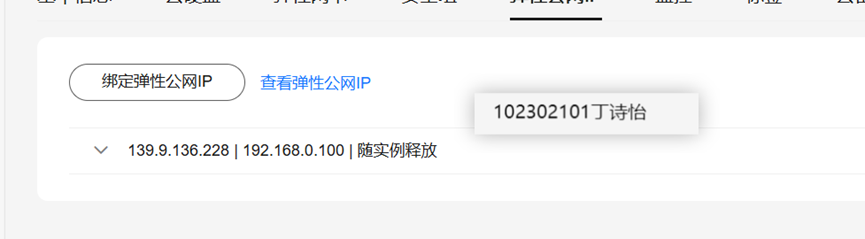
修改安全组规则
MRS服务到此购买并配置完成。
任务三:开通云数据库服务RDS
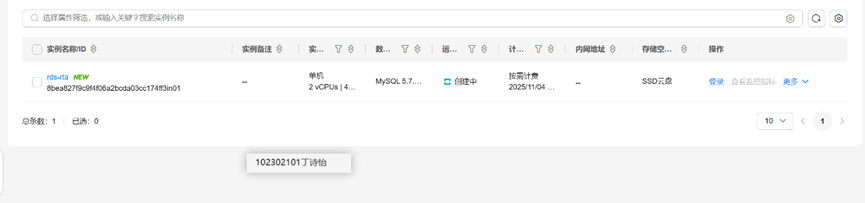
等待实例的状态变为“运行中”则实例创建完成。
配置MySQL实例
在内网连接界面向下滚动页面,在“安全组规则”中,选择“入方向规则”,然后点击“一键添加”。
弹出对话框点击“是”。
配置完成。
任务四:开通数据湖探索服务(DLI)
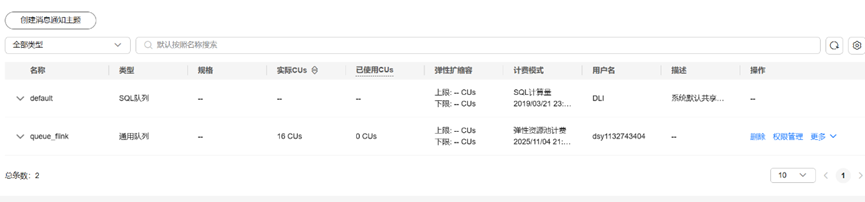
弹性资源池创建成功
队列创建成功。
服务授权
在“全局配置”中选择“服务授权”,勾选“跨源场景”(创建跨源连接需要)。
点击“更新委托权限”按钮。
配置跨源链接
DLI增强型跨源连接底层采用对等连接,直接打通DLI集群与数据源的vpc网络,通过点对点的方式实现数据互通。后续实验中DLI要读取MRS的Kafka中的数据,需要将DLI服务的网络和MRS的网络打通,所以需要进行跨源连接的配置。
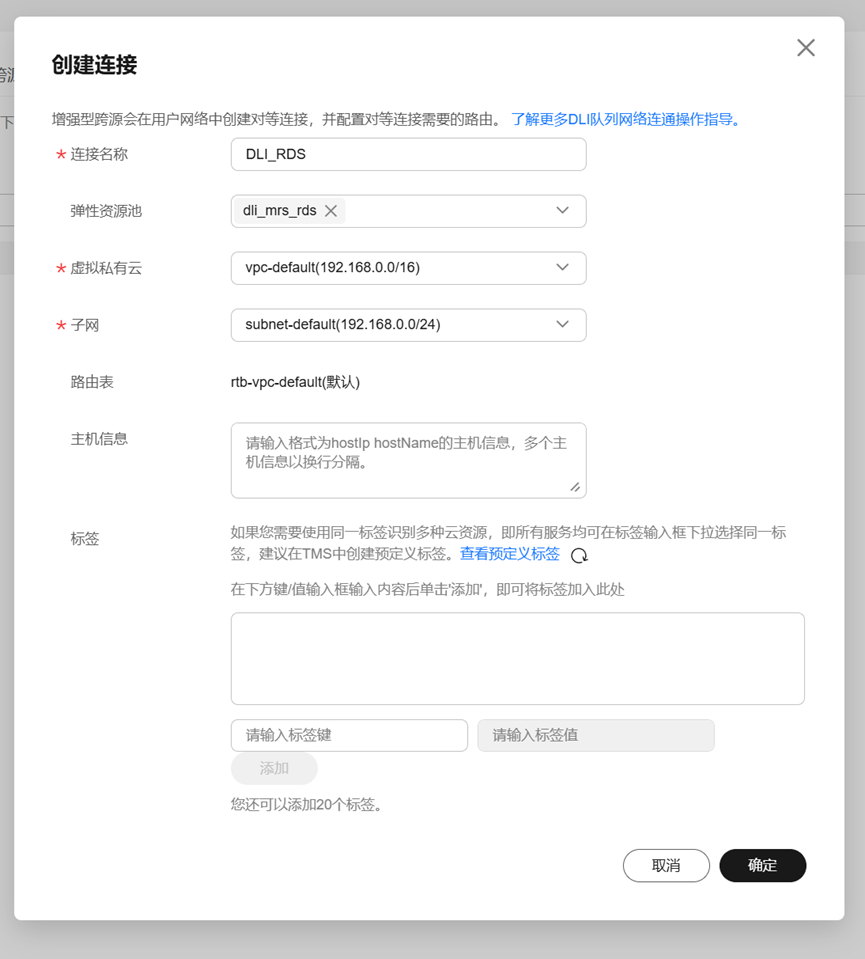
二、大数据实时分析开发实战
任务一:Python脚本生成测试数据
登录MRS的master节点服务器
本题直接使用终端ssh登录
编写Python脚本
进入/opt/client/目录,使用vi命令编写Python脚本:autodatagen.py
cd /opt/client/
vim autodatagen.py
复制下面的脚本代码
#coding:utf-8
###########################################
# rowkey:随机的两位数 + 当前时间戳,并要确保该rowkey在表数据中唯一。
# 列定义:行健,用户名,年龄,性别,商品ID,价格,门店ID,购物行为,电话,邮箱,购买日期
#421564974572,Sgxrp,20,woman,152121,297.64,313015,scan,15516056688,JbwLDQmzwP@qq.com,2019-08-01
#601564974572,Lbeuo,43,man,220902,533.13,313016,pv,15368953106,ezfrJSluoR@163.com,2019-08-05###########################################
import random
import string
import sys
import time
# 大小写字母
alphabet_upper_list = string.ascii_uppercase
alphabet_lower_list = string.ascii_lowercase
# 随机生成指定位数的字符串
def get_random(instr, length):
# 从指定序列中随机获取指定长度的片段并组成数组,例如:['a', 't', 'f', 'v', 'y']
res = random.sample(instr, length)
# 将数组内的元素组成字符串
result = ''.join(res)
return result
# 放置生成的并且不存在的rowkey
rowkey_tmp_list = []
# 制作rowkey
def get_random_rowkey():
import time
pre_rowkey = ""
while True:
# 获取00~99的两位数字,包含00与99
num = random.randint(00, 99)
# 获取当前10位的时间戳
timestamp = int(time.time())
# str(num).zfill(2)为字符串不满足2位,自动将该字符串补0
pre_rowkey = str(num).zfill(2) + str(timestamp)
if pre_rowkey not in rowkey_tmp_list:
rowkey_tmp_list.append(pre_rowkey)
break
return pre_rowkey
# 创建用户名
def get_random_name(length):
name = string.capwords(get_random(alphabet_lower_list, length))
return name
# 获取年龄
def get_random_age():
return str(random.randint(18, 60))
# 获取性别
def get_random_sex():
return random.choice(["woman", "man"])
# 获取商品ID
def get_random_goods_no():
goods_no_list = ["220902", "430031", "550012", "650012", "532120","230121","250983", "480071", "580016", "950013", "152121","230121"]
return random.choice(goods_no_list)
# 获取商品价格(浮点型)
def get_random_goods_price():
# 随机生成商品价格的整数位,1~999的三位数字,包含1与999
price_int = random.randint(1, 999)
# 随机生成商品价格的小数位,1~99的两位数字,包含1与99
price_decimal = random.randint(1, 99)
goods_price = str(price_int) +"." + str(price_decimal)
return goods_price
# 获取门店ID
def get_random_store_id():
store_id_list = ["313012", "313013", "313014", "313015", "313016","313017","313018", "313019", "313020", "313021", "313022","313023"]
return random.choice(store_id_list)
# 获取购物行为类型
def get_random_goods_type():
goods_type_list = ["pv", "buy", "cart", "fav","scan"]#点击、购买、加购、收藏、浏览
return random.choice(goods_type_list)
# 获取电话号码
def get_random_tel():
pre_list = ["130", "131", "132", "133", "134", "135", "136", "137", "138", "139", "147", "150",
"151", "152", "153", "155", "156", "157", "158", "159", "186", "187", "188"]
return random.choice(pre_list) + ''.join(random.sample('0123456789', 8))
# 获取邮箱名
def get_random_email(length):
alphabet_list = alphabet_lower_list + alphabet_upper_list
email_list = ["163.com", "126.com", "qq.com", "gmail.com","huawei.com"]
return get_random(alphabet_list, length) + "@" + random.choice(email_list)
# 获取商品购买日期(统计最近7天数据)
def get_random_buy_time():
buy_time_list = ["2019-08-01", "2019-08-02", "2019-08-03", "2019-08-04", "2019-08-05", "2019-08-06", "2019-08-07"]
return random.choice(buy_time_list)
# 生成一条数据
def get_random_record():
return get_random_rowkey() + "," + get_random_name(
5) + "," + get_random_age() + "," + get_random_sex() + "," + get_random_goods_no() + ","+get_random_goods_price()+ "," +get_random_store_id()+ "," +get_random_goods_type() + ","+ get_random_tel() + "," + get_random_email(
10) + "," +get_random_buy_time()
# 获取随机整数用于休眠
def get_random_sleep_time():
return random.randint(5, 10)
# 将记录写到文本中
def write_record_to_file():
# 覆盖文件内容,重新写入
f = open(sys.argv[1], 'w')
i = 0
while i < int(sys.argv[2]):
record = get_random_record()
f.write(record)
# 换行写入
f.write('\n')
i += 1
f.close()
if __name__ == "__main__":
write_record_to_file()
执行脚本测试
执行Python命令,测试生成100条数据
python autodatagen.py "/tmp/flume_spooldir/test.txt" 100
more /tmp/flume_spooldir/test.txt

任务二:配置Kafka
使用source命令进行环境变量的设置使得相关命令可用。
source /opt/Bigdata/client/bigdata_env

在kafka中创建topic
执行如下命令创建topic(--bootstrap-server替换成你的kafka的IP,如何获取IP请参见附录步骤)。
kafka-topics.sh --create --topic fludesc --partitions 1 --replication-factor 1 --bootstrap-server 192.174.2.105:9092
查看topic信息
kafka-topics.sh --list --bootstrap-server 192.174.2.105:9092

任务三:安装Flume客户端
执行以下命令重启Flume的服务。
cd /opt/FlumeClient/fusioninsight-flume-1.11.0
sh bin/flume-manage.sh restart

服务重启成功,安装结束!
任务四:配置Flume采集数据
在conf目录下编辑文件properties.properties
vi conf/properties.properties
加入如下内容
client.sources = s1
client.channels = c1
client.sinks = sh1
# the source configuration of s1
client.sources.s1.type = spooldir
client.sources.s1.spoolDir = /tmp/flume_spooldir
client.sources.s1.fileSuffix = .COMPLETED
client.sources.s1.deletePolicy = never
client.sources.s1.trackerDir = .flumespool
client.sources.s1.ignorePattern = ^(.)*\\.tmp$
client.sources.s1.batchSize = 1000
client.sources.s1.inputCharset = UTF-8
client.sources.s1.deserializer = LINE
client.sources.s1.selector.type = replicating
client.sources.s1.fileHeaderKey = file
client.sources.s1.fileHeader = false
client.sources.s1.basenameHeader = true
client.sources.s1.basenameHeaderKey = basename
client.sources.s1.deserializer.maxBatchLine = 1
client.sources.s1.deserializer.maxLineLength = 2048
client.sources.s1.channels = c1
# the channel configuration of c1
client.channels.c1.type = memory
client.channels.c1.capacity = 10000
client.channels.c1.transactionCapacity = 1000
client.channels.c1.channlefullcount = 10
client.channels.c1.keep-alive = 3
client.channels.c1.byteCapacityBufferPercentage = 20
# the sink configuration of sh1
client.sinks.sh1.type = org.apache.flume.sink.kafka.KafkaSink
client.sinks.sh1.kafka.topic = fludesc
client.sinks.sh1.flumeBatchSize = 1000
client.sinks.sh1.kafka.producer.type = sync
client.sinks.sh1.kafka.bootstrap.servers = 192.174.2.105:9092
client.sinks.sh1.kafka.security.protocol = PLAINTEXT
client.sinks.sh1.requiredAcks = 0
client.sinks.sh1.channel = c1
进入Python脚本所在目录,执行python脚本,再生成一份数据。
cd /opt/client/
python autodatagen.py "/tmp/flume_spooldir/test.txt" 100
查看原窗口,可以看到已经消费出了数据:

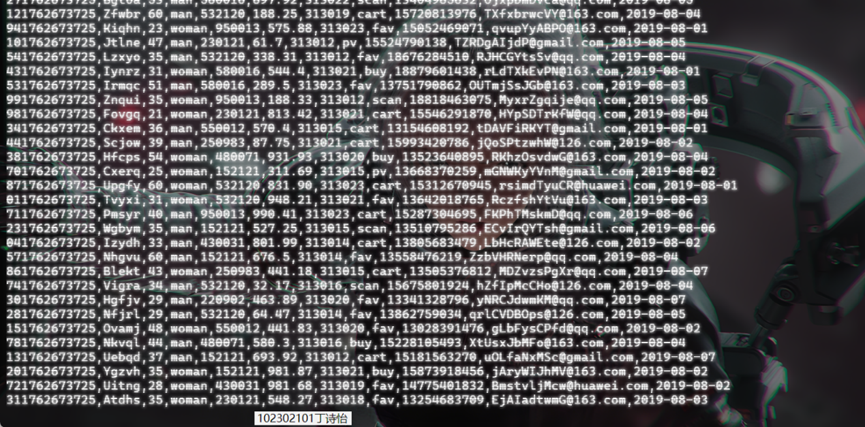
有数据产生,表明Flume到Kafka目前是打通的。
测试完毕,在新打开的窗口输入exit关闭窗口,在原窗口输入 Ctrl+c退出进程。
(2)心得体会
此次实验不仅提升了我对 Linux 命令、SQL 语句、Flink SQL 开发的实操能力,更让我理解了实时数据分析的核心逻辑与华为云生态下各服务的协同机制。从数据采集到可视化呈现,每个环节环环相扣,让我对 “流处理”“存算分离” 等概念有了更直观的认知。未来,我将继续深入学习大数据实时处理技术,提升复杂场景下的问题排查与系统优化能力,为应对实际业务中的实时数据处理需求积累经验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号