数据采集与融合技术作业3
作业1
(1)指定一个网站,爬取这个网站中的所有图片,例如中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
一、爬取前的准备:工具与环境
核心库介绍
- requests:发送 HTTP 请求,获取网页源码和图片二进制数据
- BeautifulSoup4:解析 HTML 文档,提取图片 URL
- os:处理文件路径与目录创建
- threading:实现多线程并发爬取(控制并发数避免被封 IP)
- lxml:HTML 解析器
二、实验完整过程
单线程方式爬取流程:
- 发送请求,获取目标网页的 HTML 源码
- 解析 HTML,提取所有
标签的src属性(即图片 URL)
- 遍历图片 URL,逐个下载并保存到本地
导入所需库
import requests
from bs4 import BeautifulSoup
import os
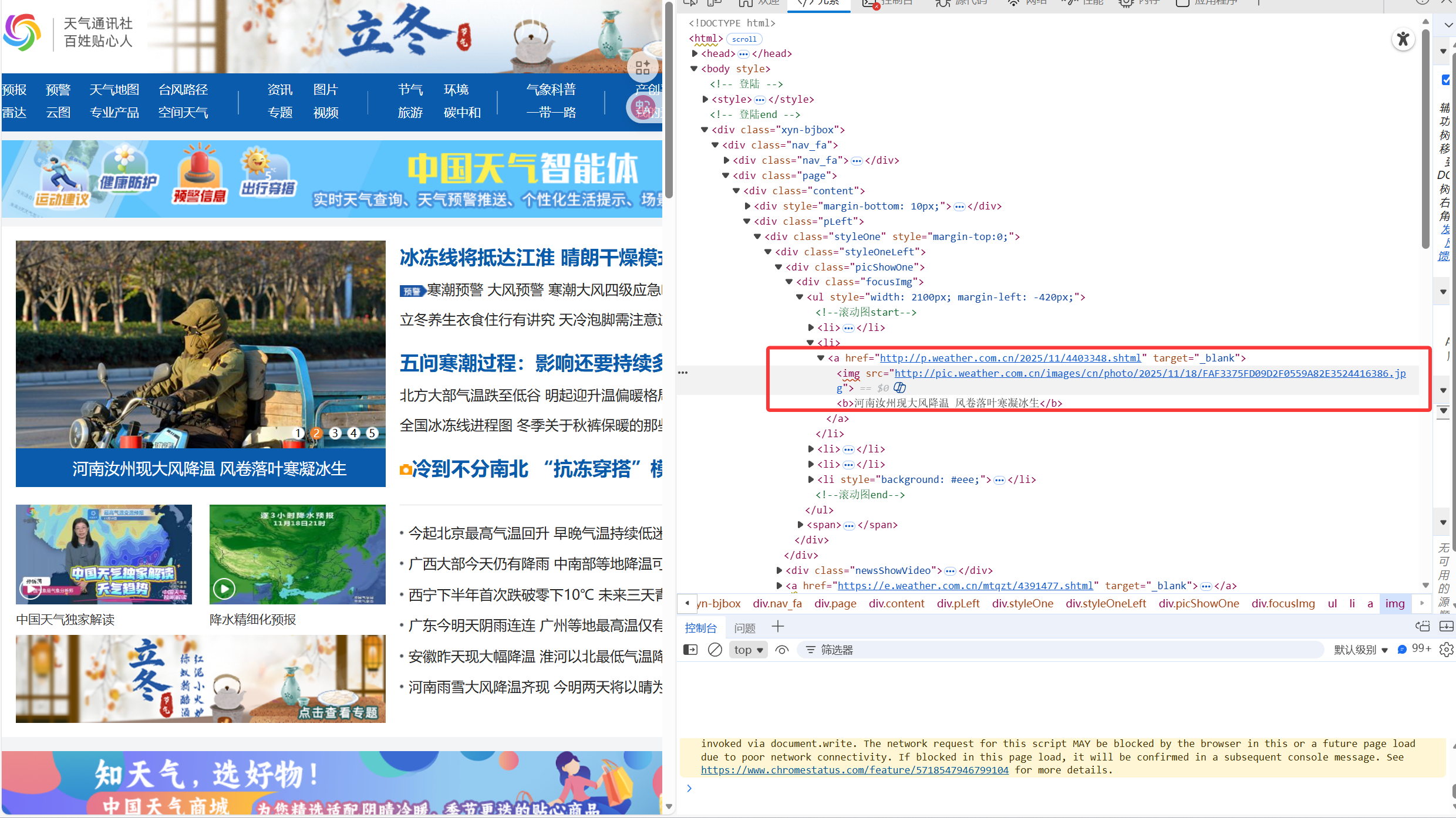
图片url都是存在标签里面的src属性中
提取图片 URL,只需要提取所有标签的src属性
def get_image_urls(url, base_url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
img_tags = soup.find_all('img')
img_urls = []
for img in img_tags:
img_src = img.get('src')
if img_src:
if not img_src.startswith('http'):
img_src = base_url + img_src
img_urls.append(img_src)
return img_urls
下载并保存图片
def download_image(url, save_dir):
if not os.path.exists(save_dir):
os.makedirs(save_dir)
file_name = url.split('/')[-1]
response = requests.get(url)
with open(os.path.join(save_dir, file_name), 'wb') as f:
f.write(response.content)
print(f"下载完成:{url}")
主函数
if __name__ == "__main__":
target_url = "http://www.weather.com.cn"
base_url = "http://www.weather.com.cn"
save_directory = "作业1/images1"
image_urls = get_image_urls(target_url, base_url)
for url in image_urls:
download_image(url, save_directory)
完整代码
import requests
from bs4 import BeautifulSoup
import os
def get_image_urls(url, base_url):
"""
解析目标网页,提取所有图片的完整URL
:param url: 目标网页的URL(需爬取图片的网页地址)
:param base_url: 网站基础URL(用于补全相对路径的图片地址)
:return: 包含所有完整图片URL的列表
"""
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
img_tags = soup.find_all('img')
img_urls = []
for img in img_tags:
img_src = img.get('src')
if img_src:
if not img_src.startswith('http'):
img_src = base_url + img_src
img_urls.append(img_src)
return img_urls
def download_image(url, save_dir):
"""
根据图片URL下载图片,并保存到本地指定目录
:param url: 单张图片的完整URL
:param save_dir: 图片保存到本地的目录路径
"""
if not os.path.exists(save_dir):
os.makedirs(save_dir)
file_name = url.split('/')[-1]
response = requests.get(url)
with open(os.path.join(save_dir, file_name), 'wb') as f:
f.write(response.content)
print(f"下载完成:{url}")
if __name__ == "__main__":
target_url = "http://www.weather.com.cn"
base_url = "http://www.weather.com.cn"
save_directory = "作业1/images1"
image_urls = get_image_urls(target_url, base_url)
for url in image_urls:
download_image(url, save_directory)
多线程方式爬取流程:
信号量定义
# 用于限制并发线程数的信号量(避免请求过多被封)
MAX_WORKERS = 5
semaphore = threading.Semaphore(MAX_WORKERS)
完整代码:
import requests
from bs4 import BeautifulSoup
import os
import threading
MAX_WORKERS = 5
semaphore = threading.Semaphore(MAX_WORKERS)
def get_image_urls(url, base_url):
"""
解析目标网页,提取所有图片的完整URL
:param url: 目标网页的URL(需爬取图片的网页地址)
:param base_url: 网站基础URL(用于补全相对路径格式的图片地址)
:return: 包含所有完整图片URL的列表
"""
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
img_tags = soup.find_all('img')
img_urls = []
for img in img_tags:
img_src = img.get('src')
if img_src:
if not img_src.startswith('http'):
img_src = base_url + img_src
img_urls.append(img_src)
return img_urls
def download_image(url, save_dir):
"""
多线程下载单张图片(带信号量并发控制、异常处理、流式下载)
:param url: 单张图片的完整URL
:param save_dir: 图片保存到本地的目录路径
"""
with semaphore:
try:
if not os.path.exists(save_dir):
os.makedirs(save_dir)
file_name = url.split('/')[-1].split('?')[0]
file_name = file_name[:50]
response = requests.get(url, timeout=15, stream=True)
response.raise_for_status()
save_path = os.path.join(save_dir, file_name)
with open(save_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
print(f"下载完成:{url}")
except Exception as e:
print(f"下载失败 {url}:{e}")
if __name__ == "__main__":
target_url = "http://www.weather.com.cn"
base_url = "http://www.weather.com.cn"
save_directory = "作业1/images2"
img_urls = get_image_urls(target_url, base_url)
threads = []
# 创建线程对象:指定线程执行的函数、函数参数、线程名称
for url in img_urls:
thread = threading.Thread(
target=download_image,
args=(url, save_directory),
name=f"Downloader-{len(threads)+1}"
)
threads.append(thread)
thread.start()
# 等待所有线程执行完成
for thread in threads:
thread.join()
两个程序爬到的结果都如下
(2)心得体会
本次作业让我掌握了 requests 库发送 HTTP 请求、BeautifulSoup4 解析 HTML 文档的基础流程。通过提取标签的src属性获取图片 URL 时,深刻理解了相对路径与绝对路径的差异,学会了用基础 URL 补全相对路径的方法,避免因路径错误导致的下载失败。
作业2
- 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath +MySQL 数据库存储技术路线爬取股票相关信息。
- 候选网站:
东方财富网: https://www.eastmoney.com/
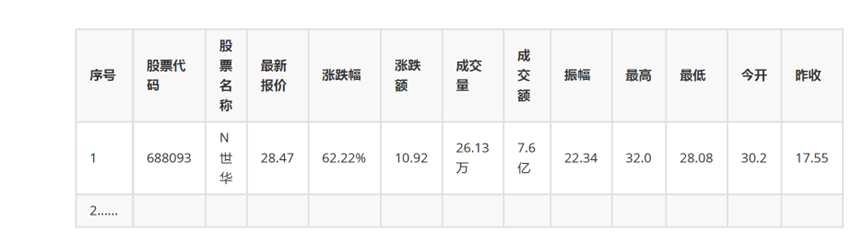
新浪股票: http://finance.sina.com.cn/stock/ - 输出信息: MySQL 数据库存储和输出格式如下,表头应是英文命名例如:序号 id,股票代码: bStockNo……,由同学们自行定义设计表头
一、爬取前的准备:工具与环境
技术栈选择
- Scrapy:强大的 Python 爬虫框架,用于数据提取和处理流程管理
- SQLite:轻量级数据库,适合存储中小型数据集
- Pandas:数据分析库,用于数据展示和后续分析
- 正则表达式:用于从文本中提取 JSON 数据片段
项目结构
StockSpider/
├── StockSpider/
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
├── run.py
└── spiders/
├── __init__.py
└── eastmoney_spider.py
二、实验完整过程
数据结构定义(items.py)
把需要输出的字段都存到StockItem类中
import scrapy
class StockItem(scrapy.Item):
"""股票数据Item定义,对应原数据字段"""
serial_num = scrapy.Field() # 序号
stock_code = scrapy.Field() # 股票代码
stock_name = scrapy.Field() # 股票名称
latest_price = scrapy.Field() # 最新价格
price_change = scrapy.Field() # 涨跌额
price_change_rate = scrapy.Field() # 涨跌幅
volume = scrapy.Field() # 成交量
turnover = scrapy.Field() # 成交额
amplitude = scrapy.Field() # 振幅
highest_price = scrapy.Field() # 最高
lowest_price = scrapy.Field() # 最低
opening_price = scrapy.Field() # 今开
previous_close = scrapy.Field() # 昨收
爬虫逻辑与作业2的逻辑一样
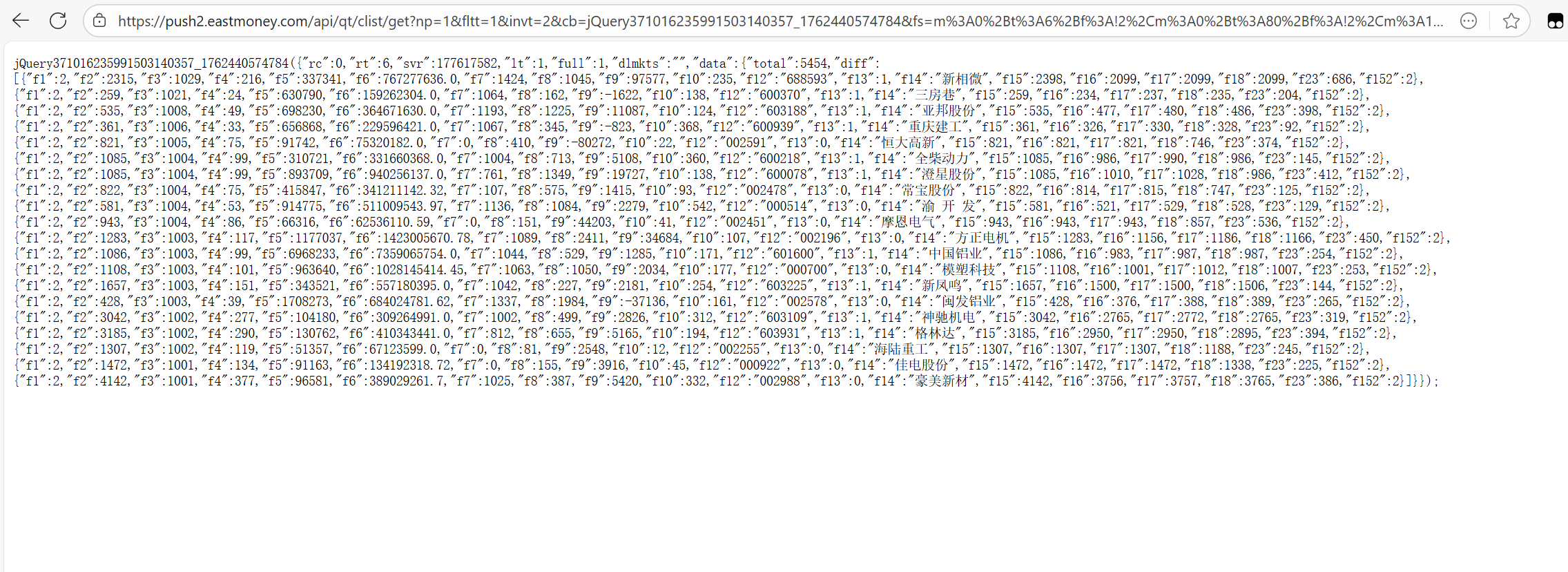
将源码存到本地文件,避免多次访问给网站造成骚扰
爬虫实现(eastmoney_spider.py)
import scrapy
import re
import json
import os
from datetime import datetime
from StockSpider.items import StockItem
class StockSpider(scrapy.Spider):
name = 'stock'
allowed_domains = []
# 配置文件路径和页数
custom_settings = {
'FILE_PATH': '股票源码.txt',
'TOTAL_PAGES': 1
}
cnt=1
def start_requests(self):
"""开始请求"""
file_path = self.settings.get('FILE_PATH')
if not os.path.exists(file_path):
self.logger.error(f"本地文件不存在:{file_path}")
return
# 模拟请求,将文件内容作为响应传递
with open(file_path, 'r', encoding='utf-8') as f:
file_content = f.read()
# 为每一页生成一个"响应"
total_pages = self.settings.get('TOTAL_PAGES', 1)
for page_num in range(1, total_pages + 1):
yield scrapy.Request(
url=f'file:///{os.path.abspath(file_path)}?page={page_num}',
callback=self.parse,
meta={'page_num': page_num, 'file_content': file_content}
)
def parse(self, response):
"""解析本地文件内容"""
page_num = response.meta.get('page_num')
source_content = response.meta.get('file_content')
self.logger.info(f"开始解析第{page_num}页数据")
pat = r'"diff":\[(.*?)\]'
data_str_list = re.compile(pat, re.S).findall(source_content)
if not data_str_list or data_str_list[0].strip() == "":
self.logger.warning(f"第{page_num}页无有效数据")
return
try:
# 解析JSON数据
data_str = data_str_list[0]
data = json.loads(f"[{data_str}]")
for item in data:
stock_item = StockItem()
stock_item['serial_num']=self.cnt
self.cnt+=1
stock_item['stock_code'] = item.get('f12', '')
stock_item['stock_name'] = item.get('f14', '')
stock_item['latest_price'] = round(item.get('f2', 0)/100, 2)
stock_item['price_change'] = f"{round(item.get('f4', 0)/100, 2)}"
stock_item['price_change_rate'] = f"{round(item.get('f3', 0)/100, 2)}%"
stock_item['volume'] = f"{round(item.get('f5', 0)/10000, 2)}万"
stock_item['turnover'] = f"{round(item.get('f6', 0)/1e8, 2)}亿"
stock_item['amplitude'] = round(item.get('f7', 0)/100, 2)
stock_item['highest_price'] = round(item.get('f15', 0)/100, 2)
stock_item['lowest_price'] = round(item.get('f16', 0)/100, 2)
stock_item['opening_price'] = round(item.get('f17', 0)/100, 2)
stock_item['previous_close'] = round(item.get('f18', 0)/100, 2)
yield stock_item
self.logger.info(f"第{page_num}页解析完成,共提取{len(data)}条数据")
except json.JSONDecodeError as e:
self.logger.error(f"第{page_num}页JSON解析失败: {e}")
except Exception as e:
self.logger.error(f"第{page_num}页解析异常: {e}")
数据处理管道(pipelines.py)
我实现了两个管道:一个用于数据库存储,另一个用于 DataFrame 展示。
数据库存储
import sqlite3
from scrapy.exceptions import DropItem
from datetime import datetime
class StockScraperPipeline:
"""股票数据处理管道:存储到SQLite数据库"""
def open_spider(self, spider):
"""爬虫启动时初始化数据库连接"""
self.conn = sqlite3.connect('local_stock_data.db')
self.cursor = self.conn.cursor()
self.create_table()
def create_table(self):
"""创建股票数据表"""
create_sql = '''
CREATE TABLE IF NOT EXISTS local_stock_market (
id INTEGER PRIMARY KEY AUTOINCREMENT,
serial_num INTEGER NOT NULL,
stock_code TEXT NOT NULL UNIQUE,
stock_name TEXT NOT NULL,
latest_price FLOAT NOT NULL,
price_change TEXT NOT NULL,
price_change_rate TEXT NOT NULL,
volume TEXT NOT NULL,
turnover TEXT NOT NULL,
amplitude FLOAT NOT NULL,
highest_price FLOAT NOT NULL,
lowest_price FLOAT NOT NULL,
opening_price FLOAT NOT NULL,
previous_close FLOAT NOT NULL
)
'''
try:
self.cursor.execute(create_sql)
self.conn.commit()
except Exception as e:
print(f"创建数据表失败: {e}")
raise # 建表失败直接终止爬虫
def process_item(self, item, spider):
"""处理每一条股票数据并插入数据库"""
try:
# 数据非空校验
required_fields = ['serial_num', 'stock_code', 'stock_name', 'latest_price']
for field in required_fields:
if not item.get(field) and item.get(field) != 0: # 允许 0 值(如价格为0)
raise ValueError(f"关键字段 '{field}' 为空,数据无效:{dict(item)}")
# 插入数据
insert_sql = '''
INSERT OR IGNORE INTO local_stock_market (
serial_num, stock_code, stock_name, latest_price, price_change,
price_change_rate, volume, turnover, amplitude, highest_price,
lowest_price, opening_price, previous_close
) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
'''
# 构造参数元组
params = (
item['serial_num'],
item['stock_code'],
item['stock_name'],
item['latest_price'],
item['price_change'],
item['price_change_rate'],
item['volume'],
item['turnover'],
item['amplitude'],
item['highest_price'],
item['lowest_price'],
item['opening_price'],
item['previous_close']
)
self.cursor.execute(insert_sql, params)
self.conn.commit()
return item
except sqlite3.IntegrityError as e:
# 处理唯一约束冲突
raise DropItem(f"数据重复,已丢弃:{item}")
except ValueError as e:
# 处理数据校验失败
print(f"数据无效: {e}")
raise DropItem(f"数据无效,已丢弃:{item}")
except Exception as e:
# 其他未知错误
print(f"插入数据失败: {e} - 数据详情:{dict(item)}")
raise DropItem(f"处理股票数据失败: {item}")
def close_spider(self, spider):
"""爬虫关闭时关闭数据库连接"""
try:
self.conn.close()
print("数据库连接已关闭")
except Exception as e:
print(f"关闭数据库连接失败: {e}")
DataFrame 展示
class StockDataFramePipeline(object):
"""额外管道:收集所有数据并输出DataFrame表格"""
def open_spider(self, spider):
self.all_items = []
def process_item(self, item, spider):
self.all_items.append(dict(item))
return item
def close_spider(self, spider):
"""爬虫结束后输出DataFrame表格"""
print("\n" + "-"*50)
print(f"数据收集完成,共收集 {len(self.all_items)} 条记录")
print("-"*50)
if not self.all_items:
print("未收集到任何有效股票数据")
return
import pandas as pd
columns = [
"serial_num", "stock_code", "stock_name", "latest_price",
"price_change", "price_change_rate", "volume", "turnover",
"amplitude", "highest_price", "lowest_price", "opening_price",
"previous_close"
]
# 创建DataFrame并处理数据类型
df = pd.DataFrame(self.all_items, columns=columns)
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 200)
pd.set_option('display.precision', 2)
# 输出格式化表格
print("\n" + "="*200)
print("股票数据汇总表")
print("="*200)
print(df.to_string(index=False, col_space=12))
print(f"\n共提取 {len(df)} 条股票数据,已保存到 local_stock_data.db 数据库")
print("="*100)
配置与启动
后面的数字代表优先级,应当让存储数据库管道优先级更高(先执行),然后再输出到终端
settings.py
FEED_EXPORT_ENCODING = "utf-8"
ITEM_PIPELINES = {
'StockSpider.pipelines.StockScraperPipeline': 300,
'StockSpider.pipelines.StockDataFramePipeline': 400,
}
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl stock -s LOG_ENABLED=False".split())
结果
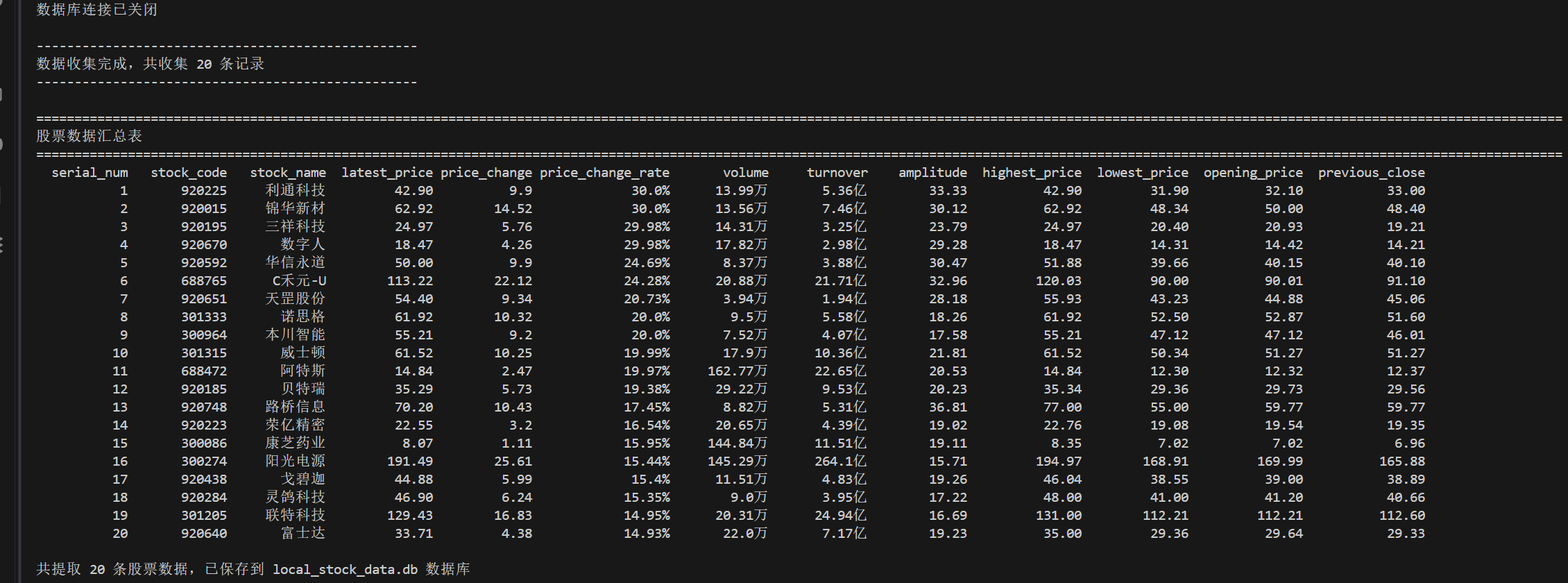
(2)心得体会
- 初期对 Scrapy 的工作流程不熟悉,不清楚 Item 如何传递给 Pipeline,通过查看官方文档与调试代码,理解了 “yield Item” 后数据自动传入 Pipeline 的机制,体会到框架化开发的便捷性。
- 正则表达式提取 JSON 数据时,因未考虑换行符导致匹配失败,后续添加re.S参数( DOTALL 模式),让.能够匹配换行符,解决了该问题,让我意识到正则表达式的匹配模式需要根据数据格式灵活调整。
- 数据格式转换(如将原始数据除以 100 转换为正常价格)时,需注意数据类型的一致性,避免出现类型错误,这让我认识到结构化数据处理中 “数据清洗” 的重要性。
作业3
- 要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用 scrapy 框架 + Xpath+MySQL 数据库存储技术路线爬取外汇网站数据。
- 候选网站:招商银行网: https://www.boc.cn/sourcedb/whpj/
技术栈
- Python 3.11
- Scrapy:强大的 Python 爬虫框架
- SQLite:轻量级关系型数据库
项目结构
forex/
├── forex/
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
├── run.py
└── spiders/
├── __init__.py
└── myspider.py
二、实验完整过程
观察网页很容易得到如下的爬取逻辑,方法与上面一个类似,不再赘述
定义数据结构(items.py)
import scrapy
class ForexItem(scrapy.Item):
Currency = scrapy.Field() # 货币名称
TBP = scrapy.Field() # 现汇买入价
CBP = scrapy.Field() # 现钞买入价
TSP = scrapy.Field() # 现汇卖出价
CSP = scrapy.Field() # 现钞卖出价
Time = scrapy.Field() # 时间
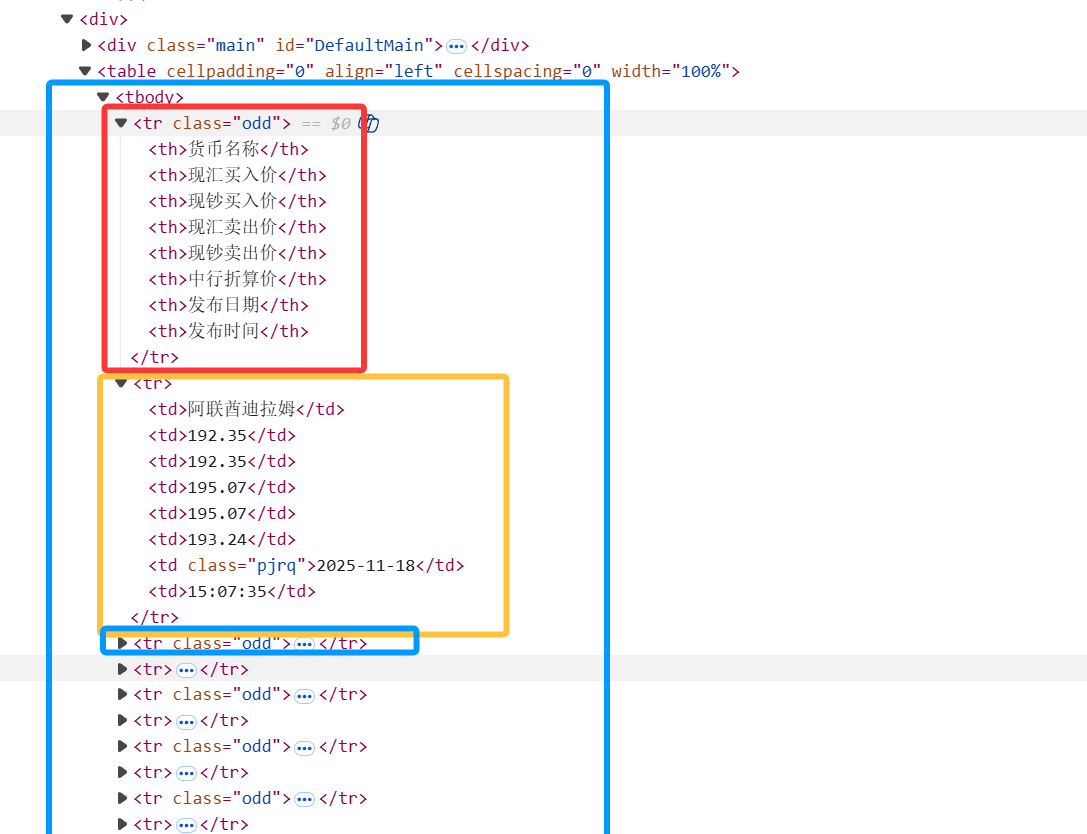
第一个tr是表头,接下来每个tr中都包含我们所需要的一个ForexItem对象
编写爬虫(myspider.py)
import scrapy
from datetime import datetime
from forex.items import ForexItem
class BocSpider(scrapy.Spider):
name = 'boc'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
# 提取外汇数据行,跳过表头行
rows = response.xpath('//div[@class="main"]/following-sibling::table/tr[position()>1]')
for row in rows:
item = ForexItem()
item['Currency'] = row.xpath('td[1]/text()').extract_first()
item['TBP'] = row.xpath('td[2]/text()').extract_first()
item['CBP'] = row.xpath('td[3]/text()').extract_first()
item['TSP'] = row.xpath('td[4]/text()').extract_first()
item['CSP'] = row.xpath('td[5]/text()').extract_first()
item['Time'] = row.xpath('td[8]/text()').extract_first()
yield item
数据处理与存储(pipelines.py)
import sqlite3
from scrapy.exceptions import DropItem
class SqlitePipeline:
def open_spider(self, spider):
# 连接数据库并创建表
self.conn = sqlite3.connect('forex_data.db')
self.cursor = self.conn.cursor()
create_table_sql = '''
CREATE TABLE IF NOT EXISTS forex_data (
id INTEGER PRIMARY KEY AUTOINCREMENT,
Currency TEXT NOT NULL,
TBP REAL,
CBP REAL,
TSP REAL,
CSP REAL,
Time TEXT
)
'''
# 打印表头
print(f" {'Currency':<15} {'TBP':<10} {'CBP':<10} {'TSP':<10} {'CSP':<10} {'Time':<10} ")
self.cursor.execute(create_table_sql)
self.conn.commit()
def process_item(self, item, spider):
# 终端格式化输出
print(f" {item['Currency']:<15} {item['TBP']:<10} {item['CBP']:<10} {item['TSP']:<10} {item['CSP']:<10} {item['Time']:<10} ")
# 插入数据到数据库
insert_sql = '''
INSERT INTO forex_data (Currency, TBP, CBP, TSP, CSP, Time)
VALUES (?, ?, ?, ?, ?, ?)
'''
self.cursor.execute(insert_sql, (
item['Currency'],
item['TBP'],
item['CBP'],
item['TSP'],
item['CSP'],
item['Time']
))
self.conn.commit()
return item
def close_spider(self, spider):
# 关闭数据库连接
self.cursor.close()
self.conn.close()
项目设置(settings.py)
ITEM_PIPELINES = {
"forex.pipelines.SqlitePipeline": 300,
}
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl boc -s LOG_ENABLED=False".split())
结果:
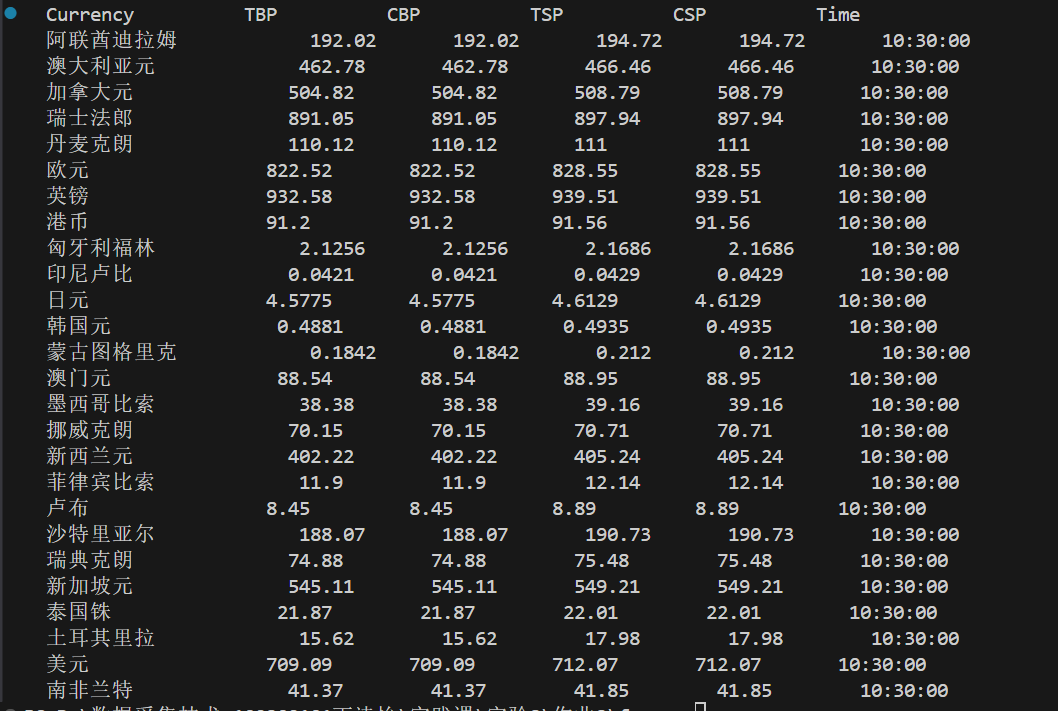
(2)心得体会
- 初期 XPath 表达式未考虑表头行,导致将表头数据也爬取下来,后续通过position()>1筛选掉表头行,解决了该问题,让我意识到解析时必须关注节点的位置关系。
- 部分外汇数据的买入价 / 卖出价可能为空,未添加异常处理导致数据库插入时出现警告,后续可在 Pipeline 中添加数据类型转换与空值处理,进一步提升爬虫的鲁棒性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号