卷积神经网络的发展及原理
1.人工神经网络发展
不同的学科领域对神经网络有着不同的理解,因此,关于神经网络的定义,在科学界存在许多不同的见解。目前使用最广泛的是T.Kohonen的定义,即神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的结构能够模拟生物神经系统对真实世界物体所作出的交互反应。
神经网络的理论研究通常认为是从1943年McCulloch 和 Pitts的研究文章《神经活动的逻辑演算》出版后开始的,文中率先提出了神经元的数学模型-M-P模型,并且证明了简单的神经网络在理论上可以逼近任意算数关系或逻辑函数,该文章被广泛传播并且产生了巨大的反响。
1949年,加拿大心里学家Hebb发表了《行为的组织》一书,强调了由于神经元的作用,心理调节在动物中是普遍存在的。这一观点并不是创新性的,但Hebb据此第一次提出了神经元突触的特定学习规律,并使用此学习规律定性地对一些心理学实验结果作了解释,此学习规律即后来所谓的Hebb学习法。
1958年,F.Rosenblatt和C.Wightman 等人提出了第一个具有学习型神经网络特点的模型--Mark I 感知器(Perceprton)模型,并证明了通过迭代改变连接权值的学习算法具有收敛性,建立了第一个真正的人工神经网络模型。
1969年M.Minsky等人出版了《感知器》一书,该书从数学角度上证明了单层网络功能有限,提出了基本上所有神经网络都遭受与感知器相同的‘致命缺陷’即不能有效地计算某些必要的判断,单层网络甚至不能解决‘异或’这样的简单逻辑运算问题,而多层网络的可行性也很值得怀疑。此书给人们留下的印象是:神经网络研究已被证明是一个死胡同。
20世纪70年代,神经网络研究进入了低潮期。
美国著名物理学家J.Hopfield在1982年和1984年分别发表了两篇关于神经网络的重要论文,这些论文连同他在世界各地的许多讲座,说服了数百名高水平的科学家、数学家和技术专家加入新兴的神经领域。Hopfield提出了采用全互连型的神经网络模型,成功求解了旅行商问题(Travelling Salesman Problem)。
为了使Hopfield模型更接近人脑的功能特性,许多科学家对这个模型进行了扩展。1983年,‘隐单元’的概念被提出,在此基础上,T.Sejnowski和G.Hinton成功研制除了玻尔兹曼机。日本的福岛邦房在Rosenblatt的感知器的基础上,增加隐层单元,构造出了可以实现联想学习的‘认知机’。
2006年,Hinton等人提出了深度学习的概念,深度学习通过组合低层特征形成更加抽象的高层 表示属性或类别,以发现数据的分布式特征表示。Hinton基于深度置信网络(DBN)提出非监督贪心逐层训练算法,为解决深层结构相关的优化难题带来希望,随后提出多层自助编码器深层结构。此外Lecun等人提出的卷积神经网络是第一个真正多层结构学习算法,它利用空间相对关系减少参数数目以提高训练性能。
2.深度学习发展
‘深度学习’的概念是由多伦多大学的G.Hinton教授于2006年《科学》上首次提出。传统的机器学习方法往往不能直接处理原始形式的自然数据。几十年来,研究者和工程师需要丰富的工程经验和深入的专业知识来设计特定的特征提取器,对原始数据(例如图像的像素值)进行处理,转换成适合机器学习系统特定的表示形式0或特征向量。学习子系统通常是一个分类器,可以检测或分类输入中的模式。
特征学习是一种直接给机器学习系统输入原始数据并自动发现检测或分类所需的特征的方法,而深度学习是具有多级特征的特征学习方法,通过非线性的模块简单组合获得,每个模块将特征在一个级别(从原始输入开始)转换成在更高级别更抽象的特征。通过足够多的这种变换的组合,可以学习非常复杂的功能。以城市道路场景为例,输入的是城市道路图像,且是以像素值矩阵作为输入,第一层学习到的特征通常表示图像中特定角度、位置、颜色的边缘。第二层学习到的特征为第一层边缘特征经过特定组合而成的特定的图案,比如树叶、车灯、车轮。第三层可以将图案组合成对应于特定对象的部分的更大组合,例如汽车、树木、交通标志牌等等,并且后续层将检测对象作为这些部分的组合。深度学习最关键的一点在于:这些特征的学习并不是由研究者和工程师人为所设计的,它们是使用一种通用的学习方法从数据中学习得到的。
通过多年来深度学习的各种尝试和创新,深度学习在人工智能邻域取得了重大进展。它已经被证明能有效地发现高维数据中的错综复杂的结构,因此适用于科学、商业和政府的许多领域。除了在图像分类、语音识别、物体检测等任务中打破传统算法的记录,它在澳洲濒危海牛追踪、图片搜索、智能分拣存储系统、图像风格化处理、医学图像识别病症迹象和粒子加速度数据分析等任务上击败了其他机器学习的方法。另外,深度学习在机器翻译、场景识别、姿态分析、推荐系统和图像分割等任务上都得到了非常优秀的结果。
3、卷积神经网络
卷积神经网络是特殊的一种人工神经网络,它目前已经成为语音分析和图像识别领域最常使用的工具之一,因此也是人工神经网络研究热点。卷积神经网络通过结合局部感知区域、共享权重、空间或者时间上的降采样来充分利用数据本身包含的局部性等特征,优化网络结构。卷积神经网络的结构是一种特殊的多层感知机,它对平移、缩放、倾斜、旋转或者其他形式的变形具有高度不变性,因此特别适合识别二维形状。
3.1卷积神经网络的结构
卷积神经网络通常是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。它受延迟神经网络(TDNN)的影响,采用权值共享来减少网络参数的规模。下面以分类数字的LeNet-5为例,这个CNN含有三种类型的神经网络层:
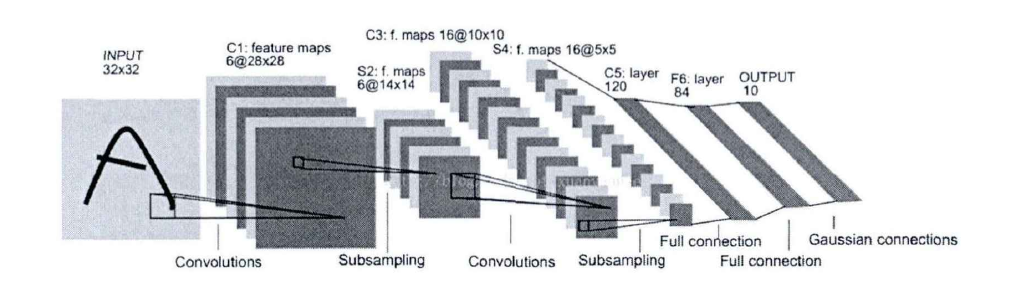
LeNet-5是一个最典型的卷积网络,由卷基层、池化层、全连接层组成,它最初是由Yann LeCun在1998年提出。上图所示,网络输入为32x32的手写数字灰度图像,经过卷积层CI,得到6x28x28的三维矩阵,称之为特征平面(Feature Map),经池化层S2降采样后得到6x14x14的特征平面,依次类推,通过卷积层与池化层的配合,组成多个卷积组,逐层提取特征,最终通过若干个全连接层完成分类。
1)卷积层
卷积神经网络主要通过两种手段降低参数数目,第一种是局部感知域(Local Receptive Field)。一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。
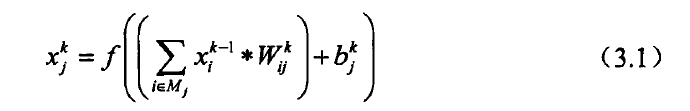
式(3.1)中,xkj 是第k层第j维的特征平面,Mj是表示输入特征平面的集合,Wijk 表示由第k-l层到第k层要产生的特征的数量,称为卷积核(Convolution Kernel)。卷积核可以看作一个四维矩阵,其中第一维是希望输出的特征平面数,第二维是当前层的特征平面数,第三、四维是局部感知域的大小。bkj表示偏置(Bias),是一个k维列向量,k是输出的特征平面数。f(x)表示一个激活函数,常用的激活函数有sigmoid函数和ReLU函数。

其中pad为填充宽度,ks为卷积核尺寸,stride为步长。以9x9特征平面作为输入为例,当pad=0, ks=3, stride=1时,输出特征平面尺寸为7x7。
2)池化层
池化是卷积神经网络另一种降低参数数目的手段,其本质是图像的一种聚合操作。输入图像经过卷积层后获得了图像的特征平面,若直接用该特征平面去做分类或其他任务,则面临计算量上的挑战。而池化操作的结果可以使得特征减少,参数减少,从而降低计算量。并且能有效的防止过拟合(Overfitting)。
池化操作实际上是通过统计一定区域内的图像平均值(平均池化)或最大值(最大池化)实现降采样的作用。即使图像中目标物体有一个较小的平移或缩放,通过池化操作依旧能够得到和未变化前相同的图像特征。例如,在识别手写体数字时候,把它不管往哪个方向移动,都会要求分类器仍然能够准确无误地将其分类为同一个数字。因此池化单元具有一定的旋转、平移、伸缩不变性。
3)全连接层
全连接层的本质即矩阵相乘。在上图中,LeNet经过两组卷积层和池化层的组合后,输出16x5x5的特征平面,即32x32的输入图像经过卷积神经网络的特征提取得到一个400维的特征向量。此时用一个400x120的矩阵与池化层S4的输出相乘后经过一个激活函数,便可以得到120维的特征向量,进一步减少特征数量。
使用全连接层有一个缺点:当输入图像尺寸改变时,原网络结构不能很好的适应新的输入图像,使用者不得不对图像进行缩放或裁减,这有可能导致图像某些特征消失或响应减弱,影响输出效果。
j Long 提出了全卷积网络结构,并成功应用于图像的语义分割任务。全卷积网络改造方法如下:对于原网络结构,全连接层的输入为K×W×H的特征平面,输出为M维的特征向量,因此全连接层的权值矩阵Wfc 是一个KWH×M的矩阵。若将全连接层的权值矩阵Wfc分解为M×K×W×H的卷积核,全连接层便转换为卷积层,且参数数目不变,不影响网络输出准确性。因此越来越多的网络结构正使用卷积层来替代全连接层。
3.1神经网络的训练
反向传播算法(Back Propagation)是由Rumelhart等在1986年提出的。BP算法根据输出层的误差来估计输出层上一层的误差,并且逐层向前递推,反向地计算每一层的误差。
考虑一个有C个类别和N个训练样本的多类别分类问题,代价函数可以由下式定义:
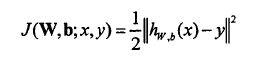 (3.5)
(3.5)
式中(x,y)表示某个输入样本,hw,b (x)表示网络对输入样本x的预测值。
对于网络中每一层有:
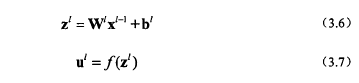
对于第L层是输出层,定义残差δL :
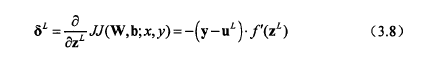
对于第1到L-1层隐含层,则残差δk 满足:
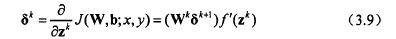
计算所需要的偏导数,计算方法如下:

最后更新权重参数W,b:

其中a为学习率。如此便可以重复梯度下降法的迭代步骤来减小代价函数J(W,b;x,y)的值,进而求解神经网络参数。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号