关于torch.nn.Conv2d的笔记
先看一下CLASS有哪些参数:
torch.nn.Conv2d( in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros' )
可以对输入的张量进行 2D 卷积。
in_channels: 输入图片的 channel 数。
out_channels: 输出图片的 channel 数。
kernel_size: 卷积核的大小。
stride: 滑动的步长。
bias: 若设为 True,则对输出图像每个元素加上一个可以学习的 bias。
dilation: 核间点距。
padding: 控制补 $0$ 的数目。padding 是在卷积之前补 $0$,如果愿意的话,可以通过使用 torch.nn.Functional.pad 来补非 $0$ 的内容。padding 补 $0$ 的策略是四周都补,如果 padding 输入是一个二元组的话,则第一个参数表示高度上面的 padding,第2个参数表示宽度上面的 padding。
关于 padding 策略的例子:
x = torch.tensor([[[[-1.0, 2.0], [3.5, -4.0]]]]) print(x, x.shape) # N = 1, C = 1, (H,W) = (2,2) layer1 = torch.nn.Conv2d(1, 1, kernel_size=(1, 1), padding=0) layer2 = torch.nn.Conv2d(1, 1, kernel_size=(1, 1), padding=(1, 2)) y = layer1(x) print(y, y.shape) z = layer2(x) print(z, z.shape)
结果:
tensor([[[[-1.0000, 2.0000], [ 3.5000, -4.0000]]]]) torch.Size([1, 1, 2, 2]) tensor([[[[-0.3515, 0.4479], [ 0.8476, -1.1510]]]], grad_fn=<ThnnConv2DBackward>) torch.Size([1, 1, 2, 2]) tensor([[[[-0.6553, -0.6553, -0.6553, -0.6553, -0.6553, -0.6553], [-0.6553, -0.6553, 0.2367, -2.4393, -0.6553, -0.6553], [-0.6553, -0.6553, -3.7772, 2.9127, -0.6553, -0.6553], [-0.6553, -0.6553, -0.6553, -0.6553, -0.6553, -0.6553]]]], grad_fn=<ThnnConv2DBackward>) torch.Size([1, 1, 4, 6])
可以看到 padding 为 $(1,2)$ 时,在高度上两边各增加了 $1$ 行,总共增加 $2$ 行。在宽度上两边各增加 $2$ 列,总共增加 $4$ 列。至于为什么增加的行列不是 $0$,这是因为有参数 bias 存在的缘故,此时 bias 值为 $-0.6553$(这个 bias 值初始值应该是一个随机数)。
关于 dilation:
默认情况下 dilation 为 $(1,1)$,就是正常的紧密排布的卷积核。
下图是 dilation 为 $(2,2)$ 的情况(没有 padding,stride 为 $(1,1)$),蓝色的是输入图像,绿色的是输出图像。
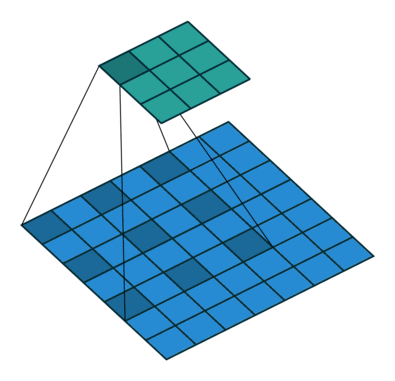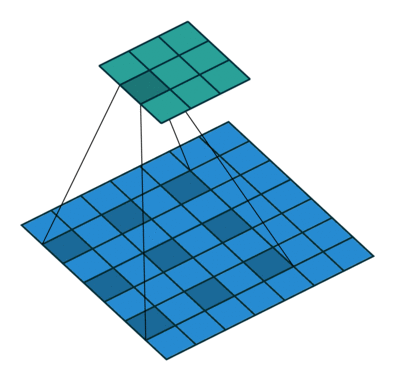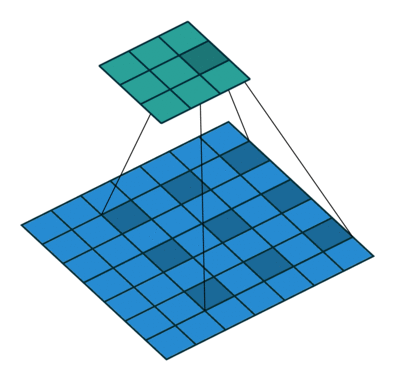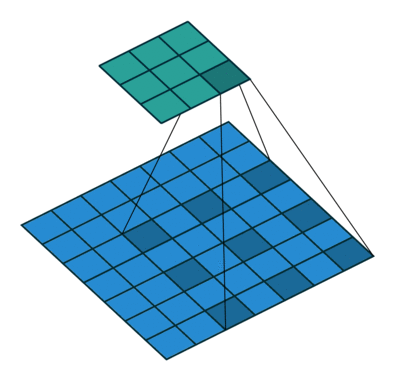
输入图像的 shape 是 $(N, C_{in}, H_{in}, W_{in})$,$N$ 是 batch size,$C_{in}$ 表示 channel 数,$H,W$ 分别表示高和宽。
输出图像的 shape $(N, C_{out}, H_{out}, W_{out})$ 可以通过计算得到:

这个式子很好理解,由于宽高的计算类似,所以只以高为例子来讲:
$H_{in} + 2 \times \rm{padding}[0]$ 即输入图像补完 $0$ 之后的高度,一个卷积核在图像上所能覆盖的高度为 $(\rm{kernel\_size}[0] - 1) \times \rm{dilation}[0] + 1$(例如上面动图就是 $(3 - 1) \times 2 + 1 = 5$),这两个值相减即为,步长为 $1$ 时,卷积核在图像高度上能滑动的次数。而这个次数除去实际步长 $stride[0]$ 再向下取整,即卷积核在图像高度上实际能滑动的次数。这个实际滑动次数加上 $1$ 即输出图像的高度。
需要注意的是:kernel_size, stride, padding, dilation 不但可以是一个单个的 int ——表示在高度和宽度使用同一个 int 作为参数,也可以使用一个 (int1, int2) 的二元组(其实本质上单个的 int 也可以看作一个二元组 (int, int))。在元组中,第1个参数对应高度维度,第2个参数对应宽度维度。
另外,对于卷积核,它其实并不是二维的,它具有长宽深三个维度;实际上它的 channel 数等于输入图像的 channel 数 $C_{in}$,而卷积核的个数即输出图像的 channel 数 $C_{out}$。
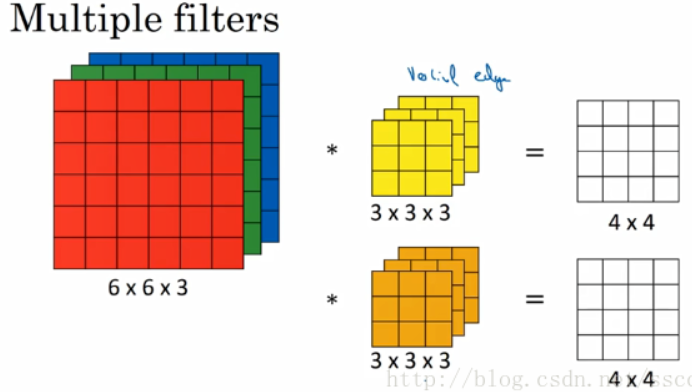
以上图为例,输入图像的 shape 是 $(C = 3, H = 6, W = 6)$,这里略去 batch size,第一个卷积核是 $(C = 3, H = 3, W = 3)$,他在输入图像上滑动并卷积后得到一张 $(C = 1, H = 4, W = 4)$ 的特征图(feature map),第二个卷积核类似得到第二张 $(C = 1, H = 4, W = 4)$ 特征图,那么输出图像就是把这两张特征图叠在一块儿,shape 即为 $(C = 2, H = 4, W = 4)$。
这里顺带记录一下 Batch norm 2D 是怎么做的:
如果把一个 shape 为 $(N, C, H, W)$ 类比为一摞书,这摞书总共有 N 本,每本均有 C 页,每页有 H 行,每行 W 个字符。BN 求均值时,相当于把这 $N$ 本书都选同一个页码加起来(例如第1本书的第36页,第2本书的第36页......),再除以每本书的该页上的字符的总数 $N \times H \times W$,因此可以把 BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字),求标准差时也是同理。
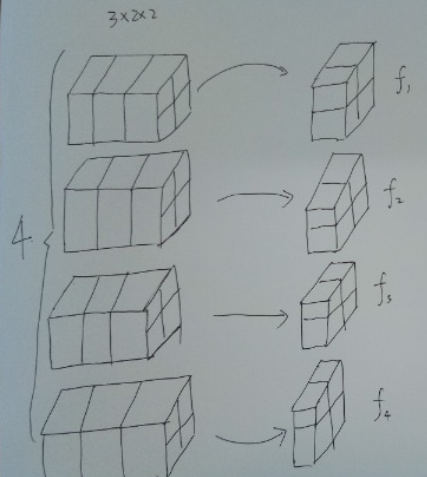
例如下图,输入的张量 shape 为 $(4, 3, 2, 2)$,对于所有 batch 中的同一个 channel 的元素进行求均值与方差,比如对于所有的 batch,都拿出来最后一个channel,一共有 $f_1 + f_2 + f_3 + f_4 = 4 + 4 + 4 + 4 = 16$ 个元素,然后去求这 $16$ 个元素的均值与方差。
求取完了均值与方差之后,对于这 $16$ 个元素中的每个元素分别进行归一化,然后乘以 $\gamma$ 加上 $\beta$,公式如下
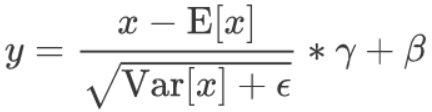
batch norm层能够学习到的参数,对于一个特定的 channel 而言实际上是两个参数 $\gamma, beta$,而对于所有的channel而言实际上就是 channel 数的两倍。
关于其他的 Normalization 做法的形象理解可以参考https://zhuanlan.zhihu.com/p/69659844

 浙公网安备 33010602011771号
浙公网安备 33010602011771号