Python网络爬虫提取之Beautiful Soup入门
(1).Beautiful Soup库的安装
Beautiful Soup库也叫美味汤,是一个非常优秀的Python第三方库,能够对html、xml格式进行解析并提取其中的相关信息,官网地址是“https://www.crummy.com/software/BeautifulSoup/”。
安装Beautiful Soup库一样是使用pip命令,通过命令“pip install BeautifulSoup4”去安装,简单演示一下,如下图:
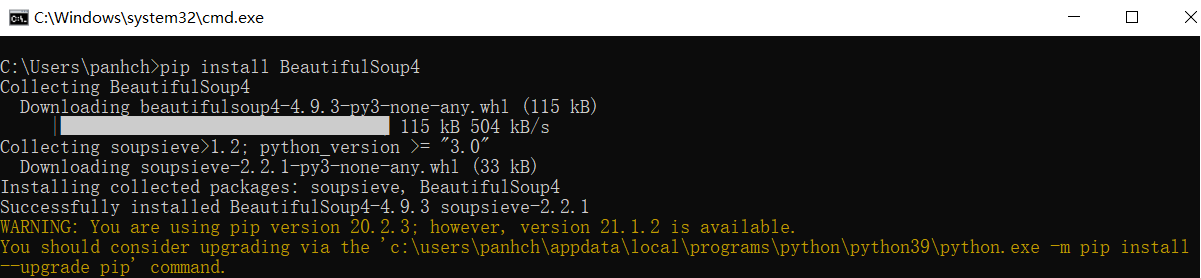
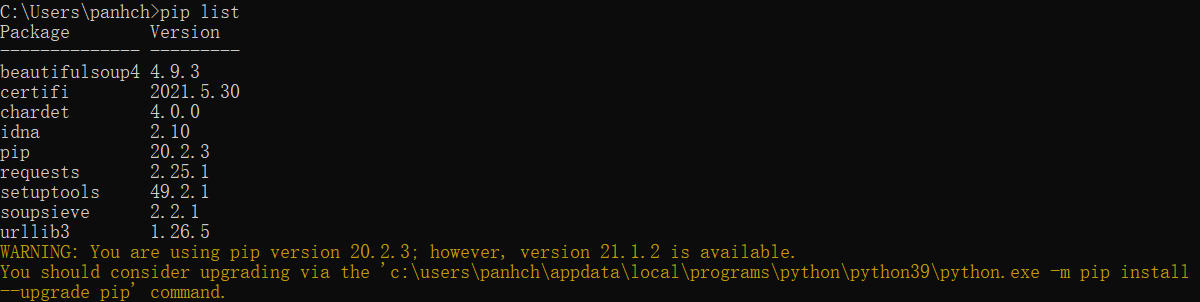
看到“WARNING: You are using pip version 20.2.3; however, version 20.2.4 is available.”不要慌,这个提示是提醒你pip可以升级了,并不是一定要升级,你可以使用“pip list”命令去查看一下安装的报是否成功,如下:
安装完成之后,做一个简单的测试,测试网址为“https://python123.io/ws/demo.html”,它的源代码如下:
<html><head><title>This is a python demo page</title></head> <body> <p class="title"><b>The demo python introduces several python courses.</b></p> <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse1 63.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p> </body></html>
接着使用IDLE来进行尝试,代码如下:
>>> import requests
>>> r = requests.get("https://python123.io/ws/demo.html")
>>> r.text
'<html><head><title>This is a python demo page</title></head>\r\n<body>\r\n<p class="title"><b>The demo python introduces sever
al python courses.</b></p>\r\n<p class="course">Python is a wonderful general-purpose programming language. You can learn Pytho
n from novice to professional by tracking the following courses:\r\n<a href="http://www.icourse163.org/course/BIT-268001" class
="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advance
d Python</a>.</p>\r\n</body></html>'
>>> demo = r.text
>>> from bs4 import BeautifulSoup #bs4是BeautifulSoup4的缩写,这里是导入bs4库里的一个BeautifulSoup类
>>> soup = BeautifulSoup(demo,"html.parser") #html.parser是解析demo的解释器,表示对demo进行html的解析
>>> print(soup.prettify())
<html>
<head>
<title>
This is a python demo page
</title>
</head>
<body>
<p class="title">
<b>
The demo python introduces several python courses.
</b>
</p>
<p class="course">
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the
following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">
Advanced Python
</a>
.
</p>
</body>
</html>
(2).Beautiful Soup库的基本元素
1)Beautiful Soup库的理解
Beautiful Soup库是能够解析html和xml文件的功能库,也可以说Beautiful Soup库是解析、遍历、维护“标签树”的功能库。以html文件为例,打开任意一个html文件的源代码,我们都能看到它是由一组尖括号构成的标签组织起来的,这里面每一对尖括号形成了一个标签,而标签之间存在上下游关系,形成了一个标签树。
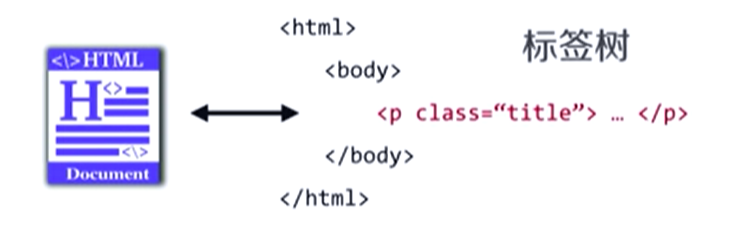
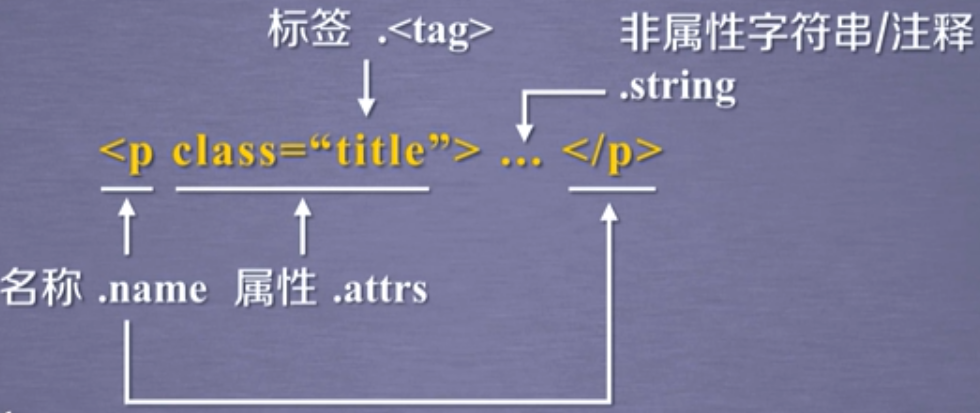
接着我们再看一个标签的具体格式,如下图所示。以p标签为例,p是这个标签的名称,成对出现;“<p>..</p>”构成了这个标签对,英文名叫tag;“class="title"”这个区域是这个标签的属性域,这里面包含零个或多个属性,这个属性是用来定义标签的特点。
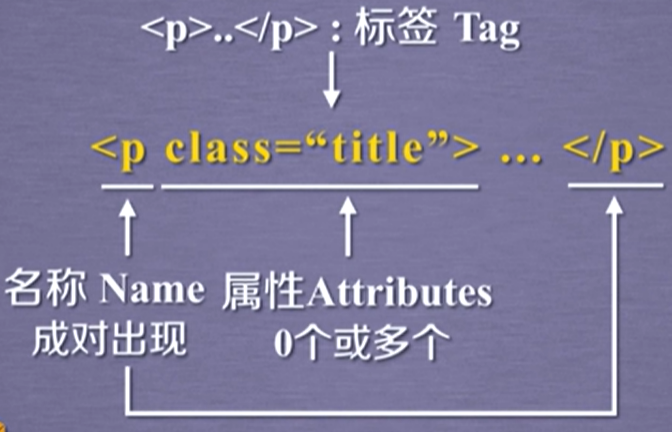
在示例图片中只有一个属性,属性名称叫class,属性内容是title。任何一个属性都有它的属性名称和属性内容,所以可以将他们称为属性的键和值,而键与值构成了键值对,键值对的格式又构成了标签的基本结构。
2)Beautiful Soup库的引用
Beautiful Soup库也叫beautifulsoup4库或bs4库,我们在使用它时需要采用一些引用方式,目前最常用的引用方式是“from bs4 import BeautifulSoup”。这种方式说明我们从bs4库中引入了一个类型,这个类型叫Beautiful Soup。
除了这样一个约定的方式之外,如果我们需要对Beautiful Soup库里的一些基本变量进行判断,我们也可以直接引用Beautiful Soup库,使用的是“import bs4”。
3)Beautiful Soup类
Beautiful Soup库本身解析的是html和xml文档,而这些文档与标签树是一一对应的,那么经过BeautifulSoup类的处理,我们可以使得每一个标签树转换为一个BeautifulSoup类。在这一过程中,我们可以将标签树看成一个字符串,而BeautifulSoup类就是一个能够代表标签树的类型。
事实上我们认为html或xml文档、标签树和BeautifulSoup类这三者是等价的。在等价的基础上,我们就可以通过BeautifulSoup类,使得标签树形成一个变量,而对这个变量的处理就是对标签树的处理。示例如下:
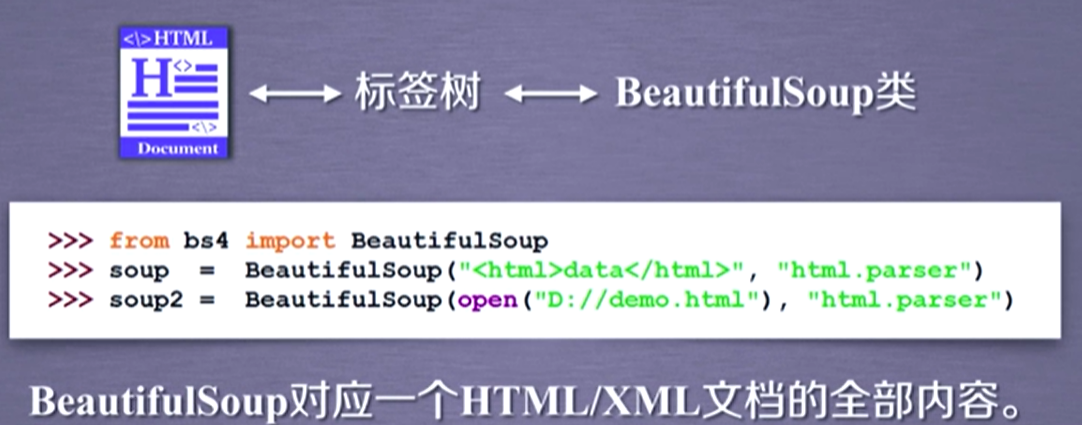
简单来讲,我们可以把BeautifulSoup类当做对应一个html或xml文档的全部内容。
4)Beautiful Soup库解析器
| 解析器 | 使用方法 | 条件 |
| bs4的HTML解析器 | BeautifulSoup(mk,'html.parser') | 安装bs4库 |
| lxml的HTML解析器 | BeautifulSoup(mk,'lxml') | pip install lxml |
| lxml的XML解析器 | BeautifulSoup(mk,'xml') | pip install lxml |
| html5lib的解析器 | BeautifulSoup(mk,'html5lib') | pip install html5lib |
实际上无论使用哪种解析器,它都可以有效解析html和xml文档,所以我们主要使用html解析器。如果在处理xml文档,或者希望获得更快的性能,或者希望获得非常准确的xml解析格式和信息的话,可以使用其它的解析器。
5)Beautiful Soup类的基本元素
| 基本元素 | 说明 |
| Tag | 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 |
| Name | 标签的名称,<p>...</p>的名称是'p',格式:<Tag>.name |
| Attributes | 标签的属性,字典形式组织,格式:<Tag>.attrs |
| NavigableString | 标签内非属性字符串,<>...</>中字符串,格式:<Tag>.string |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
如下图:
下面我们使用“https://python123.io/ws/demo.html”页面来进行演示,如下:
>>> import requests #导入requests库
>>> r = requests.get("https://python123.io/ws/demo.html")
>>> demo = r.text #将网页源代码赋给变量demo
>>> from bs4 import BeautifulSoup #导入BeautifulSoup类
>>> soup = BeautifulSoup(demo,"html.parser")
>>> soup.title #title标签
<title>This is a python demo page</title>
>>> tag = soup.a #将a标签内容赋给tag变量,这里只能获取第一个a标签的内容
>>> tag
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
>>> soup.a.name #a标签的名称
'a'
>>> soup.a.parent.name #a标签的父标签名称
'p'
>>> soup.a.parent.parent.name #a标签的父标签的父标签名称
'body'
>>> tag.attrs #a标签的属性
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
>>> tag.attrs['class'] #a标签的属性中class属性
['py1']
>>> tag.attrs['href'] #a标签的属性中href属性
'http://www.icourse163.org/course/BIT-268001'
>>> type(tag.attrs) #a标签属性的类型是字典
<class 'dict'>
>>> type(tag) #a标签的类型是bs4.element.Tag类型,也就是说bs4定义了一种特殊类型
<class 'bs4.element.Tag'>
>>> soup.a.string #a标签内非属性字符串
'Basic Python'
>>> soup.p
<p class="title"><b>The demo python introduces several python courses.</b></p>
>>> soup.p.string #直接跨越了b标签,由此可见NavigableString元素可以跨越多个标签
'The demo python introduces several python courses.'
>>> type(soup.p.string) #p标签内非属性字符串夜时一个特殊类型
<class 'bs4.element.NavigableString'>
以上是除了Comment元素意外,所有元素的展示。下面演示一下Comment元素,如下:
>>> from bs4 import BeautifulSoup
>>> newsoup = BeautifulSoup("<b><!--This is a comment--></b><p>This is not a comment</p>","html.parser")
>>> newsoup.b.string #自动省略了<!-- -->
'This is a comment'
>>> type(newsoup.b.string) #但是输出类型就是Comment元素类型
<class 'bs4.element.Comment'>
>>> newsoup.p.string
'This is not a comment'
>>> type(newsoup.p.string)
<class 'bs4.element.NavigableString'>
(3).基于bs4库的HTML内容遍历方法
以“https://python123.io/ws/demo.html”作为实例,如果我们对html代码进行结构化设计,可以发现这是一个具有树形结构的一个文本信息,如下所示:
<html>
<head>
<title>
This is a python demo page
</title>
</head>
<body>
<p class="title">
<b>
The demo python introduces several python courses.
</b>
</p>
<p class="course">
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the
following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">
Advanced Python
</a>
.
</p>
</body>
</html>
我们可以看到很多标签,这些标签标明了信息结构的逻辑关系,但并不能直接看出基本的树形结构,所以转换一下,如下图所示。其实,任何一个html和xml格式的文件都是这样的树形结构,这样的树形结构形成了三种遍历方法:首先一种是沿着树的下行遍历,即由根节点向叶子节点遍历的方向;另外一种是从叶子节点向根节点实现的上行遍历方式;还有一种是在平级节点之间互相遍历的平行遍历方式。

1)标签树的下行遍历
| 属性 | 说明 |
| .contents | 当前节点的子节点列表,将<Tag>所有儿子节点存入列表 |
| .children | 当前节点的子节点的迭代类型,与.contents类似,用于遍历循环儿子节点 |
| .descendants | 当前节点的子孙节点的迭代类型,包含所有子孙节点,用于遍历循环 |
.contents实例如下:
>>> import requests
>>> r = requests.get("https://python123.io/ws/demo.html")
>>> demo = r.text
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(demo,"html.parser")
>>> soup.head
<head><title>This is a python demo page</title></head>
>>> soup.head.contents #head标签的子节点列表
[<title>This is a python demo page</title>]
>>> soup.body.contents #body标签的子节点列表
['\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\n', <p class="course">Python
is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking th
e following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href
="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, '\n']
>>> len(soup.body.contents) #body标签的子节点列表的长度
5
>>> soup.body.contents[1] #body标签的子节点列表中第二个参数
<p class="title"><b>The demo python introduces several python courses.</b></p>
.children实例和.descendants实例如下:
>>> for child in soup.body.children:
print("child:%s" %(child)) #因为存在换行的转义字符\n,所以为了方便观察,这里加上child:前缀
child:
child:<p class="title"><b>The demo python introduces several python courses.</b></p>
child:
child:<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
child:
>>> for child in soup.body.descendants:
print("child:%s" %(child)) #因为存在换行的转义字符\n,所以为了方便观察,这里加上child:前缀
child:
child:<p class="title"><b>The demo python introduces several python courses.</b></p>
child:<b>The demo python introduces several python courses.</b>
child:The demo python introduces several python courses.
child:
child:<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
child:Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
child:<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
child:Basic Python
child: and
child:<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
child:Advanced Python
child:.
child:
#需要存在一行才能观测到最后一个换行符
注意:从以上实例可以看出,在操作时需要小心,因为换行符/n或其它字符可能成为子节点。
2)标签树的上行遍历
| 属性 | 说明 |
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
实例如下:
>>> import requests
>>> r = requests.get("https://python123.io/ws/demo.html")
>>> demo = r.text
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(demo,"html.parser")
>>> soup.title.parent
<head><title>This is a python demo page</title></head>
>>> soup.html.parent
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
</body></html>
>>> soup.parent
>>> for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
p
body
html
[document]
注意:html标签的父标签就是它本身,文件本身没有父标签。
3)标签树的平行遍历
| 属性 | 说明 |
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .pervious_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .pervious_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
注意:标签树的平行遍历是有条件的,所有的平行遍历必须发生在同一个父亲节点下。
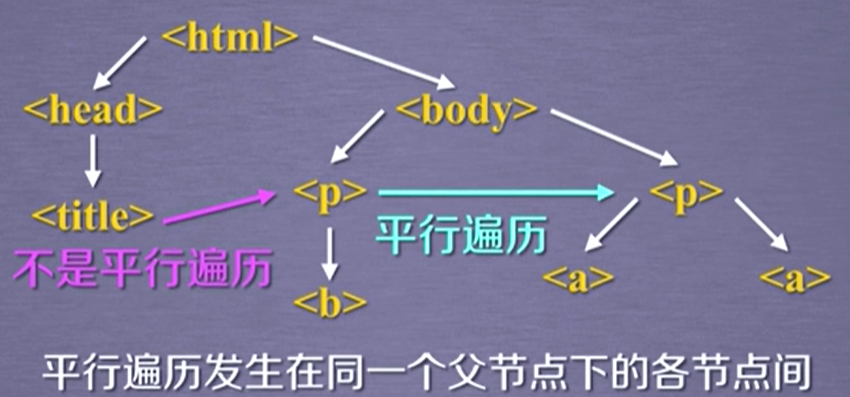
注意:在标签树中,尽管树形结构采用的是标签的形式来组织,但是标签之间的NavigableString也构成了标签树的节点。也就是说任何一个节点它的平行标签、它的父标签、它的子标签都可能存在NavigableString类型的节点。所以我们并不能想当然的认为平行遍历获得的下一个节点一定是标签类型,在使用过程中需要进行相关处理。
.next_sibling和.previous_sibling实例如下:
>>> import requests
>>> r = requests.get("https://python123.io/ws/demo.html")
>>> demo = r.text
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(demo,"html.parser")
>>> soup.a.next_sibling #a标签的下一个平行标签
' and '
>>> soup.a.next_sibling.next_sibling #a标签的下一个平行标签的下一个平行标签
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
>>> soup.a.previous_sibling #a标签的上一个平行标签
'Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by
tracking the following courses:\r\n'
>>> soup.a.previous_sibling.previous_sibling #a标签不存在上一个平行标签的上一个平行标签
>>> soup.a.parent #查看一下父标签进行验证
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice t
o professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2"
href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
.next_siblings和.previous_siblings实例如下:
>>> for sibling in soup.a.next_siblings:
print("sibling:%s" %(sibling))
sibling: and
sibling:<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
sibling:.
>>> for sibling in soup.a.previous_siblings:
print("sibling:%s" %(sibling))
sibling:Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
4)总结

(4).基于bs4库的HTML格式输出
这一部分的主要是为了让html代码友好的显示,能够被人更好的阅读,以及能够被程序更好的读取和分析。
在bs4库中提出了一个方法,叫prettify(),实例如下:
>>> import requests
>>> r = requests.get("https://python123.io/ws/demo.html")
>>> demo = r.text
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(demo,"html.parser")
>>> soup.prettify()
'<html>\n <head>\n <title>\n This is a python demo page\n </title>\n </head>\n <body>\n <p class="title">\n
<b>\n The demo python introduces several python courses.\n </b>\n </p>\n <p class="course">\n Python
is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracki
ng the following courses:\n <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">\n
Basic Python\n </a>\n and\n <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="lin
k2">\n Advanced Python\n </a>\n .\n </p>\n </body>\n</html>'
>>> print(soup.prettify())
<html>
<head>
<title>
This is a python demo page
</title>
</head>
<body>
<p class="title">
<b>
The demo python introduces several python courses.
</b>
</p>
<p class="course">
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional
by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">
Advanced Python
</a>
.
</p>
</body>
</html>
prettify这个方法能够为html文本的标签以及内容添加换行符,它也可以对每一个标签来做相关的处理。例如,取出其中的a标签来进行处理,如下:
>>> print(soup.a.prettify()) <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1"> Basic Python </a>
在bs4库中还有一个很重要的问题叫编码,bs库将任何读入的html文件或字符串都转换成了UTF-8编码。Python3.X系列默认支持编码是UTF-8,所以在使用bs4库解析时并没有任何问题,如果使用的是Python2.X系列那么需要做相关的转换。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号