
python爬虫--01入门篇
1 爬虫
1.1 爬虫原理
爬虫需要做2件事:
1、模拟计算机对服务器发起Request请求;
2、接收服务器端的Response内容并解析、提取所需的信息;
1.2 爬虫流程
分为多页面爬虫流程、跨页面爬虫流程;
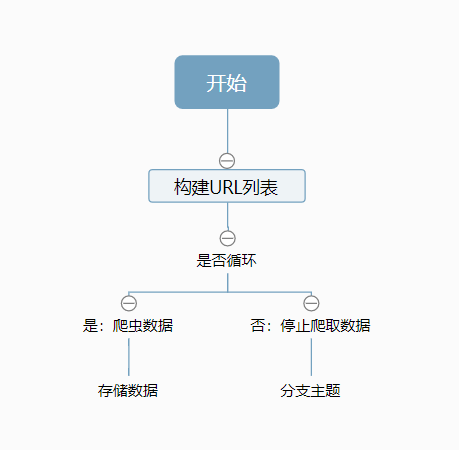
1.2.1 多页面爬虫流程
流程如下:
(1) 手动翻页并观察各网页的URL构成特点,构造出所有页面的URL存入列表中;
(2) 根据URL列表依次循环取出URL;
(3) 定义爬虫函数;
(4) 循环调用爬虫函数、存储数据;
(5) 循环完毕,结束爬虫程序;
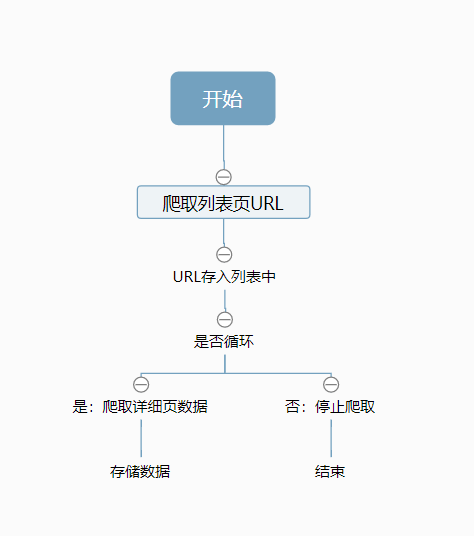
1.2.2 跨页面爬虫流程
流程如下:
(1) 定义爬取函数爬取列表页的所有专题的URL;
(2) 将专题URL存入列表中【种子URL】;
(3) 定义爬取详细页数据函数;
(4) 进入专题详细页面爬取详细页数据;
(5) 存储数据,循环完毕,结束爬虫程序;
请大家尊重原创,如要转载,请注明出处:转载自:https://www.cnblogs.com/diandian520
谢谢!!
***********
请大家尊重原创,如要转载,请注明出处:转载自:https://www.cnblogs.com/diandian520
谢谢!!
***********

 浙公网安备 33010602011771号
浙公网安备 33010602011771号