字符串算法
字符串为什么不滚出OI
manacher算法
可以做到 \(O(n)\) 复杂度求回文。
回文这种东西非常EX,当然可以用字符串哈希来解决这种EX的东西,但是,字符串哈希能做的操作属实有点少,虽说不容易被卡,但是好像用处不算太大。所以就有了 \(\text{manacher}\) 算法,在求回文的时候同时也可以解决多种复杂的问题。
原理呢也不太难。
(1)统计奇偶
首先就是统计奇偶,然后再在各个字符之间插入特殊符号,一般就是插 ‘#’字符,然后为了省略边界判断,在开头的时候插入一个‘@’字符(有\(\text{Letax}\) 美元符号不好写)。
例如: ababac 变为 @#a#b#a#b#a#c# 。
这样所有的回文串的长度都变为奇数。而原回文串的长度为现在回文串半径减 \(1\)。
如: @#a#b#a#b#a#c#
半径长度->\(\text{11214161412121}\)
回文串长度->\(\text{00103050301010}\)
(2)求半径长度
那么半径长度怎么求呢?
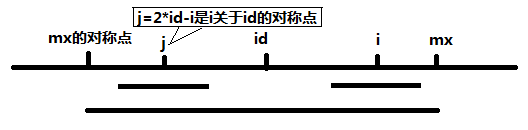
我们设一个储存半径的数组 \(len_i\),求这个数组即可。设 \(mx\) 为 \(\max \{ k+len_k - 1 \mid 1\leq k < i \}\),也就是前面回文串覆盖到的最远距离,然后设它的对称中心为 \(id\)(可能是原串中的字符,也可能是插入的字符)。这时 \(i\) 有它关于 \(id\) 的对称点 \(j\),这时可以发现,此时的 \(len_j\) 已经求出,那么如何确定 \(len_i\) 呢?
因为有 \(S_{mx' \sim mx}\) 关于 \(id\) 对称,而 \(S_{j-len_{j} \cdots j+len_{j}-1}\) 也关于 \(j\) 点对称,要求关于 \(i\) 点对称的半径,需要对 \(len_j\) 进行分类讨论。
如果 \(mx>i\),则有以下两种情况
情况一:\(i+len_j-1<mx\),则 \(len_i=len_j\)。
如下图所示
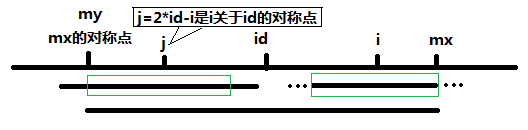
情况二:\(i+len_j-1 \geq mx\),则 \(len_i=mx-i+1\),然后依次枚举判断 \(S_{mx+1\cdots} = S_{2*i-mx-1\cdots}\)。(注意 \(S_{mx+1\cdots}\) 是增大的,而 \(S_{2*i-mx-1\cdots}\) 是减小的)
如下图所示
如果 \(mx \leq i\)
则将 \(len_i=1\),然后依次枚举判断 \(S_{i+1 \cdots }=S_{i-1 \cdots }\)。(注意 \(S_{i+1 \cdots}\) 是增大的,而 \(S_{i-1\cdots}\) 是减小的)
(3)code
理解了思路代码就非常好写了。
char s[N*2],str[N*2];
int Len[N*2],len;
void init()
{
int k=0;
str[k++]='$';
for(int i=0;i<len;i++)
str[k++]='#',
str[k++]=s[i];
str[k++]='#';
len=k;
}
void manacher()
{
init();
int mx=0,id;
for(int i=1;i<len;i++)
{
if(mx>i) Len[i]=min(Len[2*id-i],mx-i);
else Len[i]=1;
while(str[i+Len[i]]==str[i-Len[i]])
Len[i]++;
if(Len[i]+i>mx)
mx=Len[i]+i,id=i;
}
}
题目
BZOJ 3790
母亲节就要到了,小 H 准备送给她一个特殊的项链。这个项链可以看作一个用小写字母组成的字符串,每个小写字母表示一种颜色。为了制作这个项链,小 H 购买了两个机器。第一个机器可以生成所有形式的回文串,第二个机器可以把两个回文串连接起来,而且第二个机器还有一个特殊的性质:假如一个字符串的后缀和一个字符串的前缀是完全相同的,那么可以将这个重复部分重叠。例如:\(\text{aba}\) 和 \(\text{aca}\) 连接起来,可以生成串 \(\text{abaaca}\) 或 \(\text{abaca}\)。现在给出目标项链的样式,询问你需要使用第二个机器多少次才能生成这个特殊的项链。
一遍manacher跑完之后就直接成了贪心经典题,区间覆盖了,为图省事直接扔到堆里了。
#include<bits/stdc++.h>
using namespace std;
const int N=4e5+1;
struct node
{
int l,r;
};
int len[N],id,mx,ans;
char s[N],s1[N];
bool operator < (node x,node y)
{
return x.l>y.l;
}
priority_queue<node> q;
int main()
{
while(scanf("%s",s)!=EOF)
{
memset(s1,0,sizeof(s1));
s1[0]='$';
for(int i=0;s[i];++i)
{
s1[i*2+1]='#';
s1[i*2+2]=s[i];
}
s1[strlen(s1)]='#';
memset(len,0,sizeof(len));
ans=mx=id=0;
for(int i=1;s1[i];++i)
{
len[i]=mx>i?min(len[id*2-i],mx-i):1;
while(s1[i+len[i]]==s1[i-len[i]]) len[i]++;
if(len[i]+i>mx) mx=len[i]+i,id=i;
}
while(!q.empty()) q.pop();
int Len=strlen(s1)-1;
for(int i=2;i<Len;i++) q.push((node){i-len[i]+1,i+len[i]-1});
for(int L=1,R=0;L<Len;ans++,L=R)
while(!q.empty()&&q.top().l<=L)
{
R=max(R,q.top().r);
q.pop();
}
printf("%d\n",ans-1);
}
return 0;
}
HDU 4513
吉哥又想出了一个新的完美队形游戏!
假设有 \(n\) 个人按顺序站在他的面前,他们的身高分别是 \(h_1 , h_2 \cdots ,h_n\),吉哥希望从中挑出一些人,让这些人形成一个新的队形,新的队形若满足以下三点要求,则就是新的完美队形:
1、挑出的人保持原队形的相对顺序不变,且必须都是在原队形中连续的;
2、左右对称,假设有 \(m\) 个人形成新的队形,则第 \(1\) 个人和第 \(m\) 个人身高相同,第 \(2\) 个人和第 \(m-1\) 个人身高相同,依此类推,当然如果 \(m\) 是奇数,中间那个人可以任意;
3、从左到中间那个人,身高需保证不下降,如果用H表示新队形的高度,则 \(H_1 \leq H_2 \leq H_3 \cdots \leq H_mid\)。
现在吉哥想知道:最多能选出多少人组成新的完美队形呢?
一般的 \(\text{manacher}\) 添加的是’#’,但是本题左半边的身高不递减,所以添加的应该是 \((h_i+h_{i+1})/2\),注意细节。处理后的第奇数个身高是添加上去的,第偶数个身高是一开始输入的,当 \(i-p_i\) 是奇数时,无论 \(h_{i-p_i}\) 与 \(h_{i+p_i}\) 是否相等,\(p_i\) 都应该加一。
#include<iostream>
#include<cstdio>
#include<cmath>
#include<algorithm>
using namespace std;
const int N=2e5+1;
int a[N],s[N],len[N];
int manacher(int l)
{
int mx,id,ans;
id=mx=ans=0;
for(int i=0;i<l;i++)
{
if(i<mx) len[i]=min(len[2*id-i],mx-i);
else len[i]=1;
while(s[i-len[i]]==s[i+len[i]])
{
if(s[i-len[i]]==-1) len[i]++;
else
{
if(s[i-len[i]]<=s[i-len[i]+2]) len[i]++;
else break;
}
}
if(i+len[i]>mx)
{
id=i;
mx=i+len[i];
}
ans=max(ans,len[i]-1);
}
return ans;
}
int main()
{
int n,t,L;
cin>>t;
while(t--)
{
scanf("%d",&n);
for(int i=0;i<n;++i)
{
scanf("%d",&a[i]);
}
s[0]=0,s[1]=-1,L=2;
for(int i=0;i<n;++i)
{
s[L++]=a[i];
s[L++]=-1;
}
s[L++]=-1;
printf("%d\n",manacher(L));
}
return 0;
}
HDU不让用万能头,差评!
trie树
trie树,又叫字典树,具体用处是啥呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号