
pytorch ---神经网络语言模型 NNLM 《A Neural Probabilistic Language Model》
论文地址:http://www.iro.umontreal.ca/~vincentp/Publications/lm_jmlr.pdf
论文给出了NNLM的框架图:
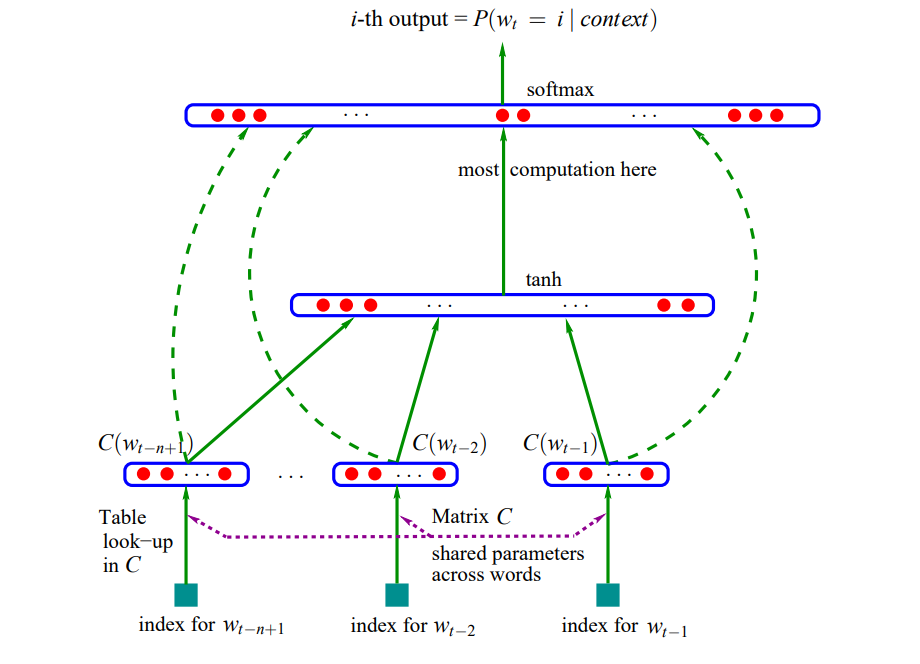
针对论文,实现代码如下(https://github.com/graykode/nlp-tutorial):
1 # -*- coding: utf-8 -*- 2 # @time : 2019/10/26 12:20 3 4 import numpy as np 5 import torch 6 import torch.nn as nn 7 import torch.optim as optim 8 from torch.autograd import Variable 9 10 dtype = torch.FloatTensor 11 12 sentences = [ "i like dog", "i love coffee", "i hate milk"] 13 14 word_list = " ".join(sentences).split() 15 word_list = list(set(word_list)) 16 word_dict = {w: i for i, w in enumerate(word_list)} # {'i': 0, 'like': 1, 'love': 2, 'hate': 3, 'milk': 4, 'dog': 5, 'coffee': 6}} 17 number_dict = {i: w for i, w in enumerate(word_list)} 18 n_class = len(word_dict) # number of Vocabulary 19 20 # NNLM Parameter 21 n_step = 2 # n-1 in paper ->3gram 22 n_hidden = 2 # h in paper ->number hidden unit 23 m = 2 # m in paper ->embedding size 24 25 # make data batch (input,target) 26 # input: [[0,1],[0,2],[0,3]] 27 # target: [5,6,4] 28 def make_batch(sentences): 29 input_batch = [] 30 target_batch = [] 31 32 for sen in sentences: 33 word = sen.split() 34 input = [word_dict[n] for n in word[:-1]] 35 target = word_dict[word[-1]] 36 37 input_batch.append(input) 38 target_batch.append(target) 39 40 return input_batch, target_batch 41 42 # Model 43 class NNLM(nn.Module): 44 def __init__(self): 45 super(NNLM, self).__init__() 46 self.C = nn.Embedding(n_class, m) 47 self.H = nn.Parameter(torch.randn(n_step * m, n_hidden).type(dtype)) 48 self.W = nn.Parameter(torch.randn(n_step * m, n_class).type(dtype)) 49 self.d = nn.Parameter(torch.randn(n_hidden).type(dtype)) 50 self.U = nn.Parameter(torch.randn(n_hidden, n_class).type(dtype)) 51 self.b = nn.Parameter(torch.randn(n_class).type(dtype)) 52 53 def forward(self, X): 54 X = self.C(X) 55 X = X.view(-1, n_step * m) # [batch_size, n_step * m] 56 tanh = torch.tanh(self.d + torch.mm(X, self.H)) # [batch_size, n_hidden] 57 output = self.b + torch.mm(X, self.W) + torch.mm(tanh, self.U) # [batch_size, n_class] 58 return output 59 60 model = NNLM() 61 62 criterion = nn.CrossEntropyLoss() 63 optimizer = optim.Adam(model.parameters(), lr=0.001) 64 65 input_batch, target_batch = make_batch(sentences) 66 input_batch = Variable(torch.LongTensor(input_batch)) 67 target_batch = Variable(torch.LongTensor(target_batch)) 68 69 # Training 70 for epoch in range(5000): 71 72 optimizer.zero_grad() 73 output = model(input_batch) 74 75 # output : [batch_size, n_class], target_batch : [batch_size] (LongTensor, not one-hot) 76 loss = criterion(output, target_batch) 77 if (epoch + 1)%1000 == 0: 78 print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss)) 79 80 loss.backward() 81 optimizer.step() 82 83 # Predict [5,6,4] (equal with target) 84 predict = model(input_batch).data.max(1, keepdim=True)[1] 85 86 # print to visual 87 print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号