基于tcp协议的socket编程
一、什么是Scoket
1、Socket介绍
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
所以,我们无需深入理解tcp/udp协议,socket已经为我们封装好了,我们只需要遵循socket的规定去编程,写出的程序自然就是遵循tcp/udp标准的。
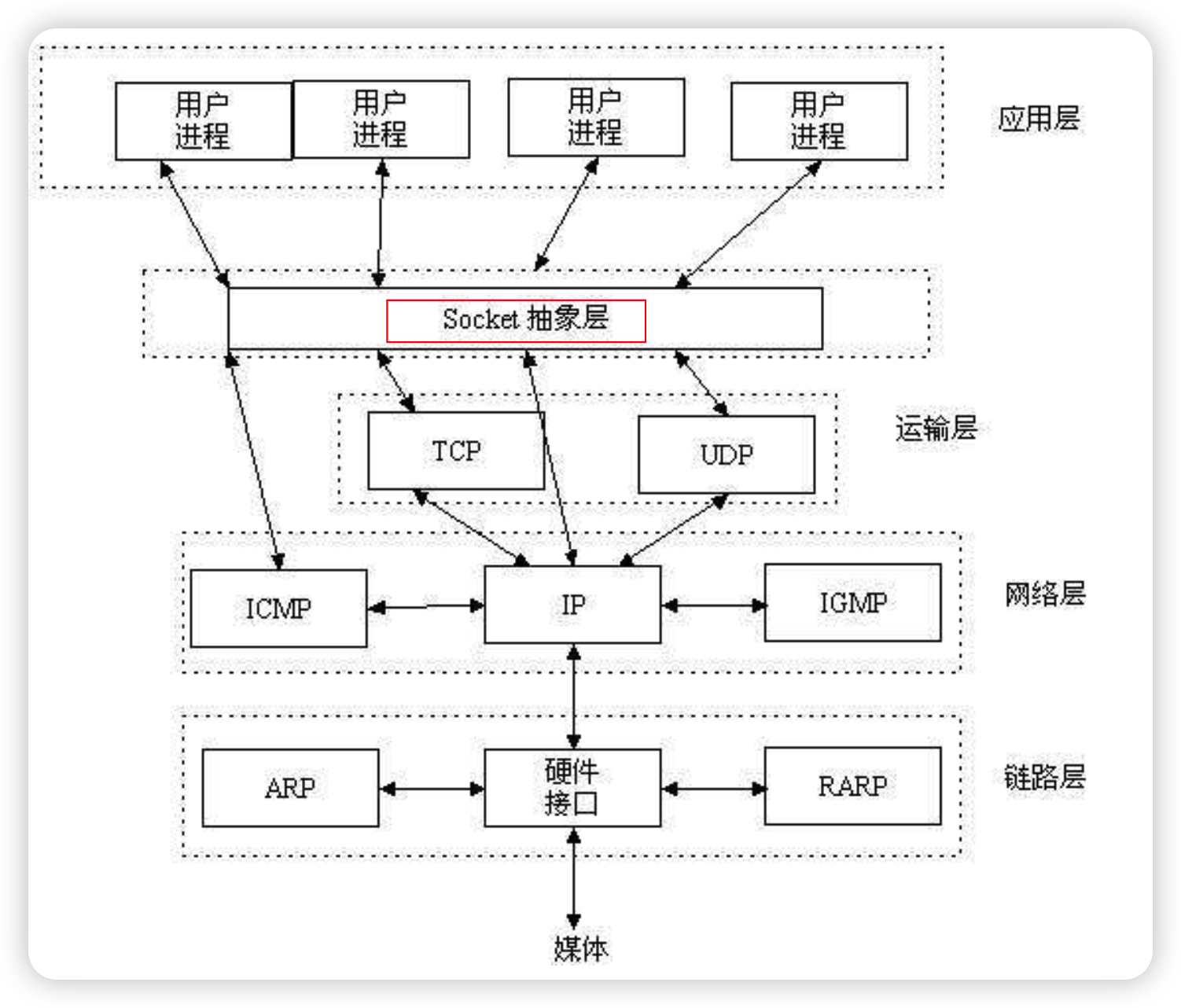
注意:也有人将socket说成ip+port,ip是用来标识互联网中的一台主机的位置,而port是用来标识这台机器上的一个应用程序,ip地址是配置到网卡上的,而port是应用程序开启的,ip与port的绑定就标识了互联网中独一无二的一个应用程序,而程序的pid是同一台机器上不同进程或者线程的标识。
2、基于文件类型的套接字家族
AF_UNIX
unix一切皆文件,基于文件的套接字调用的就是底层的文件系统来取数据,两个套接字进程运行在同一机器,可以通过访问同一个文件系统间接完成通信
3、基于网络类型的套接字家族
AF_INET
(还有AF_INET6被用于ipv6,还有一些其他的地址家族,不过,他们要么是只用于某个平台,要么就是已经被废弃,或者是很少被使用,或者是根本没有实现,所有地址家族中,AF_INET是使用最广泛的一个,python支持很多种地址家族,但是由于我们只关心网络编程,所以
大部分时候我么只使用AF_INET)
4、套接字工作流程
先从服务器端说起,服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。
在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。
客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。

socket()是一个类,实例化对象后可以调用各种方法
class socket(_socket.socket):
"""A subclass of _socket.socket adding the makefile() method."""
__slots__ = ["__weakref__", "_io_refs", "_closed"]
def __init__(self, family=AF_INET, type=SOCK_STREAM, proto=0, fileno=None):
# For user code address family and type values are IntEnum members, but
# for the underlying _socket.socket they're just integers. The
# constructor of _socket.socket converts the given argument to an
# integer automatically.
_socket.socket.__init__(self, family, type, proto, fileno)
self._io_refs = 0
self._closed = False
5、服务端套接字函数
|
方法
|
用途
|
|
s.bind()
|
绑定(主机,端口号)到套接字
|
|
s.listen()
|
开始TCP监听
|
|
s.accept()
|
被动接受TCP客户的连接,(阻塞式)等待连接的到来
|
|
方法
|
用途
|
|
s.connect()
|
主动初始化TCP服务器连接
|
|
s.connect_ex()
|
connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
|
|
方法
|
用途
|
|
s.recv()
|
接收TCP数据
|
|
s.send()
|
发送TCP数据(send在待发送数据量大于己端缓存区剩余空间时,数据丢失,不会发完)
|
|
s.sendall()
|
发送完整的TCP数据(本质就是循环调用send,sendall在待发送数据量大于己端缓存区剩余空间时,数据不丢失,循环调用send直到发完)
|
|
s.recvfrom()
|
接收UDP数据
|
|
s.sendto()
|
发送UDP数据
|
|
s.getpeername()
|
连接到当前套接字的远端的地址
|
|
s.getsockname()
|
当前套接字的地址
|
|
s.getsockopt()
|
返回指定套接字的参数
|
|
s.setsockopt()
|
设置指定套接字的参数
|
|
s.close()
|
关闭套接字
|
|
方法
|
用途
|
|
s.setblocking()
|
设置套接字的阻塞与非阻塞模式
|
|
s.settimeout()
|
设置阻塞套接字操作的超时时间
|
|
s.gettimeout()
|
得到阻塞套接字操作的超时时间
|
|
方法
|
用途
|
|
s.fileno()
|
套接字的文件描述符
|
|
s.makefile()
|
创建一个与该套接字相关的文件
|
二、基于TCP协议的套接字编程(简单)
1、服务端
import socket
# 1、实例化一个server对象
server = socket.socket()
# server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 实例化得到socket对象
# server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 实例化得到socket对象
# 2、绑定ip+端口
server.bind(('127.0.0.1', 8000))
# 3、监听消息
server.listen(3) # 3 代表的是半连接池:可以等待的客户端的数量
# 4、接受消息
sock, addr = server.accept() # 代码走到这里会停住,等待接收客户端发来的消息。返回的是一个元组(tuple)
# sock:代表的是当前客户端的连接对象
# addr:代表的是客户端的信息(ip+port)
# 5、真正获取客户端发来的消息
data = sock.recv(1024) # 接受的最大数据字节数
print('客户端发来的消息是:%s' % data)
# 6、服务端给客户端发消息
sock.send(b'this is server!') # 数据类型必须是字节型
# 7、断开与客户端之间的连接
sock.close()
# 8、关闭server
server.close()
半连接池(Half-Open Connection Pool)补充如下:
半连接池是一种用于管理连接状态的技术,旨在限制同时打开的未完成连接(半连接)的数量。
当服务器端接收到客户端的连接请求时,通常需要执行一系列操作来完成连接的建立,包括握手、认证等。在这些操作完成之前,连接处于半连接状态,也称为未完成连接。
半连接池的目的是通过限制半连接的数量,防止服务器资源被大量未完成的连接占用。通过控制半连接的数量,可以避免服务器过载和拒绝服务等问题。
可以通过设置socket对象的listen()方法的参数来实现半连接池。该参数表示服务器端可以同时接受的最大等待连接数,即半连接池的大小。
例如,server_socket.listen(3)指定了半连接池的大小为3,服务器端最多能够同时处理3个未完成的连接。当半连接池已满时,服务器端会拒绝后续的连接请求。
需要注意的是,半连接池的大小应根据服务器的处理能力和资源限制来合理设置。设置过小的半连接池可能导致客户端连接被拒绝,而设置过大的半连接池可能导致服务器资源耗尽。
2、客户端
import socket
# 1. 实例化对象
client = socket.socket() # 默认的参数就是基于网络的tcp socket
# 2. 连接服务端
client.connect(('127.0.0.1', 8000))
# 3. 给服务端发送消息
client.send(b'this is client')
# 4. 接受服务端发来的消息
data = client.recv(1024)
print('服务端发来的消息:%s' % data)
# 5. 断开连接
client.close()
三、基于TCP协议的套接字编程(循环版)
1、服务端
import socket
# 1、实例化一个server对象
server = socket.socket()
# server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 实例化得到socket对象
# server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 实例化得到socket对象
# 2、绑定ip+端口
server.bind(('127.0.0.1', 8001))
# 3、监听消息
server.listen(3) # 3 代表的是半连接池:可以等待的客户端的数量
while True:
# 4、接受消息
sock, addr = server.accept() # 代码走到这里会停住,等待接收客户端发来的消息
# sock:代表的是当前客户端的连接对象
# addr:代表的是客户端的信息(ip+port)
while True:
try:
# 5、真正获取客户端发来的消息
data = sock.recv(1024) # 接受的最大数据字节数
print('客户端发来的消息是:%s' % data)
if len(data) == 0:
break # 退出内层循环,重新接收一个sock客户端对象
# 6、服务端给客户端发消息
sock.send(b'this is server!') # 数据类型必须是字节型
except ConnectionResetError as e:
print(e)
break
# 7、断开与客户端之间的连接
sock.close()
# 8、关闭server
server.close()
2、客户端(可以有1到n个客户端,取决于半连接池的大小设置)
import socket
# 1. 实例化对象
client = socket.socket() # 默认的参数就是基于网络的tcp socket
# 2. 连接服务端
client.connect(('127.0.0.1', 8001))
while True:
res = input('请输入你要发送的消息:')
if res == 'exit':
break
if res == '':
continue
# 3. 给服务端发送消息
client.send(res.encode('utf8'))
# 4. 接受服务端发来的消息
data = client.recv(1024)
print('服务端发来的消息:%s' % data)
# 5. 断开连接
client.close()
四、多进程版(支持多客户端并发)
服务端
import socket
import multiprocessing
# 把向客户端发送数据、接收数据逻辑写到函数里面去,参数定义为每个传进来的sock 客户端对象
def handle_client(sock):
while True:
try:
data = sock.recv(1024) # 接收客户端的数据
print('客户端发来的消息是:%s' % data)
if len(data) == 0: # 判断客户端传过来的数据是否为空
break
sock.send(b'this is server!') # 给客户端发消息
except ConnectionResetError as e:
print(e)
break
sock.close()
if __name__ == '__main__':
server = socket.socket()
server.bind(('127.0.0.1', 8001))
server.listen(4)
# 循环部分的逻辑写客户端的接收、实例化、进程启动
while True:
sock, addr = server.accept()
p = multiprocessing.Process(target=handle_client, args=(sock,))
p.start()
print(p.name)
server.close()
客户端同上
服务端
import socketserver
class MyTCPHandler(socketserver.BaseRequestHandler):
def handle(self):
# 接收数据
self.data = self.request.recv(1024).strip() # request 这里表示一个客户端
print('Rceived:', self.data)
# 发送自定义数据
message = "This is server"
# self.request.sendall(self.data.upper())
self.request.sendall(message.encode())
if __name__ == '__main__':
HOST, PORT = 'localhost', 8888
server = socketserver.TCPServer((HOST, PORT), MyTCPHandler)
# 永久服务
server.serve_forever()
客户端
import socket
# 创建一个TCP socket
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:
sock.connect(('localhost', 8888))
# 发送数据
message = 'hello'
sock.sendall(message.encode('utf8'))
# 接收响应
response = sock.recv(1024)
print('Response:', response.decode('utf8'))
1、服务端
import socket
# 1、实例化一个server对象
server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # DGRAM 数据报协议UDP
# 2、绑定ip+port
server.bind(('127.0.0.1', 9000))
while True:
data, client_addr = server.recvfrom(1024) # 接受客户端的信息(消息+ip:port)
print('===>', data, client_addr) # 打印data 和 ip:port
server.sendto(data.upper(), client_addr) # 给客户端发消息,复用上面的data转为大写
server.close()
2、客户端
import socket
client = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 数据报协议-》UDP
while True:
msg = input('请输入你要发送的消息: ').strip()
client.sendto(msg.encode('utf-8'), ('127.0.0.1', 9000))
# data, server_addr = client.recvfrom(1024)
data = client.recvfrom(1024)
print(data)
client.close()
七、沾包问题
1、什么是沾包
网络通信中的"粘包"(Packet Sticking)是指发送方在发送数据时,连续发送的多个数据包被接收方接收时粘在一起,形成一个大的数据包。
这种情况可能会导致接收方无法正确解析和处理数据,从而引发数据解析错误。
2、沾包的原因
主要原因是网络传输的数据没有明确的边界,导致接收方无法准确分割接收到的数据。常见的导致粘包的情况包括:
- 发送方连续发送多个数据包时,这些数据包在网络传输过程中被合并为一个大的数据包。
- 接收方缓冲区大小较小,无法及时接收完整的数据包,导致多个数据包被合并在一起。如 client.recv(1024)
- 网络传输中存在延迟、拥塞等因素,导致数据包的发送和接收不同步。
3、解决粘包问题的方法有多种,其中常用的方法包括:
- 增加边界标识:发送方在数据包之间添加特定的边界标识符,接收方根据标识符来分割接收到的数据。例如,在每个数据包之后添加换行符或特定字符作为边界标识。
- 使用固定长度的数据包:发送方将数据按照固定长度进行分割并发送,接收方根据固定长度来解析数据包。这种方法需要发送方和接收方事先约定好固定长度。
- 使用长度字段:发送方在每个数据包的开头添加一个表示数据长度的字段,接收方先读取长度字段,然后根据长度读取相应长度的数据。这种方法需要发送方和接收方都严格按照长度字段进行处理。
4、struct 模块
struct 是 Python 中的一个内置模块,用于处理二进制数据和 Python 数据类型之间的相互转换。
它提供了一组函数,可用于在不同的数据类型之间进行打包(pack)和解包(unpack)操作,使得处理二进制数据更加方便和灵活
struct模块的主要目的是处理不同机器之间的数据交换,或者处理与底层操作系统相关的二进制数据。它能够将Python数据类型和C结构体类型相互转换,使得数据在不同平台和编程语言之间能够正确地传递和解析。
struct模块的常用函数包括:
pack(format, v1, v2, ...):将数据按照指定的格式(format)打包为字节序列。format参数指定了数据的布局和类型,v1, v2, ...参数表示要打包的数据。返回一个包含打包数据的字节序列。unpack(format, buffer):从字节序列中按照指定的格式(format)解包数据。format参数指定了数据的布局和类型,buffer参数为包含要解包的字节序列。返回一个包含解包数据的元组。calcsize(format):计算指定格式(format)的字节序列的长度。返回一个整数,表示字节序列的长度。
struct模块支持的格式字符串中包含了多种数据类型和格式指示符,例如:
- 数字类型:
b(有符号字节),B(无符号字节),h(有符号短整数),H(无符号短整数),i(有符号整数),I(无符号整数),l(有符号长整数),L(无符号长整数),f(单精度浮点数),d(双精度浮点数)等。 - 字节顺序:
<(小端序,低字节在前),>(大端序,高字节在前),!(网络字节顺序)等。 - 其他格式指示符:
s(字节序列),x(字节填充)等。
案例:
服务端
import socket
import json
import struct
server = socket.socket() # 实例化server
server.bind(('127.0.0.1', 8083)) # 绑定ip+端口
server.listen(5) # 开启监听
while True:
sock, address = server.accept() # 接受用户发的数据
# 先接收客户端固定长度为4的字典报头数据
recv_first = sock.recv(4) # 第一次接收来自客户端的消息
print(recv_first)
# 解析字典报头
dict_length = struct.unpack('i', recv_first)[0]
# 接收字典数据
real_data = sock.recv(dict_length) # 第二次接收来自客户端序列化后的字典
print(real_data)
# 解析字典(json格式的bytes数据 loads方法会自动先解码 后反序列化)
real_dict = json.loads(real_data)
print(real_dict)
# 获取字典中的各项数据
data_length = real_dict.get('size')
file_name = real_dict.get("file_name")
recv_size = 0
with open('test.mp4', 'wb') as f:
while recv_size < data_length:
data = sock.recv(1024) # 第三次接收来自客户端的数据
recv_size += len(data)
f.write(data)
注:
1、os.path.getsize(xxx.mp4)返回的是文件大小,单位为字节。这里第三次收客户端发来的二进制格式的视频文件,这里计算长度。逻辑是收完二进制文件,其len之后的长度等价于文件的大小
2、recv_size 相当与计数器
3、with open只打开了一次,没有多次写覆盖的操作,循环写,写完再关闭。
客户端
import json
import socket
import struct
import os
client = socket.socket() # 买手机
client.connect(('127.0.0.1', 8083)) # 拨号
while True:
data_path = os.path.dirname(os.path.abspath(__file__))
# print(os.listdir(data_path)) # [文件名称1 文件名称2 ]
movie_name_list = os.listdir(data_path)
for i, j in enumerate(movie_name_list, 1):
print(i, j)
choice = input('请选择您想要上传的电影编号>>>:').strip()
if choice.isdigit():
choice = int(choice)
if choice in range(1, len(movie_name_list) + 1):
# 获取文件名称
movie_name = movie_name_list[choice - 1]
# 拼接文件绝对路径
movie_path = os.path.join(data_path, movie_name)
# 1.定义一个字典数据
data_dict = {
'file_name': 'XXX老师合集.mp4',
'desc': '这是非常重要的数据',
'size': os.path.getsize(movie_path), # 获取文件的大小,字节数
'info': '下午挺困的,可以提神醒脑'
}
data_json = json.dumps(data_dict) # 序列化字典,序列化以后为字符串
# 2.制作字典报头
data_first = struct.pack('i', len(data_json)) # 压缩i模式,i 表示int类型
#### 客户端连续3次给服务端发送消息 ####
# 3.发送字典报头
client.send(data_first)
# 4.发送字典
client.send(data_json.encode('utf8')) # 以字节形式发送序列化后的字典
# 5.发送真实数据
with open(movie_path, 'rb') as f:
for line in f:
client.send(line)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号