爬虫信息提取方式。新人学的不仔细
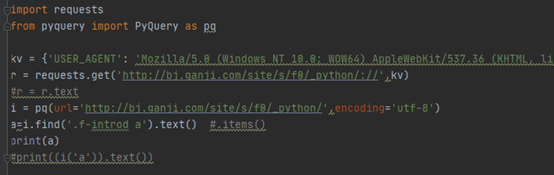
Pyquery
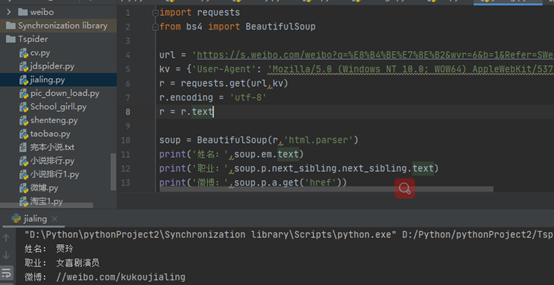
Beautiful Soup
煲汤然后
Xpath
//标签/[@class=’’/.text()].extract() 感觉这个上手快 理解也快 没放图
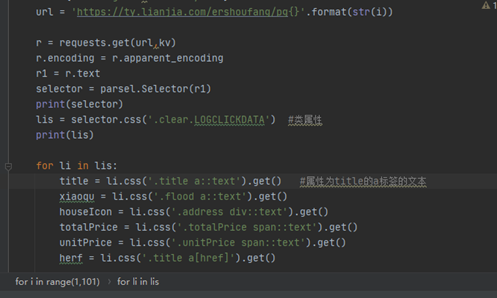
Css selector 提取一个大标签 获取内部相同标签内容 省空间 代码 工作
再就是Re了 自己没写明白 但是很厉害 就不放了
是不是有其他的方式 应该有吧,咱刚接触,也不知道
Pyquery
Beautiful Soup
煲汤然后
Xpath
//标签/[@class=’’/.text()].extract() 感觉这个上手快 理解也快 没放图
Css selector 提取一个大标签 获取内部相同标签内容 省空间 代码 工作
再就是Re了 自己没写明白 但是很厉害 就不放了
是不是有其他的方式 应该有吧,咱刚接触,也不知道

 浙公网安备 33010602011771号
浙公网安备 33010602011771号