java集合框架
先概念一下,集合框架,也可以说是容器,在java中,存放数据的大可理解为容器。
看之前了解到Collection是一个接口,而Collection包含了List和Set这两个接口。
看图理解:
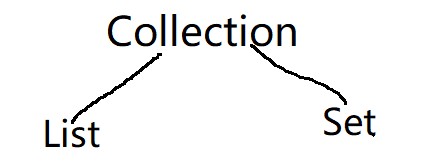
总接口Collection能分两个接口出来,当然是有自己的方法的,这里看这么些:
collection中的添加:add


public class CollectionTest { public static void main(String[] args) { Collection collection=new ArrayList(); collection.add(1); collection.add("asd"); collection.add(3); collection.add(5); System.out.println(collection); } }
collection中的删除:clear
public class CollectionTest { public static void main(String[] args) { Collection collection=new ArrayList(); collection.add(1); collection.add("asd"); collection.add(3); collection.add(5); //collection.clear删除的是所有的内容 System.out.println(collection.clear); } }
collection中是否为空:isEmpty()
public class CollectionTest { public static void main(String[] args) { Collection collection=new ArrayList(); collection.add(1); collection.add("asd"); collection.add(3); collection.add(5); //collection.isEmpty();如果有内容返回false 没有内容返回true System.out.println("是不是为空:"+collection.isEmpty()); } }
collection中是否包含:contains()
public class CollectionTest { public static void main(String[] args) { Collection collection=new ArrayList(); collection.add(1); collection.add("asd"); collection.add(3); collection.add(5); //collection.contains("asd");如果包含返回true 不包含返回false System.out.println("是否包含:"+collection.contains("asd")); } }
collection中内容的长度:size()
public class CollectionTest { public static void main(String[] args) { Collection collection=new ArrayList(); collection.add(1); collection.add("asd"); collection.add(3); collection.add(5); //collection.size();Collection中的长度为size;String中的长度为length //Collection的长度并不是说所有的元素加起来有多长,而是的每个内容 System.out.println("collection中的内容有:"+collection.size()+"个"); } }
最后是大头!!!!!!
迭代器,因为Collection是接口,没有引用类型,所以不能用常用for循环来遍历,只能通过迭代器来进行遍历。
public class CollectionTest { public static void main(String[] args) { Collection collection=new ArrayList(); collection.add(1); collection.add("asd"); collection.add(3); collection.add(5); Iterator iterator=collection.iterator();//条件 //while循环 while(iterator.hasnext()){ system.out.println(iterator.next()); } //for循环 for(iterator=collection.iterator();iterator.hasNext();) { System.out.println(iterator.next()); } } }
以上就是Collection中常用的方法,如果还有其他需要的可以接着更新。
接着介绍Collection的List接口:
List的特点是:有序的集合,允许重复元素存在;其中包含ArrayList、Vector、LinkedList这些派生类。
接着派生类的特点具体如下:
ArrayList跟Vector是有相同点、不同点的:
相同点:底层都是数组,增删慢,查询块;
不同点是:ArrayList 线程不安全,效率高;Vector 线程安全,效率低。
LinkedList:底层是链表,查询慢,增删快;线程不安全,效率高。
这里看看list的使用方法:
list中的添加 add
public class CollectionTest { public static void main(String[] args) { List list=new ArrayList(); list.add(1); list.add(3); list.add(5); } }
list中的修改 set
public class CollectionTest { public static void main(String[] args) { List list=new ArrayList(); list.add(1); list.add(3); list.add(5); //list.set(k,o); //list的修改需要根据索引修改 括号里边第一个是索引 第二个是要修改的值 System.out.println("修改的:"+list.set(1, 99)); } }
list中的删除 remove
public class CollectionTest { public static void main(String[] args) { List list=new ArrayList(); list.add(1); list.add(3); list.add(5); list.remove(1); //这里的删除是根据索引删除的 System.out.println("删除"+list.remove(1)); System.out.println(list); } }
list中的获取值 get
public class CollectionTest { public static void main(String[] args) { List list=new ArrayList(); list.add(1); list.add(3); list.add(5); //list.get(索引); System.out.println("根据索引拿到的:"+list.get(1)); } }
因为父类是Collection 想遍历的话也只能通过迭代器,因为继承了父类的没有引用类型;
public class CollectionTest { public static void main(String[] args) { List list=new ArrayList(); list.add(1); list.add(3); list.add(5); Iterator iterator=list.iterator();//条件 //while while(iterator.hasNext()) { System.out.println(iterator.next()); } //for for(iterator=list.iterator();iterator.hasNext();) { System.out.println(iterator.next()); } } }
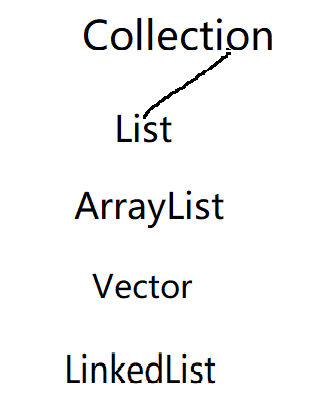
这里Collection中list的功能特点就介绍完了,在了解完Collection后,想起之前某培训机构的校长竟然问学生"ArrayList和List的区别是什么",听到这一个问题,真是让我想到了“师傅你是做什么工作的”,这里一定记得List的子类,Collection的子类。
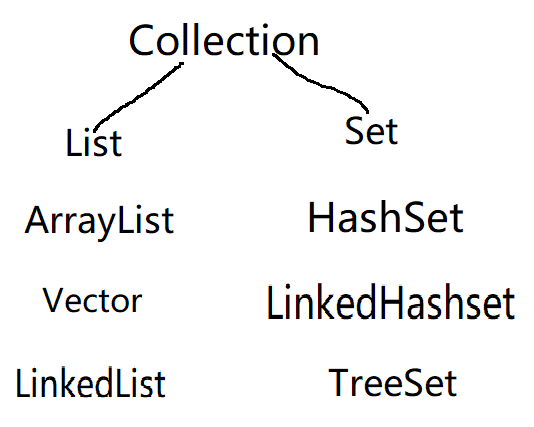
接着看看Collection中Set接口:
Set的特点:无序(输出的顺序和插入的顺序不一样),不允许重复;其中有HashSet、HashlinkedSet、TreeSet这些派生类。它们也有独有的特点如下:
HashSet:底层数据是哈希表;不保证有序。
HashlinkedSet:底层是哈希表加链表;链表嘛,自然会有序。
TreeSet:二分叉,左边小,右边大;会使元素自然排序,

这里set也就完成了。最后是一大家子的合照。
再接着是跟collection并列的Map
虽然是跟Collection并列的关系了,但分下去的接口没有那么多,就Map自己。
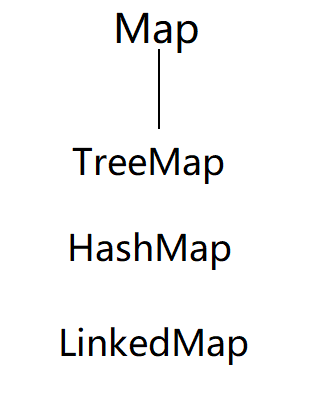
看看Map和并列的Collection之间会的区别有哪些:
- Map存储的元素是成对出现的,键是唯一的,值是可以重复的;而Collection存储元素是单独的。
- Map的集合存储只针对键有效,和值无关;Collection的数据结构针对元素
说完总的,看看分下来的子类的特点
HashMap:键是哈希表结构,可以保证键的唯一性。
LinkedMap:Map 接口的哈希表和链接列表实现,具有可预知的迭代顺序。
TreeMap:键是红黑树结构,可以保证键的排序和唯一性。
然后就是Map的使用方法:
Map中的添加 put
public class MapTest { public static void main(String[] args) { Map< Integer, String> map=new HashMap<Integer, String>(); map.put(20200520,"阿萨德"); map.put(20200521, "q全文"); map.put(20200502, "王企鹅"); System.out.println(map); } }
Map中的删除 clear
public class MapTest { public static void main(String[] args) { Map< Integer, String> map=new HashMap<Integer, String>(); map.put(20200520,"阿萨德"); map.put(20200521, "q全文"); map.put(20200502, "王企鹅"); map.clear(); //clear之后 所有的元素都没了 System.out.println(map); } }
Map中的判断 是否包含键、是否包含值 containsKey、 containsValue
public class MapTest { public static void main(String[] args) { Map< Integer, String> map=new HashMap<Integer, String>(); map.put(20200520,"阿萨德"); map.put(20200521, "q全文"); map.put(20200502, "王企鹅"); //包含返回true 不包含返回false System.out.println("是否包含这个键"+map.containsKey(20200520)); System.out.println("是否包含这个值"+map.containsValue("大企鹅")); } }
Map中看内容的长度 size
public class MapTest { public static void main(String[] args) { Map< Integer, String> map=new HashMap<Integer, String>(); map.put(20200520,"阿萨德"); map.put(20200521, "q全文"); map.put(20200502, "王企鹅"); //这里返回结果为3 只添加了3个内容 System.out.println(map.size()); } }
Map都跟Collection并列了,当然没有引用类型,也是通过迭代器来遍历的
public class MapTest { public static void main(String[] args) { Map< Integer, String> map=new HashMap<Integer, String>(); map.put(20200520,"阿萨德"); map.put(20200521, "q全文"); map.put(20200502, "王企鹅"); //迭代器 while循环 Set<Map.Entry<Integer, String>> set=map.entrySet();//获取Set<Map.Entry<Integer, String>> Iterator<Entry<Integer, String>> iterator=set.iterator();//判断条件 while(iterator.hasNext()) { Map.Entry<Integer, String> entry=iterator.next(); System.out.println(entry.getKey()+" "+entry.getValue()); } //for each Set<Map.Entry<Integer, String>> set=map.entrySet();//获取Set<Map.Entry<Integer, String>> Iterator<Entry<Integer, String>> iterator=set.iterator();//判断条件 for(Map.Entry<Integer, String> entry:set) { System.out.println(entry.getValue()+" "+entry.getKey()); } } }
到最后的结构表,是这样的:

打住打住 如果还想了解 可以看一看常见的数据结构。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号