2025,每天10分钟,跟我学K8S(四十三)- Prometheus(一)
前面内容,讲述了很多K8S的知识点,也了解了K8S的基础使用。从本章节开始,我们一起来学习下K8S中的监控系统。作为一名合格的devopser,知道监控是生产环境不可或缺的,我们需要时刻了解系统环境的各种指标,不管是node的指标,还是pod中运行的应用的指标,在他们出现问题时候,能第一时间通过告警的方式通知到我们。
而Prometheus作为和K8S都是云原生计算基金会出品的产品,现在基本是是K8S监控的标配了。从本章开始,我们就一起来学习它。
什么是Prometheus
Prometheus 是一款开源的 时序数据库与监控告警系统,专为云原生和分布式环境设计,其核心功能是通过多维数据模型和灵活的查询语言实现对系统、应用及基础设施的全方位监控。它将所有信息都存储为时间序列数据;因此实现一种Profiling监控方式,实时分析系统运行的状态、执行时间、调用次数等,以找到系统的热点,为性能优化提供依据。
一、核心特性
1.多维数据模型
每个监控指标由 指标名称(Metric Name) 和 标签(Labels) 唯一标识,支持从多维度(如请求方法、状态码、服务实例等)对数据进行分析。例如,http_requests_total{method="GET", status="200"} 可细分统计不同请求的成功率。
2.PromQL 查询语言
提供类似 SQL 的语法,支持复杂的数据聚合、数学运算和实时计算。例如,计算 CPU 使用率:
100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)种灵活性使其适用于趋势分析和故障排查。
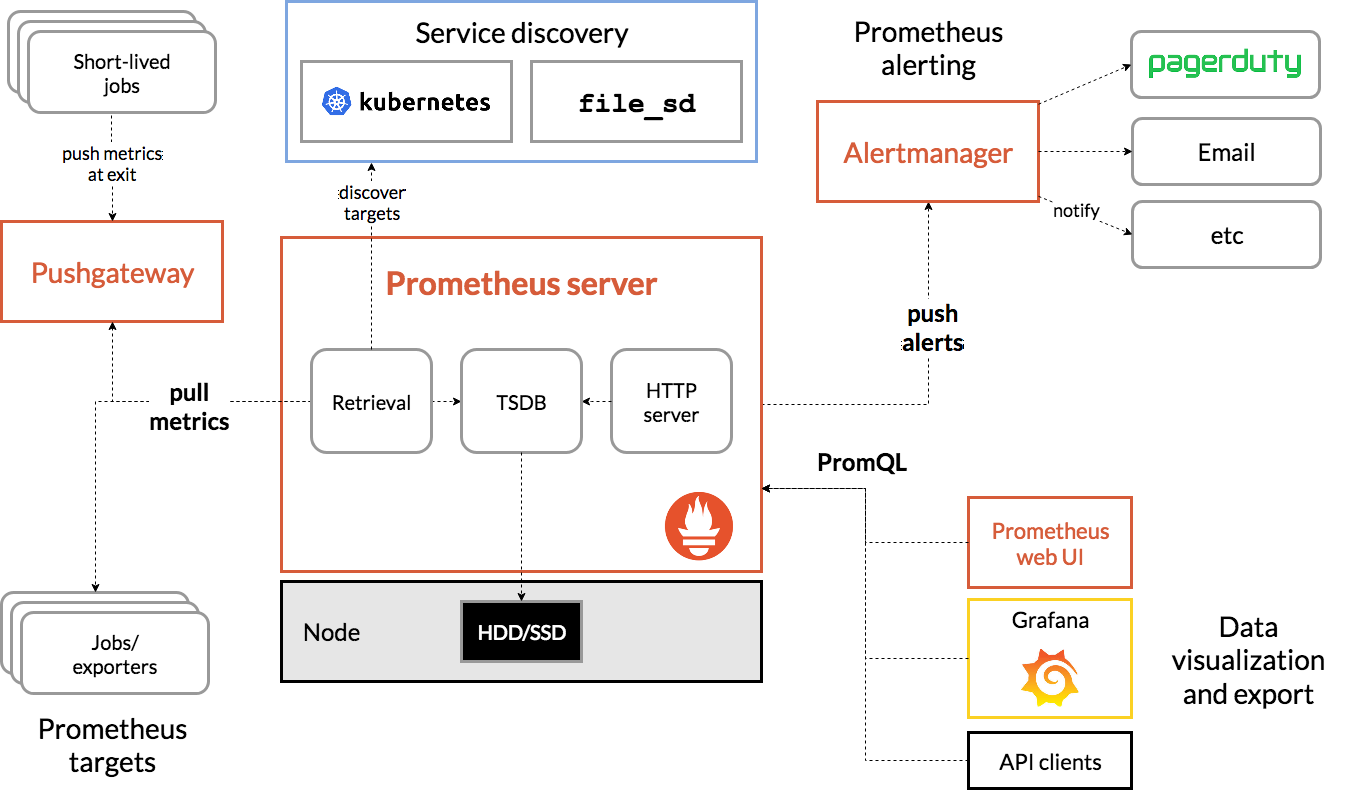
3.主动拉取(Pull)与推送(Push)结合
- 拉取模式:Prometheus Server 定期从配置的目标(如 Exporter、应用程序端点)主动抓取指标。
- 推送模式:通过 Pushgateway 支持短生命周期任务(如批处理作业)的指标上报。
4.动态服务发现
支持 Kubernetes、Consul 等服务发现机制,自动识别并监控动态变化的服务实例,减少手动配置成本。
5.告警管理
Alertmanager 负责处理告警的去重、分组和路由,支持邮件、Webhook、Slack 等多种通知渠道。
二、核心组件
| 组件 | 功能 | 适用场景 |
|---|---|---|
| Prometheus Server | 核心服务,负责数据采集、存储(TSDB 时序数据库)和查询(PromQL) | 长期运行的监控目标(如服务器、容器) |
| Exporter | 将第三方系统(如 MySQL、Redis)的指标转换为 Prometheus 兼容格式 | 间接监控非原生支持的应用或服务 |
| Pushgateway | 临时存储短生命周期任务的指标数据,供 Server 拉取 | 批处理作业、一次性任务 |
| Alertmanager | 处理告警规则触发后的通知逻辑,支持静默、抑制和路由策略 | 告警分级管理、多级通知渠道整合 |
| Grafana | 可视化工具,提供丰富的仪表盘模板展示 Prometheus 数据 | 数据趋势分析、多维度可视化 |
三、版本选择
目前常用的Prometheus 有3个版本提供选择,Prometheus Operator 、 kube-prometheus、kube-prometheus-stack。其内在核心都是 Prometheus ,由不同的人群在维护。
Prometheus Operator
Prometheus Operator: 在 Kubernetes 上手动一步步搭建,然后管理 Prometheus 集群。该项目的目的是简化和自动化基于 Prometheus 的 Kubernetes 集群监控堆栈的配置。适合定制化方案,但是需要一步步的搭建。
kube-prometheus
基于 Prometheus Operator 的预配置方案,包含 Prometheus、Alertmanager、Grafana、kube-state-metrics 等组件,提供开箱即用的监控规则和仪表盘,并且已经安排了一个名为 prometheus-k8s 的 prometheus,默认带有警报和规则,几乎一键搭建,减少用户的配置,并且带有其他 prometheus 需要的组件,如:
- Grafana
- kube-state-metrics
- prometheus adapter
- node exporter
- ...
kube-prometheus-stack
kube-prometheus的helm版本,由社区维护的 Helm Chart,整合了 kube-prometheus 的功能,并增加兼容性优化和扩展组件(如 Thanos),支持参数化部署和版本管理
四、适用场景
-
云原生与容器监控
与 Kubernetes 深度集成,自动发现 Pod、Service 等资源,监控容器资源使用率(CPU、内存)及微服务性能。 -
微服务架构监控
通过服务发现和标签机制,追踪分布式系统中的请求链路、错误率及延迟。 -
基础设施监控
收集主机(Node Exporter)、网络设备、存储系统的指标,支持容量规划和故障预警。 -
业务指标监控
自定义业务指标(如订单量、用户活跃度),结合 PromQL 实现实时业务分析。
五、优势与局限
-
优势:
- 轻量级:单节点部署,不依赖分布式存储。
- 高扩展性:支持联邦集群(Federation)和远程存储(如 Thanos、Cortex)。
- 社区生态:CNCF 毕业项目,拥有丰富的 Exporter 和集成工具。
-
局限:
- 数据精度:适用于可靠性监控,但不适合需要 100% 准确性的计费场景。
- 长期存储:原生 TSDB 适合短期数据,长期存储需依赖外部方案。
六、典型工作流程示例
- 数据采集:Prometheus Server 定期从 Node Exporter 拉取主机指标。
- 规则评估:根据
alert.rules判断 CPU 使用率是否超阈值。 - 告警触发:触发后 Alertmanager 发送邮件通知运维人员。
- 可视化展示:通过 Grafana 仪表盘实时查看监控趋势。
工作流程图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号