python入门第一篇
内容大纲:
一.内容编码
二.数据类型
三.变量
四.常量
五.格式化
一.内容编码
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。

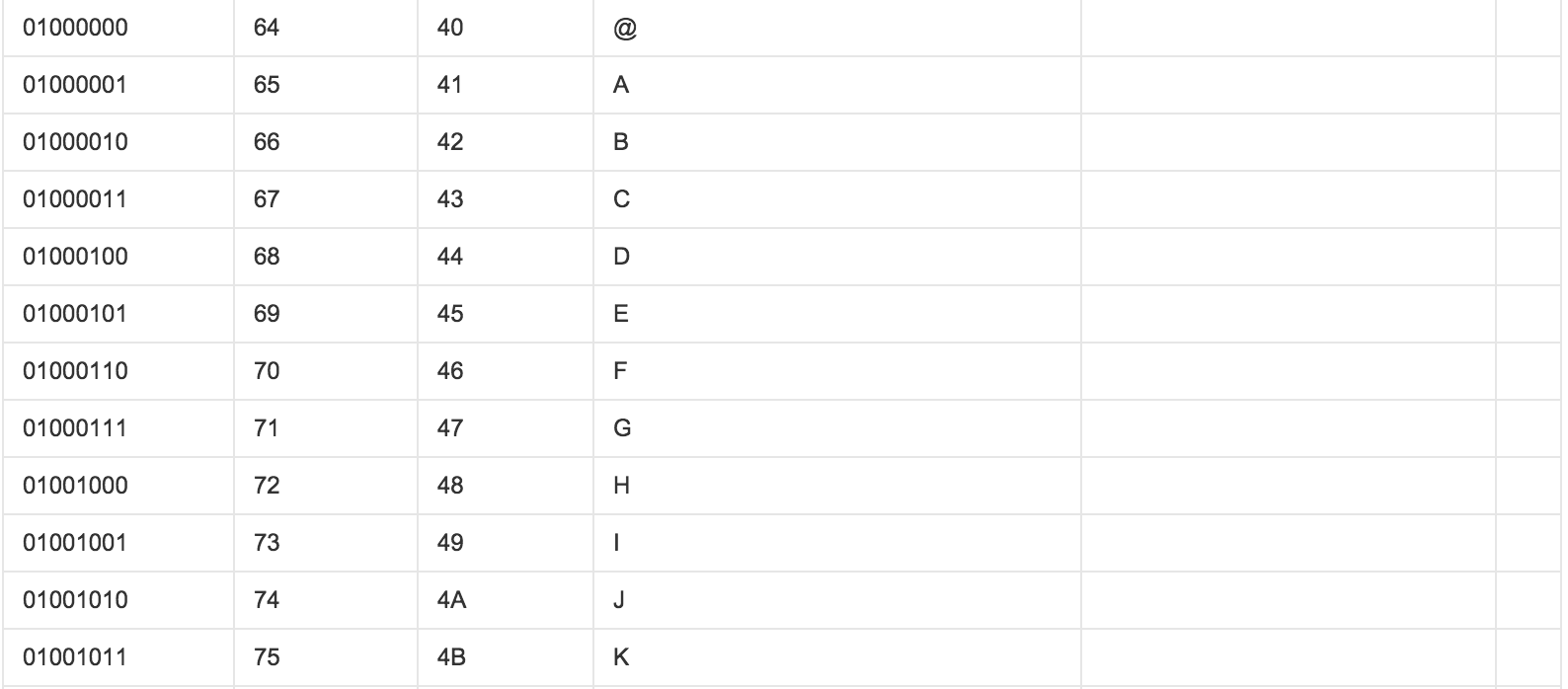
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
|
1
2
3
|
#!/usr/bin/env python print "你好,世界" |
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
|
1
2
3
4
|
#!/usr/bin/env python# -*- coding: utf-8 -*- print "你好,世界" |
提示:python3默认所有的编码都为utf-8,所以"--*--coding:utf-8--*--"可以省略。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:

浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
二.数据类型
计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值。但是,计算机能处理的远不止数值,还可以处理文本、图形、音频、视频、网页等各种各样的数据,不同的数据,需要定义不同的数据类型。在Python中,能够直接处理的数据类型有以下几种:
1.整数
Python可以处理任意大小的整数,当然包括负整数,在程序中的表示方法和数学上的写法一模一样,例如:1,100,-8080,0,等。计算机由于使用二进制,所以,有时候用十六进制表示整数比较方便,十六进制用0x前缀和0-9,a-f表示,例如:0xff00,0xa5b4c3d2,等。
2.浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x109和12.3x108是完全相等的。浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(除法难道也是精确的?是的!),而浮点数运算则可能会有四舍五入的误差。
3.字符串
字符串是以单引号'或双引号"括起来的任意文本,比如'abc',"xyz"等等。请注意,''或""本身只是一种表示方式,不是字符串的一部分,因此,字符串'abc'只有a,b,c这3个字符。如果'本身也是一个字符,那就可以用""括起来,比如"I'm OK"包含的字符是I,',m,空格,O,K这6个字符。
如果字符串内部既包含'又包含"怎么办?可以用转义字符\来标识,比如:'I\'m \"OK\"!'
4.转义字符
转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\.
如果字符串里面有很多字符都需要转义,就需要加很多\,为了简化,Python还允许用r''表示''内部的字符串默认不转义,例如:

如果字符串内部有很多换行,用\n写在一行里不好阅读,为了简化,Python允许用'''...'''的格式表示多行内容,例如:

5.布尔值
布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写)。
布尔值可以用and、or和not运算。
and运算是与运算,只有所有都为True,and运算结果才是True:

or运算是或运算,只要其中有一个为True,or运算结果就是True:

not运算是非运算,它是一个单目运算符,把True变成False,False变成True:

5.空值
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
三.变量
在Python中,等号=是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量,例如:

变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。例如Java是静态语言,赋值语句如下(// 表示注释):
int a = 123; // a是整数类型变量
a = "ABC"; // 错误:不能把字符串赋给整型变量
和静态语言相比,动态语言更灵活,就是这个原因。
四.常量
所谓常量就是不能变的变量,比如常用的数学常数π就是一个常量。在Python中,通常用全部大写的变量名表示常量:PI = 3.14159265359
五.格式化
最后一个常见的问题是如何输出格式化的字符串。我们经常会输出类似'亲爱的xxx你好!你xx月的话费是xx,余额是xx'之类的字符串,而xxx的内容都是根据变量变化的,所以,需要一种简便的格式化字符串的方式。
在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
>>> 'Hello, %s' % 'world'
'Hello, world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'
你可能猜到了,%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
>>> '%2d-%02d' % (3, 1)
' 3-01'
>>> '%.2f' % 3.1415926
'3.14'
如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True)
'Age: 25. Gender: True'
有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
>>> 'growth rate: %d %%' % 7
'growth rate: 7 %'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号