为什么自动驾驶领域发论文都是用强化学习算法,但是实际公司里却没有一家使用强化学习算法?—— (特斯拉今年年初宣布推出实际上第一款纯端到端的自动驾驶系统,全部使用强化算法,替换掉30万行C++的rule-based代码)
为什么自动驾驶领域发论文都是用强化学习算法,但是实际公司里却没有一家使用强化学习算法?—— (特斯拉今年年初宣布推出实际上第一款纯端到端的自动驾驶系统,全部使用强化算法,替换掉原有的30万行C++的rule-based代码)
给出一个自己比较认可的答案:
https://www.zhihu.com/question/547768388/answer/2622883313

总结一下:
基于RL的自动驾驶更像是一种技术探索选择,属于技术战略类型的,而实际情况是:规则 + 传统控制,已经cover 99%场景。
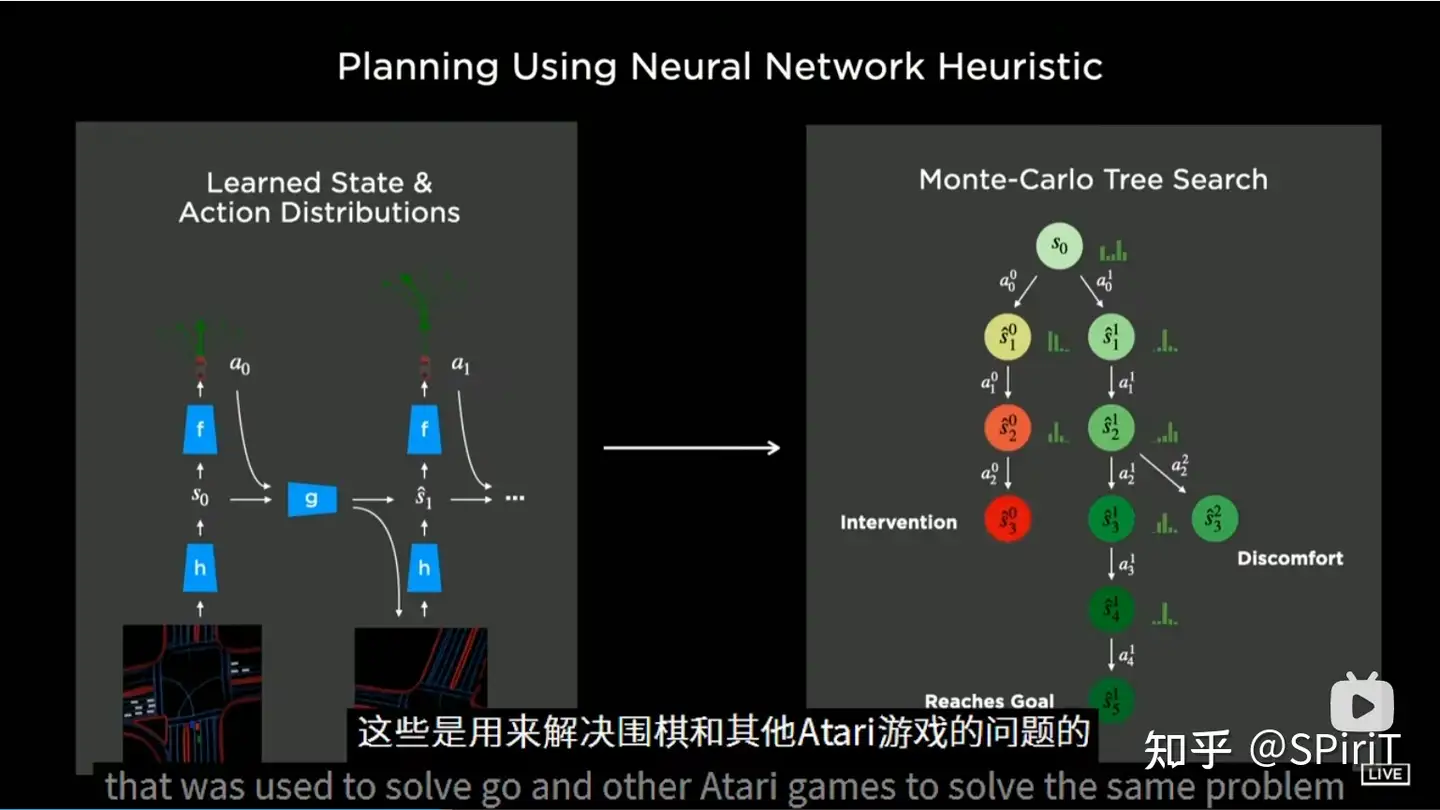
补充:
根据一些透露的资料显示,特斯拉使用RL算法并不是同其他企业那样大部分依赖于仿真环境下生成的数据,而是在结合仿真数据的基础上大部分使用真实驾驶环境下的数据进行训练,根据美国的一些YouTuber上传的视频显示特斯拉使用的端到端的强化学习算法的自动驾驶技术有着明显的“老司机”的感觉,更加贴近人类的驾驶习惯,而这是其他公司的rule-based自动驾驶系统所达不到的水平。
本博客是博主个人学习时的一些记录,不保证是为原创,个别文章加入了转载的源地址,还有个别文章是汇总网上多份资料所成,在这之中也必有疏漏未加标注处,如有侵权请与博主联系。
如果未特殊标注则为原创,遵循 CC 4.0 BY-SA 版权协议。
posted on 2024-04-24 12:00 Angry_Panda 阅读(209) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号