Agent开发概述
1 AI应用的技术发展
1.1 LLM(裸大模型调用)
简单理解类似于后端接口调用,直接返回response body。处理逻辑如下图所示:

1.2 Chatbot(简易聊天机器人)
Chatbot,即聊天机器人,最出名的应该是ChatGPT了,2022年底横空出世,自此开启了全球AI加速化的浪潮。
Chatbot的实现原理,其实就是在裸大模型调用上封装了一层,从后端接口调用,变成了界面可视化的Chatbot。当然,Chatbot的每一轮对话,都会包含系统提示词+历史对话+最新一轮的用户提示词。
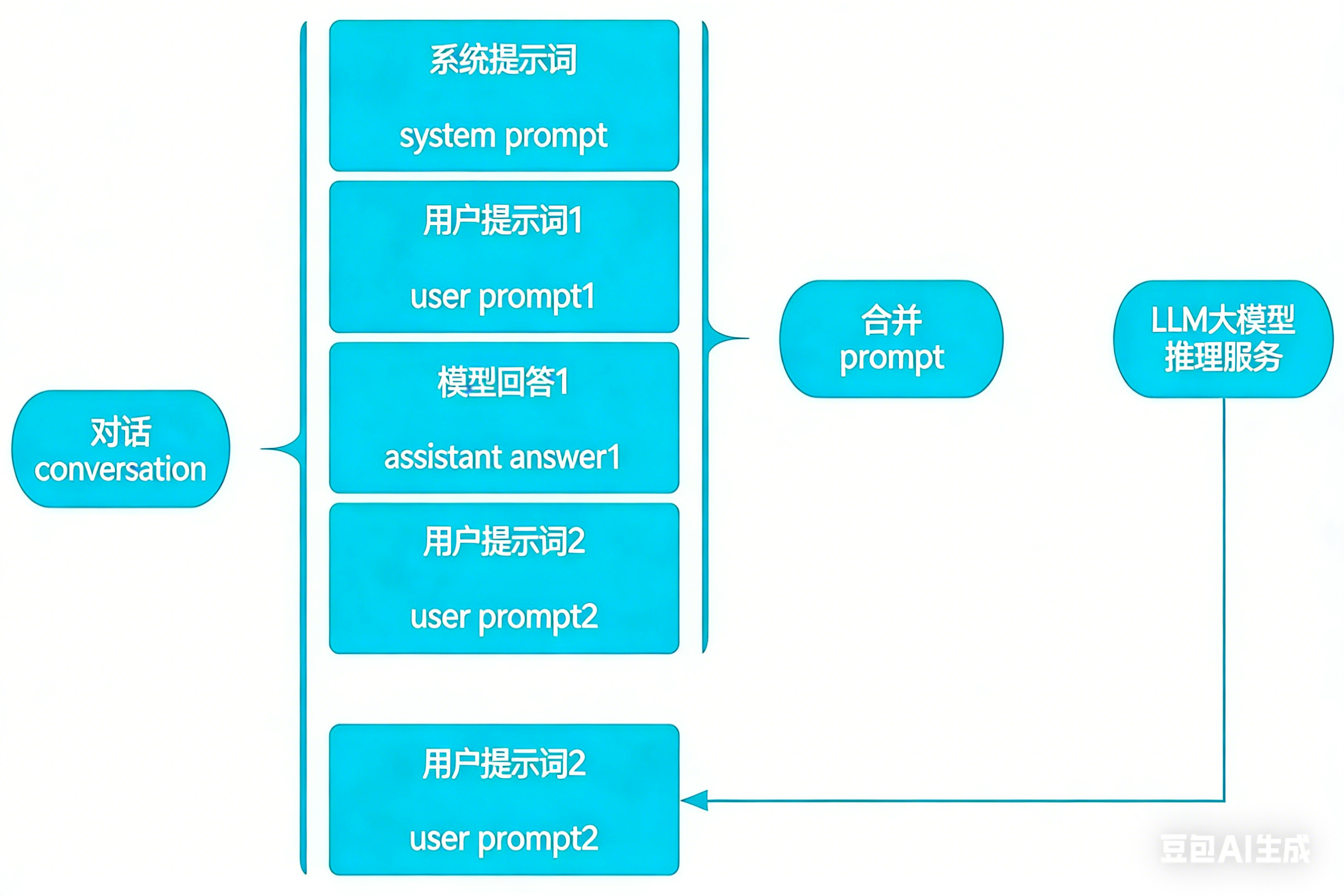
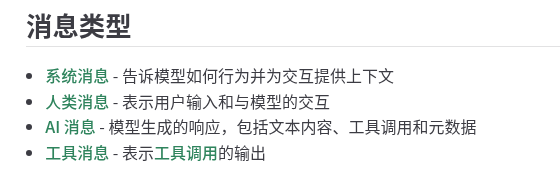
各大模型对不同类型的消息的权重/上下文处理不同,这意味着有时手动创建新的 AIMessage 对象并将其插入消息历史中就像来自模型一样很有帮助。
OpenAI对于不同消息类型的权重解释:https://platform.openai.com/docs/guides/text#message-roles-and-instruction-following

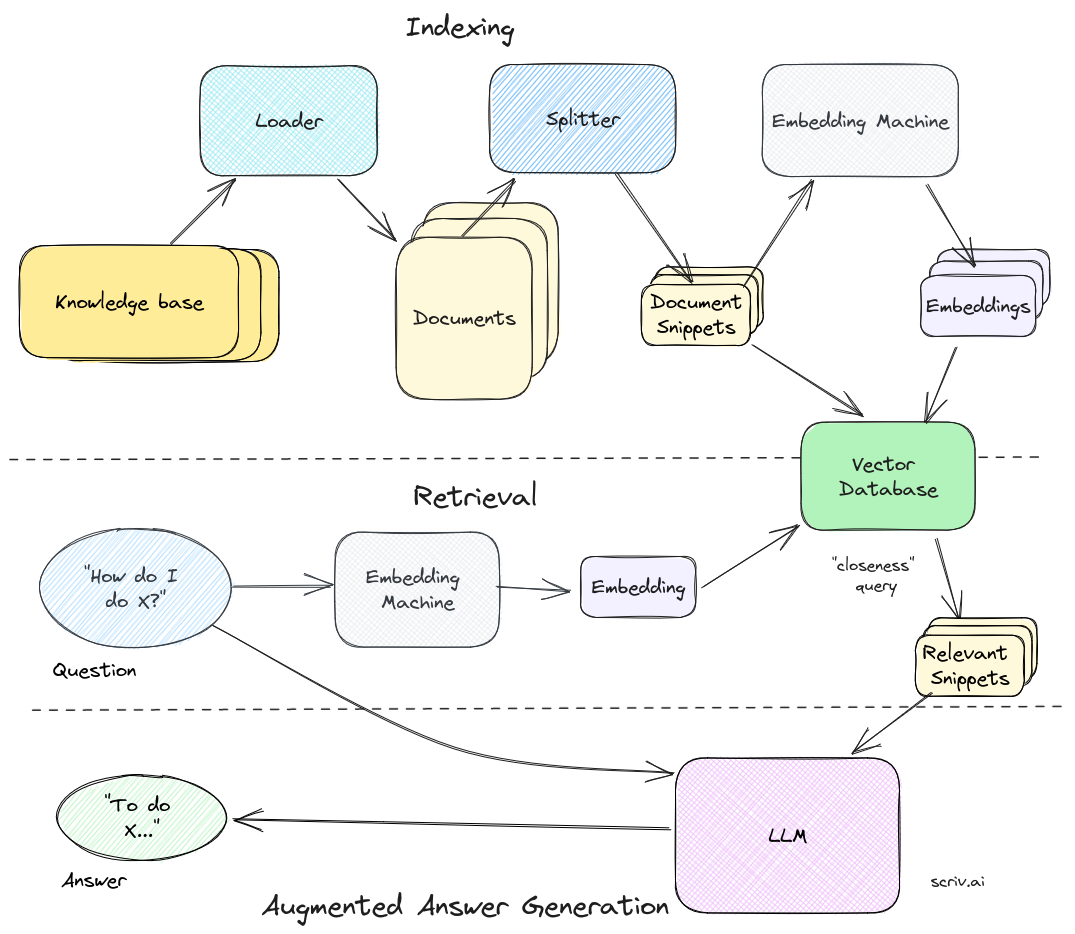
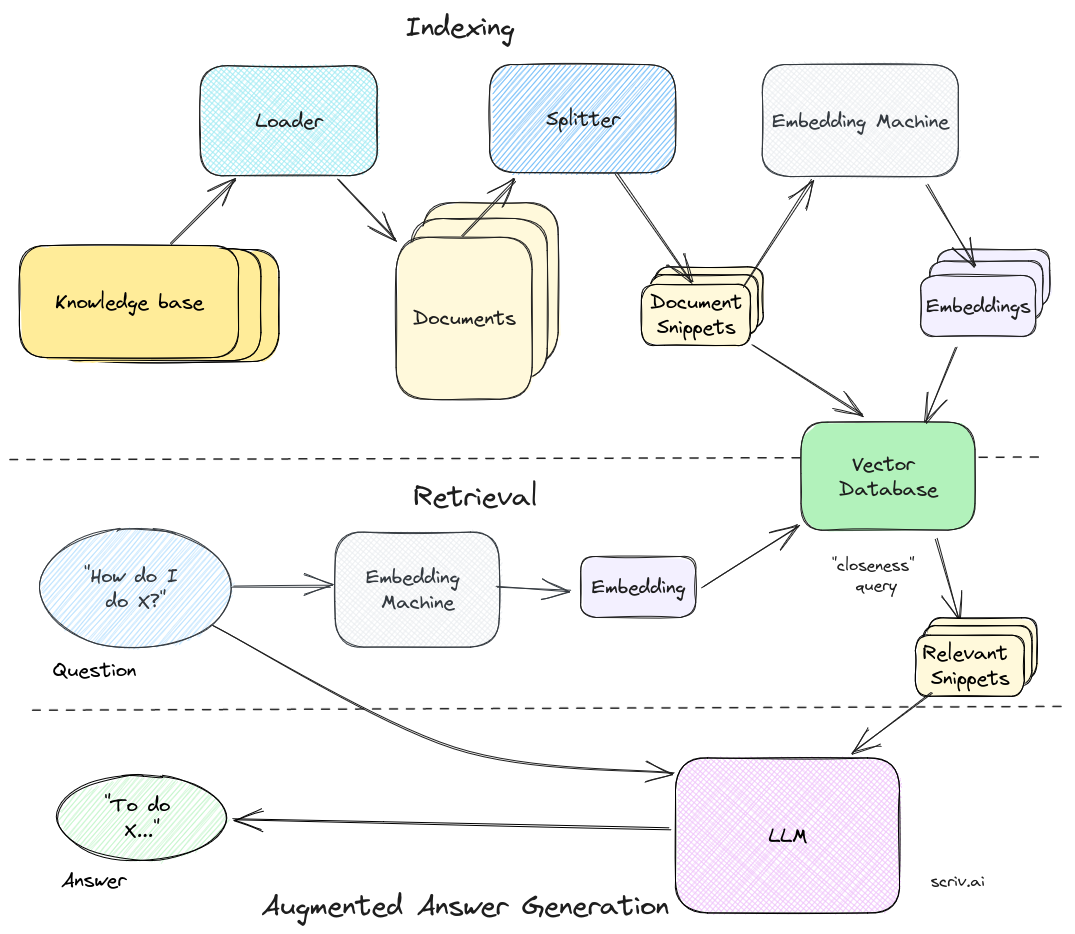
1.3 RAG(检索增强生成)
动态注入外部知识,实现检索增强生成
1.4 Agent(智能体)
大模型从此能够帮我们干活
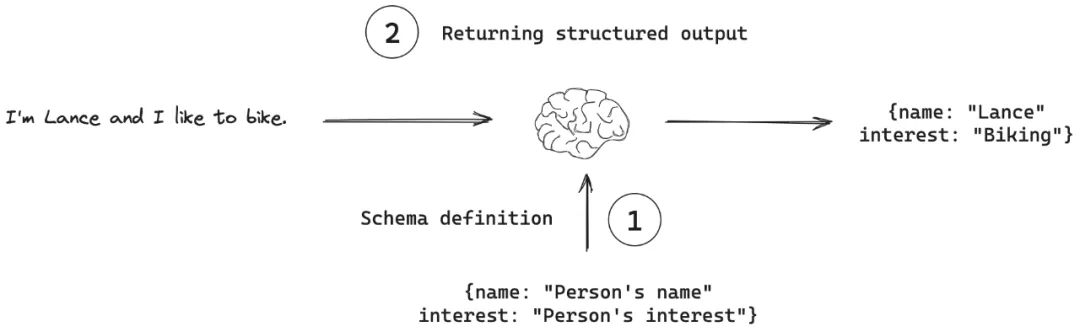
1.5 Structured output(结构化输出)
结构化输出指的是LLMs生成符合特定、预定义格式的响应的能力,而非仅仅是自由格式的文本。
结构化输出能力是模型工程与传统软件工程的关键交互接口
Structured output的几种实现方式
https://mp.weixin.qq.com/s/bT5Z9HBgLl2I4Ylbxklw0A
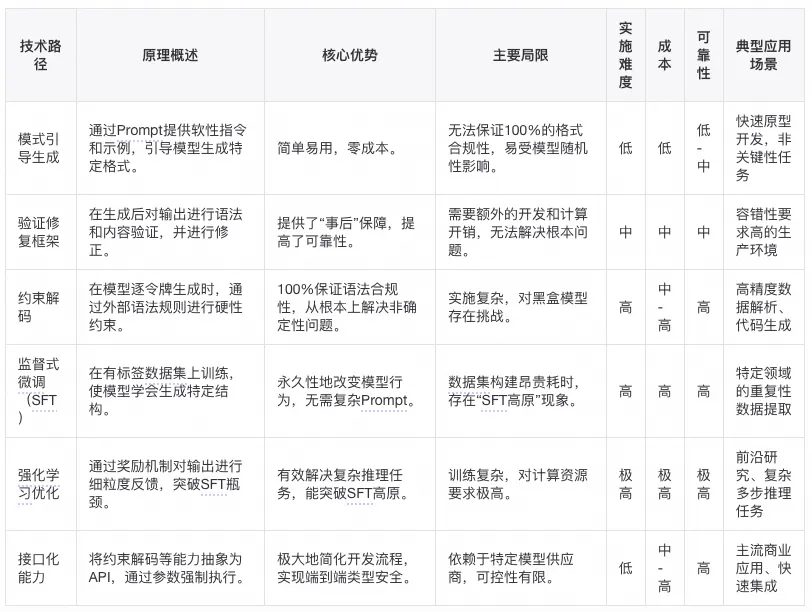
一、模式引导生成
1.1 原理与实践:Prompt工程的艺术与科学
其核心原理是利用精心设计的提示词(Prompt),向模型提供明确的指令、具体的格式要求,甚至通过提供示例来引导模型生成符合预期结构的内容 。
1.2 局限性与非确定性分析
根据研究,单纯依赖Prompt工程的可靠性可能仅能达到约85.1% 。仅依赖Prompt是远远不够的,必须引入更强的控制机制。
二、验证与修复框架
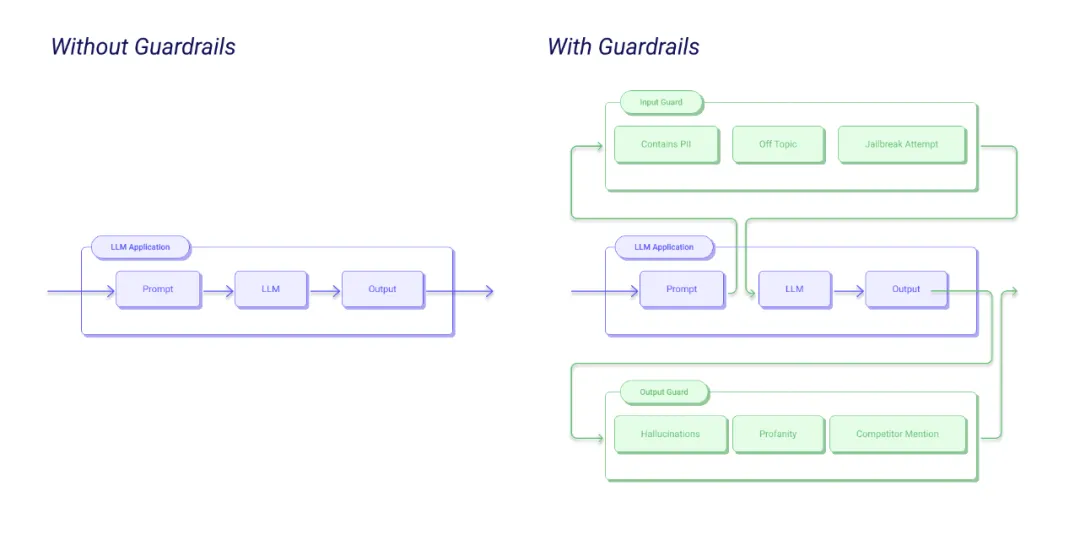
鉴于模式引导生成的非确定性,验证与修复框架在模型生成响应之后对其进行验证和修复,构成了确保LLM结构化输出在生产环境中常用的工程化方法。
现代框架如guidance,Guardrails,通过结构化格式声明(如Pydantic或RAIL)和自动修复技术来处理LLM输出的不可靠性 。
三、其他深度学习方法
四、接口化能力
近年来,主流大语言模型提供商(如OpenAI、Grok等)已将结构化输出作为其核心API能力进行内化,标志着这项技术从一个“研究课题”或“工程挑战”演变为一个“商业化商品”。
JSON模式(JSON Mode): 2023年,OpenAI等平台推出了JSON Mode,通过一个简单的参数设置,强制模型只输出JSON格式。然而,这种模式无法保证输出遵循特定的架构(schema)。
完整结构化输出(Structured Outputs): 随着GPT-4o和Grok等新一代模型的发布,接口化能力得到了极大提升。开发者现在可以直接通过API调用,将Pydantic模型或JSON Schema作为参数传入,由模型保证返回的响应完全符合预定义的架构。这项能力将底层的约束解码等复杂技术抽象化,为开发者提供了端到端的类型安全(Type-safe)和一致性保障。
约束输出(Constraining outputs ):GPT-5 支持为自定义工具提供上下文无关文法(CFG),通过 Lark 文法来限制输出的语法或 DSL 格式。附加一个 CFG(例如 SQL 或 DSL 文法),可以确保助手生成的文本符合你的文法规则。这使得能够进行精确、受约束的工具调用或结构化响应,在 GPT-5 的函数调用中直接实施严格的语法或领域特定格式,从而提升对复杂或受限领域的控制性和可靠性。
Constraining outputs
from openai import OpenAI
client = OpenAI()
grammar = """
start: expr
expr: term (SP ADD SP term)* -> add
| term
term: factor (SP MUL SP factor)* -> mul
| factor
factor: INT
SP: ""
ADD: "+"
MUL: "*"
%import common.INT
"""
response = client.responses.create(
model="gpt-5",
input="Use the math_exp tool to add four plus four.",
tools=[
{
"type": "custom",
"name": "math_exp",
"description": "Creates valid mathematical expressions",
"format": {
"type": "grammar",
"syntax": "lark",
"definition": grammar,
},
}
]
)
print(response.output)
总结:
1.6 Function calling(函数调用)
没有Function calling之前,Agent对于工具的调用,需要在提示词里显示声明,工具调用参数的结构化文本,再由程序做规则化解析。
Function calling将工具调用下沉为模型能力,提供API调用,意图理解与调用成功率大幅提升。
Function calling的说明工具调用时序
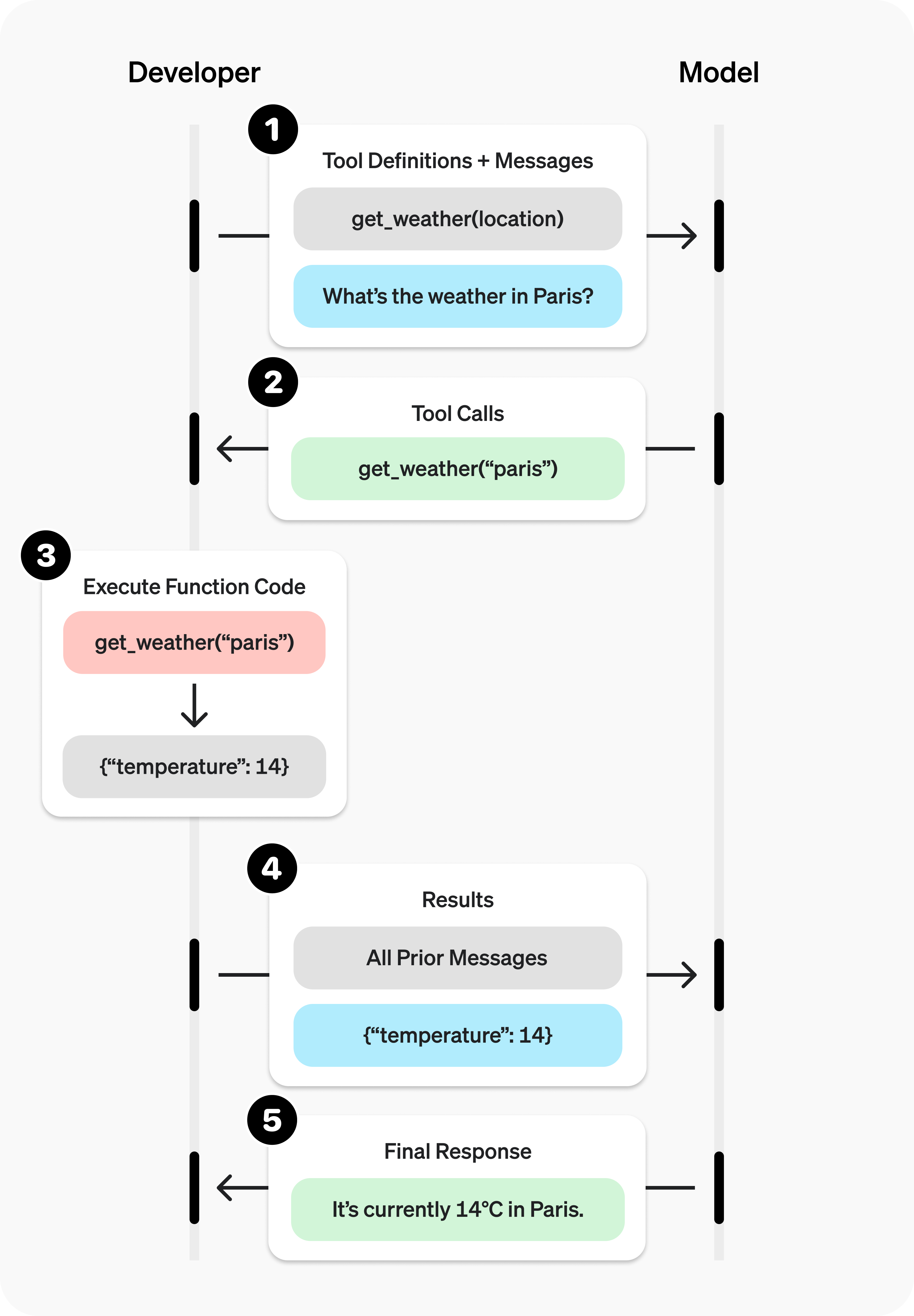
OpenAI工具调用示例
from openai import OpenAI
import json
client = OpenAI()
# 1. Define a list of callable tools for the model
tools = [
{
"type": "function",
"name": "get_horoscope",
"description": "Get today's horoscope for an astrological sign.",
"parameters": {
"type": "object",
"properties": {
"sign": {
"type": "string",
"description": "An astrological sign like Taurus or Aquarius",
},
},
"required": ["sign"],
},
},
]
def get_horoscope(sign):
return f"{sign}: Next Tuesday you will befriend a baby otter."
# Create a running input list we will add to over time
input_list = [
{"role": "user", "content": "What is my horoscope? I am an Aquarius."}
]
# 2. Prompt the model with tools defined
response = client.responses.create(
model="gpt-5",
tools=tools,
input=input_list,
)
# Save function call outputs for subsequent requests
input_list += response.output
for item in response.output:
if item.type == "function_call":
if item.name == "get_horoscope":
# 3. Execute the function logic for get_horoscope
horoscope = get_horoscope(json.loads(item.arguments))
# 4. Provide function call results to the model
input_list.append({
"type": "function_call_output",
"call_id": item.call_id,
"output": json.dumps({
"horoscope": horoscope
})
})
print("Final input:")
print(input_list)
response = client.responses.create(
model="gpt-5",
instructions="Respond only with a horoscope generated by a tool.",
tools=tools,
input=input_list,
)
# 5. The model should be able to give a response!
print("Final output:")
print(response.model_dump_json(indent=2))
print("\n" + response.output_text)
1.7 Multi Agent(多智能体)
单Agent指一个独立的Agent,在执行任务时,通常由其自己进行。而多Agent系统是指由多个相互作用的,基于LLM构建的Agent所组成的系统。它们通过共享信息、通信和协调行动来共同解决问题或完成任务。

2 AI Agent简介
2.1 AI Agent概念
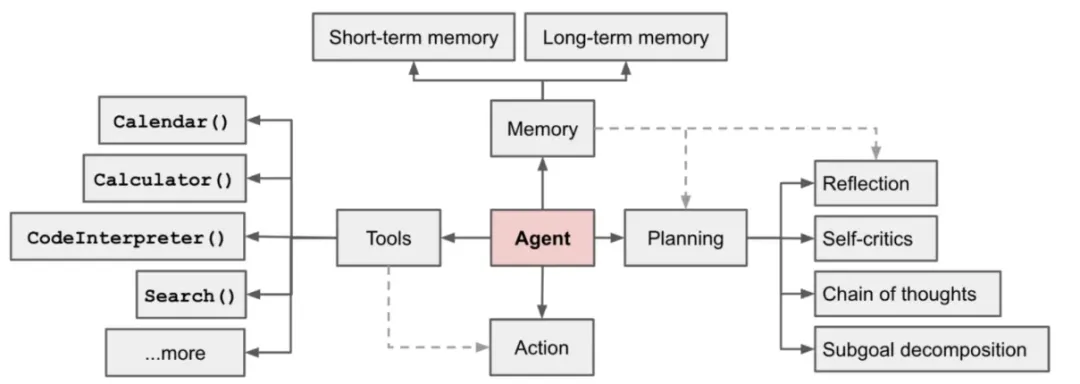
OpenAI的研究主管Lilian Weng给出的定义是:Agent = 大模型(LLM)+ 规划(Planning)+ 记忆(Memory)+ 工具使用(Tool Use)。这个定义实际上是从技术实现的角度对Agent进行了定义,它指的是要实现一个Agent,就需要支持这些能力,它需要基于大模型,需要有规划的能力,能思考接下来要做的事情,需要有记忆,能够读取长期记忆和短期记忆,需要能够使用工具,他是将支持这些能力的集合体定义为了Agent。
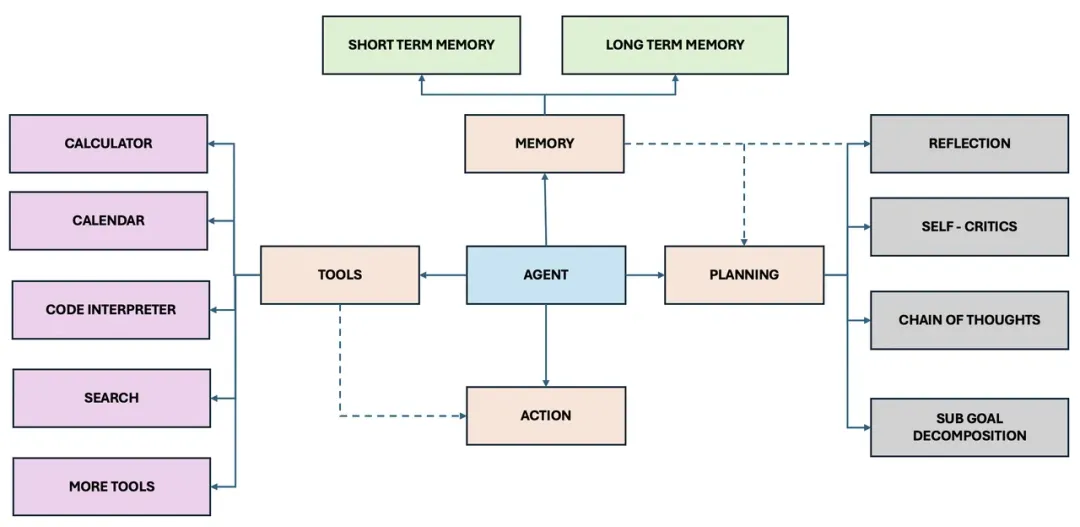
复旦大学NLP团队给出来的,他们认为Agent的概念框架包括三个组件:大脑、感知、行动。大脑模块作为控制器,承担记忆、思考和决策等基本任务。感知模块从外部环境感知并处理多模态信息,而行动模块则使用工具执行任务并影响周围环境。
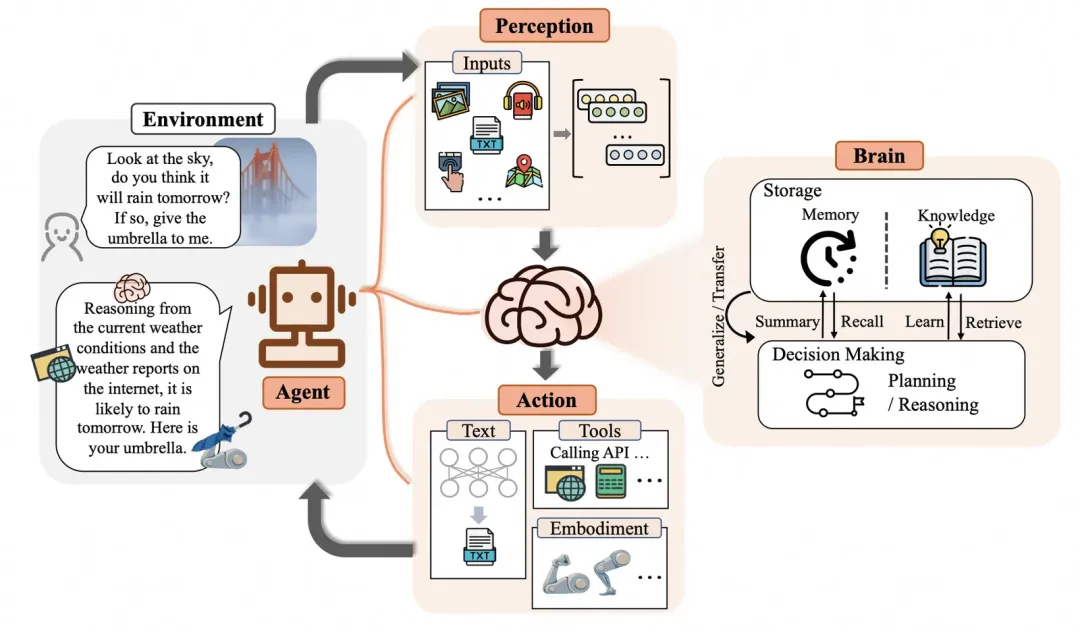
简单来说,Agent代表一个能规划、可思考、有记忆、能使用工具的模块
2.2 AI Agent的典型设计模式
参考文档:
https://mp.weixin.qq.com/s/7CZ6cHWQ-T9bmaWoJFwdwA
https://blog.langchain.com/planning-agents/
2.2.1 ReAct (推理与行动)
概念
ReAct = Reasoning(推理)+ Acting(行动),本质是一种让语言模型通过与外部工具、环境动态交互完成复杂任务的智能体架构范式。其核心目标是打破传统语言模型“输入-输出”的单向链路,构建“感知-决策-执行-反馈”的智能闭环,使模型从“被动应答者”升级为“主动问题解决者”。

从技术本质来看,ReAct并非单一算法,而是“语言模型+工具集+循环调度机制”的集成架构。其核心创新在于将人类解决问题的认知模式(分析-操作-反馈)抽象为机器可执行的框架,使AI具备了自主拆解任务、动态调整策略的能力。
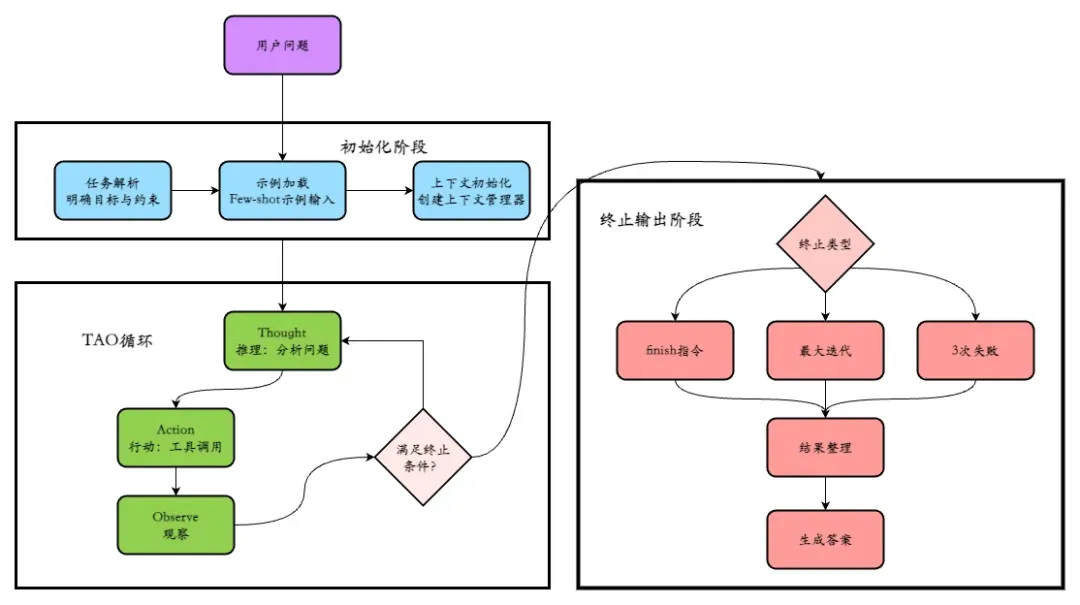
工作原理
ReAct的工作流程可分为“初始化-循环迭代-终止输出”三个阶段,每个阶段的核心操作与逻辑衔接如下,完整展现TAO闭环的动态执行过程:
优缺点
优点: ReAct架构的动态适应性极强,能够根据实时的环境观察灵活调整其行动计划,有效应对不确定性和突发情况(事实上,后面所有的设计模式,本质都是基于 ReAct 的)。其显式的推理轨迹使得整个决策过程高度可解释,这不仅便于开发者进行调试,也增强了用户对Agent的信任度。
缺点: 每次工具调用都需要进行一次LLM推理,这导致ReAct的执行速度相对较慢,并会产生高昂的Token消耗。此外,由于其每次只规划下一步,这种“规划近视”可能导致Agent陷入局部最优解,而无法找到全局最优的行动路径。
2.2.2 Plan & Execute (规划与执行)
概念
https://blog.langchain.com/planning-agents/
Plan & Execute(计划与执行)架构的出现,是对ReAct高成本和低效率问题的一种直接回应。其核心思想在于将Agent的工作流明确地分为两个独立的阶段:一个由功能强大的LLM负责的“规划”阶段,和一个由更轻量级或特定模型负责的“执行”阶段。在规划阶段,LLM一次性生成一个详细的、多步骤的静态计划。随后,执行器会根据这个计划逐一完成每个步骤,而无需每次都调用大型LLM进行决策。
工作原理
与ReAct的主要区别在于,ReAct是动态的、反应式的,每一步都可能重新规划,这赋予了其灵活性;而Plan & Execute则是静态的、预先确定的。它牺牲了ReAct的实时适应性,换来了更高的执行效率和更低的运营成本。这种设计模式通过将“智慧”(规划)与“体力”(执行)解耦,为Agent的实际工程化提供了更具成本效益和可控性的方案。
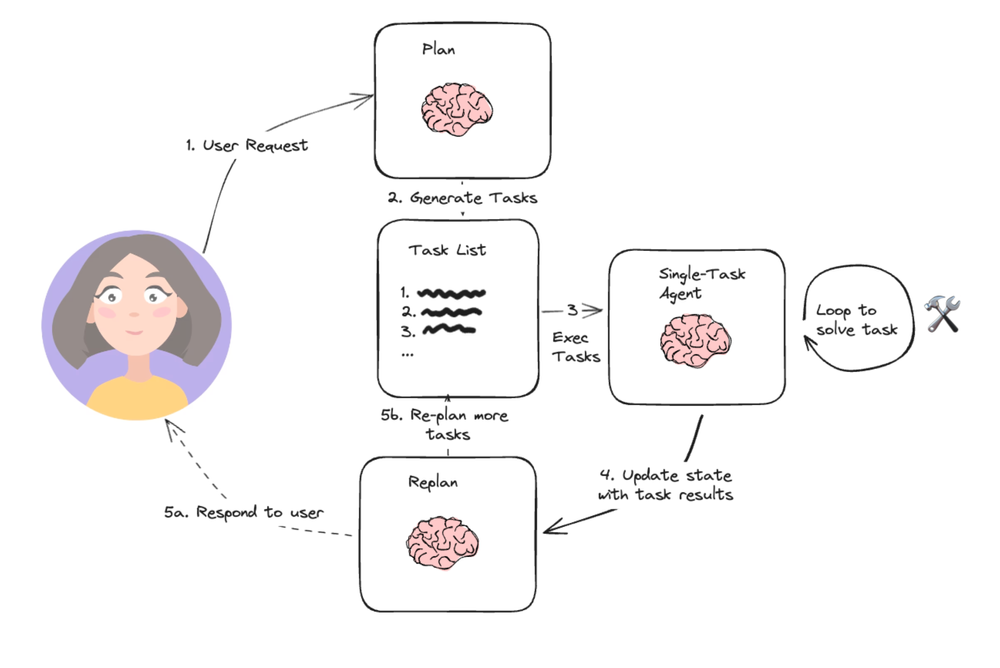
优缺点
优点:
该架构显著减少了对昂贵大型LLM的调用次数,仅在初始规划和当计划失败需要重新规划时才使用,执行阶段可以利用更小、更快的模型,从而实现了更高的效率和成本节约。同时,由于它强制LLM在任务开始时就进行全局思考,有助于避免ReAct可能出现的局部最优问题 。
缺点:
其主要局限在于鲁棒性较差。由于计划是静态的,Agent无法在执行过程中动态应对突发状况或错误,一旦某个步骤失败,除非重新启动整个规划流程,否则无法继续 。此外,许多Plan & Execute的实现仍依赖于串行执行,效率仍有提升空间 。
2.2.3 REWООO (Reasoning Without Observation)
概念与工作原理
ReWOO(Reasoning Without Observation,无观察推理)是Plan & Execute架构的一种高效变体。其核心理念在于,Planner一次性生成一个完整的、包含变量占位符的计划,然后Worker根据该计划执行,并由Solver进行结果汇总 。Planner的输出不仅包含推理步骤,还包括带变量赋值的工具调用,例如 #E1 = Tool[argument]。其中的变量(如#E1)代表前一步骤的输出,可以在后续步骤中直接引用,从而实现了数据的高效传递 。
ReWOO与Plan & Execute的根本区别在于对变量的支持。传统的Plan & Execute在步骤间传递信息效率低下,而ReWOO通过引入变量,避免了在每个子任务执行后再次调用LLM进行数据传递和重新规划,从而显著提升了流程效率 。这种设计模式将编译原理中的“变量”概念引入自然语言计划,实现了更高效的数据流编排。
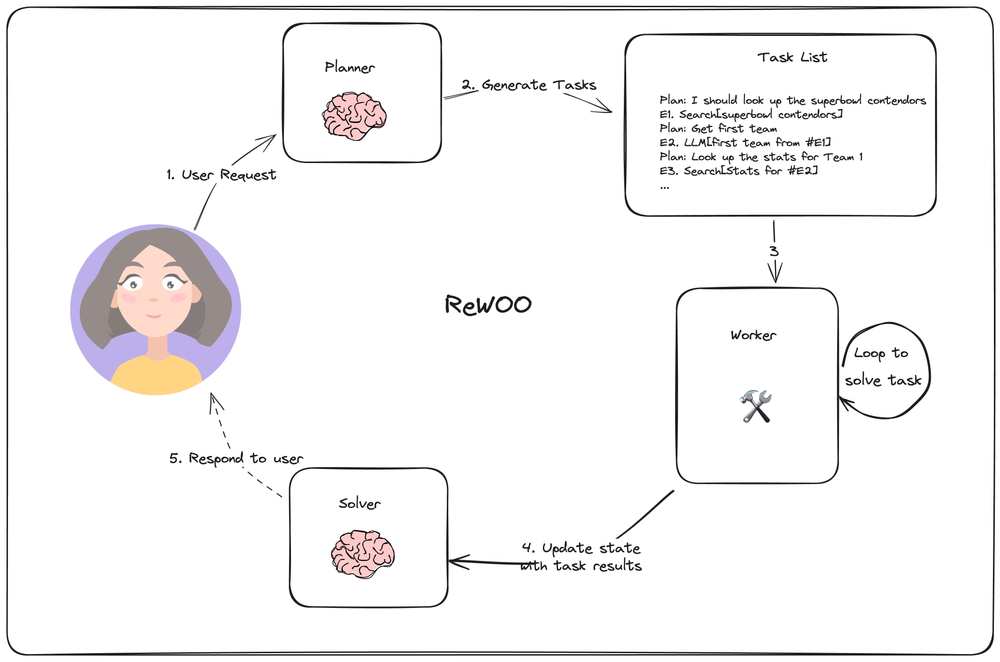
优缺点
优点:
ReWOO通过一次性规划整个任务链,避免了ReAct中反复调用LLM所产生的冗余提示词和历史上下文,因此显著减少了Token消耗,提高了Token效率。此外,由于规划数据在理论上不依赖于工具的实时输出,该架构简化了模型的微调过程 。
缺点:
尽管引入了变量,但其任务执行本质上仍是串行的,无法充分利用可以并行的任务 。与Plan & Execute类似,ReWOO的容错能力较弱,一旦某个任务执行失败,整个流程可能会中断,需要重新开始 。
2.2.4 LLM Compiler
概念与工作原理
https://github.com/SqueezeAILab/LLMCompiler
LLM Compiler架构被设计为进一步提升任务执行速度,其核心思想是让Planner生成一个任务的有向无环图(DAG),而非简单的列表 。这个任务图清晰地定义了所有任务、所需的工具、参数以及任务间的依赖关系。一个独立的任务调度单元会根据这个DAG,自动并行执行所有依赖已满足的任务,从而实现最大化的并发执行,提供显著的速度提升 。
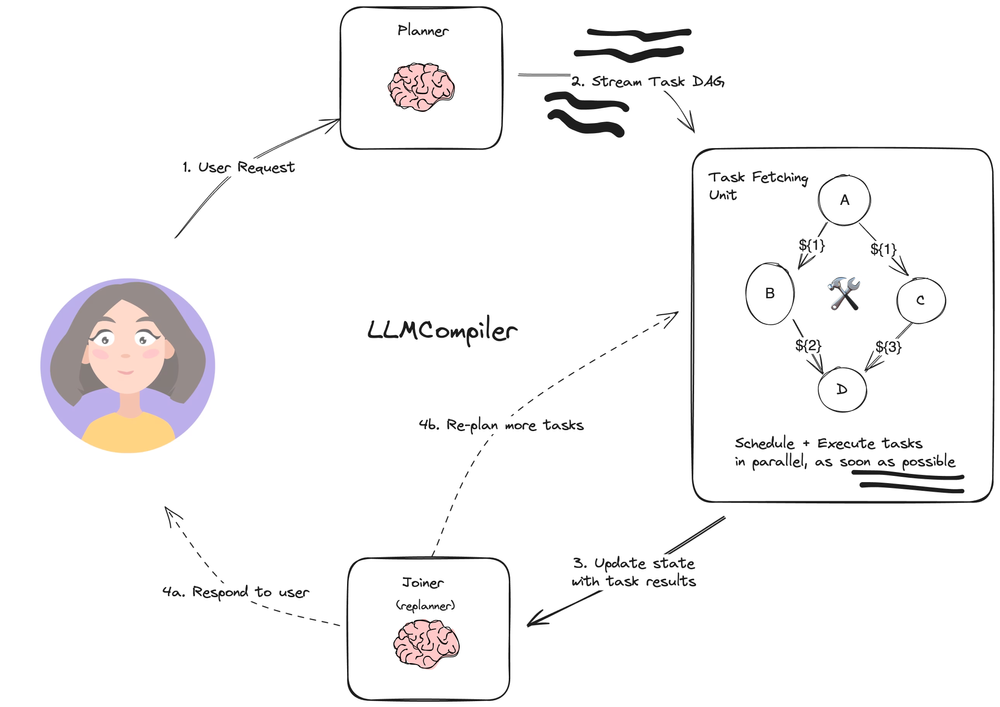
LLM Compiler与ReWOO最根本的区别在于,它从根本上解决了ReWOO的串行执行限制,通过DAG将任务的执行从串行提升到了并行 。这标志着Agent架构的设计开始融合计算机科学中成熟的系统工程和算法优化思想,而非仅仅模仿人类的思维过程。
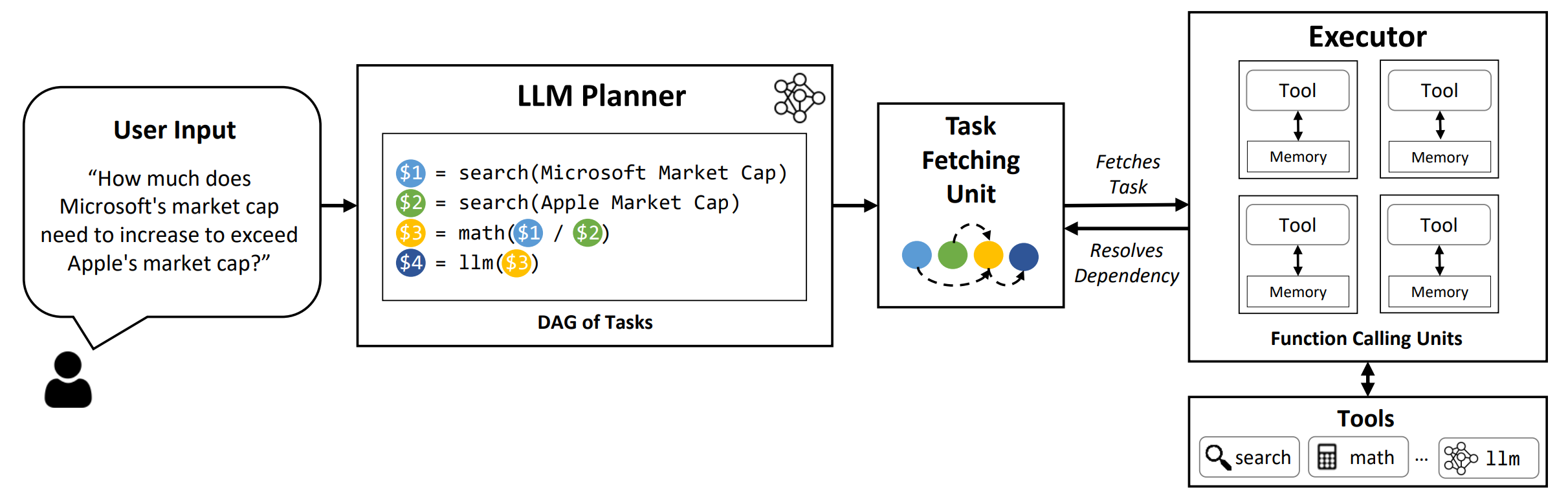
优缺点
优点:
通过并行调用工具,LLM Compiler能够实现极高的执行效率,相比其他规划类方法,可获得显著的速度提升(论文中宣称可达3.6倍) 。这种速度提升也带来了成本节约,因为减少了总体执行时间 。此外,任务图的结构化输出便于理解和调试,提高了可解释性 。
缺点:
该架构的工程实现难度较高,需要构建复杂的任务调度单元和依赖管理机制 。与所有预规划架构类似,LLM Compiler也面临单点任务失败可能导致整个流程中断的风险,鲁棒性仍然是其面临的挑战。
2.2.5 典型应用场景
|
# |
设计模式 |
应用场景 |
示例 |
|---|---|---|---|
|
1 |
ReAct |
典型单Agent的应用场景,与外部环境进行持续交互的场景
|
在知识密集型问答任务中,Agent可以利用搜索引擎API动态检索信息,以验证和补充其内部知识(尤其是那种需要反复查阅的复杂问题,不是现在很多聊天应用上简单的“联网回答”功能)。 在模拟游戏环境或网页浏览等需要多步交互和决策的任务中,ReAct也能够灵活地进行路径探索和任务完成。 |
|
2 |
Plan & Execute |
流程相对固定但步骤繁多、需要调用多种工具或子智能体的复杂任务
|
自动化报告生成、数据分析工作流或保险理赔处理。 在这种预先定义的工作流中,LLM用于处理每个子任务中的模糊性,而整体流程则由静态计划严格控制 |
|
3 |
ReWoo |
需要提升运行效率,可以通过链式调用工具来获取信息,且工具串行调用期间,无需大模型反思的场景。 |
一个多步骤的知识问答任务,如“查询某超级碗球队的四分卫数据”,就需要先查询球队信息,再用结果作为输入去查询四分卫数据。 此外,它也适用于文档摘要和信息提取任务,通过规划多个步骤来处理文档的不同部分,然后将结果汇总。 |
|
4 |
LLM Compiler |
需要同时获取多项独立信息或调用多个API以完成任务的场景
|
电商比价、多源数据整合或需要并发执行多个子任务以加速整体流程的应用 |
3 AI应用工程化
3.1 Agent & Workflow
3.1.1 定义
https://arthurchiao.art/blog/build-effective-ai-agent-zh/
https://docs.langchain.com/oss/python/langgraph/workflows-agents
工作流(Workflow):通过预定义的代码路径来编排大模型和和工具
智能体(Agent):大模型动态决定自己的流程及使用什么工具,自主控制如何完成任务
3.1.2 选型建议
|
评估维度 |
工作流(Workflow) |
智能体(Agent) |
|---|---|---|
|
任务特征 |
任务明确、结构化,可拆解为固定子流程 |
任务开放、非结构化,执行路径需动态调整 |
|
决策模式 |
遵循预定义规则与路径,无自主决策能力 |
基于环境反馈自主规划、判断与执行 |
|
可控性与可预测性 |
可控性高,执行过程可预测,调试与优化成本低 |
可控性相对低,灵活性强,但执行结果存在不确定性 |
|
成本与效率 |
执行效率高,资源消耗可预期 |
执行延迟较高,资源消耗随任务复杂度动态变化 |
|
适用场景 |
可标准化执行的场景 |
无法预设流程的场景 |
|
典型应用示例 |
数据智能体的意图识别与场景路由 |
数据智能体的自然语句建模场景 |
总体原则
-
如果任务可以预先设计出合理的执行流程,就优先使用工作流,因为它更高效、低成本、可控
-
必要时增加智能体的自主性
-
根据具体业务场景,可以两种结合使用
3.1.3 AI Workflow 的常见范式
|
范式类型 |
核心逻辑 |
图示 |
适用场景 |
典型案例 |
优势与特点 |
|---|---|---|---|---|---|
|
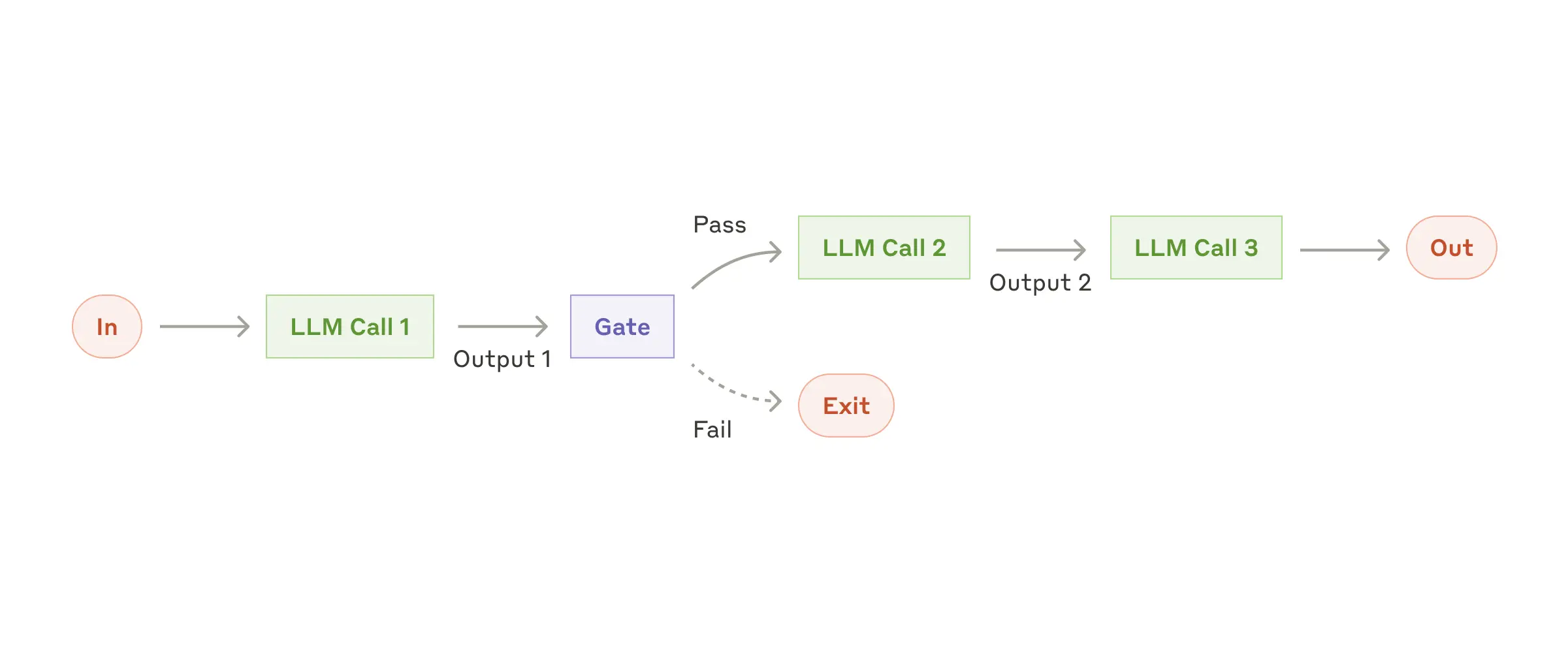
提示链(Prompt chaining) |
将任务拆分为固定子任务,按顺序调用LLM |
|
任务可拆解为明确步骤的场景 |
|
流程清晰、结果可控,易调试优化 |
|
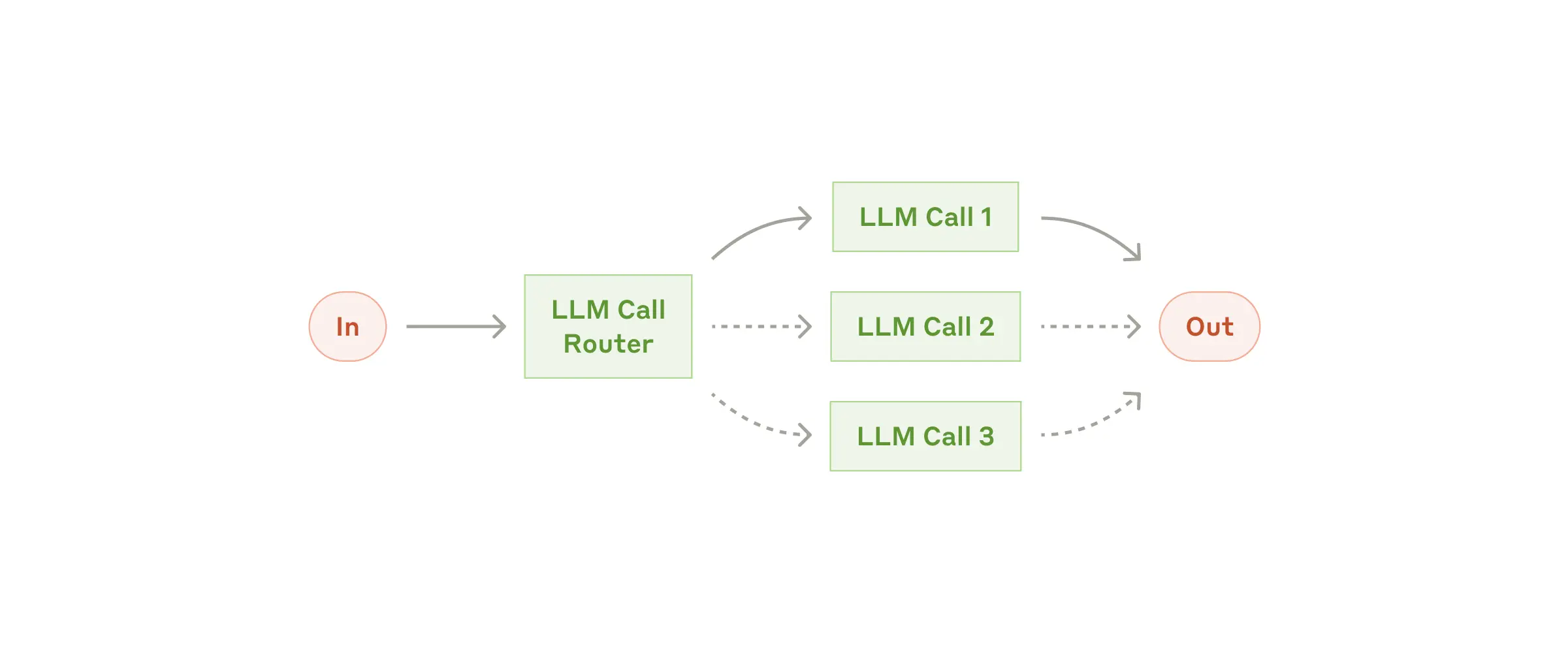
路由(Routing) |
先分类任务,再匹配对应处理逻辑 |
|
任务需差异化处理以提升效率/效果的场景 |
|
资源精准分配,降低无效消耗 |
|
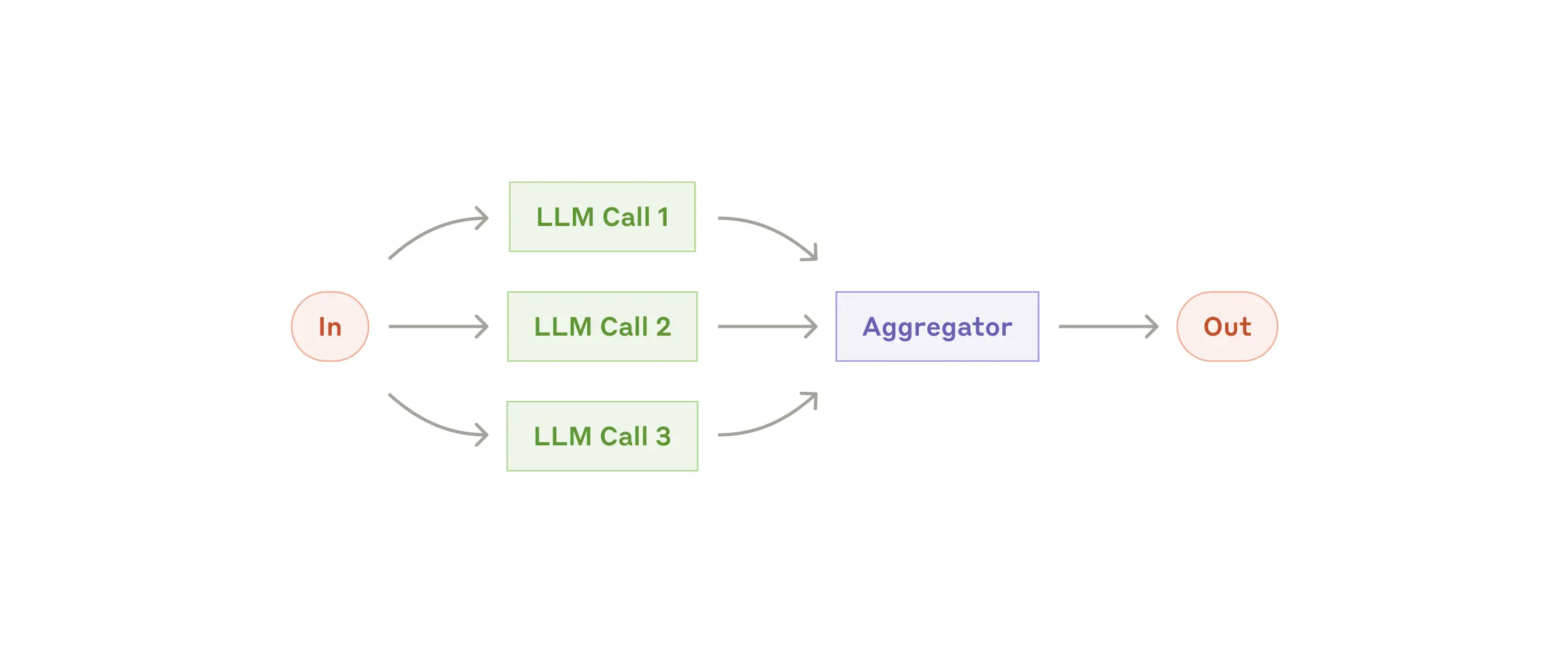
并行化(Parallelization) |
同时执行多个子任务,再汇总结果 |
|
需提速/多视角验证的场景 |
|
缩短总耗时,提升结果可靠性 |
|
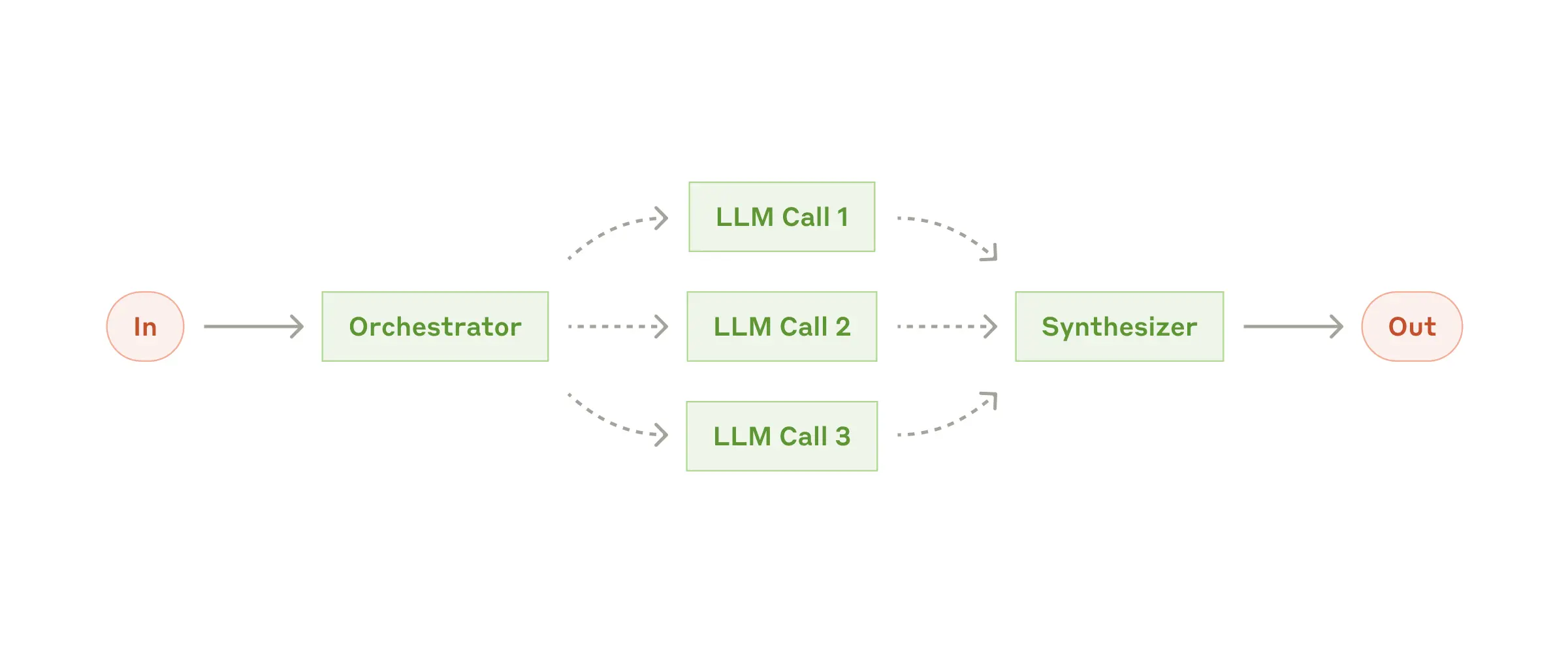
编排者-工作者(Orchestrator-workers) |
编排者拆分任务,分配给不同工作者执行 |
|
子任务类型多样、需多角色协作的场景 |
|
适配复杂多组件任务,扩展性强 |
|
评估者-优化者(Evaluator-optimizer) |
生成结果→评估→迭代优化,循环至达标 |
|
有明确评估标准、需持续改进的场景 |
|
结果质量可控,适配高要求场景 |
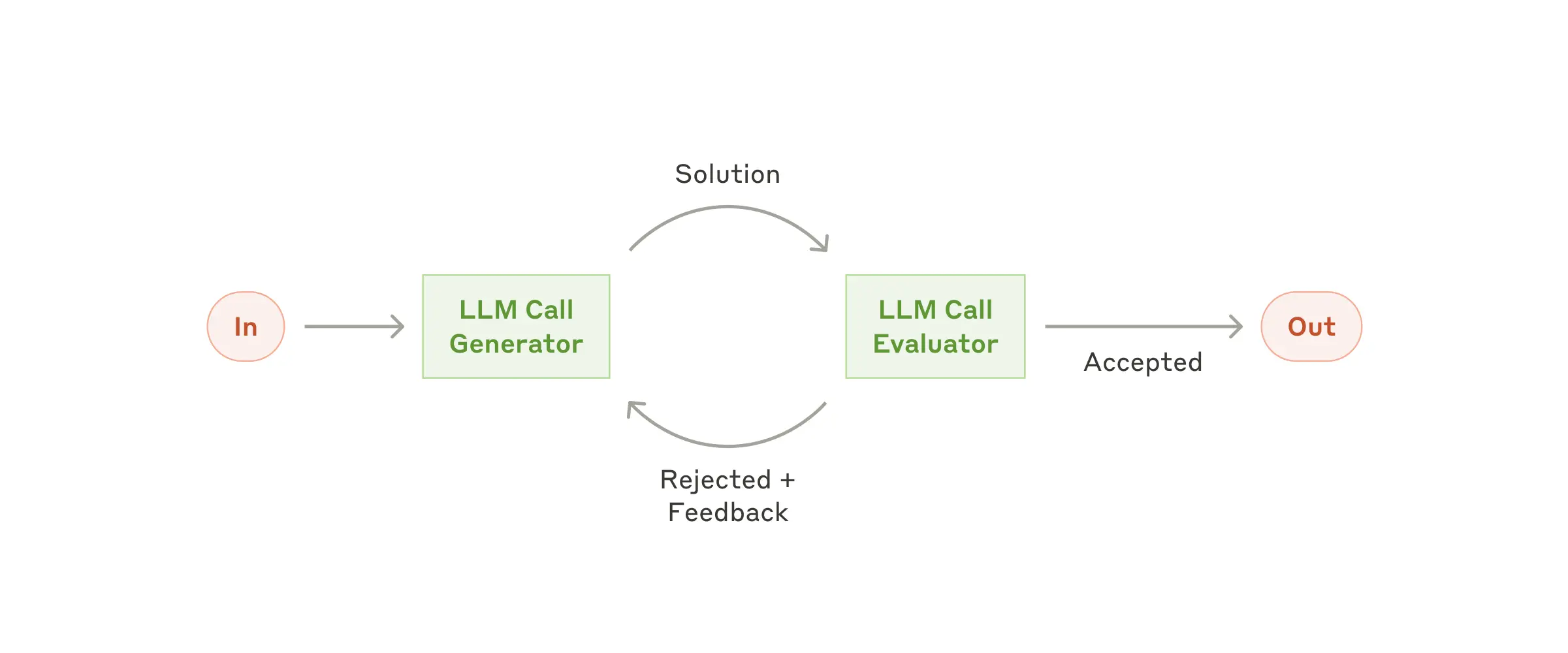
3.2 AI应用开发框架
3.2.1 是否需要智能体框架
引用框架的好处
一个框架的本质,是提供一套经过验证的“规范”。它将所有智能体共有的、重复性的工作(如主循环、状态管理、工具调用、日志记录等)进行抽象和封装,让我们在构建新的智能体时,能够专注于其独特的业务逻辑,而非通用的底层实现。
相比于直接编写独立的智能体脚本,使用框架的价值主要体现在以下几个方面:
-
提升代码复用与开发效率
-
实现核心组件的解耦与可扩展性
-
标准化复杂的状态管理
-
简化可观测性与生产级部署能力
引用框架可能的问题
-
增加抽象性
-
一些框架可能调试困难
-
框架的拓展性,能否很好支撑所需的业务场景
3.2.2 当前主流框架
按开发类别区分:
|
分类 |
代表框架 |
核心关注点 |
目标用户 |
|---|---|---|---|
|
多智能体协作 |
AutoGen, CrewAI, Agno |
Agent间的交互、协作、性能 |
AI研究员、工程师 |
|
LLM应用开发 |
LangChain, PydanticAI |
应用的模块化构建、定制化 |
AI工程师、开发者 |
|
低代码/零代码 |
Dify, Coze, n8n |
快速开发、降低门槛 |
产品经理、业务分析师、非技术人员 |
框架对比:
|
框架名称 |
核心定位 |
技术特性 / 突出优势 |
典型适用场景 |
|---|---|---|---|
|
LangChain/LangGragh |
构建LLM应用的模块化全能框架 |
生态集成极广,组件高度灵活、可定制,提供强大的调试监控工具LangSmith |
需要深度定制和复杂逻辑编排的企业级应用、多步推理的问答系统 |
|
CrewAI |
基于角色分工的多智能体协作框架 |
模拟人类团队协作(如定义研究员、编辑等角色),多智能体协作能力突出 |
内容创作、复杂数据分析、需要多角色协同的自动化任务 |
|
AutoGen |
对话驱动的多智能体框架 |
通过Agent间的自然语言对话协同完成任务,动态性强 |
科研模拟、复杂问题辩论、代码生成与测试等需要动态交互的场景 |
|
Dify |
低代码/可视化AI应用开发平台 |
图形化界面拖拽式开发,上手快,内置RAG引擎和多种Agent模板,开发效率极高 |
快速构建企业知识库问答、智能客服、需要快速原型验证的场景 |
|
Coze |
零代码快速部署平台 |
近乎零门槛,可视化流程设计,插件生态丰富,与字节生态(如飞书)集成深 |
非技术用户快速构建聊天机器人、社交媒体内容管理、轻量级自动化 |
|
n8n |
基于工作流自动化的低代码平台 |
可视化工作流设计,节点丰富,支持 Webhook、API、数据库、AI 模型等多种集成,灵活的触发器和条件分支 |
跨系统数据集成、自动化业务流程、与 AI 工具结合的自动化工作流、轻量级企业级自动化 |
|
PydanticAI |
注重类型安全和数据可靠性的企业级框架 |
建立在Pydantic之上,提供强大的数据验证和类型安全,确保AI交互的可预测性 |
对数据格式和应用程序可靠性要求高的生产级应用 |
|
Agno |
专注于极致性能和低资源消耗的框架 |
宣称代理创建速度极快,内存效率高,支持多模态数据(文本、图像、音频)处理 |
高性能、资源敏感型应用,如实时客户支持、财务分析 |
选型建议:
复杂的企业级 LLM 应用模块化编排:LangChain/LangGragh
纯多智能体协作应用:CrewAI/AutoGen
快速验证与实现、标准化流程编排:Dify/n8n
企业内部框架
3.3 Agent上下文工程
3.3.1 什么是上下文工程
上下文工程是一门设计和构建动态系统的学问,其唯一目标是:在正确的时间、以正确的格式,向大模型精准“投喂”完成任务所需的一切信息和工具。
Google DeepMind 的高级 AI 关系工程师 Philipp Schmid 在他最新的一篇博客(https://www.philschmid.de/context-engineering)里也把上下文工程拆成多个组成模块,包括:
系统提示 / 系统指令:定义行为、规则、例子
用户提示:当前问题或任务
短期记忆 / 对话历史:当前会话内容
长期记忆:跨 session 的用户偏好、项目信息
检索信息(RAG):动态抓取文档、数据库或 API 的内容
可用工具:如 search、send_email 等函数定义
结构化输出:规定格式,如 JSON、表格
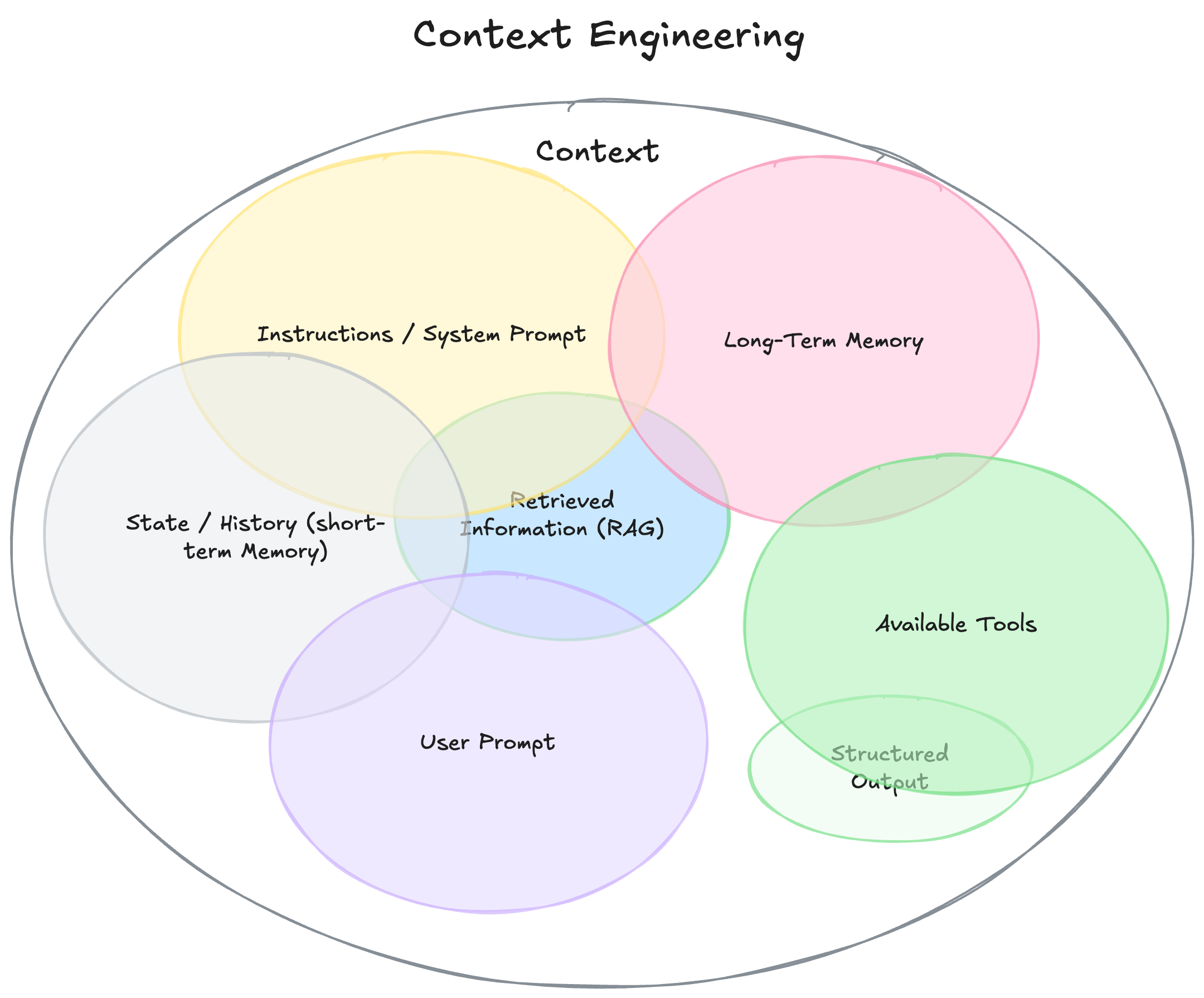
而且归纳出核心具备四大特征:
它是一个动态系统,而非静态字符串。 上下文不是一个写死的“模板”,而是在调用 LLM 前,由 Agent 根据实时需求动态拼装的结果。它是有生命力的。
它按需生成,而非一成不变。 这个请求,上下文可能是你的日程表;下一个请求,可能就需要最新的网页搜索结果或一封关键邮件。它是“千人千面、千时千面”的。
它精准投喂信息与工具,而非信息轰炸。 核心是“刚刚好”,避免“垃圾进、垃圾出”。只提供任务真正需要的信息和能力,多一分都是干扰。
它极度重视格式,而非“生肉”数据。 与其粗暴地丢给模型一堆原始日志,不如给它一段提炼后的摘要;一
3.3.2 上下文工程与提示词工程
提示词工程:
“Prompt”这个词,大家一听,就能到联想到随便让 ChatGPT 干点事,比如“解释一下什么是量子力学”这种简单的提示,再复杂一点的 prompt,加入任务说明、给几个示例、定义输出规则,核心是尽可能清晰地表达你的需求。对于一些简单应用,这种方式便捷与高效。
上下文工程:
随着应用系统的复杂,可能需要精心地去构建上下文(context),这样大模型才能完成复杂、定制化的任务。
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
与写提示词的离散任务不同,上下文工程是迭代的,每次决定传递给模型时都会进入策划阶段。
提示工程的主要关注点是如何编写有效的提示,尤其是系统提示。然而,随着我们向向更强大的智能体设计,能够在多轮推理和更长的时间范围内运行,我们需要管理整个上下文状态的策略(系统指令、工具、 模型上下文协议 (MCP)、外部数据、消息历史等)。
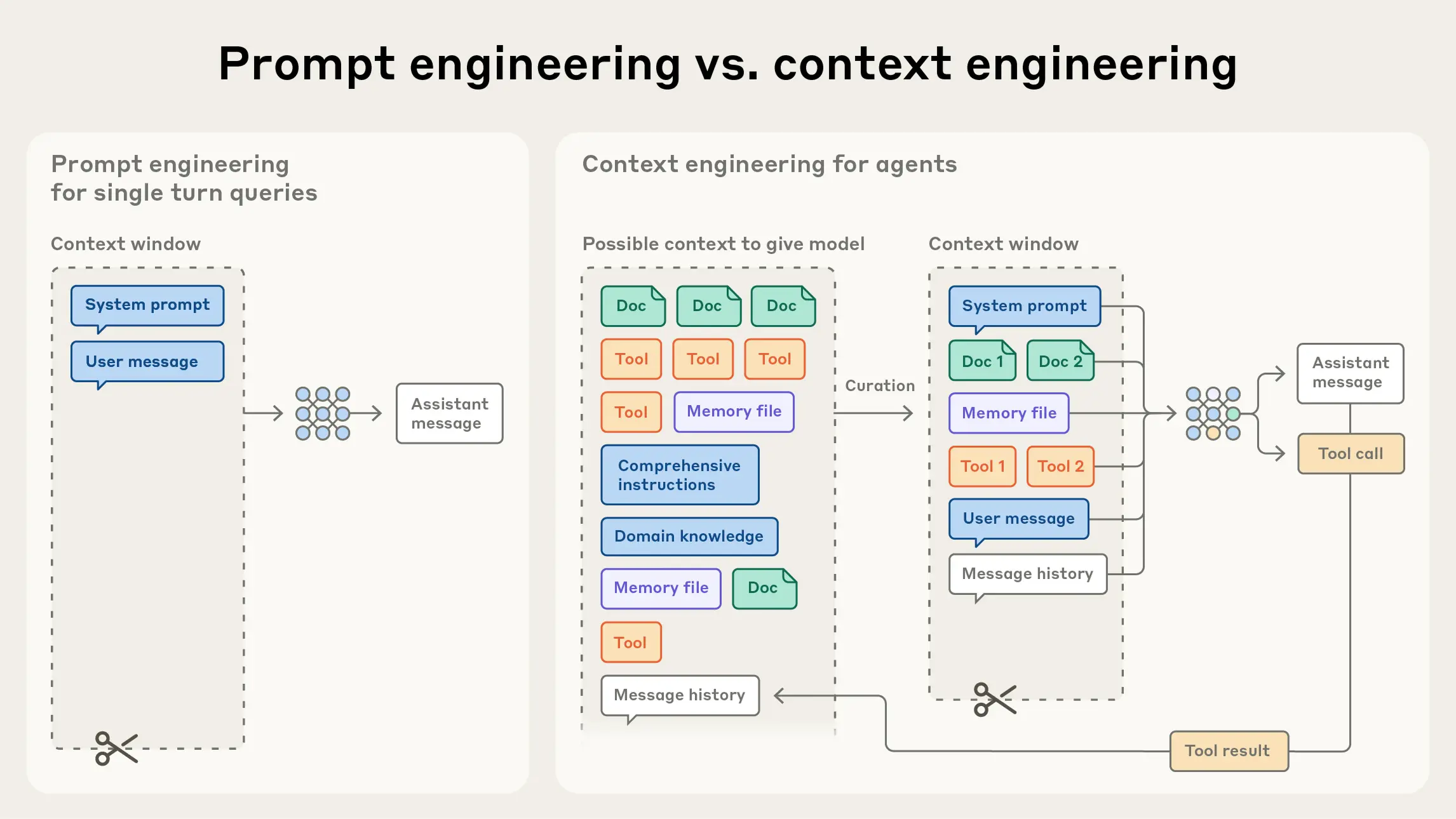
3.3.3 如何上手“上下文工程”
https://blog.langchain.com/context-engineering-for-agents/
https://docs.langchain.com/oss/python/langchain/context-engineering
AI 开发框架 LangChain 发布了一篇博客总结了四大核心落地策略:
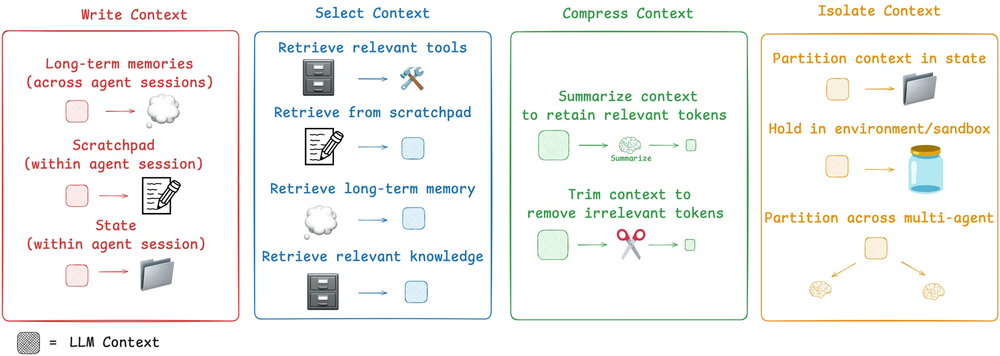
|
策略名称 |
核心目标 |
具体操作 |
应用场景 |
|---|---|---|---|
|
Write Context(编写上下文) |
构建完整的上下文基础 |
|
AI Agent的初始上下文搭建 |
|
Select Context(筛选上下文) |
精准调取相关信息 |
|
需要动态补充信息的任务(如问答) |
|
Compress Context(压缩上下文) |
优化Token使用效率 |
|
上下文长度超出模型Token限制时 |
|
Isolate Context(隔离上下文) |
管理上下文的作用范围 |
|
多Agent协作、复杂任务分模块处理 |
场景与示例:
|
问题 |
核心症状 |
对应解决方案 |
|---|---|---|
|
上下文中毒 |
工具返回错误/幻觉信息,污染后续推理 |
|
|
上下文分心 |
信息过载淹没核心指令,AI抓不住重点 |
|
|
上下文混淆 |
信息格式混乱,AI错误解读内容 |
|
|
上下文冲突 |
上下文包含矛盾信息,AI被迫错误“站队” |
|
3.4 生产级应用
Agent身份认证与授权管理
https://mp.weixin.qq.com/s/8j-lUb3xaiFS8p7oqyL9RQ
Agent质量评估
https://mp.weixin.qq.com/s/lHNYHM5V_ph23frb7v8G2A
Agent评估是指对Agent在执行任务、决策制定和用户交互方面的性能进行评估和理解的过程。由于Agent具有固有的自主性,对其进行评估对于确保其正常运行至关重要。
Agent可观测性评估
https://mp.weixin.qq.com/s/iycWw99MJK7s0dbOHjnFqQ
构建一套从行为洞察到质量评估、从成本监控到闭环优化的多维度可观测框架
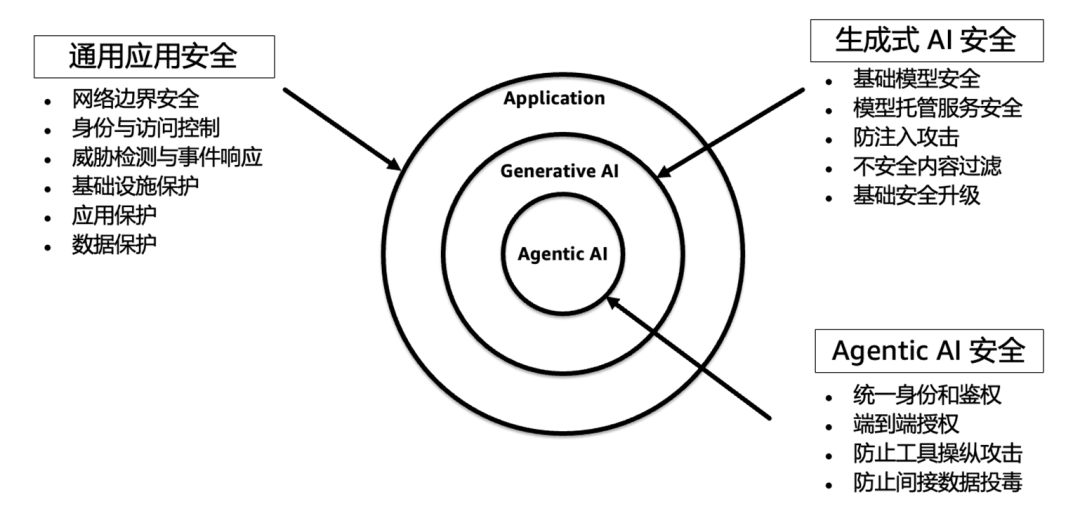
Agent应用隐私与安全
https://mp.weixin.qq.com/s/Bt31I0DPtIeN5xYqaUSYJA
4 AI应用实践

 浙公网安备 33010602011771号
浙公网安备 33010602011771号