
架构师需要具备的技能
一、架构师需要具备的技能
架构师推动是主要的,架构师需要五项全能:技术,沟通,推动,管理,撕逼😃😃😃。
通常情况下,成熟的团队不会轻易改变技术栈,反而是新成立的技术团队更加倾向于采用新技术。
架构师需要对中间件,常见系统,架构场景有自己的深入理解。
成熟的架构师需要对已经存在的技术非常熟悉,对已经经过验证的架构模式烂熟于心,然后根据自己对业务的理解,挑选合适的架构模式进行组合,再对组合后的方案进行修改和调整。
对于架构师来说,常见系统的性能量级需要烂熟于心,例如nginx负载均衡性能是3万左右,mc的读取性能5万左右,kafka号称百万级,zookeeper写入读取2万以上,http请求访问大概在2万左右。
具体的数值和机器配置以及测试案例有关,但大概的量级不会变化很大。
如果是业务系统,由于业务复杂度差异很大,有的每秒500请求可能就是高性能了,因此需要针对业务进行性能测试,确立性能基线,方便后续架构设计做比较。
架构师关注的是一秒的数据,即 TPS 和 QPS。设计的目标应该以峰值来计算。峰值一般取平均值的3倍。
系统设计需要考虑一定的性能余量。为了预留一定的系统容量应对后续业务的发展,我们将设计目标假设为峰值的 4 倍。
->每秒平均值的12倍。
针对“新浪微博”Demo的架构设计方案思考:
我们假设新浪微博系统用户每天发送 1000 万条微博,那么微博子系统一天会产生 1000 万条消息,我们再假设平均一条消息有 10 个子系统读取,那么其他子系统读取的消息大约是 1 亿次。
1000 万和 1 亿看起来很吓人,但对于架构师来说,关注的不是一天的数据,而是 1 秒的数据,即 TPS 和 QPS。我们将数据按照秒来计算,一天内平均每秒写入消息数为 115 条,每秒读取的消息数是 1150 条;再考虑系统的读写并不是完全平均的,设计的目标应该以峰值来计算。峰值一般取平均值的 3 倍,那么消息队列系统的 TPS 是 345,QPS 是 3450,这个量级的数据意味着并不要求高性能。
虽然根据当前业务规模计算的性能要求并不高,但业务会增长,因此系统设计需要考虑一定的性能余量。由于现在的基数较低,为了预留一定的系统容量应对后续业务的发展,我们将设计目标设定为峰值的 4 倍,因此最终的性能要求是:TPS 为 1380,QPS 为 13800。TPS 为 1380 并不高,但 QPS 为 13800 已经比较高了,因此高性能读取是复杂度之一。注意,这里的设计目标设定为峰值的 4 倍是根据业务发展速度来预估的,不是固定为 4 倍,不同的业务可以是 2 倍,也可以是 8 倍,但一般不要设定在 10 倍以上,更不要一上来就按照 100 倍预估。
“高可用存储”要求已经写入的消息在单台服务器宕机的情况下不丢失;“高可用读取”要求已经写入的消息在单台服务器宕机的情况下可以继续读取。架构师第一时间想到的就是可以利用 MySQL 的主备复制功能来达到“高可用存储“的目的,通过服务器的主备方案来达到“高可用读取”的目的。
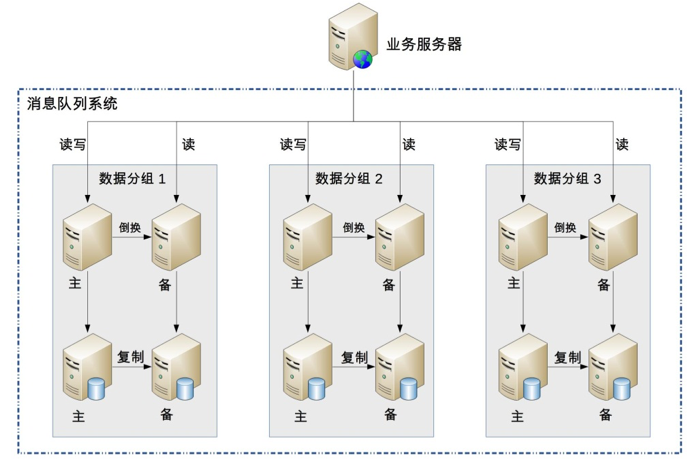
当业务增长,原来单机房的集群设计不满足业务需求了,需要升级为异地多活的架构。
二、技能知识点
Hadoop 能够将高可用、高性能、大容量三个大数据处理的复杂度问题同时解决。
微服务架构,是解决了可扩展性。
NoSQL:Key-Value 的存储和数据库的索引其实是类似的,Memcache 只是把数据库的索引独立出来做成了一个缓存系统。Hadoop 大文件存储方案,基础其实是集群方案 + 数据复制方案。Docker 虚拟化,基础是 LXC(Linux Containers)。LevelDB 的文件存储结构是 Skip List。
Kafka :是成熟的开源消息队列方案,功能强大,性能非常高,而且已经比较成熟,很多大公司都在使用。
Kafka 的设计目的是为了支撑大容量的日志消息传输,而我们的消息队列是为了业务数据的可靠传输。
Netty :是 Java 领域成熟的高性能网络库,架构师可以选择用Java开发基于 Netty 开发消息队列系统。
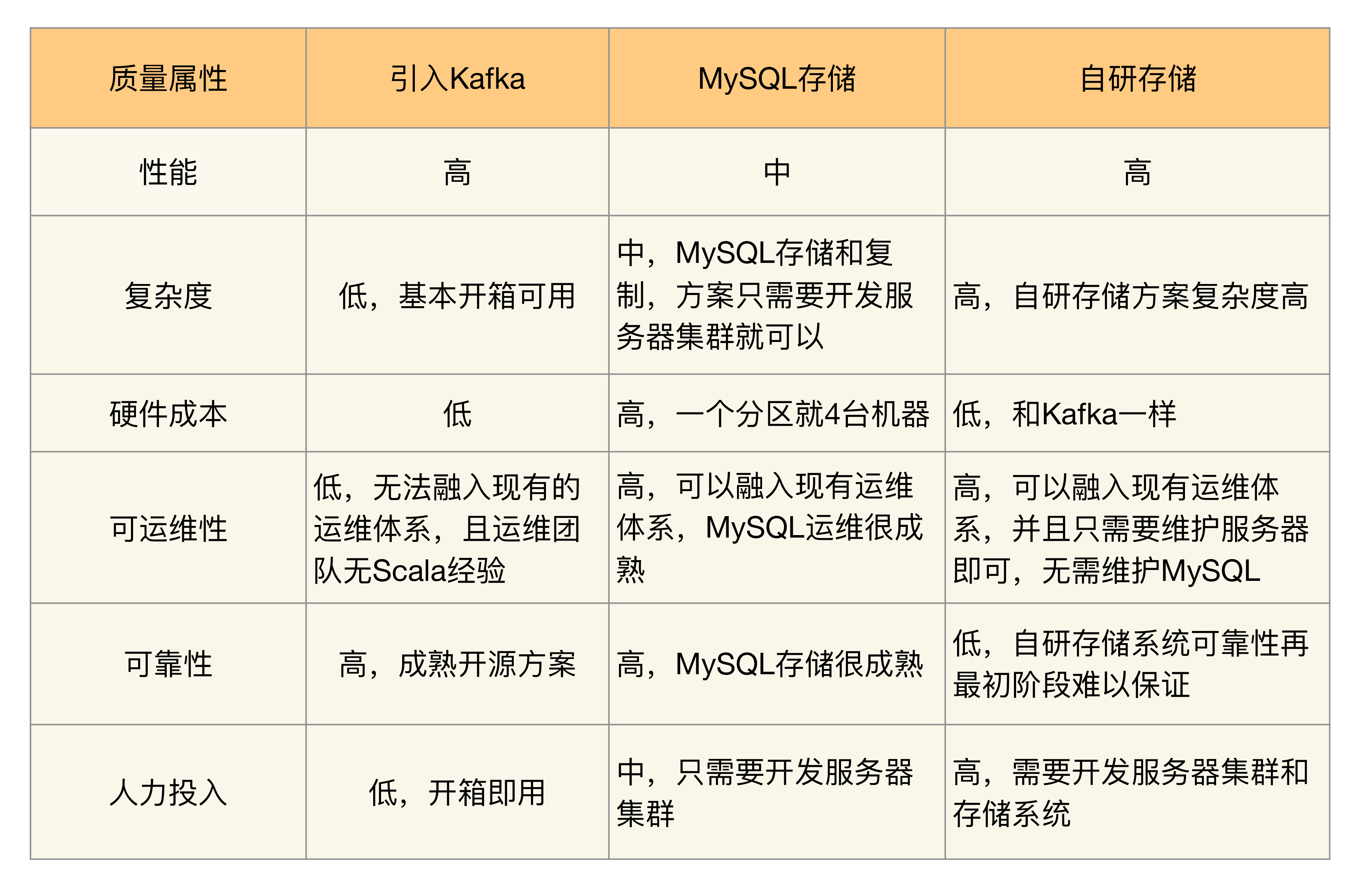
开源方案选择可能就包括 Kafka、ActiveMQ、RabbitMQ;集群方案的存储既可以考虑用 MySQL,也可以考虑用 HBase,还可以考虑用 Redis 与 MySQL 结合等;自研文件系统也可以有多个,可以参考 Kafka,也可以参考 LevelDB,还可以参考 HBase 等。
MySQL: 主备复制功能。使用 MySQL 来存储消息数据,性能肯定不如使用文件系统。
三、RocketMQ 和 Kafka 有什么区别,阿里为何选择了自己开发 RocketMQ?
Kafka针对海量数据,但是对数据的正确度要求不是十分严格。
而阿里巴巴中用于交易相关的事情较多,对数据的正确性要求极高,Kafka不合适,然后就自研了RocketMQ。
RocketMQ可以理解为是Java版的kafka,两者比较类似😄
1、数据可靠性
kafka使用异步刷盘方式,异步Replication
RocketMQ支持异步刷盘,同步刷盘,同步Replication,异步Replication
(存疑:有人说:kafka同步刷盘同步复制早支持了,同步复制不会有乱序。)
2、严格的消息顺序
Kafka支持消息顺序,但是一台Broker宕机后,就会产生消息乱序
RocketMQ支持严格的消息顺序,在顺序消息场景下,一台Broker宕机后,发送消息会失败,但是不会乱序
3、消费失败重试机制
Kafka消费失败不支持重试
RocketMQ消费失败支持定时重试,每次重试间隔时间顺延
4、定时消息
Kafka不支持定时消息
RocketMQ支持定时消息
5、分布式事务消息
Kafka不支持分布式事务消息
阿里云ONS支持分布式定时消息,未来开源版本的RocketMQ也有计划支持分布式事务消息
6、消息查询机制
Kafka不支持消息查询
RocketMQ支持根据Message Id查询消息,也支持根据消息内容查询消息(发送消息时指定一个Message Key,任意字符串,例如指定为订单Id)
7、消息回溯
Kafka理论上可以按照Offset来回溯消息
RocketMQ支持按照时间来回溯消息,精度毫秒,例如从一天之前的某时某分某秒开始重新消费消息
………
RocketMQ 和 Kafka 有什么区别?
(1) 适用场景
Kafka适合日志处理;RocketMQ适合业务处理。
(2) 性能
Kafka单机写入TPS号称在百万条/秒;RocketMQ大约在10万条/秒。Kafka单机性能更高。
(3) 可靠性
RocketMQ支持异步/同步刷盘;异步/同步Replication;Kafka使用异步刷盘方式,异步Replication。
RocketMQ所支持的同步方式提升了数据的可靠性。
(4) 实时性
均支持pull长轮询,RocketMQ消息实时性更好
(5) 支持的队列数
Kafka单机超过64个队列/分区,消息发送性能降低严重;
RocketMQ单机支持最高5万个队列,性能稳定(这也是适合业务处理的原因之一)。
3 为什么阿里会自研RocketMQ?
(1) Kafka的业务应用场景主要定位于日志传输;对于复杂业务支持不够
(2) 阿里很多业务场景对数据可靠性、数据实时性、消息队列的个数等方面的要求很高
(3)当业务成长到一定规模,采用开源方案的技术成本会变高(开源方案无法满足业务的需要;旧版本、自开发代码与新版本的兼容等)
(4) 阿里在团队、成本、资源投入等方面约束性条件几乎没有。
1、架构上RocketMQ不依赖zk,而Kafka重度依赖zk;2、RocketMQ没有完全开源的,有一些功能需要自己重写;而Kafka应用广泛,社区支持力度大,这样对运维压力和成本会小很多。
人少或者没有统一的运维体系,kafka是最稳妥的选择
