linux网络编程(八)UDP网络编程
一、UDP编程框架
使用 UDP 进行程序设计可以分为客户端和服务器端两部分。
服务器端主要包含建立套接字、将套接字与地址结构进行绑定、读写数据、关闭套接宇几个过程。
客户端包括建立套接字、读写数据、关闭套接字几个过程。
服务器端和客户端两个流程之间的主要差别在于对地址的绑定 bind() 函数,客户端可以不用进行地址和端口的绑定操作。
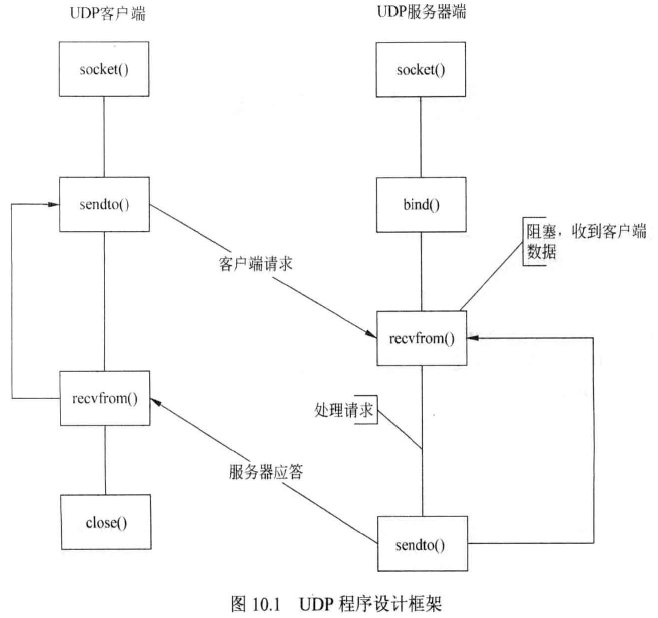
UDP 协议的程序设计框架如图 10.1 所示,客户端和服务器之间的差别在于服务器必须使用 bind() 函数来绑定侦昕的本地 UDP 端口,而客户端则可以不进行绑定,直接发送到服务器地址的某个端口地址。
与TCP程序设计相比较,UDP缺少了connect()、listen()及accept()函数,这是用于UDP协议无连接的特性,不用维护TCP的连接、断开等状态。
1.UDP协议的服务器端流程
UDP协议的服务器端程序设计的流程分为套接字建立、套接字与地址结构进行绑定、收发数据、关闭套接字等过程,分别对应于函数socket()、bind()、sendto()、recvfrom()和close()。
建立套接字过程使用socket()函数,这个过程与TCP协议中的含义相同,不过建立的套接字类型为数据报套接字。地址结构与套接字文件描述符进行绑定的过程中,与 TCP 协议中的绑定过程不同的是地址结构的类型。 当绑定操作成功后,可以调用 recvfrom() 函数从建立的套接字接收数据或者调用 sendto() 函数向建立的套接字发送网络数据。 当相关的处理过程结束后,需要调用 close() 函数关闭套接字。
2.UDP协议的客户端流程
UDP 协议的服务器端程序设计的流程分为套接字建立、收发数据、关闭套接字等过程,分别对应于函数 socket()、 sendto()、 recvfrom() 和 close()。
建立套接字过程使用 socket() 函数,这个过程与 TCP 协议中的含义相同,不过建立的 套接字类型为数据报套接字。 建立套接字之后,可以调用函数 sendto() 向建立的套接字发送数据或者调 recvfrom() 函数从建立的套接字收网络数据。 当相关的处理过程结束后,需要调用 close() 函数关闭套接字。
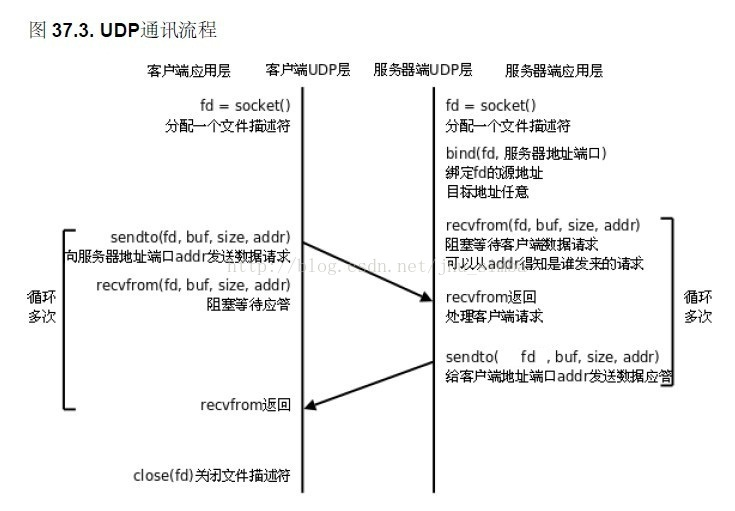
UDP通信流程的回射客户/服务器:

二、UDP协议程序设计的问题
由于 UDP 协议缺少流量控制等机制,容易出现些难以解决的问题。 UDP 的报文丢失、报文乱序、connect()函数、流量控制、外出网络接口的选择等是比较容易出现的问题
1.UDP报文丢失
当路由器要对转发的数据进行存储、处理、合法性判定、转发等操作,容易出现错误,所以很可能在路由器转发的过程中出现数据丢失的现象,如图 10.10 所示。当UDP的数据报文丢失的时候,函数recvfrom()会一直阻塞,直到数据到来。
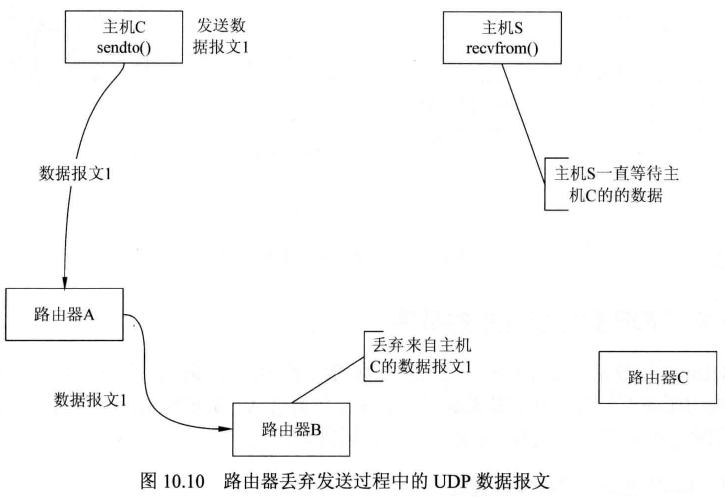
在UDP服务器客户端的例子中,如果客户端发送的数据丢失,服务器会一直等待, 直到客户端合法数据到来;如果服务器的响应在中间被路由器丢弃,则客户端会一直阻塞,直到服务器数据的到来。在程序正常运行的过程中是不允许出现这种情况的,所以可以设置超时时间来判断是否有数据到来。对于数据丢失的原因,并不能通过一种简单的方法获得。例如,不能区分服务器发给客户端的响应数据是在发送的路径中被路由器丢弃,还是服务器没有发送此响应数据。
1-1.UDP报文丢失的对策
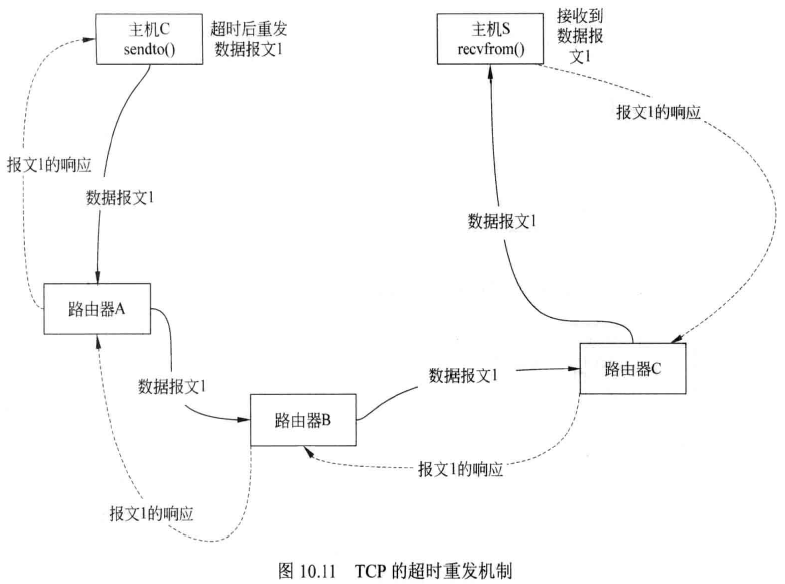
UDP协议中的数据报文丢失是先天性的,因为UDP是无连接的、不能保证发送数据的正确到达。图10.11为TCP连接中发送数据报文的过程,主机C发送的数据经过路由器,到达主机S后,主机S要发送一个接收到此数据报文的响应,主机C要对主机S的响应进行记录,直到之前发送的数据报文1已经被主机S接收到。 如果数据报文在经过路由器的时候,被路由器丢弃,则主机C和主机S会对超时的数据进行重发。
2.UDP数据发送中的乱序
UDP协议数据收发过程中,会出现数据的乱序现象。所谓乱序是发送数据的顺序和接收数据的顺序不一致,例如发送数据的顺序为数据包A、数据包B、数据包C,而接收数据包的顺序变成了数据包B、数据包A、数据包C。
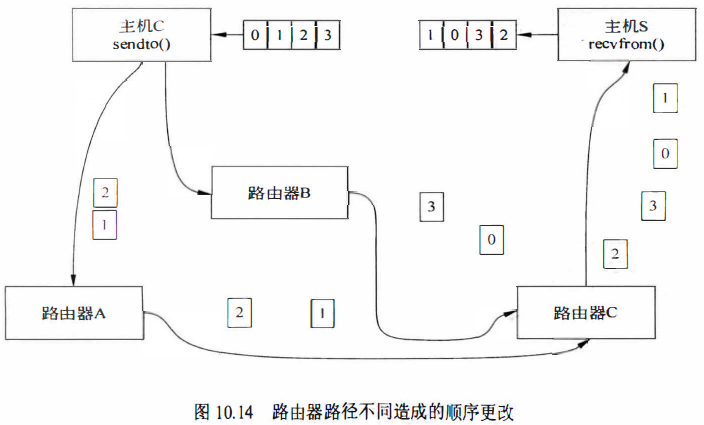
由于路由器的存储转发可能造成数据顺序的更改,UDP协议的数据经过路由器时的路径造成了发送数据的混乱,如图10.14所示。从主机C发送的数据0123,其中数据0和3经过路由器B、路由器C到达主机S,数据1和数据2经过路由器A和路由器C到达主机S,所以数据由发送时的顺序0123变成了顺序1032。
2-1. UDP乱序的对策
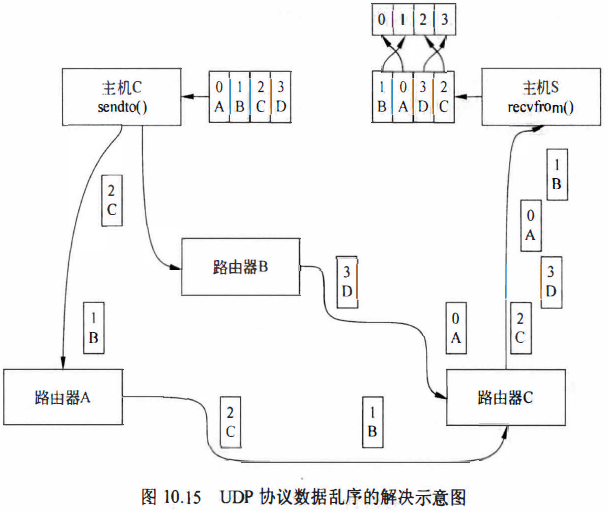
对于乱序的解决方法可以采用发送端在数据段中加入数据报序号的方法,这样接收端对接收到数据的头端进行简单地处理就可以重新获得原始顺序的数据, 如图10.15所示。
3.UDP协议中的connect() 函数
UDP协议的套接字描述符在进行了数据收发之后,才能确定套接字描述符中所表示的发送方或者接收方的地址,否则仅能确定本地的地址。例如客户端的套接字描述符在发送数据之前,只要确定建立正确就可以了,在发送的时候才确定发送目的方的地址;服务器bind()函数也仅仅绑定了本地进行接收的地址和端口。
connect() 函数在TCP协议中会发生三次握手,建立一个持续的连接,一般不用于 UDP。在 UDP 协议中使用 connect() 函数的作用仅仅表示确定了另一方的地址,并没有其他的含义。connect() 函数在 UDP 协议中使用后会产生如下的副作用:
- 使用 connect() 函数绑定套接字后,发送操作不能再使用 sendto() 函数,要使用 write() 函数直接操作套接字文件描述符,不再指定目的地址和端口号。
- 使用 connect() 函数绑定套接字后,接收操作不能再使用 recvfrom() 函数,要使用read()类的函数,函数不会返回发送方的地址和端口号。
- 在使用多次 connect() 函数的时候,会改变原来套接字绑定的目的地址和端口号,用新绑定的地址和端口号代替,原有的绑定状态会失效。可以使用这种特点来断开原来的连接。
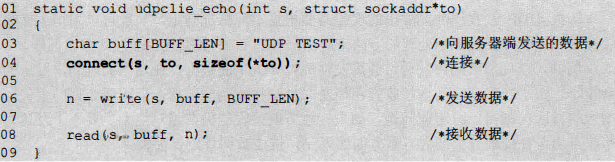
下面是一个使用 connect()函数的例子,在发送数据之前,将套接字文件描述符与目的地址使用 connect()函数进行了绑定,之后使用 write()函数发送数据并使用 read() 函数接收数据。
4. UDP缺乏流量控制
UDP 协议没有 TCP 协议所具有的滑动窗口概念,接收数据的时候直接将数据放到缓冲区中。如果用户没有及时地从缓冲区中将数据复制出来,后面到来的数据会接着向缓冲区中放入。当缓冲区满的时候,后面到来的数据会覆盖之前的数据而造成数据的丢失。
4-1. UDP 缺乏流量控制概念
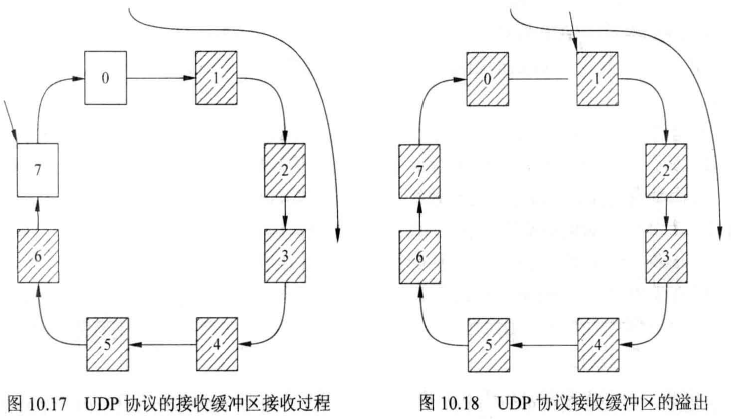
如图 10.16 所示为 UDP 的接收缓冲区示意图,共有8个缓冲区,构成一个环状数据缓冲区。起点为0。当接收到数据后,会将数据顺序放入之前数据的后面,并逐步递增缓冲区的序号,如图 10.17所示。当数据没有接收或者接收数据比发送数据的速率要慢, 之前接收的数据被覆盖,造成数据的丢失,如图10.18所示。
4-2. 缓冲区溢出对策
解决UDP接收缓冲区溢出的现象需要根据实际情况确定,一般可以用增大接收数据缓冲区和接收方接收单独处理的方法来解决局部的UDP数据接收缓冲区溢出问题。
5.UDP协议中的外出网络接口
在网络程序设计的时候,有时需要设置一些特定的条件。例如,一个主机有两个网卡,由于不同的网卡连接不同的子网,用户发送的数据从其中的一个网卡发出,将数据发送到特定的子网上。使用函数connect()可以将套接字文件描述符与一个网络地址结构进行绑定,在地址结构中所设置的值是发送接收数据时套接字采用的IP地址和端口。
6.UDP协议中数据报文截断
当使用UDP协议接收数据的时候,如果应用程序传入的接收缓冲区的大小小于到来数据的大小时,接收缓冲区会保存最大可能接收到的数据, 其他的数据将会丢失,并且有MSG_TRUNC的标志。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号