PythonGetWebTitle(批量获取网站标题)
最近写了批量get网站title的脚本,脚本很慢不实用,bug很多,慎用!主要是总结踩得坑,就当模块练习了。
源码如下:
import requests
import argparse
import re
class bcolors:
HEADER = '\033[95m'
OKBLUE = '\033[94m'
OKGREEN = '\033[92m'
WARNING = '\033[93m'
FAIL = '\033[91m'
ENDC = '\033[0m'
BOLD = '\033[1m'
UNDERLINE = '\033[4m'
def parser_args():
parser = argparse.ArgumentParser()
parser.add_argument("-f","--file",help="指定domain文件")
# parser.add_argument("-f","--file",help="指定domain文件",action="store_true") 不可控
return parser.parse_args()
def httpheaders(url):
proxies = {
'http': 'http://127.0.0.1:8080'
}
headers = {
'Connection': 'close',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
requests.packages.urllib3.disable_warnings()
res = requests.get(url, proxies=proxies, headers=headers, timeout=10, verify=False)
res.encoding = res.apparent_encoding
head = res.headers
# print('[+]url:'+url,' '+'Content-Type:'+head['Content-Type'])
title = re.findall("<title>(.*)</title>", res.text, re.IGNORECASE)[0].strip()
print(bcolors.OKGREEN+'[+]url:'+url,' '+'title:'+title+' length:'+head['Content-Length']+bcolors.ENDC)
def fileopen(filename):
with open(filename,'r') as obj:
for adomain in obj.readlines():
adomain = adomain.rstrip('\n')
try:
httpheaders(adomain)
except Exception as e:
print(bcolors.WARNING +'[+]'+adomain+" Connect refuse"+bcolors.ENDC)
if __name__ == "__main__":
try:
abc = vars(parser_args())
a = abc['file']
fileopen(a)
except FileNotFoundError as e:
print('目录下无该文件'+a)
本次踩到的坑:
1.使用Python3 requests发送HTTPS请求,已经关闭认证(verify=False)情况下,控制台会输出以下错误:
InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
命令行看到此消息,强迫症会很难受。
解决办法:在执行code前加入 requests.packages.urllib3.disable_warnings()
2.关于argparse模块的用法:
def parser_args(): parser = argparse.ArgumentParser() #创建ArgumentParser()对象 parser.add_argument("-f","--file",help="指定domain文件") #主要看第二个参数,--file将file传作key值,例如:-f aaa,那么file的value为'aaa' # parser.add_argument("-f","--file",help="指定domain文件",action="store_true") 不可控 return parser.parse_args()
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
分割线,此时已是3月10日凌晨2:56
已经被bug折磨的死去活来,书到用时方恨少,当初我要是好好学习就不会这样了T T
上代码!
这次加了线程,脚本运行速度可以像火箭一样快了
# -*- coding:utf-8 -*-
import threading,requests,re
import logging
logging.captureWarnings(True)
from concurrent.futures import ThreadPoolExecutor
import argparse
import time
# lock = threading.Lock()
def parser_args():
parser = argparse.ArgumentParser()
parser.add_argument("-f","--file",help="指定domain文件")
return parser.parse_args()
def getTitle(url):
f = open("resultssq.txt", "a", encoding='utf-8')
headers = {
'Connection': 'close',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36',
'Accept': 'textml,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
try:
res = requests.get(url, headers=headers, timeout=100, verify=False)
res.encoding = res.apparent_encoding
a = res.status_code
title = re.findall("<title>(.*)</title>", res.text, re.IGNORECASE)[0].strip()
resurlhttp = url.rsplit('//')
if 'https://'+resurlhttp[1] == res.url.rstrip('/'):
f.write('[+]'+res.url + "\t----\t" +title+'\n')
return print('[+]'+res.url + "\t----\t" + title)
if url == res.url.rstrip('/'):
f.write('[+]'+res.url + "\t----\t" +title+'\n')
return print('[+]'+res.url + "\t----\t" + title)
else:
f.write('[redirect]'+url+'\t => \t'+res.url + "\t----\t" +title+'\n')
print('[redirect]'+url+'\t => \t'+res.url + "\t----\t" + title)
except:
# time.sleep(10)
print(res.status_code,url)
f = f.close()
a = vars(parser_args())
file = a['file']
try:
with ThreadPoolExecutor(max_workers=100) as executor:
for i in open(file, errors="ignore").readlines():
executor.submit(getTitle, i.strip().strip('\\'))
except:
print('-f 指定domain文件')
追加跳转功能:如果网站是https协议,但是在只请求主机名的情况下,url上没有web协议,在res.url逻辑判断后可变为https:
当脚本运行完毕后,去查看result文件,发现少六七十个域名,排查错误发现是except语句之后并没有.write('xxx'),虚惊一场。尝试在except后执行写入语句,,,并不可以。
复制粘贴命令行打印结果,发现仍然少三十左右域名,我艹!
按照我写的逻辑应该都会输出的,突然想到,网站不存活的话不行,编写以下代码找出没被输出的url
f = open('wwwww.txt','r',encoding='utf-8') f1 = open('taobao.txt','r',encoding='utf-8') lists = [] for ii in f.readlines(): ii = ii.rstrip('\n') lists.append(ii) for i in f1.readlines(): i = i.rstrip('\n') if i not in lists: print(i)
艹,这个tmd也有坑,直接和f.read()判断,返回结果都是True
发现这几个孙子没输出,这几个url有的hostip存活,有的判断不出hostip
将这几个未输出的url扔到脚本debug捕获到异常HTTPConnectionPool
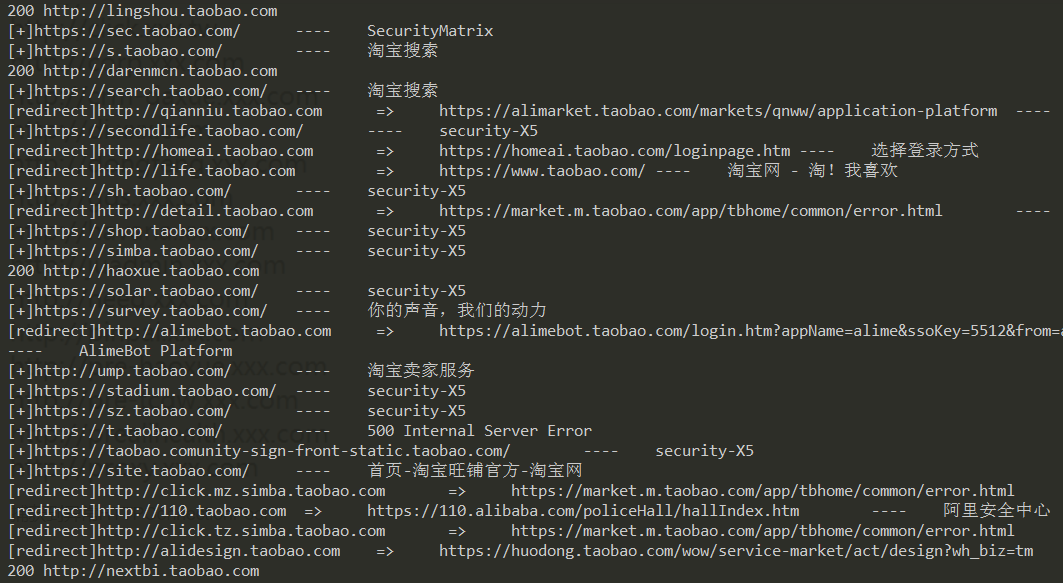
脚本运行效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号